この記事は GraphQL Advent Calendar 2020 13 日目の記事です。
前回の記事は @maaz118 さんの GraphQL の @defer, @stream ディレクティブを試してみる でした。
GraphQLにおける2つのPagination方式
Offset-basedとCursor-based
GraphQLにおけるpaginationには、Offset-based paginationとCursor-based paginationの2つが主な方法としてあります。
GraphQLの公式ページには3つの例が載っています。
https://graphql.org/learn/pagination/#pagination-and-edges
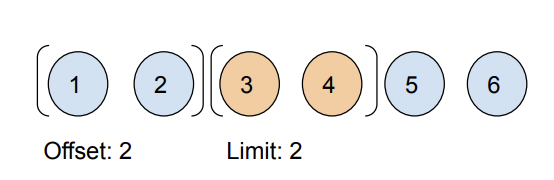
- We could do something like friends(first:2 offset:2) to ask for the next two in the list.
- We could do something like friends(first:2 after:$friendId), to ask for the next two after the last friend we fetched.
- We could do something like friends(first:2 after:$friendCursor), where we get a cursor from the last item and use that to paginate.
最初のケースである friends(first:2 offset:2) がOffset-based paginationです。
これはGraphQLに限らず、REST APIにおいても主流なページネーションの方法の1つですね。
SQLにおいて、first がLIMIT, offsetがそのままOFFSETに対応するので、SQLに触れたことのある方なら理解がしやすいと思います。
2つ目、3つ目の例のfriends(first:2 after:$friendId)、friends(first:2 after:$friendCursor) がCursor-based paginationの例となります。
この2つはCursorのフォーマットが違います。一方の例では、IDをcursorとして使用していますが、もう一方は前回取得結果より、cursorを取り出して使用しています。
Cursor-based paginationにおいては、firstがLIMITに対応するのはOffset-basedと同様ですが、afterに指定された値以降を取得することになります。
この場合の実際のSQLは実装によって異なりますが、もっとも単純な例として、sequentionに大きくなる値の場合には WHERE cursor > $1 のようになります。
- cursorがIdで3を指定した場合(
friends(first:2 after:3))

それぞれのページネーション方式に適するユースケース
この2つのページネーション方式は、それぞれ適するユースケースが違います。
Offset-basedは、リストの中の特定の範囲の集合を抜き出すのに向いています。
具体的にはGoogleの検索結果のページ遷移などです。

ここでダイレクトに3ページ目に遷移したい時、1ページあたりの表示件数が20件であれば、offset: 40, first: 20 と指定すれば良いことになります。
Cursor-basedでは、このような遷移には基本的には向いていません。afterに指定することになるcursorは前回の取得結果から取り出すことになるので、2ページ目を取得するまではafterに指定する値が分からないからです。
Cursor-basedが向いているのは、Twitterのタイムラインのような、前回の取得結果から最新の差分のみを取得したいケースです。
常に前回結果から取得した値の最後を次のクエリのafterに指定すれば良いことになるので、実装が簡易になります。
この2つにおいてはどちらが優れているということはなく、適材適所で使い分けるべきかなと思います。
cursorのフォーマット
先ほどあげた3つ目の例(friends(first:2 after:$friendCursor))としてIDを使わないことを示唆しているように、cursorのフォーマットに厳密な決まりはありません。
必要な情報は要件によって変わるため、上のGraphQLの公式ページにおいても、必要な情報を入れた上でbase64 encodingして文字列に変換した値を使用することが推奨されています。
base64 encodingをcursorに施した実装においては、Resolverがcursorの指定を受け取った時にdecodeして、paginationに必要な情報を取得することになります。
特に明確な決まりがないため、どのような実装にしようか自分でも悩むことが多いです。
前置きが長くなりましたが、この記事ではcursorの生成をサポートしているライブラリの実装を比べながら、ベストプラクティスを探っていきます。
対象のライブラリたち
この記事では以下のライブラリを対象にしています。
- graphql-ruby v1.11.6
- Prisma1 v1.34.10
- Hasura v1.3.3
graphql-ruby
実装はこちらにありました。
https://github.com/rmosolgo/graphql-ruby/blob/v1.11.6/lib/graphql/relay/relation_connection.rb#L9
def cursor_from_node(item)
item_index = paged_nodes.index(item)
if item_index.nil?
raise("Can't generate cursor, item not found in connection: #{item}")
else
offset = item_index + 1 + ((paged_nodes_offset || 0) - (relation_offset(sliced_nodes) || 0))
if after
offset += offset_from_cursor(after)
elsif before
offset += offset_from_cursor(before) - 1 - sliced_nodes_count
end
encode(offset.to_s)
end
end
この実装においては、offsetを計算した上で、base64 encodingの元としています。
なので方法論的にはOffset-basedと同じ仕組みで動くことになります。
Cursorのフォーマットに指定がないゆえに、このようにOffset-basedにも寄せられるのはCursor-basedの利点とも言えそうですね。
Prisma1
Prisma2もCursorには対応しているのですが、こちらはbase64 encodingなどの対応は入っておらず、uniqueなモデルのフィールドは、要件を満たす限りcursorとしても採用可能というだけの素朴な対応なので、今回はあえてPrisma1を参考にしていきます。(Prisma1はすでにmaintenance modeで、重大なバグを除いて機能追加はないので、新規採用はおすすめしません。)
Prisma2のドキュメントはこちら。 https://www.prisma.io/docs/concepts/components/prisma-client/pagination#cursor-based-pagination
ラフにコードベースを眺めたところ、ちょうどcursorから実際のSQL条件に変換するところ(生成側ではなく受け取り時)が見つかったので、そこを参考にします。
// First, we fetch the ordering for the query. If none is passed, we order by id, ascending.
// We need that since before/after are dependent on the order.
val (orderByField: jooq.Field[AnyRef], orderByWithAlias: jooq.Field[AnyRef], sortOrder: SortOrder) = orderBy match {
case Some(order) => (modelColumn(order.field), aliasColumn(order.field.dbName), order.sortOrder)
case None => (idField, idWithAlias, SortOrder.Asc)
}
val value: IdGCValue = before match {
case None => after.get
case Some(id) => id
}
val cursor = `val`(value.value.asInstanceOf[AnyRef])
val selectQuery = sql
.select(orderByField)
.from(modelTable(model))
.where(idField.equal(placeHolder))
// Then, we select the comparison operation and construct the cursors. For instance, if we use ascending order, and we want
// to get the items before, we use the "<" comparator on the column that defines the order.
def cursorFor(cursorType: String): Condition = (cursorType, sortOrder) match {
case ("before", SortOrder.Asc) => or(and(orderByWithAlias.eq(selectQuery), idWithAlias.lessThan(cursor)), orderByWithAlias.lessThan(selectQuery))
case ("before", SortOrder.Desc) => or(and(orderByWithAlias.eq(selectQuery), idWithAlias.lessThan(cursor)), orderByWithAlias.greaterThan(selectQuery))
case ("after", SortOrder.Asc) => or(and(orderByWithAlias.eq(selectQuery), idWithAlias.greaterThan(cursor)), orderByWithAlias.greaterThan(selectQuery))
case ("after", SortOrder.Desc) => or(and(orderByWithAlias.eq(selectQuery), idWithAlias.greaterThan(cursor)), orderByWithAlias.lessThan(selectQuery))
case _ => throw new IllegalArgumentException
}
orderByで指定されたフィールドの値を、今回のafter/before(Prisma1はafterだけでなくbeforeにも対応しています)で指定された値とみなして採用する実装になっています。
つまりorderBy: createdAtと指定されていれば、WHERE createdAt > $1のようになるわけですね。
当然ですが、前回結果取得時のorderBy条件が、今回も同様でなければ動きません。
Hasura
コードを追ってみてもイマイチ生成箇所が掴めなかった(Haskell分からん..)ので、テストコードから値を探ってみます。
description: Fetch 2nd page of articles ordered by their article count
url: /v1beta1/relay
status: 200
query:
query: |
query {
author_connection(
first: 2
order_by: {articles_aggregate: {count: asc}}
after: "eyJhcnRpY2xlc19hZ2dyZWdhdGUiIDogeyJjb3VudCIgOiAxfSwgImlkIiA6IDN9"
){
pageInfo{
startCursor
endCursor
hasPreviousPage
hasNextPage
}
edges{
cursor
node{
name
articles_aggregate{
aggregate{
count
}
}
}
}
}
}
response:
data:
author_connection:
pageInfo:
startCursor: eyJhcnRpY2xlc19hZ2dyZWdhdGUiIDogeyJjb3VudCIgOiAyfSwgImlkIiA6IDJ9
endCursor: eyJhcnRpY2xlc19hZ2dyZWdhdGUiIDogeyJjb3VudCIgOiAzfSwgImlkIiA6IDF9
hasPreviousPage: true
hasNextPage: false
edges:
- cursor: eyJhcnRpY2xlc19hZ2dyZWdhdGUiIDogeyJjb3VudCIgOiAyfSwgImlkIiA6IDJ9
node:
name: Author 2
articles_aggregate:
aggregate:
count: 2
- cursor: eyJhcnRpY2xlc19hZ2dyZWdhdGUiIDogeyJjb3VudCIgOiAzfSwgImlkIiA6IDF9
node:
name: Author 1
articles_aggregate:
aggregate:
count: 3
endCursorの値をdecodeしてみると{"articles_aggregate" : {"count" : 3}, "id" : 1}という値が算出されました。
これはorder_byに指定されている値 + 自身のIDになっていますね。
仕組み的にはPrisma1と同様、orderByで指定された値をCursorとしても使用することになるのだと思います。
さてベストプラクティスは?
どの実装もCursorを実現する妥当な実装と言えるかなぁと思います。
graphql-rubyの実装が他の2つとは違いましたが、ユースケースによってはOffset-basedの利点を取り入れることもできるのでケースバイケースとも言えそうです。
個人的には、一般的なCursor-basedの要件としては、Prisma1やHasuraの実装のように、OrderByに指定しているフィールドがsequentionであることを前提に、その値を元にcursorを生成するのが無難なのかと思います。