なぜこの記事を書くのか
AWS re:Invent 2018 で歓声とともに発表されたAWS LakeFormationですが、約1年半経っても有効活用がされているという話をあまり聞きません。私は根本的にはLakeFormationの「サービス設計がよくない」ことが原因だと思いますが、そもそも情報が少なすぎることも要因の1つだと思います。(最近発売された書籍「AWSではじめるデータレイク」もLakeFormationの説明は少ないです。)そのため、使い方・機能を、それぞれマクロ・ミクロの視点から少し整理してみようと思います。結果的にまとまりのよくない記事になってしまいましたが、利用判断の一助になれば幸いです。
- なお本記事では以下の機能については触れません。
- 他社データカタログ機能との比較
- Blueprints機能
- GlueやIAMの互換性まわり
- 運用設計
まずはマクロな視点から説明します。
LakeFormationを利用したほうがいいケース
- 利用ユーザ側が以下の条件に多く当てはまる場合は、LakeFormationの利点が得られると思います。(上から重要な順に記載)
-
AWSのIAMに精通しているエンジニアがいない
- またはユーザ部門でセルフサービスとしてデータレイクを運用したい
- 最低3名程度のデータ管理チームを立てることができる
- データカタログ機能にあまり期待しなくてよい
- 新しくデータレイクを構築しようとしている
- LakeFormationの学習コストおよび利用ユーザへの啓蒙コストを払うことができる
LakeFormationの利点
-
データレイクの複雑なIAM設計の多くから解放される
- これに尽きると思います。ただしすべてLakeFormationで完結できるとは限りませんので、IAM設計ができる人を用意しておく必要はあります。特に以下のようなところでIAM設計が必要になります。
- データパイプラインのうち両端(インプット/アウトプット寄りのところ)
- これはLakeFormationがIAMの「代理」的な動きをすることに起因します。
- 代理的な動き(IAMロールのassume)ができない多くのサードパーティツールとの連携ではメリットを活かせないことがあります。
- これはLakeFormationがIAMの「代理」的な動きをすることに起因します。
- LakeFormationのユーザ(ペルソナ)に設定するIAMの設計
- 複雑なIAM設計のイメージは以下がわかりやすいと思います。
- 利点の大きさはLakeFormationなしでデータレイクを作ってみないとわかりづらいと思います。AWSのデータレイクはリージョンサービスであるS3が中心になります。リージョンサービスはインターネットに隣接する位置にあるため、アクセス制御のミスが命取りになりえます。S3の主たるアクセス制御機能はバケットポリシーです。
- バケットポリシーは「リソースベースポリシー」に分類されるものです。ユーザやロールに付与する「アイデンティティベースポリシー」と異なります。ただ条件によって両者がOR演算、またはAND演算で関連しあいます。それゆえ、データレイク(S3)へのアクセスを考えるときには、以下の両方を考えなければいけません。
- データの置き場 → バケットポリシー(リソースベースポリシー)で制御
- データの利用者 → IAMポリシー(アイデンティティベースポリシー)で制御
- 通常、同一アカウント同士であればバケットポリシーとIAMポリシーはOR演算になります。OR演算はどちらか一方が明示的なAllowを通せばOKになってしまうため、緩い認可ロジックといえます。制御をしっかりやるにはバケットポリシーは明示的なdenyをかけたうえで例外を追加していくというような複雑な条件が必要になります。(例外のためにnot系の条件を多用する場合はド・モルガンの法則の理解も必要です。)
- **複雑な設計が必要ということは、それだけセキュリティの抜け穴が発生しやすいというリスクがあるということにほかなりません。**また、そのリスクを回避するためには適切なスキルを持つエンジニアの確保コストが必要である、ということを意味します。クラウド専業のSIerに勤めている私からみても、IAMポリシーを使いこなすことのできるエンジニアは稀少ですので、確保は困難なことが多いと思います。不確実性の海を渡るため、デジタルトランスフォーメーションの要であるデータレイクが必要なのに、**セキュリティリスクを抱えたままで、かつ回避できるエンジニアも確保できない、というときに浮上してくるのがLakeFormationです。**ただしLakeFormationそのものの学習コストもそれなりに高いため、汎用的なIAMポリシーの学習コストとのトレードオフを思うと、それなりにデータ分析経験の厚みのある組織でないとマッチしないのではないかと思います。
利用に際し、まず考えるべきこと
LakeFormationがカバーする範囲は、データレイクのごく一部。
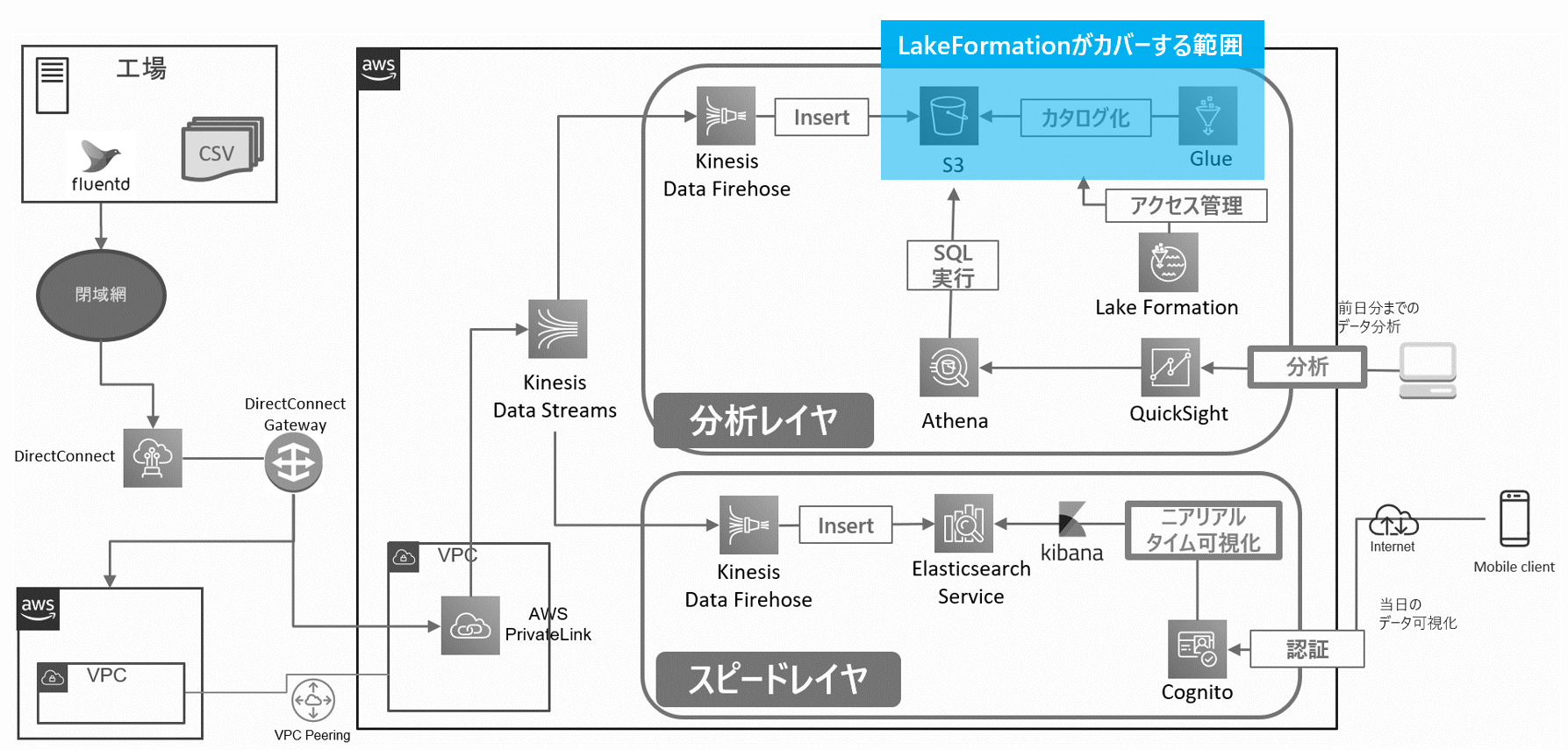
- 上図はLambdaアーキテクチャを採用した、IoT寄りな小・中規模データレイクの参考図です。
- LakeFormationはデータレイクの一部でしかありません。LakeFormationがカバーしない要素は、ぱっと思いつくだけでも以下のようなものがあります。
- データパイプライン(INPUT/OUTPUT)の設計
- データストアの設計
- S3の構造設計
- ETL処理(Glueジョブコーディング)
- BIのダッシュボード
- 業務レベルの利用フロー整備
- ここでは深堀りしませんが、どれもボリュームの大きい設計要素です。とくに[1.データパイプラインの設計]がもっともハードな要素です。「LakeFormation」という名前が人に抱かせるイメージに惑わされないように、設計要素を見極めてから計画を立てる必要があります。
ユーザ側のデータレイク利用スキームに以下の3種の役割を組み込むことができるか
- LakeFormationは以下のようなペルソナ(人間の役割)を想定して設計されています。社内リソースが確保できるか、文化的にも業務フローに組み込むことができそうか、検討してから導入することをおすすめします。
| # | ペルソナ名 | 役割 |
|---|---|---|
| 1 | データレイク管理者 | データ全体の管理者。窓口や啓蒙活動などを担う。 「データスチュワード」とも呼ばれる。 |
| 2 | データエンジニア | 生データを使いやすい形に加工し提供する人。 コーディングスキル持ち、メンテナンスもできるSRE的な人が担う |
| 3 | データ分析者 | 加工されたデータを利用する人。 BIなど見える化のスキルを持つ人が担う。 Athenaだけ利用できるIAMユーザであったり、QuickSightが利用するIAMロールであったり、様々。 (なお「IAMプリンシパル」とは、IAMユーザやIAMロールのことを指す) |
-
上記役割はAWSの公式資料では「ペルソナ」と呼ばれています。
- https://www.slideshare.net/AmazonWebServicesJapan/20191001-aws-black-belt-online-seminar-aws-lake-formation-198737098/45
- 実際に上記ペルソナ用のIAMを作成する場合は以下のページを参考にします。
- https://docs.aws.amazon.com/ja_jp/lake-formation/latest/dg/permissions-reference.html
- ただし上記ではデータエンジニアにIAMユーザを参照する権限がなく、他ユーザへのアクセス付与ができないため、「"iam:List*"」Actionの許可も追加しておいたほうがよいと思います。そのほか、Glueログ確認用に[CloudWatchLogsReadOnlyAccess]、ノートブックの開発用に[AWSGlueConsoleSageMakerNotebookFullAccess]ポリシーなどもつけておいたほうがよいかもしれません。
-
3人以上用意できなくても、たとえば以下のような兼任であれば、LakeFormationのアクセス制御の利点が活かせます。
- [1. データレイク管理者]と[2. データエンジニア]を一人が兼任する
- [2. データエンジニア]と[3. データ分析者]を一人が兼任する
- しかし一人で1,2,3すべてを兼任するような場合は、むしろLakeFormationの機能が足かせになると思います(将来的に人が増えるからしばらく一人でデメリットを受容する、という割り切りもアリです)。
-
2番目の「データエンジニア」というのが少し曲者です。AIやデータ活用基盤をすでにもっている組織であれば耳慣れた言葉ですし、チームも存在するかもしれません。LakeFormationは費用対効果を考えるとデータレイク導入前に利用検討することが望ましいのですが、データレイク導入前の段階で「データエンジニア」というロールを確保できている組織は多くは無いと思います。しかしながらLakeFormationを理解するためには、このAWSにおける「データエンジニア」の役割を意識することが不可欠です。
ここから機能をミクロな視点で説明していきたいと思います。
LakeFormationによってアクセス制御がどのように変わるのか
LakeFormationがない場合
急がば回れの精神で、S3から最も遠い位置にあるQuickSightから、Athena+Glueを経由してS3に行く例で考えてみます。

- QuickSightは[aws-quicksight-service-role-v0]という、サービスが自動生成するIAMロール(サービスリンクロール)を使ってS3にアクセスしようとします。
- S3へのアクセス許可はQuickSightの設定[QuickSightの管理]->[セキュリティとアクセス権限]からバケットを選択することで可能になります。
- 上記に登録されたS3バケットは、[aws-quicksight-service-role-v0]ロール内の[AWSQuickSightS3Policy]ポリシーに自動で登録されます。 -
ここではS3にアクセスする主体はQuickSightのIAMロールであるため、AthenaやGlueのことはあまり考える必要はなく、S3のバケットだけを気にしていれば良いシンプルな構造になっています。一方でこの構造は関所のようなものがなく、エンドツーエンドの認証認可になっています。つまりアクセス元のポリシーでS3へのアクセスが制御できてしまう(※)ため、データアクセスのガバナンスが効きづらいことが懸念されます。
- ※先に書いたようにS3バケットポリシーで明示的なDenyを行わない限り、IAMポリシーだけで許可を入れられてしまいます。
- なお、QuickSightのEnterpriseEditionであればQuickSightユーザ単位でS3アクセス制御ができますが、そのようにアクセス元サービスの機能に頼ってその機能のありなしにヤキモキするよりも、一元的なガバナンスの効く関所のようなものがあったほうが楽ですよね。
LakeFormationがある場合
ではLakeFormationを使うとどのように変化するか見ていきます。
- 初期設定として以下の作業を行います。
- まず、LakeFormationの[DataLake Locations]に、アクセスしたいS3バケットを登録します。
- すると代理的にS3にアクセスするロールが、指定したバケットにアクセスできるようになります。
- つぎにLakeFormationの[Data permissions]設定を行い、Glueデータベース/テーブルへの許可を、QuickSightのロールに対して付与します。
- まず、LakeFormationの[DataLake Locations]に、アクセスしたいS3バケットを登録します。
LakeFormationの設定は以下のような構造になります。
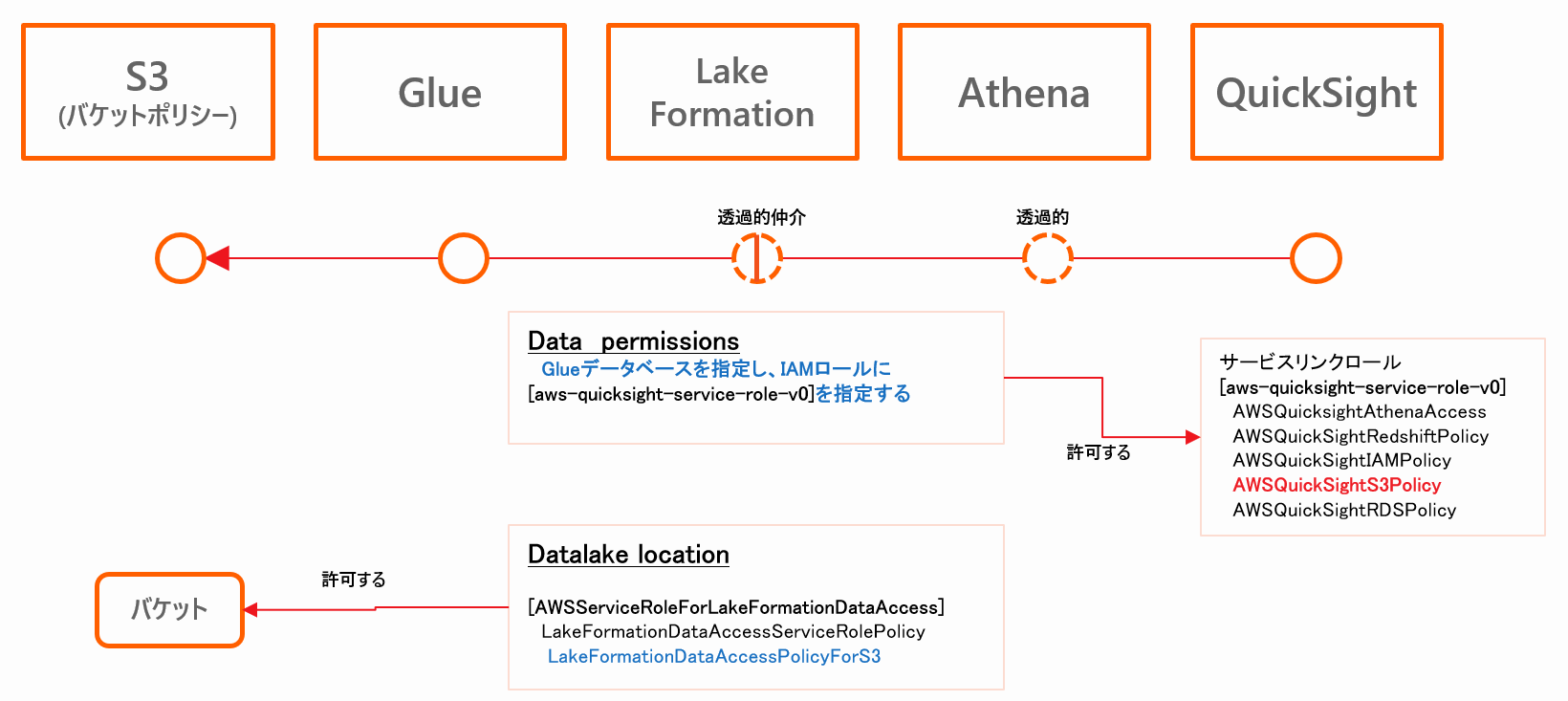
- つまり、LakeFormationで認証認可がいったん中断し、異なるチェック機構が「ハイジャック的に」介入するようになります。
- 例えていうなら駅員(LakeFormation)が客(IAMプリンシパル)の行き先を確認し、許可台帳(Data permissions)をチェックして、行き先(DataLake Locations)にあわせた許可バッヂ(IAMロール)を客の胸に貼り付けるような動きです。
- 実際のチェック機構を絵にしたのが以下イメージ図です。
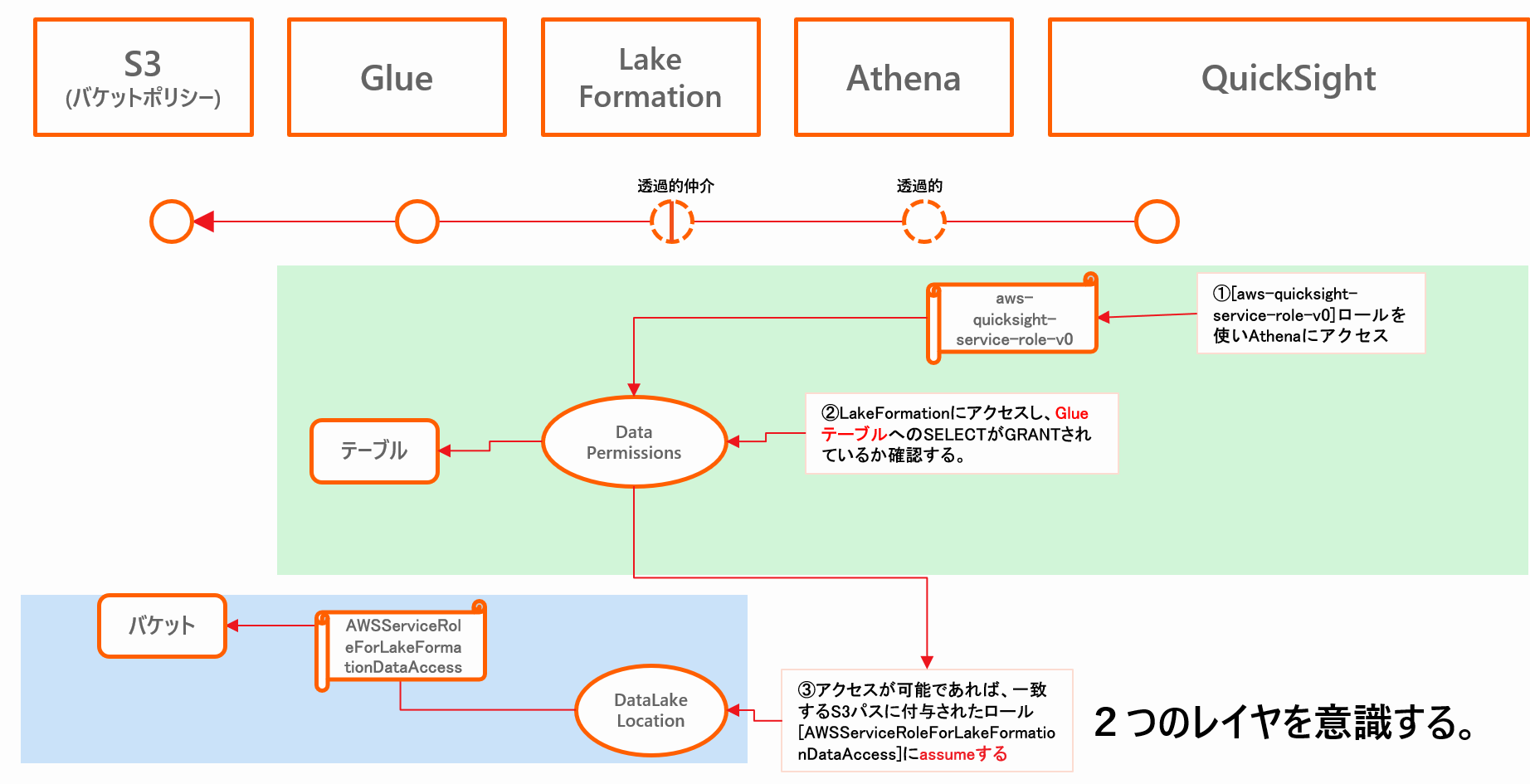
- **S3にたいしての認証の主体が、QuickSightのIAMロールから、LakeFormationのIAMロールに代理的に切り替わっていることがわかります。**その交通整理を行うのがLakeFormationだということになります。ガバナンスの効く関所ができたようなイメージです。
- LakeFormationを用いる例では、QuickSightのロールにS3バケットへのアクセス許可を追加する必要がありません。
- [AWSQuickSightS3Policy]ポリシーにS3バケットを登録する必要がなくなり、LakeFormation側の制御に統合できます。
- つまり客は行き先ごとの許可証を自分で毎回申請する必要がなく、行きたいところを駅員に伝えればよいだけになります。
| 利用有無 | S3アクセス認可の違い | デメリット |
|---|---|---|
| LakeFormationを利用しない (IAMによるアクセス制御) |
アクセス元のIAMにS3バケットへの許可が必要 | S3バケットポリシーを適切に設定しないと新規IAMポリシーでデータにアクセスされる危険性 |
| LakeFormationを利用する (LakeFormationによるアクセス制御) |
アクセス元のIAMにS3バケットへの許可が不要 | LakeFormationの設定として、Glueテーブルへの認可が必要 |
- 従来の[IAMによるアクセス制御]との互換性については今回は触れませんが、以下のURLが有用です。ちゃんと理解して設定しておかないと、意図しないアクセス許可の抜け道ができてしまうことがあります。
- https://www.slideshare.net/AmazonWebServicesJapan/20191001-aws-black-belt-online-seminar-aws-lake-formation-198737098/58
- https://docs.aws.amazon.com/ja_jp/lake-formation/latest/dg/upgrade-glue-lake-formation.html
- https://docs.aws.amazon.com/lake-formation/latest/dg/getting-started-setup.html#setup-change-cat-settings
LakeFormationの機能について
そもそも
ここでいったんスタート地点に立ち戻って考えてみます。
-
そもそも従来の[IAMによるアクセス制御]があるなかで、後続サービスであるLakeFormationがアクセス制御を追加で行うにはどうすればいいのでしょうか。S3全体に強制的にバリアのようなものをかけて[IAMによるアクセス制御]を阻害してしまったら既存システムへの影響が大きすぎます。影響を抑えるには「この場所がLakeFormationで管理したいS3パスだ」というように限定的に宣言する他ありません。その宣言こそが「DataLake Locations」という機能です。
- この宣言がなされていないS3パスは従来の[IAMによるアクセス制御]のまま扱われます。既存の仕組みと棲み分けができるということですね。
-
当然、特定のS3パスをバリアしたあとは、ファイアウォールのようにアクセス元に許可させる設定も必要です。それが[Data permissions]という機能です。ここまではわかりやすい話です。
Glueテーブルの位置づけ
- LakeFormationのややこしいところがここからです。[Data permissions]は、S3のパスにたいして許可するのではなく、Glueテーブルにたいして許可をする必要があります。つまり、許可をするまえに予めデータカタログを作りテーブルスキーマを定義しておかないといけないということです。なぜこのような面倒なしくみになっているのでしょうか。おそらくアクセス制御をデータベース単位、テーブル単位、のみならずカラム単位で行えるようにするためだと考えられます。テーブルスキーマが存在しないとカラム単位で制御ができないからです(※)。
- ※ちなみに特定のカラムを見せたくない場合は、アクセス制御ではなくGlueジョブで先に消してしまうという手もアリです。
- Glueデータベース、Glueテーブル(テーブルスキーマ)をあわせてAWSデータカタログという言葉でまとめてみます。
- AWSデータカタログはあくまでメタデータであり、データの実体ではない、仮想的な存在です。ポインタのようなものであり、1データストレージに複数のメタデータを作成できます。
| 区分 | オントロジー | LakeFormationにおける捉え方 |
|---|---|---|
| データストレージ | ・データの実体 | ・S3のパス(スキーマ情報なし) |
| メタデータ (AWSデータカタログ |
・仮想的な存在 ・実体を補足的に説明する情報 ・データの場所を示すポインタ |
・Glueデータベース(Glueテーブルのまとまり) ・Glueテーブル(スキーマ情報やリネージなどのビジネスドメイン情報) |
-
上記のようにLakeFormationは「メタデータ=Glueテーブル」として設計してあります。データを登録するためにはテーブルを作成し、しかも面倒なことにテーブルスキーマも同時に定義しなければ作成ができません。(テーブルスキーマの認識は手動の他にGlueクローラでも可能ですが、面倒であることに変わりはありません。)
-
このようにLakeFormationでは、データカタログを使うために、Glueテーブルが重要な役割を担う構造になっています。このGlueテーブルの位置づけこそが[Data Locations](※)という最も分かりづらい機能を理解するのに重要な認識となります。
- ※名称的にも[Data Locations]と[Datalake Locations]は紛らわしく誤解を招きやすいです。
Data Locationsとは
-
まず、ポインタであるデータカタログ(Glueテーブル)を、データエンジニアが無制限に作れる場合を考えます。LakeFormationにおいては、Glueテーブルがデータストレージの実体を指し示すゲートのような役割を担うため、ユーザにデータを公開する道をデータエンジニアが自由に作れてしまうことになります。具体的な例として、1つの[Datalake Locations]の配下に、別の部署に見せたくない機密情報が含まれているS3パスがあるケースを考えます。そのようなとき、別の部署に勝手にデータを提供してほしくないS3パスを、許可制に切り替えるのが[Data Locations]です。
-
[Data Locations]は、データに対しての「読み書き」の権限を制御する機能ではありません。特定の場所への「テーブル作成」を制御する機能です。
-
デフォルトではこの制御は無効化されています。制御を有効化したい場合は、[Data Locations]にS3パスと、そこへのテーブル作成を許すIAMプリンシパルを登録することで防御ができます。つまりこれはセキュリティの追加レイヤーを提供するものであり、使わないという選択肢もあるということです。
- なお、Glueデータベース作成時の設定[location - optional](以下)にS3パスを入力した場合は、配下のパスの[Data Locations]を無効化するケースもありますので、ご注意ください。
-
絵にしてみると以下のような関係になっています。

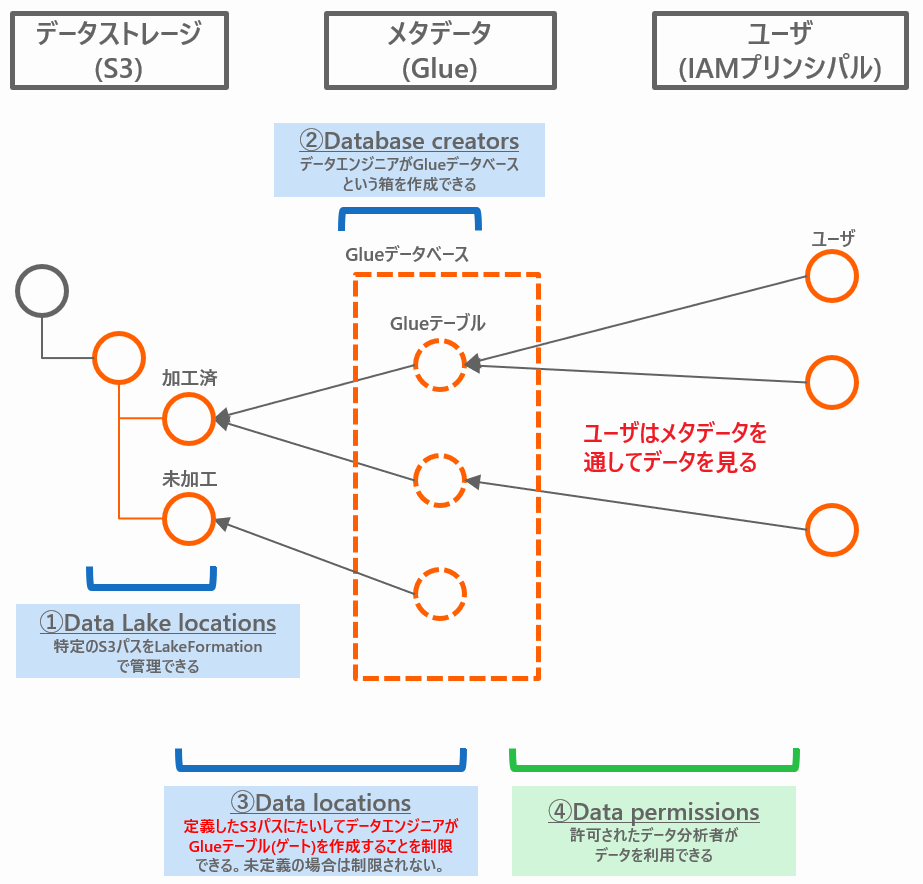
- 繰り返しになりますが、実データへのゲートとなるGlueテーブルを作る権限は、アクセスのためのパイプライン敷設と同義であるため、セキュリティ上とても重要です。それを制限できるようになる機能が[Data locations]です。
ペルソナ視点から理解する
- ペルソナ視点でLakeFormationの機能・操作とマッピングしてみます。
| ペルソナ | LakeFormation上の登録 | 主に扱う機能 | LakeFormation上の役割 | 操作例 |
|---|---|---|---|---|
| データレイク管理者 | [Data lake administrators]に登録されたIAMユーザ/ロール | [Data lake locations], [Database creators], [Data Locations] |
S3バケットを登録したり全体の権限を管轄する | ・[Data lake locations]にS3バケットを登録する。 ・IAMプリンシパルを作成したり、[Database creators]にデータエンジニアを登録する。 ・データエンジニアからの要請に応じて[Data Locations]の設定を行う。 |
| データエンジニア | [Database creators]に登録されたIAMユーザ/ロール |
[Crawlers], [Jobs], [Data permissions] |
AWS内のデータパイプライン形成やそのアクセス制御を行う | ・Glueでデータを登録(カタログ化)する。 ・[Data permissions]でデータ分析者にGlue上のデータベース・テーブルへのアクセスを許可する |
| データ分析者 | [Data permissions]に登録されたIAMユーザ/ロール | - | データを利用する | ・IAMユーザ/ロールに付与されている[Data permissions]の権限でGlueのテーブルにアクセスする |
- 上表はあくまで一例ですので、運用設計によっては付与するポリシーのアレンジが必要になります。ただ大枠として3つのペルソナを想定してユーザ設計を行うとLakeFormationと親和性があがります。
さいごに
-
記事を書いてみて改めて思いましたが、やはりシンプルに説明することが難しい、学習コストの高いサービスだと感じます。
-
S3にたいしてのアクセス制御はエンタープライズレベルに可能なのですが、謳い文句の「安全なデータレイクを数日で構築」ができるかと問われると、できないと思います。データレイクに必要な設計要素にたいし、サービスのカバー範囲が狭いためです。
- Blueprintsの種類が増える、もしくはAIでメタデータを自動認識するなど機能が拡張されていけば名実一体に近づくと思いますので期待したいです。
-
現サービスレベルでの使い所としては、例えば「すでにAWSのデータレイクが構築できておりアクセス制御周りだけを強化したい」というようなフェーズで、リプレイスとして導入するのは有効な気がします。(そのようなフェーズであれば学習コストの妥当性が醸成されていると思います。)
-
個人的には、LakeFormationはスモールスタートを支援すべく、利用ユーザにとって「データエンジニア」を意識しなくてもよい(透過的で、かつGlueのデータベースやテーブル概念と分離された)サービス設計にすべきであったと思います。今更それは難しいでしょうから、他のサービスを拡充させたうえで疎結合なサービス構造にしてみるのもいいかもしれません。たとえばこんなふうに・・・
- AWS DataLake(総称)
- Amazon DataCatalog(新サービス)
- AWS CatalogControl(旧AWS LakeFormation)
- AWS DataControl(新サービス)
- ・・・あくまで勝手に考えたプロダクトデザインです
- AWS DataLake(総称)