はじめに
Redshiftをメインに使っているユーザを想定して、DataZoneのデータソースにRedshift(Provisioned版)を登録してみます。
- なお、Redshift Serverless版についてはClassmethodさんの良記事があります
まずは
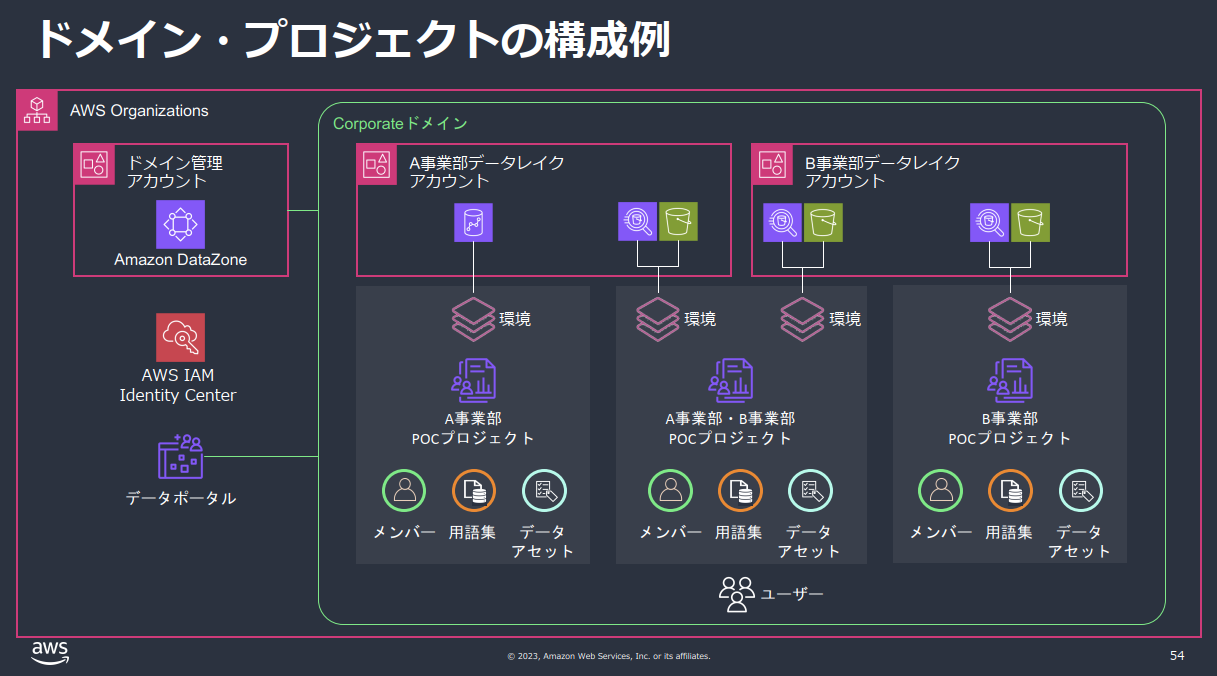
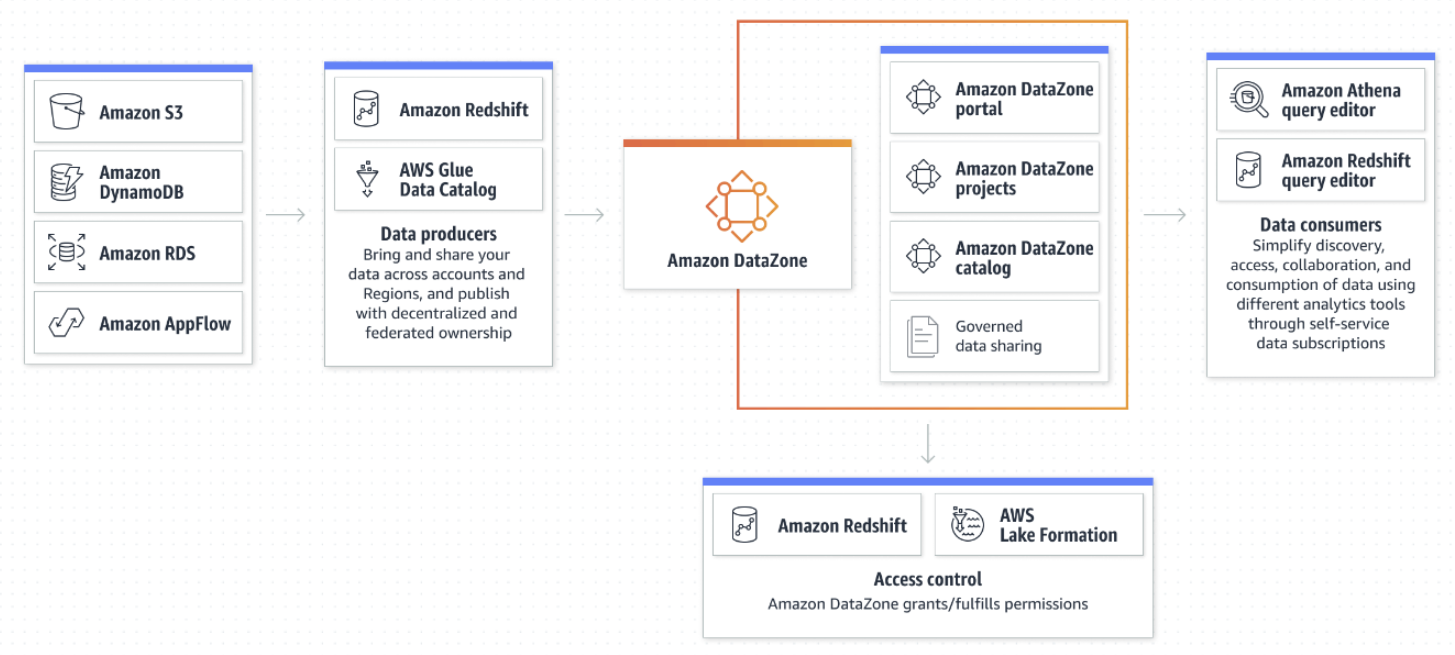
DataZoneの構成例
- DataZoneを触るときはこの図を見直しておくと吉です。
- 久しぶりに触ると間違いなくDataZoneにおける「ドメイン」という概念に戸惑います。
- DataZoneにおけるドメインとは、AWSアカウントを跨ってデータを利活用する組織体のようなものです。
- 会社単位やグループ企業単位など、ともかく広い範囲で作るグループです。
- 企業内のデータカタログを共有する最大範囲で捉えておくと良いと思います。
- また、利用に際しDataZone「プロジェクト」も必要になります。
- これはひとまずデータを提供または利用するメンバーをまとめるチームのようなものだと思えばよく、部署名やグループ名など、管理しやすい単位で作成すればよいと思います。
出典:https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-DataZone-Overview_1231_v1.pdf
- これはひとまずデータを提供または利用するメンバーをまとめるチームのようなものだと思えばよく、部署名やグループ名など、管理しやすい単位で作成すればよいと思います。
手順
- 本記事の手順の流れ
- 【Redshift】クラスタの起動
- 【DataZone】各種IDの確認
- 【Secrets Manager】Redshift用シークレットの作成
- 【DataZone】環境の作成
- 【Redshift】テスト用テーブルの作成
- 【DataZone】データソースの作成
- 【DataZone】データソースの実行
- 【DataZone】インベントリデータの確認
- 【DataZone】インベントリデータの公開
本作業の前提条件
-
DataZone
- 東京リージョンを利用
- ドメインを作成済み
- プロジェクトを作成済み
-
Redshift
- 東京リージョンを利用
- クラスタを作成済み
情報源と注意事項
- 公式のRedshift追加手順はこちら
- その他注意事項
- 「スキーマ」という用語について
- 一般にデータベース界隈では「スキーマ」は処理系によって異なる意味を持つことがあります。DataZoneでRedshiftをソースとして利用する場合、AWSマネジメントコンソールの表記上それらが区別されていないので、混乱しないようにここに記載します。
- DataZoneでは全般的に「スキーマ」はテーブルの列(カラム)情報を指します。
- Redshiftの文脈において「スキーマ」は、「データベース -> スキーマ -> テーブル」という構造に位置する、テーブルをまとめる上位概念を意味しています。
- 本記事では文脈上紛らわしい場合のみ、これを意識的に「Redshiftスキーマ」と呼ぶことにします。
- 一般にデータベース界隈では「スキーマ」は処理系によって異なる意味を持つことがあります。DataZoneでRedshiftをソースとして利用する場合、AWSマネジメントコンソールの表記上それらが区別されていないので、混乱しないようにここに記載します。
- 「スキーマ」という用語について
Redshiftのクラスタ起動
- データソースに登録したいRedshift(Provisioned版)を起動しておきます。(割愛)
- ネットワークの諸条件について
- DataZoneからのアクセスのために、特別な対応は必要ありません。
- クラスタの「パブリックアクセス」:不要
- SecurityGroup:インバウンドを開ける必要なし
- これは、DataZoneからRedshiftへのメタデータ取得には[Redshift Data API]が用いられるためです。通信的にはループバックアドレス(127.0.0.1)からのアクセスになります。
- DataZoneからのアクセスのために、特別な対応は必要ありません。
- ネットワークの諸条件について
DataZone (情報確認)
Redshiftクラスタをデータカタログに登録するにあたり、まずはRedshiftの認証情報をどこかに保存する必要があります。「どこか」とはAWS の SecretsMangerになります。
まずは、後述のSecretsMangerへのタグ付けに必要な情報として、DataZoneの「ドメイン名」と「ドメインID」を取得します。
-
DataZoneドメイン管理アカウントのにログインして、ドメインを表示します。
-
対象のドメインのデータポータルを開きます。
-
データポータルを開いたら、画面左上からプロジェクトを選択しておきます。
-
次に画面右上のユーザ名をクリックし、表示される「ドメインID」「プロジェクトID」 をコピーしておきます。
-
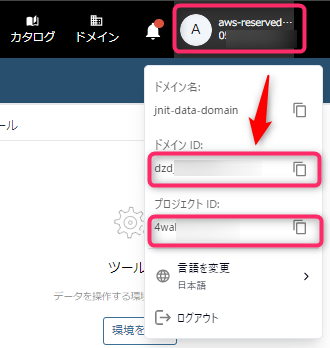
- ※ドメイン名ではなく、ドメインIDをコピーする点に注意してください。
- ※プロジェクトIDは、左上でプロジェクト選択済みの場合に表示されます。
-
Secrets Manager
- AWS Secrets Manager を開き、新しいシークレットを作成します。
- Redshift用のシークレットタイプを選択し、接続対象のRedshiftクラスタのユーザ・パスワードを入力し、と対象クラスタを選択します。
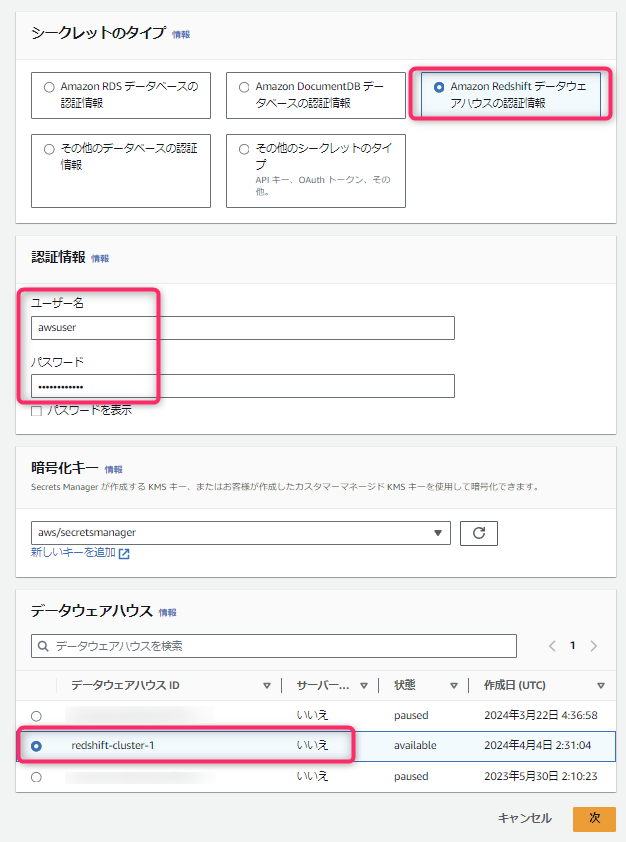
- なお、ここで入力するDBユーザは管理者相当(スーパーユーザ)権限でよいと思います。SecretsはDataZone側ではARNを指定する形となります。
- このユーザを元に、後のDataZoneの「環境」作成時にDataZone内の指定DBにスキーマも作成されますので、それなりに強い権限のDBユーザを指定する必要があります。
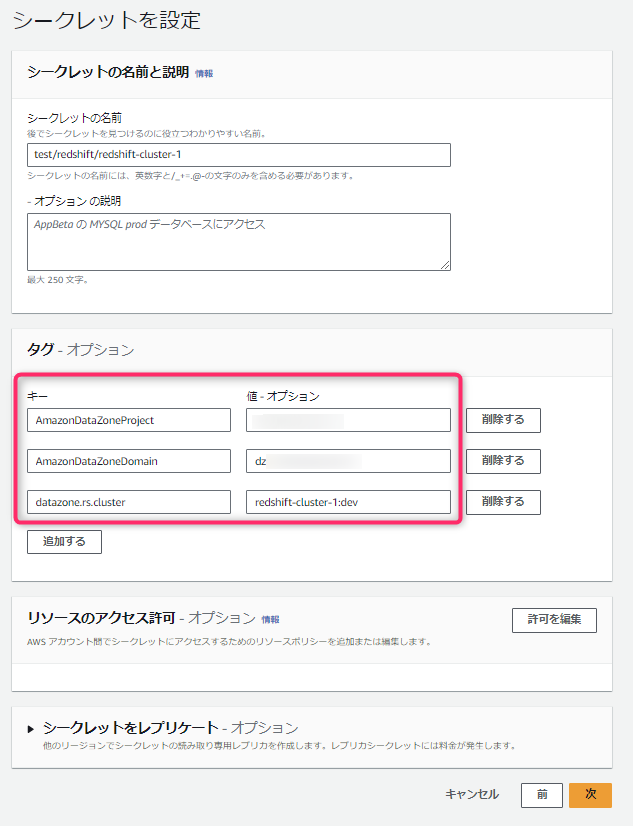
- 次の画面では、シークレットの名前を入力後、いくつかタグを設定します。
- 設定すべきタグの命名規則などは公式に載っています。Redshift Provisiond版の場合、下表の設定が必要になります。
- Redshift用のシークレットタイプを選択し、接続対象のRedshiftクラスタのユーザ・パスワードを入力し、と対象クラスタを選択します。
| Key | Value | 備考 |
|---|---|---|
| AmazonDataZoneProject | <projectID> | プロジェクト名ではないことに注意。後にDataZoneユーザ用のIAMポリシーの条件等に利用される。 |
| AmazonDataZoneDomain | <domainID> | ドメイン名ではないことに注意。後にDataZoneユーザ用のIAMポリシーの条件等に利用される。 |
| datazone.rs.cluster | <cluster_name:database name> | 指定した場合は後のDataZoneの「環境」設定で自動入力される |
DataZone (設定)
作成済みのドメインを選択して、データポータルを開きます。
データポータルを開いたら、作成済みのプロジェクトを選択します。
DataZoneの「環境」とは何か?
- 環境とは何か?
- データソースの設定を行う前にまず、DataZoneにおける「環境」とは何かを理解しておく必要があります。
- 「環境」はいわば「DataZoneにおける各データソースへの入口のようなもの」 です。
- 先の図のとおり、「環境」は1プロジェクト内に複数作成することができます。
- データソース毎、つまり「Redshiftの特定クラスタのデータベースをクエリエディタでアクセスする環境」や「Glueの特定のデータベースをAthenaでアクセスする環境」などです。
- また、以下のキャプチャのとおり、「環境」はより上位のテンプレート(ブループリントや環境プロファイル)の雛形を元に作成されます。
-

- 環境で何が作成されるのか?
- 「環境」の説明に「インフラストラクチャとツールがデプロイされる」と記載されています。これはクラスタがデプロイされるという意味ではありません。なのでデータソース(この場合Redshiftクラスタ)は予め自分で用意しておく必要があります。つまり「環境」作成でDataZoneにデプロイされるのは「DataZoneにとってのデータソースへの入口」( ツールへのリンクとそれに紐づく権限 )です。
- DataZoneにおけるRedshift向けの「環境」においてはそれぞれ以下を意味します。
- インフラストラクチャ
- 作成済みのRedshiftクラスタがDataZoneに認識されること
- ツール
- Redshiftで標準提供されるクエリエディタ(ブラウザ上で操作可)へのDataZone専用リンク
- このリンクからクエリエディタにアクセスすることでDataZone専用の権限(IAMロール)でテーブルの操作が可能に。
- Redshiftで標準提供されるクエリエディタ(ブラウザ上で操作可)へのDataZone専用リンク
- インフラストラクチャ
- なぜ環境が必要なのか?
- ここで、「いやいや、そんな入口用意してもらわなくても、Redshiftの管理画面から普通に操作できますけど? だってDataZone使うのにそもそもAWSのIAMユーザあるいはSSOユーザが必要なんだし」という疑問が湧いてきます。この疑問の回答としては、DataZoneはデータカタログだけでなく権限管理の役割も兼ねているためです。
- IAMまたはSSOで発行するDataZone向けユーザはRedshiftやAthenaの直接的な実行権限をつけずにDataZoneカタログから(専用のIAMロールで)操作してもらうことで、ガバナンス・統制を一元的に効かせることができるようになります。
- そのための新しい使い方をするために用意された門がDataZone(と「環境」)になります。
- https://docs.aws.amazon.com/ja_jp/datazone/latest/userguide/datazone-concepts.html#what-are-projects
-
Amazon DataZone プロジェクトでは、環境は、0 個以上の設定済みリソース (Amazon S3、AWS Glue データベース、Amazon Athena ワークグループなど) のコレクションであり、これらのリソースを操作できる IAM プリンシパルの特定のセットが含まれます。
環境プロファイルの作成
では環境プロファイルを作成していきます。
DatZoneポータルにてプロジェクト選択状態で、「環境」-> 「環境プロファイル」 -> 「環境プロファイルを作成」と選択していきます。
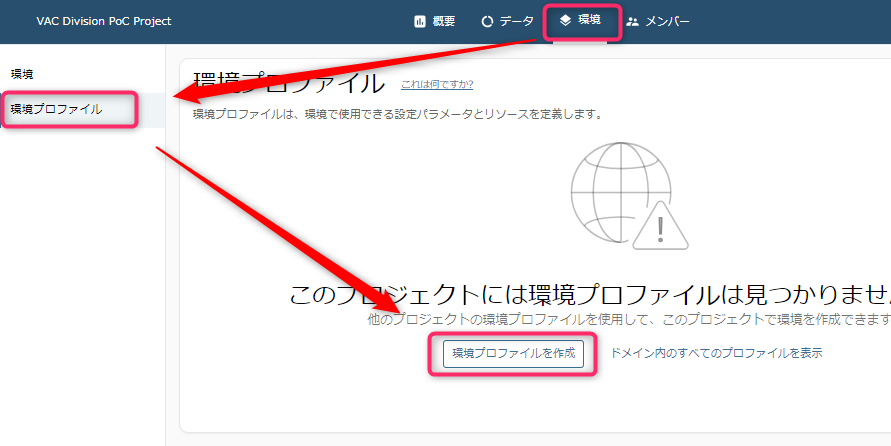
-
環境プロファイルに名前を設定します。
- 個人的には、データベースクラスタ名や、そのクラスタの大雑把な役割名などが含まれていると管理しやすいと思います。
- ブループリントは、AWSが自動でブループリントとして用意した「DefaultDataWarehouse」を指定します。
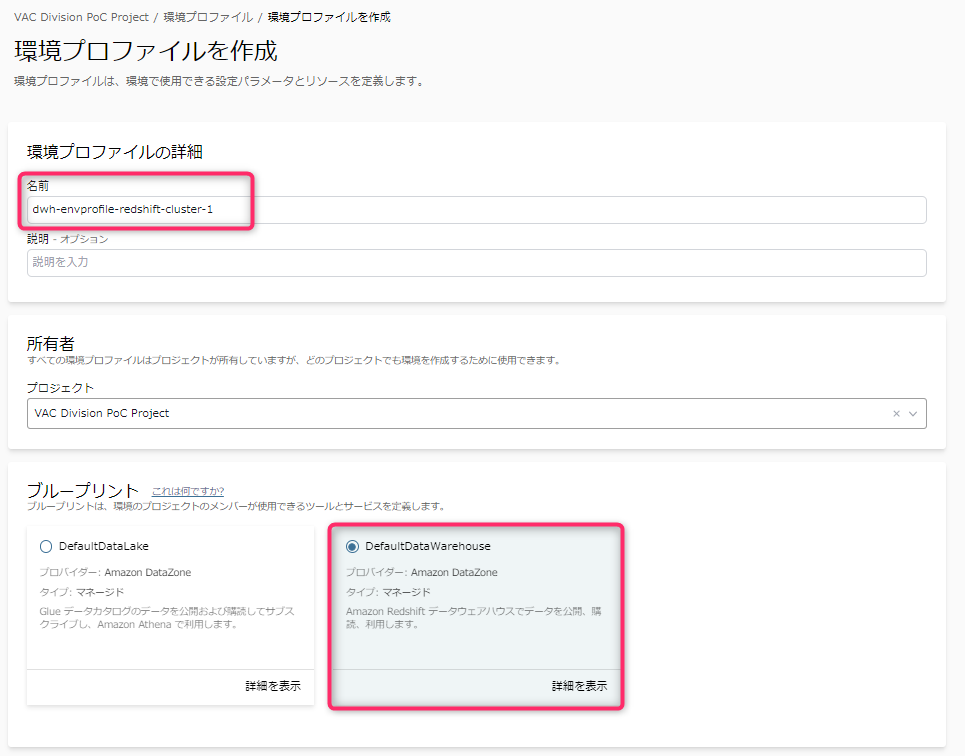
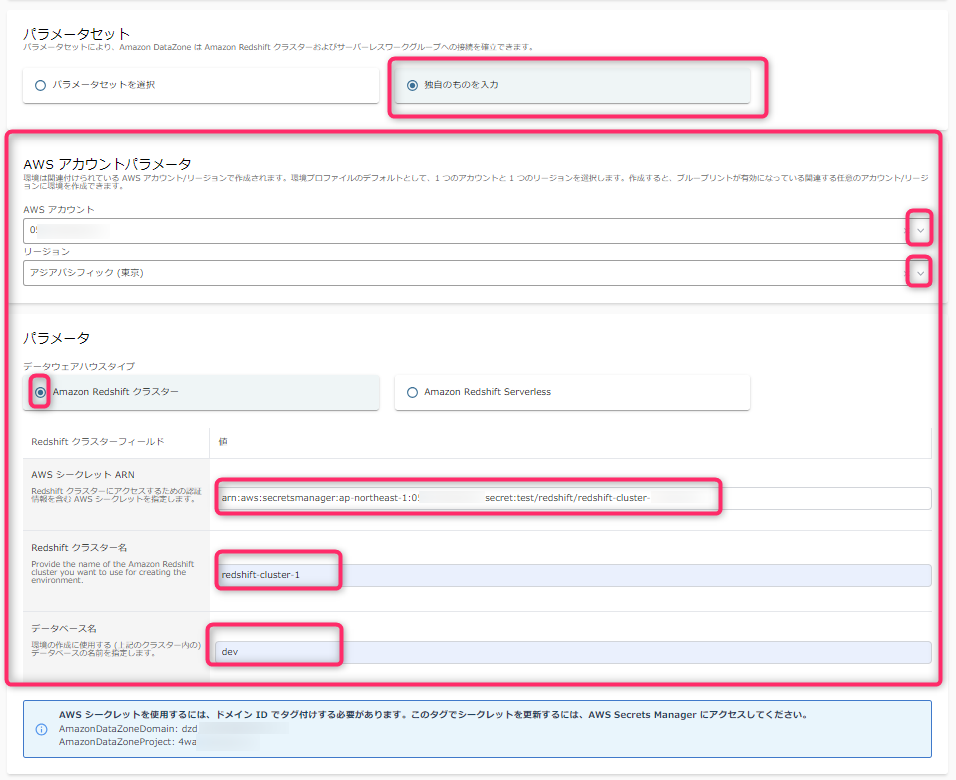
- すると、Redshift用のパラメータ入力項目が出現します。パラメータはすべて必須入力項目です。
- パラメータセットに「独自のものを入力」を選択すると、環境プロファイル毎に個別にRedshiftへの接続情報等を設定できます。
- 「パラメータセットを選択」の場合は、上位の概念であるブループリント側で事前に準備したRedshift接続情報を選択することができます。(2024年3月アップデートにより実装。これによりシークレット名などをデータ公開・利用者が理解しておく必要がなくなった)
- 「AWSアカウントパラメータ」や「リージョン」は、このデータベースクラスタを利用する可能性のあるデフォルトのアカウントとリージョンをリストからそれぞれ1つ指定します。
-
環境を作成できるプロジェクトと、対象のRedshiftにおける公開可能なスキーマを選択します。
- 「公開」については、DataZoneの「環境」が自動で新規作成するRedshiftスキーマ以外の、既存スキーマ内テーブルも含める場合は、「任意のスキーマから公開」を選択します。
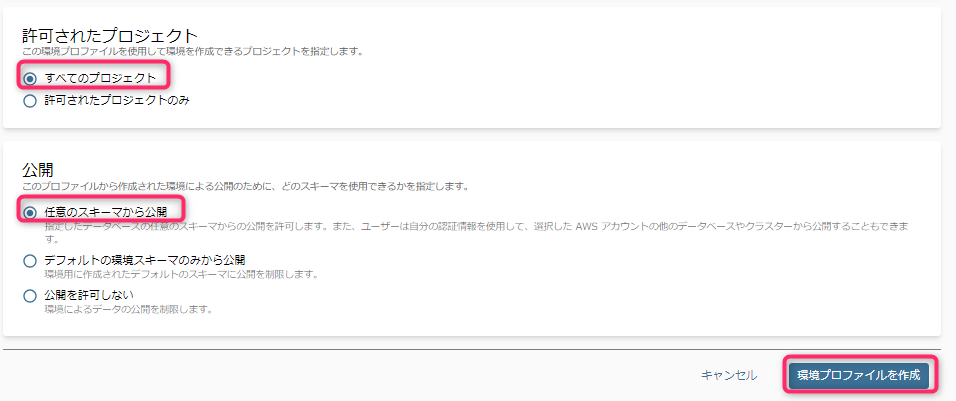
- 「公開」については、DataZoneの「環境」が自動で新規作成するRedshiftスキーマ以外の、既存スキーマ内テーブルも含める場合は、「任意のスキーマから公開」を選択します。
環境の作成
-
「環境プロファイル」が作成できたら、今度はそれを元に作成される「環境」を作成していきます。
-
まずは「環境」タブ -> 「環境」メニュー -> 「環境を作成」を選択します。
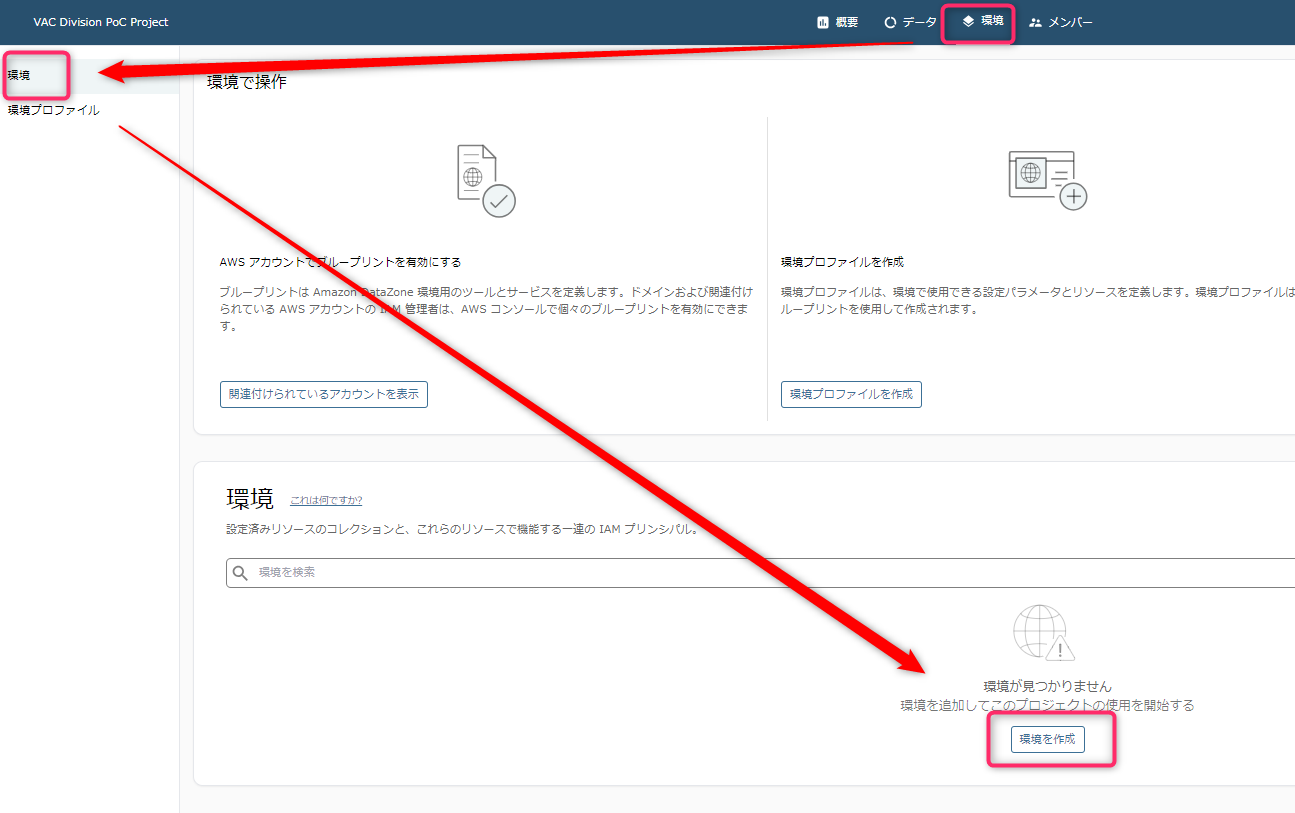
-
環境の名前と、先程作成した環境プロファイルを選択します。
- 環境の名前は、1つの環境が1つのRedshiftクラスタに紐づくため、個人的にはRedshiftクラスタ名が含まれているとよいかと思います。
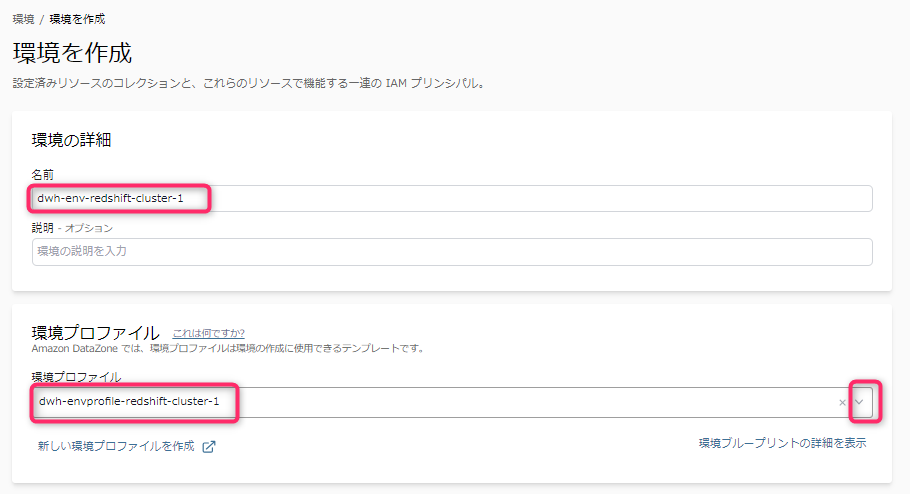
- 環境の名前は、1つの環境が1つのRedshiftクラスタに紐づくため、個人的にはRedshiftクラスタ名が含まれているとよいかと思います。
-
DB接続用パラメータ(クラスタ名など)は、環境プロファイルで設定した値を自動的に引き継いでいます。
- この場合の唯一の入力項目である「Custom Schema name - オプション」は、作成済みのスキーマを選択するのではなく、データカタログとして新しくこれからテーブルを作っていきたい新規のRedshiftスキーマ名(テーブルをまとめるグループ)を指定します。
- この値はあくまでオプションであるため、省略することができます。省略した場合は、以下の命名規則のスキーマが、指定したデータベース内に作成されます。
- datazone_env_<環境名>_<複数の環境の場合、乱数>
- なぜDataZone専用のスキーマをRedshiftデータベース内に強制的に作る仕様になっているのかは、理由はよくわかりません(権限管理しやすさ?)。
- もちろん、あとから環境にたいして「データソース」を追加して、既存のRedshiftスキーマを選択することもできます。
- また、DataZone専用スキーマは、環境作成時に自動削除されません。(「環境」作成後にユーザが作成したテーブルが、環境もろとも消えてしまうことを避けるためでしょう)
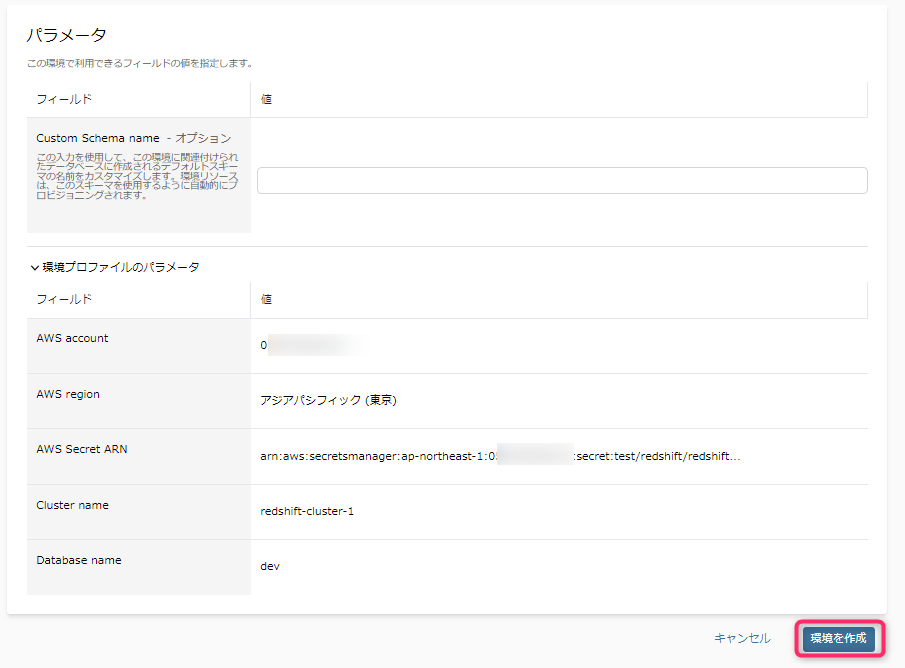
- この値はあくまでオプションであるため、省略することができます。省略した場合は、以下の命名規則のスキーマが、指定したデータベース内に作成されます。
- この場合の唯一の入力項目である「Custom Schema name - オプション」は、作成済みのスキーマを選択するのではなく、データカタログとして新しくこれからテーブルを作っていきたい新規のRedshiftスキーマ名(テーブルをまとめるグループ)を指定します。
デプロイ画面に遷移するため、数分待ちます。
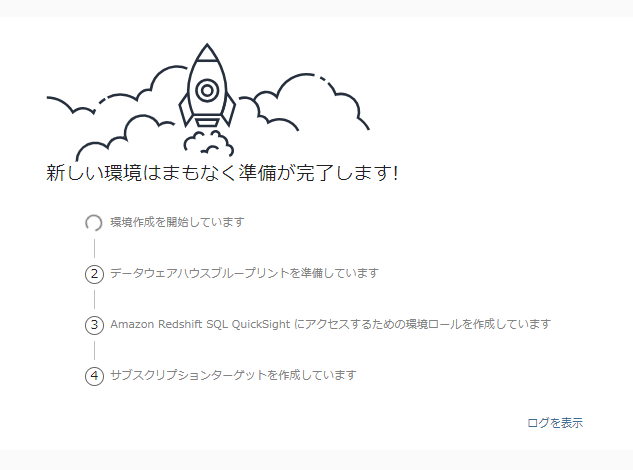
環境作成が正常に完了すると、自動的に「環境」の概要画面に遷移します。
-
ダッシュボードに以下の項目が確認できます。
- データアセット
- データソース
- 分析ツール
-
新規作成したプロジェクトの場合、以下のようになっているはずです。
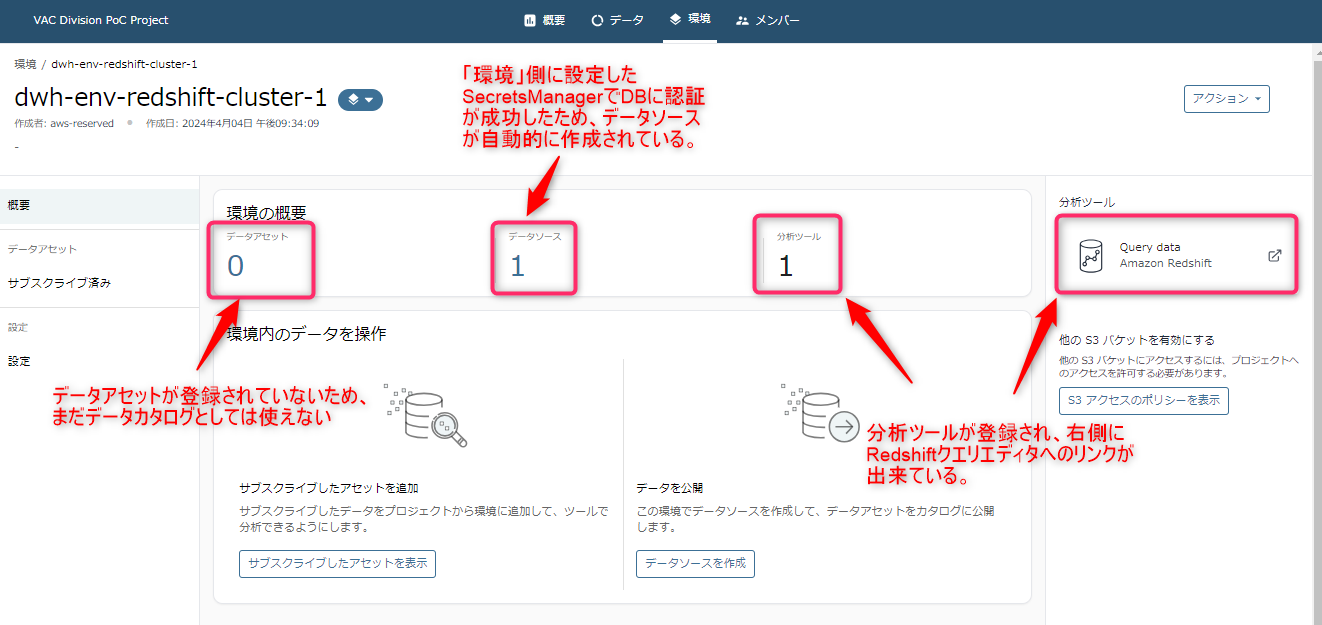
では、このあと「環境」を使ってRedshiftの中身のカラム情報などを取得していくのですが、その前にRedshift内に肝心のテーブルがないため、テスト用テーブルを作っていきます。
Redshift (テスト用テーブルの作成)
それではRedshiftにテーブルを作るために、ついでにDataZoneからクエリエディタに遷移してみます。
「環境」の右側にあるツールの「Query data」をクリックします。
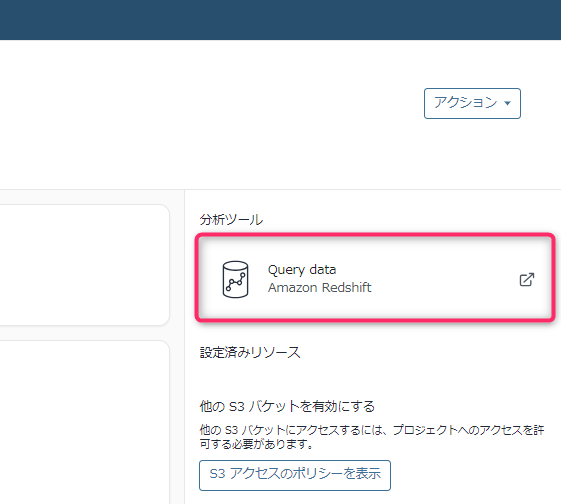
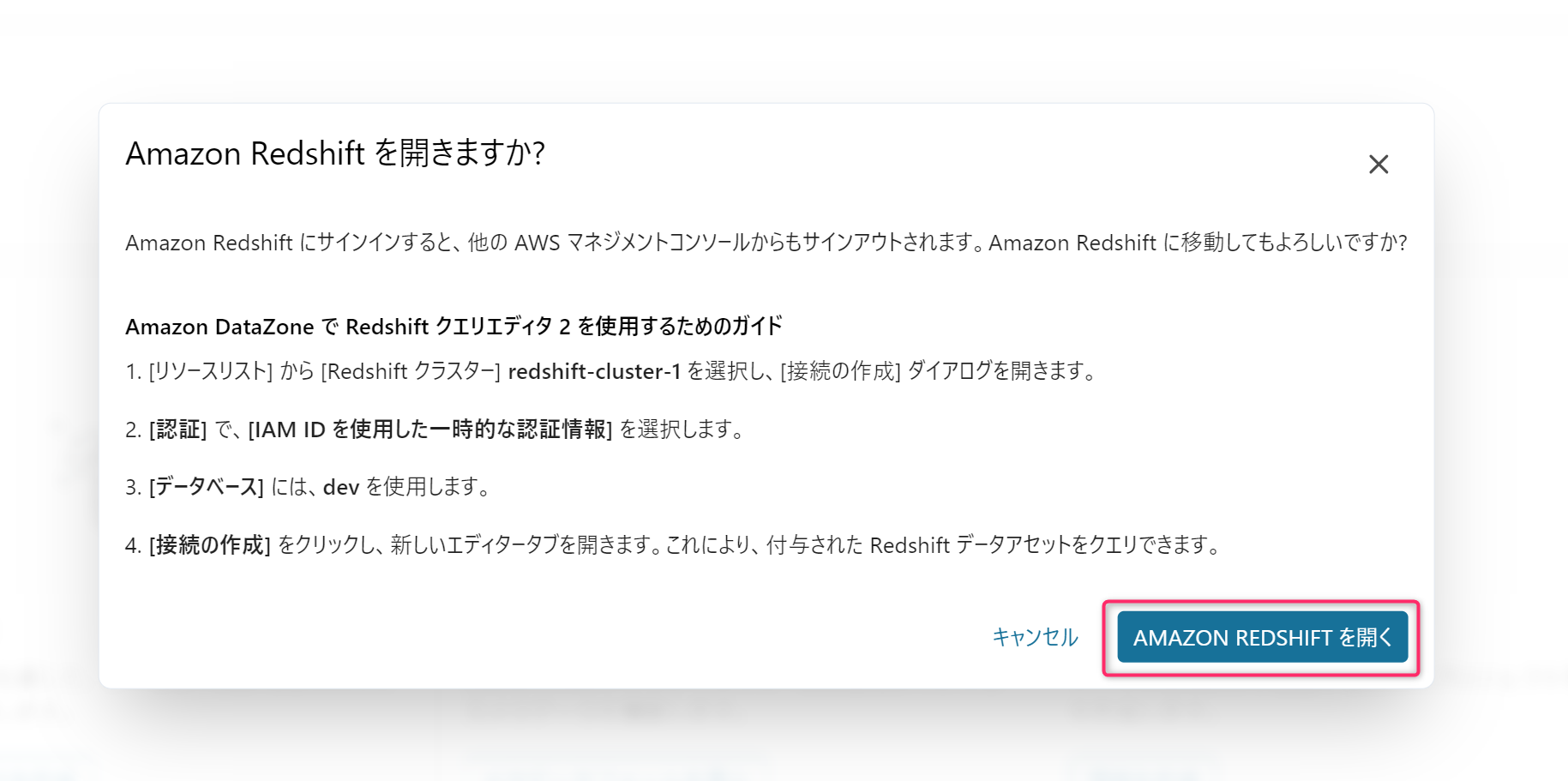
DataZoneからクエリエディタv2に認証させる方法が案内されます。「IAM IDを使用した一時的な認証情報」を選択するようです。このまま進みます。
するとこれまでのAWSマネジメントコンソールのセッションが切れ、Redshiftクエリエディタv2に切り替わります。また、画面右上をみると、先ほどログインしていたIAM/SSOユーザとは異なり、datazone専用のIAMロール「datazone_usr_」に切り替わっていることがわかります。
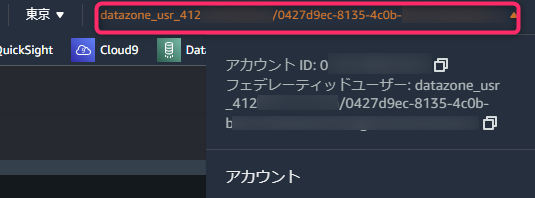
対象クラスタの右側にある三点リーダから「Create connection」または「Edit connection」を開きます。
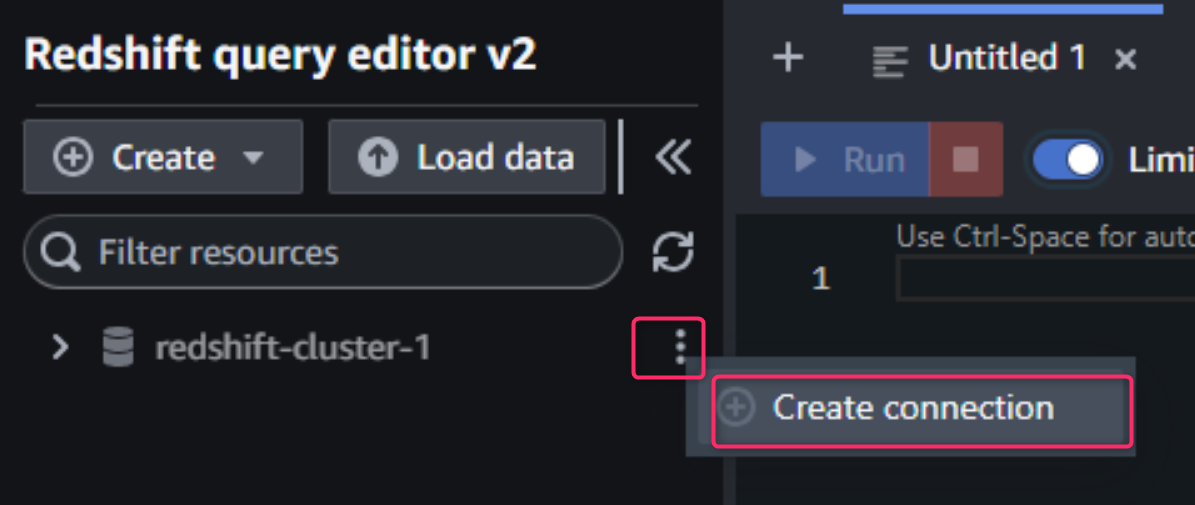
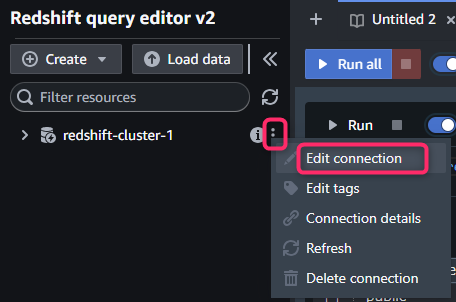
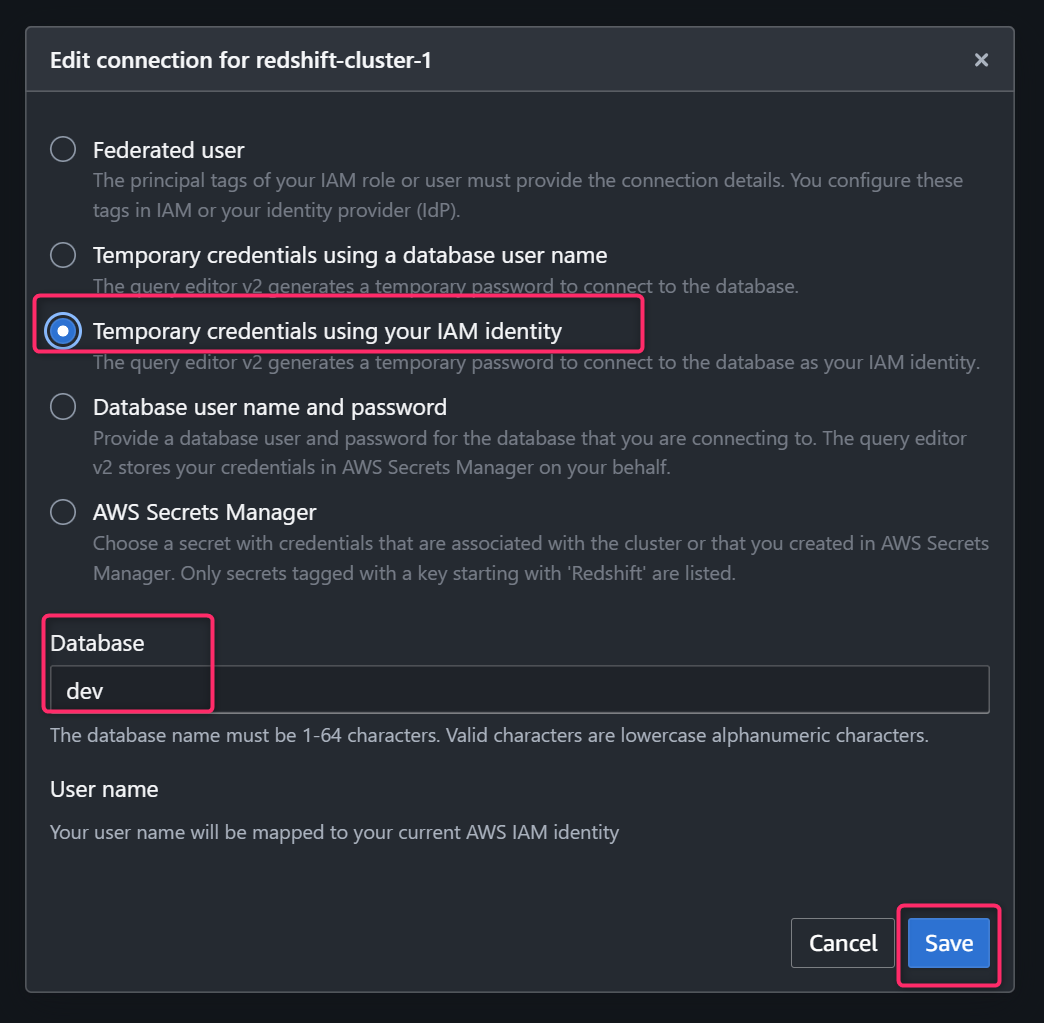
「Temporary credentials using your IAM identity」を選択し、先程の案内で表示されたデータベース名(ここでは「dev」)を入力し、「Save」でDBへのコネクションを確立します。
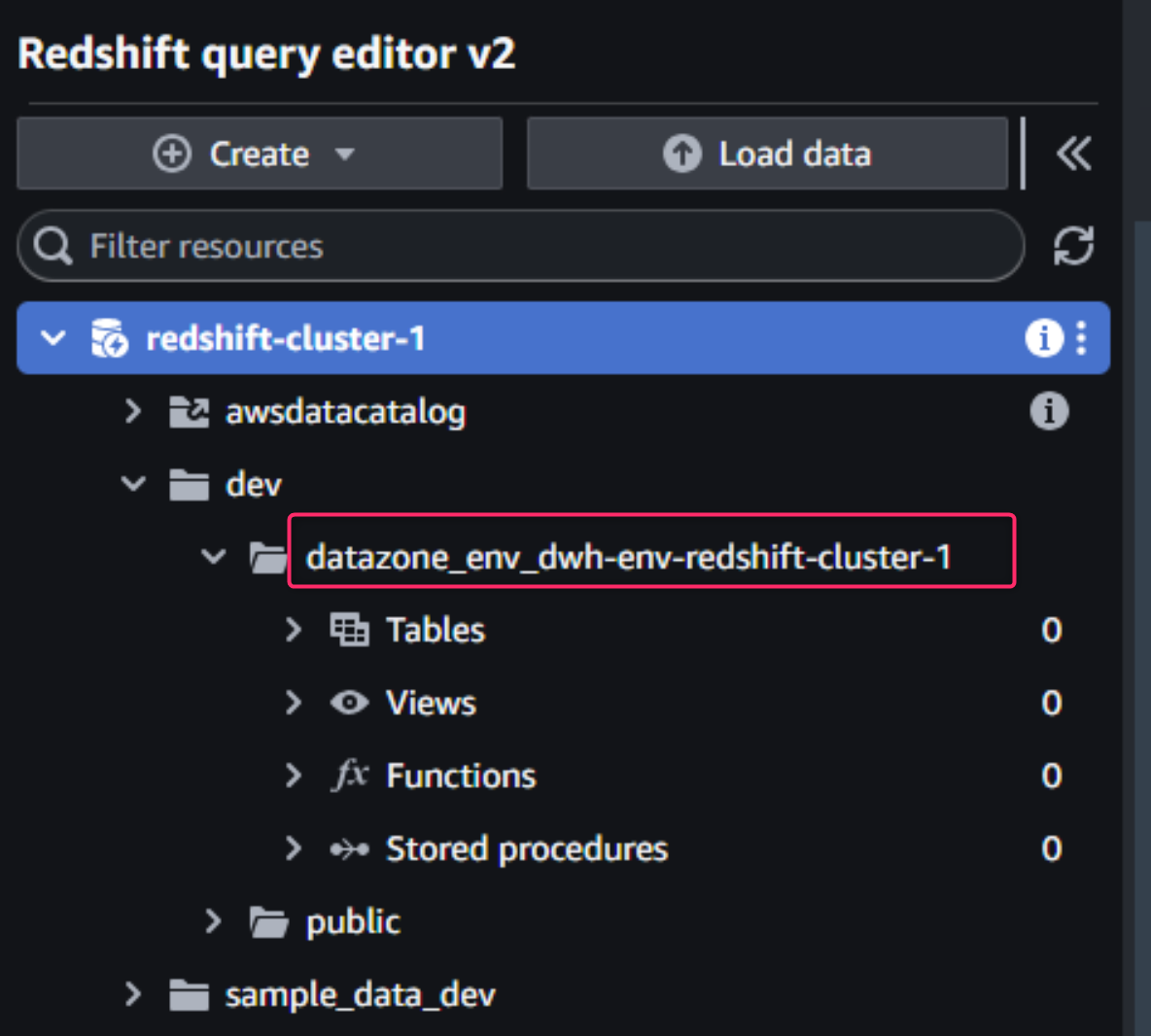
接続ができたら、クラスタ名とデータベース名をクリックしていきます。
- すると、「環境」作成と同時に用意されたDataZone専用のRedshiftスキーマが確認できます。
- 前述のとおり、このRedshiftスキーマは、オプションで自分で名前を指定しない場合は、以下の命名規則を持ちます。
- datazone_env_<環境名>_<複数の環境の場合、乱数>
- 前述のとおり、このRedshiftスキーマは、オプションで自分で名前を指定しない場合は、以下の命名規則を持ちます。
テスト用テーブルの作成
では、選択しているクラスタとデータベース名が正しいことを確認して、SQLを実行します。

スキーマ名を指定して、「mkt_sls_tables」というテーブルをCTASで作成します。
CREATE TABLE "datazone_env_dwh-env-redshift-cluster-1".mkt_sls_table AS
SELECT 146776932 AS ord_num, 23 AS sales_qty_sld, 23.4 AS wholesale_cost, 45.0 as lst_pr, 43.0 as sell_pr, 2.0 as disnt, 12 as ship_mode,13 as warehouse_id, 23 as item_id, 34 as ctlg_page, 232 as ship_cust_id, 4556 as bill_cust_id
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561
※なお、Redshiftのデフォルトでは、通常のユーザーには他のユーザーのデータを表示する許可がありません。(スーパーユーザを除く)
テーブル作成が完了したら、クエリエディタを閉じて、DataZone管理画面に戻ります。(以前のセッションが切れているので、マネジメントコンソールにログインし直す必要があります)
DataZone (設定)
データソースの作成
環境を作成しただけでは、いわばDBへの接続コネクタができあがったようなものなので、まだデータの中身まで見にいけていません。データの中身を見てテーブル情報をDataZoneのデータカタログに登録するには、「データソース」を用意し「実行」という、クローリングに相当する作業を実施する必要があります。
- 今回は、環境作成と同時にデータソースが自動作成されたためデータソースの新規作成は実施しません。
- 新規作成したり同一環境でデータを追加する場合は以下のような手順になります。
- 「データ」タブから「データソース」->「データソースを作成」を選択します。
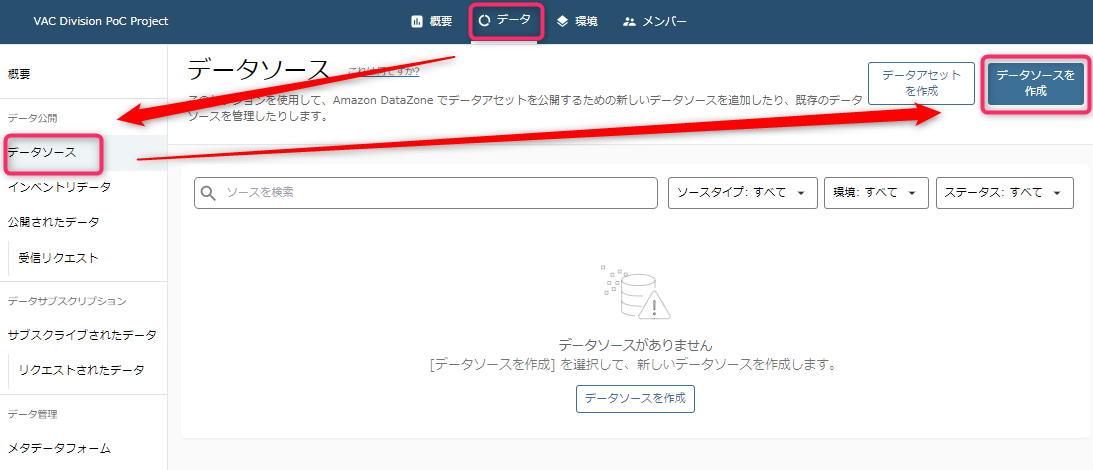
- データソースの作成画面は割愛します。環境作成後にデータソースを追加作成する場合は、Redshiftスキーマを任意に指定することができます。例えばRedshiftであればデフォルトで存在する「public」スキーマを指定することもできます。その場合、publicスキーマに存在する既存のテーブルが参照できます。
データソースの「実行」
「データ」タブから「データソース」 とたどり、作成済みのデータソースを選択します。
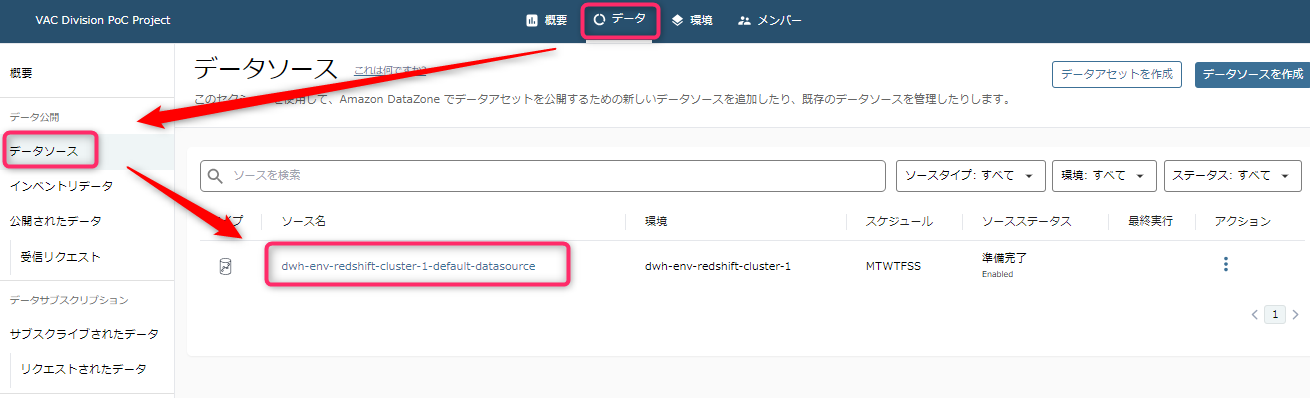
- まずはデータソースのスケジュールを見ます。
- 「環境」から自動構築されたデータソースは、自動的に定期的な「実行」スケジュールが設定されてしまっています。
- 「実行」によるクローリングのマシンパワーはコンピューティングの課金対象になるので、注意が必要です。
- データソースから「スケジュール」を選択すると全ての曜日(MTWTFSS)で、データソース作成時点で「実行(つまりクローラ)」がスケジューリングされています。ほとんどの場合で日時の編集やオンデマンド実行への変更が必要になると思います。
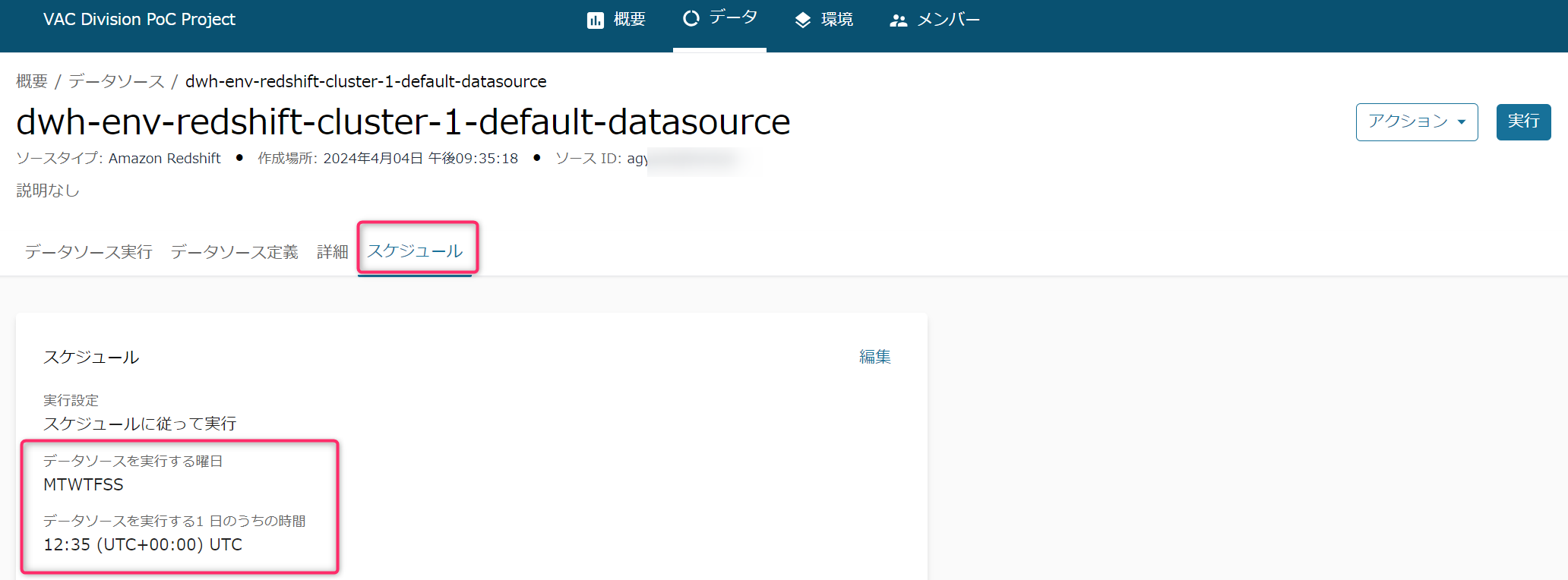
いったんここではオンデマンドに変更します。
スケジュールの「編集」ボタンより「オンデマンドで実行」を選択します。
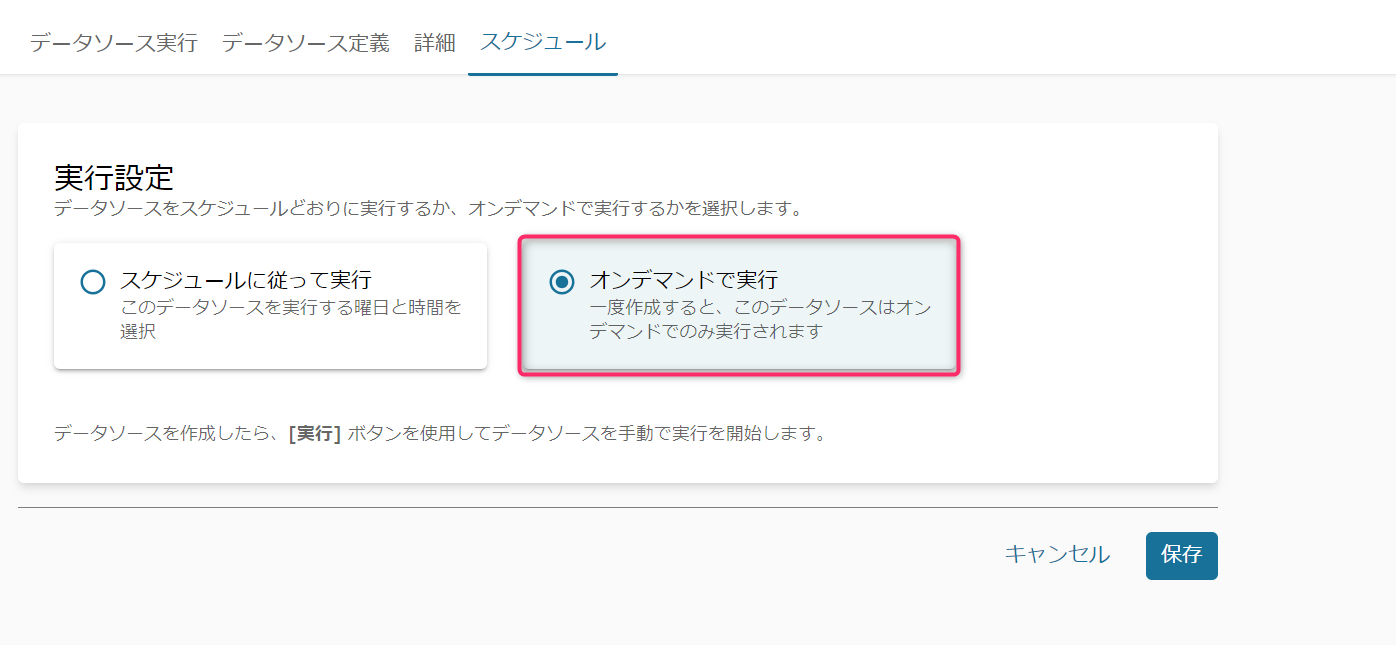
次に画面右上の「実行」ボタンを押して、Redshiftへのクローリングを開始します。正常完了すると画面左側にその旨表示されます。
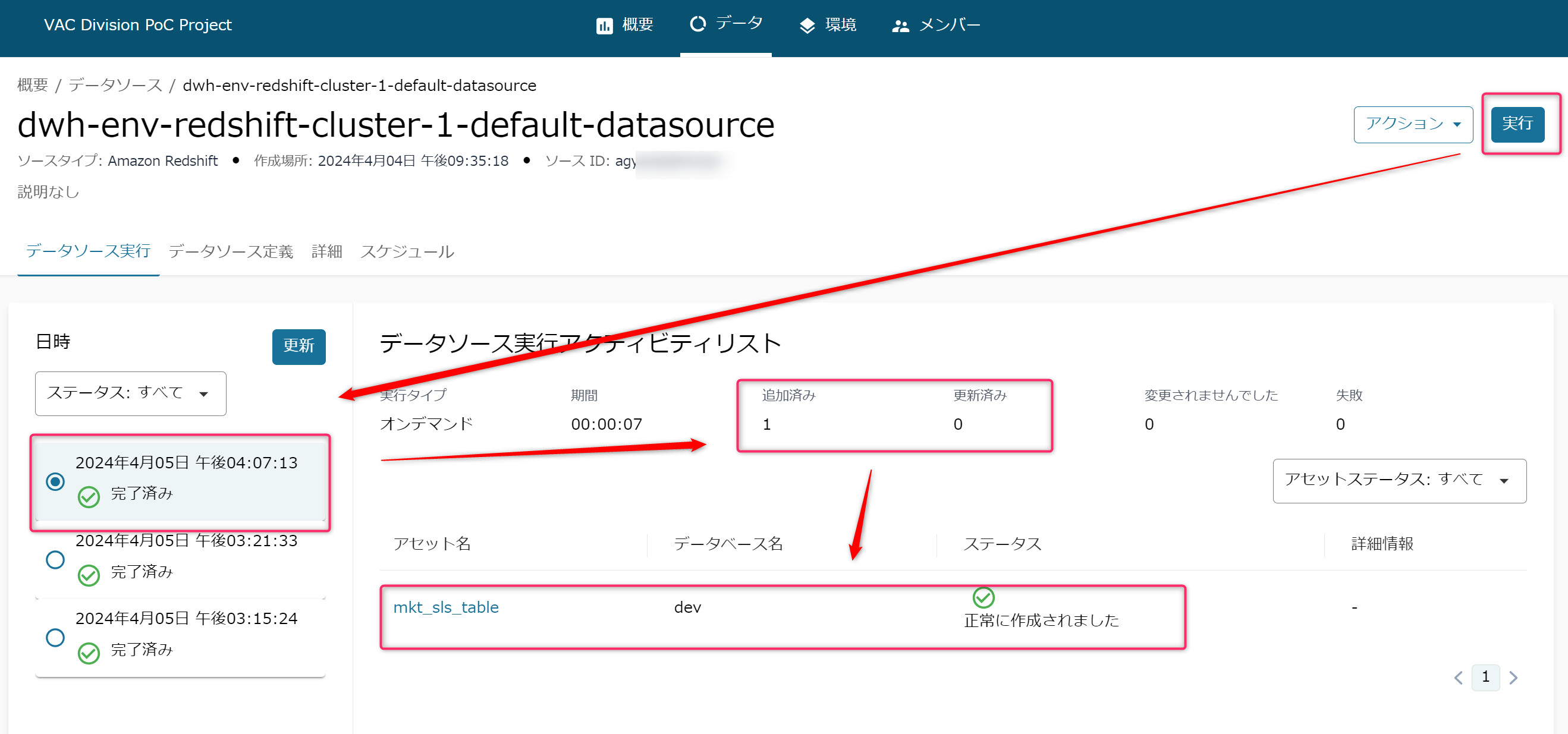
インベントリデータの確認
- ではDataZoneにメタデータ(※)が登録されているか確認していきます。
- ※テーブルのカラム名(いわゆるテクニカルメタデータ)やその解説など(いわゆるビジネスメタデータ)
- 自分が持っているメタデータは、まず「インベントリ」に登録されます。
- 「インベントリ」にあるアセット(メタデータ)は、DataZoneの同一プロジェクトのメンバーのみ確認が可能です。
- つまり「インベントリ」上にあるメタデータは、「自分たちプロジェクト関係者だけが内部で管理している状態」「プロジェクト外の人には存在すら認知されていない状態」のメタデータを指します。
- その後アセットを「公開」することにより、DataZoneドメインの他のプロジェクトメンバーがアセットを検索できるようになります。
「データ」-> 「インベントリデータ」 -> 「テーブル名」とクリックしていきます。
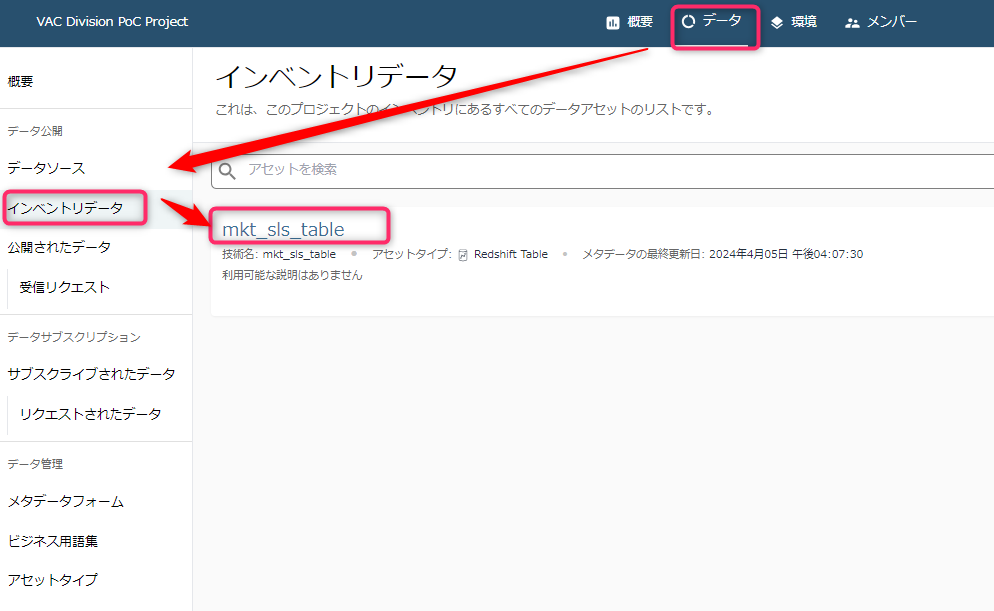
まずはテーブルの「ビジネスメタデータ」が表示されました。
データスチューワードや、データプロデューサーなど、データを管理・提供する側にいるユーザは、ここでREADMEや用語集などを整えて、利用者にわかりやすい説明を追加します。
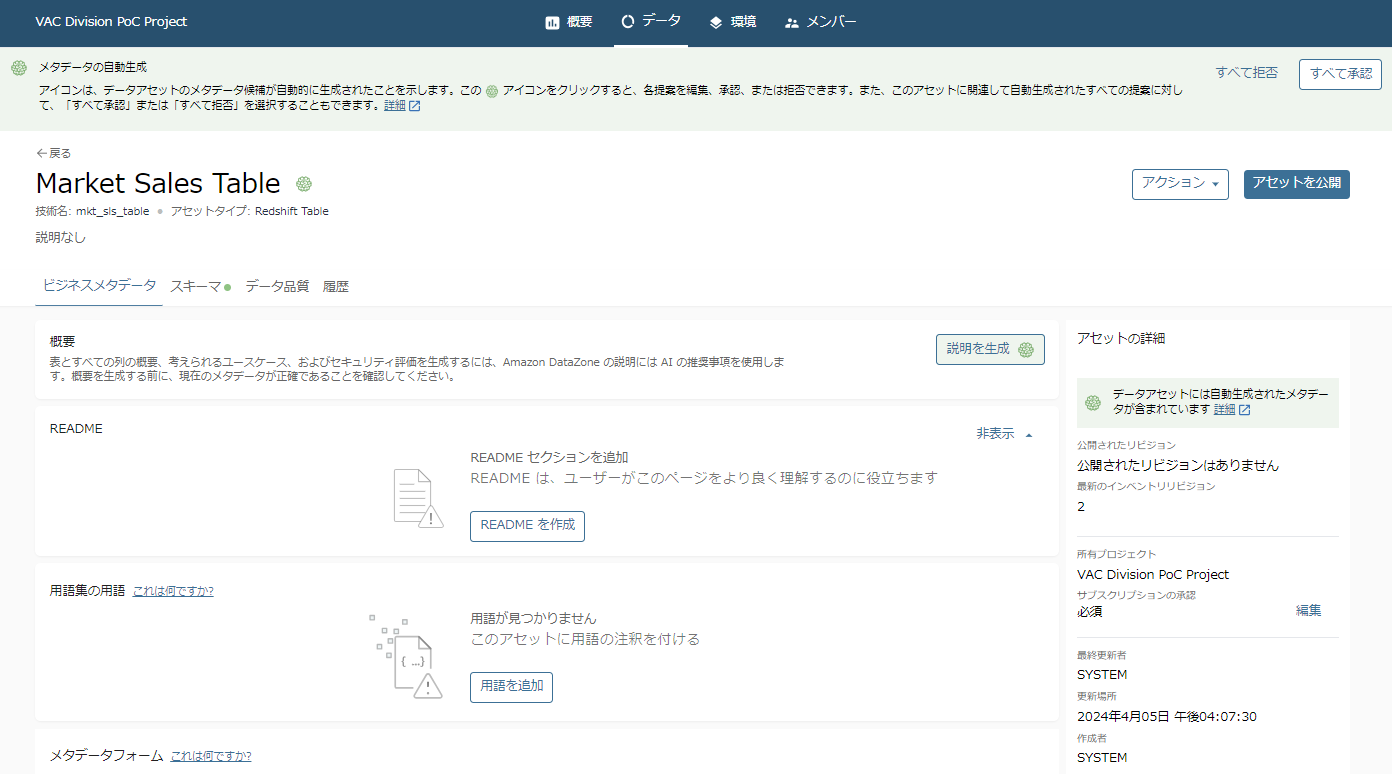
- ここで肉付けされた情報は、後ほど「公開(パブリッシュ)」後に他のプロジェクトから、「カタログ」上で参照できるようになります。そのため、基本的に同社の従業員が使いやすい単語を多用して登録するとよいと思います。
- 以下の資料に記載されている通り、「ビジネス用語集」や「メタデータフォーム」も検索時のサーチ対象になります。
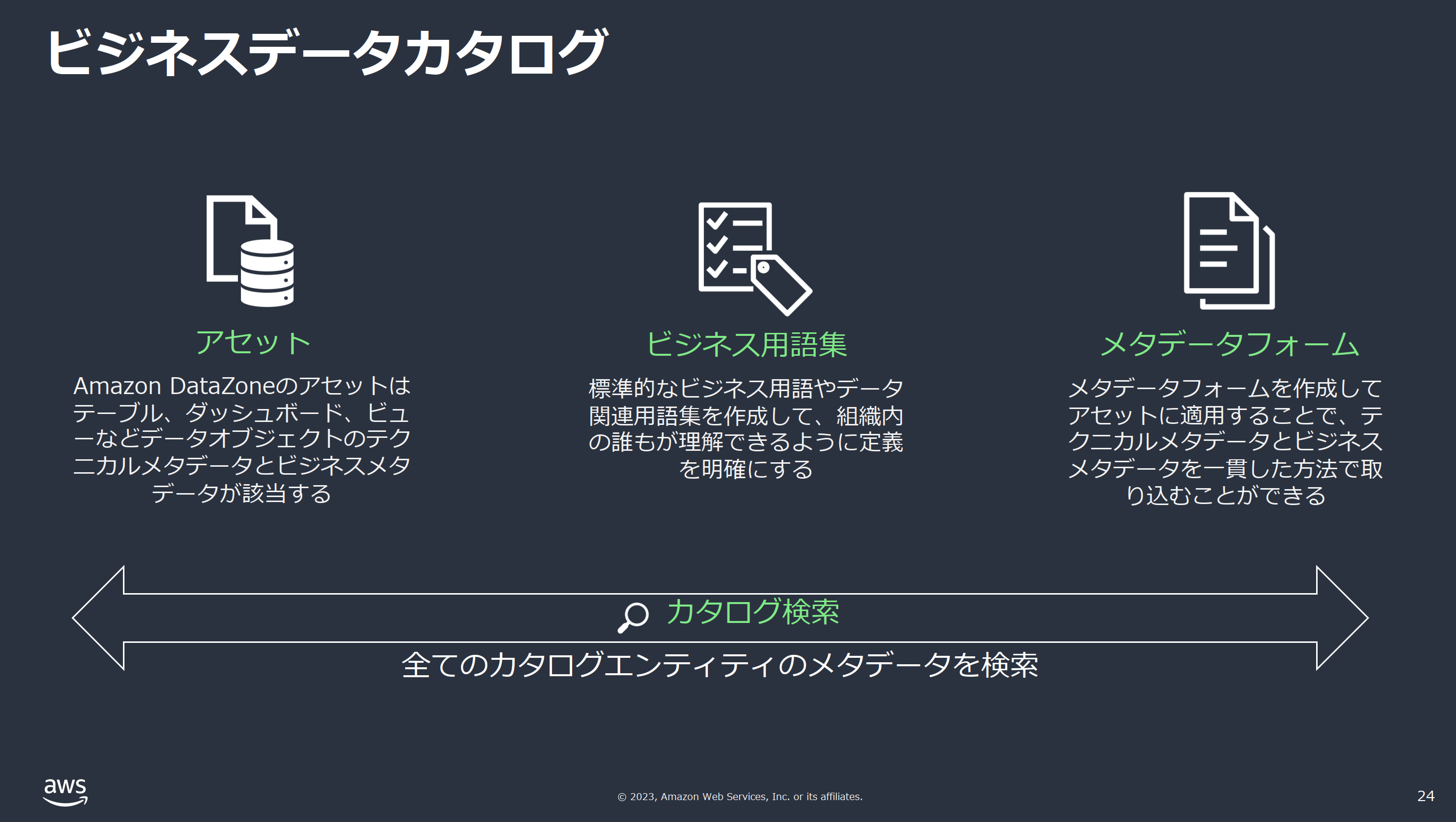
- 以下の資料に記載されている通り、「ビジネス用語集」や「メタデータフォーム」も検索時のサーチ対象になります。
なお、ここで「説明を生成」をクリックすると、
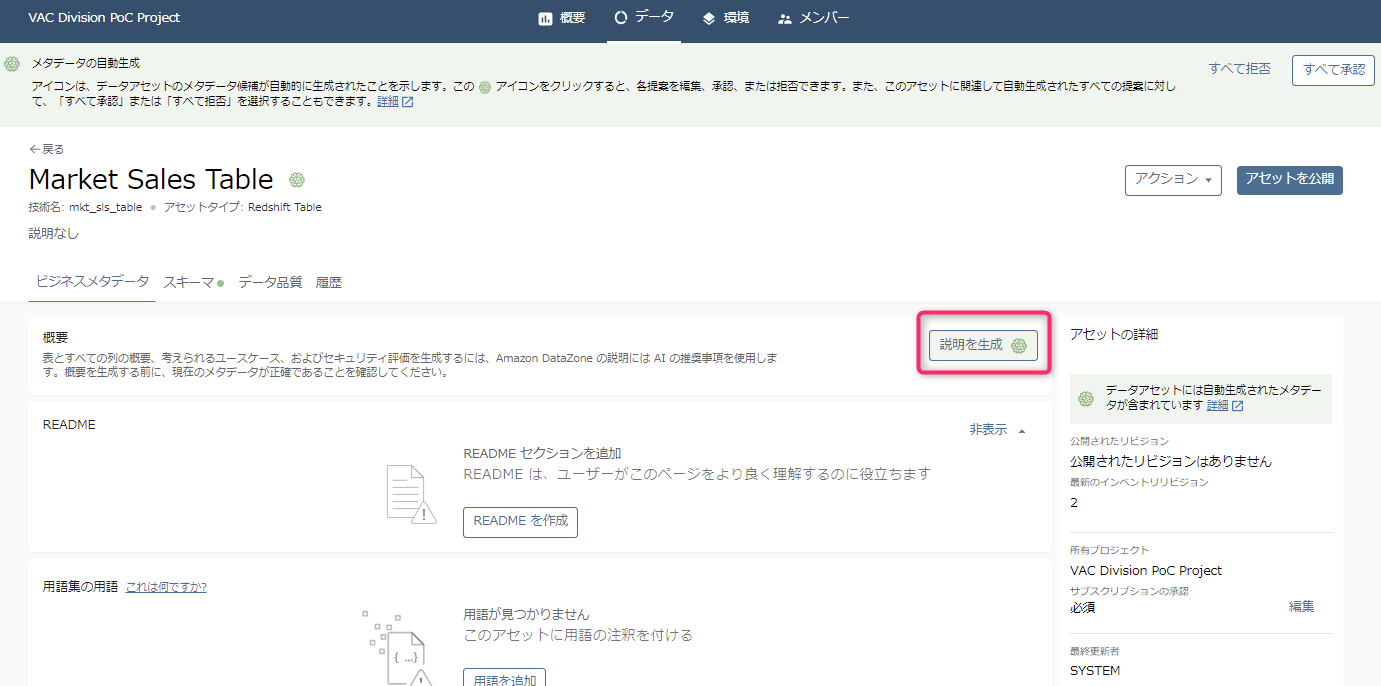
(私のシンプルなテーブルの場合)2分程度で「概要」欄にテーブルの概要とユースケースの文章がAIによって生成されます。

この生成AIの機能はAmazon Bedrockが利用されており、おそらくDataZoneの課金体系における「レコメンデーション」に相当するもので、課金対象と思われます。
- Google翻訳の結果は以下の通りです。
mkt_sls_table には、個々の製品の注文と販売取引に関する詳細データが含まれています。この小売販売データは、注文番号、製品 ID、販売数量、価格設定、割引、履行の詳細、顧客 ID などの主要な指標を追跡します。
ord_num は、注文ごとに一意の識別子を提供します。 sales_qty_sld は、注文ごとに販売された数量を取得します。注文された特定の製品を追跡する item_id と併用すると、製品レベルの販売量を分析できます。 Wholesale_cost 列と sell_pr 列は、企業の内部コストと最終販売価格および顧客に与えられた割引 (disnt) を比較することにより、製品レベルの収益性についての洞察を提供します。
価格データ (sell_pr、lst_pr、disnt) と ship_mode、warehouse_id などのフルフィルメントの詳細は、プロモーションやサプライ チェーンの意思決定に情報を提供し、マージンと物流コストのバランスをとることができます。顧客レベルの分析をサポートするために、出荷用 (ship_cust_id) と請求用 (bill_cust_id) の顧客 ID が含まれています。 ctlg_page は、マーケティング効果を測定するために、印刷物/デジタル カタログで製品が掲載されている場所を追跡します。
要約すると、このトランザクション レベルの販売データにより、製品の販売、価格設定、フルフィルメント、顧客分析が可能になり、小売環境におけるマージン、在庫、マーケティング キャンペーン、顧客エクスペリエンスを最適化できます。これを顧客、製品、倉庫などの他のテーブルと結合すると、小売業務の 360 度のビューを提供できます。
ユースケース
mkt_sls_table には、製品、価格設定、顧客、マーケティングなどにわたる小売業務を最適化するためのさまざまな分析を強化できる詳細な販売取引データが含まれています。
製品マネージャーは、item_id、sales_qty_sld、wholesale_cost 列を利用して販売量と製品レベルの収益性を分析し、価格設定、在庫、品揃えの決定を行うことができます。マーケティング担当者は、ctlg_page と販売データを活用して、カタログ キャンペーンのパフォーマンスを評価し、マーケティング支出を最適化できます。価格アナリストは、lst_pr、sell_pr、および disnt を使用して、製品ごとのプロモーションおよび値下げ戦略を通知できます。
注文データ (ord_num、sales_qty_sld) と顧客の配送 ID および請求 ID (ship_cust_id、bil_cust_id) を使用することで、顧客分析によりエクスペリエンスとロイヤルティを向上させることができます。フルフィルメント チームは、ship_mode、warehouse_id を使用して、物流ネットワークとコストを最適化できます。営業ディレクターは、チームまたはチャネルのパフォーマンスを追跡し、個々の注文の詳細から機会を特定できます。
要約すると、この取引レベルの販売データは、主要な小売業務全体にわたる統合分析を提供することで、小売企業の製品ポートフォリオ管理、価格設定の最適化、マーケティング アトリビューション、顧客維持、サプライ チェーンの効率化に役立ちます。これは、オムニチャネルと e コマースの両方の設定において、小売製品、マーケティング、販売、物流、財務の各チームに利益をもたらすでしょう。
-
画面上にある情報源がテーブル名やカラム名だけであるにも関わらず、分析の方法やテーブル結合まで示唆してくれます。
- なお以下の記事によると、ビジネス用語集やテーブル内のフィールドも参照している可能性があるとのことでしたので、生成AIによる概要作成に頼りたい場合は、あらかじめビジネスメタデータを一通り登録してから生成させるとよいかもしれません。
-
翻訳内容が問題なければ、「承認」ボタンで確定できます。
-
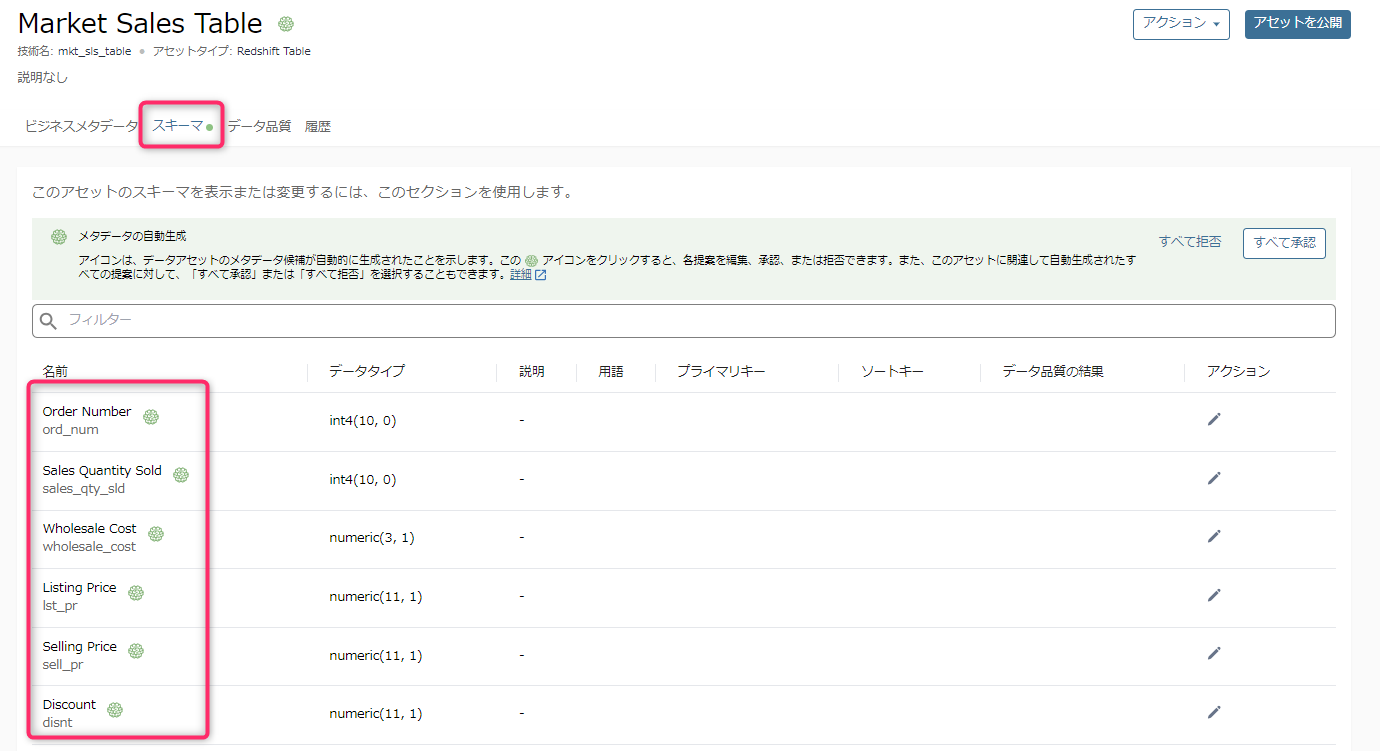
「スキーマ」タブをクリックすると、いわゆるテーブルのカラム情報(いわゆるテクニカルメタデータ)が表示されます。
- 緑色のアイコンがついているカラムはAIによって、カラム名などから自動で、人間が理解しやすい説明に変えてくれたものです。
- AIによるカラムの説明テキストは、私が見た限りではまだ精度がよくないので、一通り眺めて手直しして、場合によっては日本語で記載したほうがよいかもしれません。
- AIが生成したカラムのビジネス名を編集する場合は、緑アイコンで変更できます。
- カラムのビジネス名、長文の説明などは、行の「アクション」から編集ができます。
- 「アクション」の編集押下後は以下のように行ごとに詳しい説明を追加できます。
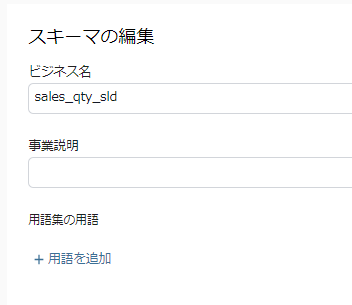
- 「アクション」の編集押下後は以下のように行ごとに詳しい説明を追加できます。
-
また、忘れがちですがテーブル名のように見えるテキストの右にも緑アイコンが出ているので、クリックして編集または承認を押しておきます。
- テーブル名のようにみえるこのテキストは「データアセットのビジネス名」とのことなので、ビジネス的にわかりやすい名称(日本語など)を指定しておくとよいと思います。
- なお下に小さく出ている「技術名」というのがデータベース上のテーブル名のようです。
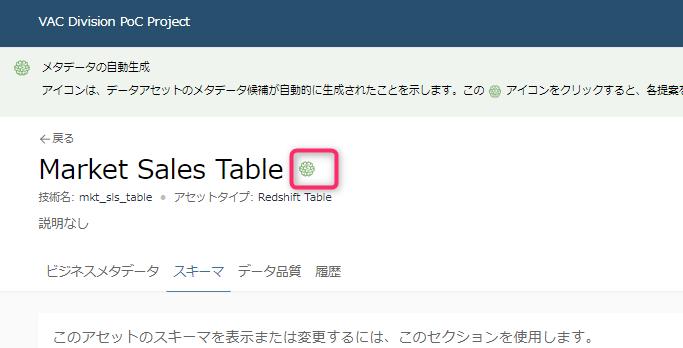
一通り承認すると、画面上部に出ていた緑色の警告(以下)が消えます。

画面右上の「アセットを公開」を押します。このとき、未承認のメタデータが残っていると、その部分は公開されないという警告がでます。以下の画面キャプチャは、すべて承認後のものです。
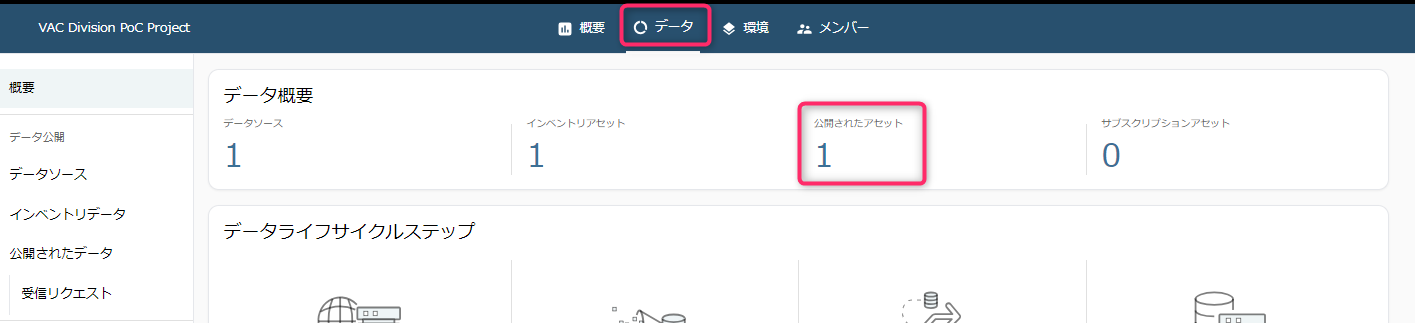
「データ」をクリックすると概要に「公開したアセット」が増えていることがわかります。
「メタデータフォーム」「ビジネス用語集」の使い方
-
ここまで見てきた「データアセット」は以下の資料をみるとよくわかります。
- 今回のように新規プロジェクトに単純にソースを新規追加した直後は、キャプチャ右側の「アセット」しか存在しない状態です。(出典)
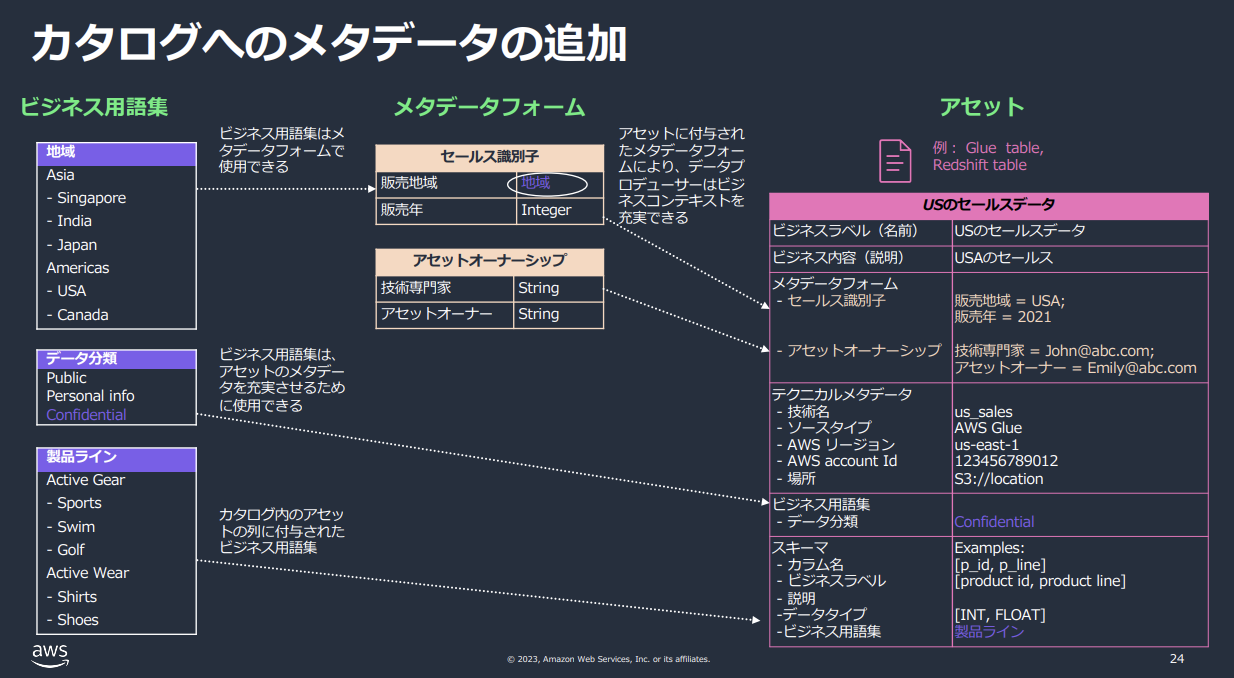
- 今回のように新規プロジェクトに単純にソースを新規追加した直後は、キャプチャ右側の「アセット」しか存在しない状態です。(出典)
-
では「メタデータフォーム」や「ビジネス用語集」はどのように使うものでしょうか。
- 一言でいえば、データを管理するうえでデータ提供者につけてもらいたい値のテンプレートのようなものです。
- たとえばデータ提供者に、一定のフォーマットで登録してもらいたいデータ(上図だとメタデータフォームの「セールス識別子」の「販売地域」など)は、データスチューワードがまず、先にビジネス用語集で地域のリストを作っておきます。
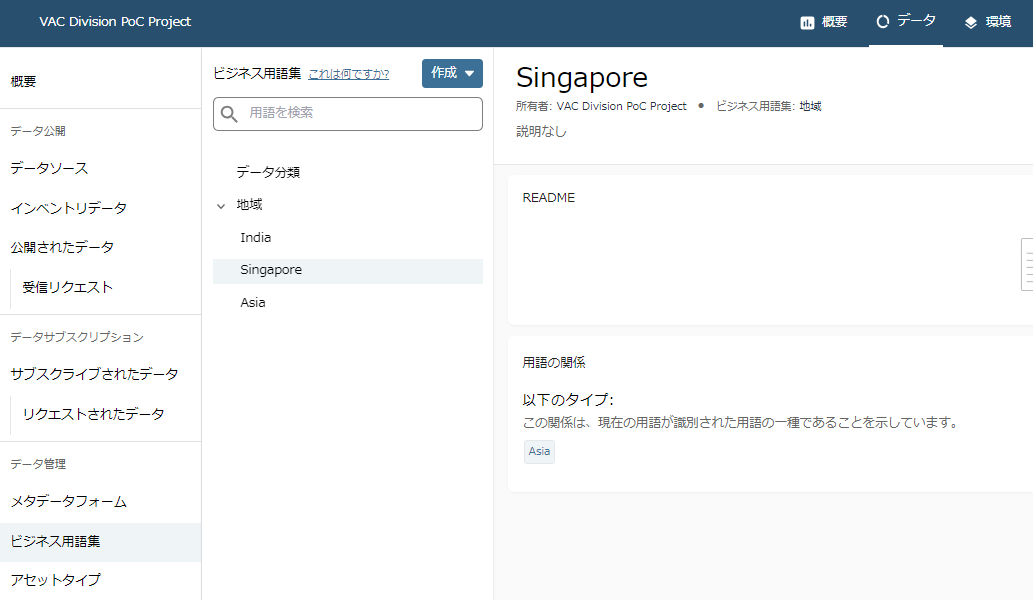
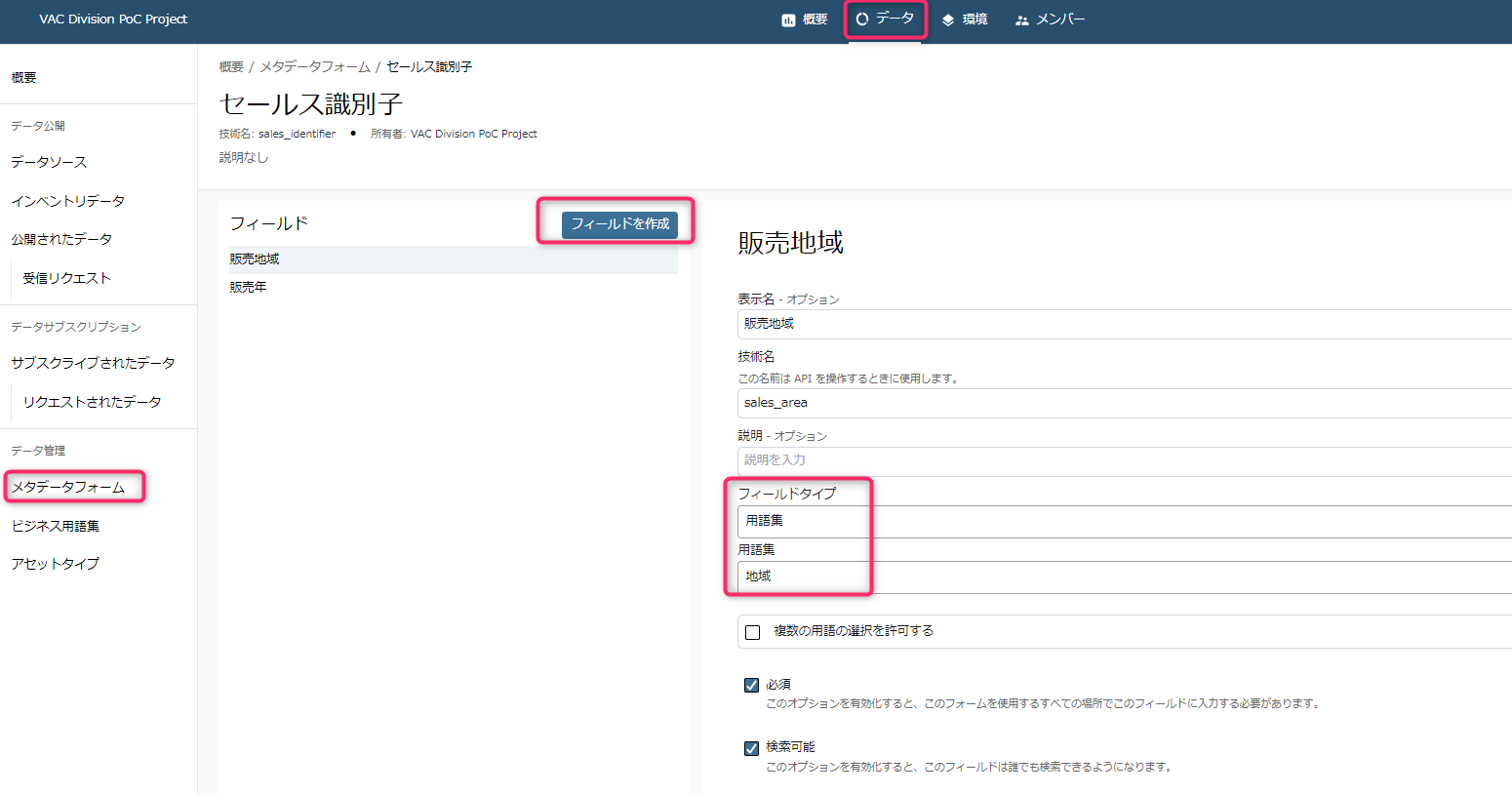
- データスチュワードはさらにメタデータフォームを作成し、「販売地域」のフィールドとして「用語集」として指定しておきます。
- データ提供者は「ビジネスメタデータ」画面の下部にある「メタデータフォームを追加」を押します。
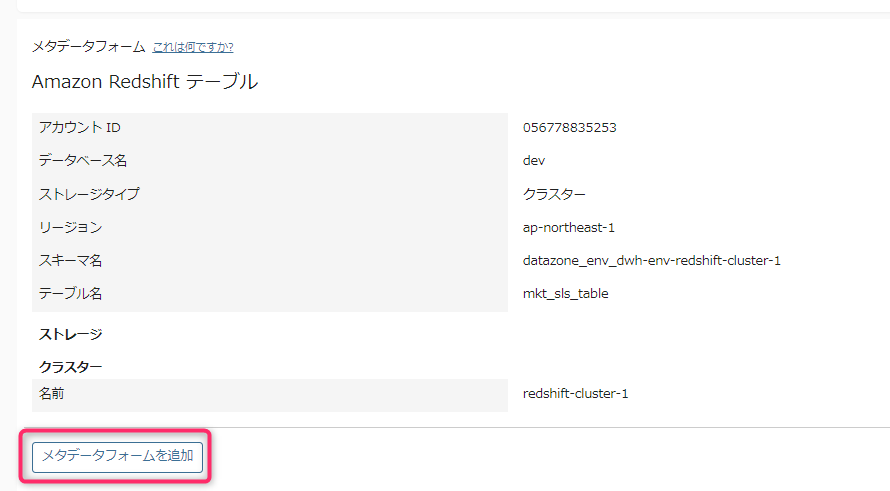
- データ提供者は表示される項目のリストボックスから地域を選ぶだけで、一貫性をもった名称の情報を付与することができ、表記のゆれやブレなどによる検索ミスなども防げます。
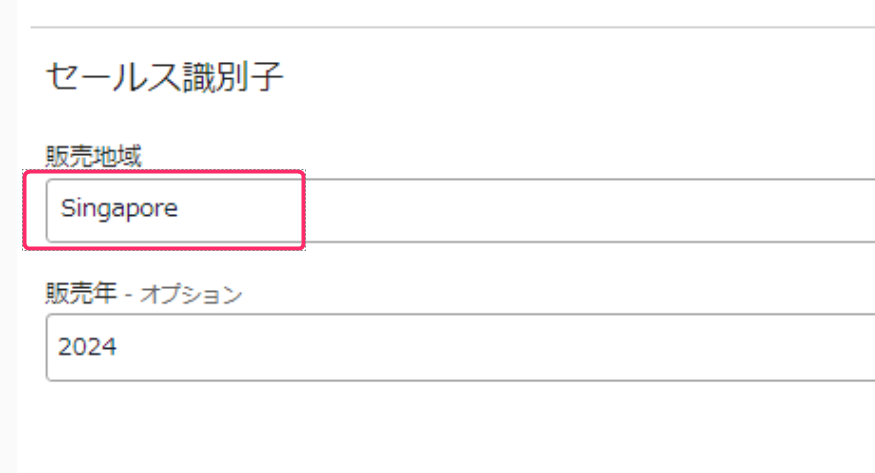
- データスチュワードはさらにメタデータフォームを作成し、「販売地域」のフィールドとして「用語集」として指定しておきます。
-
つまり、元のデータベース上のテーブルに存在しない情報を、DataZoneではメタデータとしてテーブル単位で情報を追加できます。
- メタデータ追加は手動にはなってしまいますが、データベース上のテーブルにカラムを追加することなく、ビジネスに活用できる情報を伝えることができるという点で、価値があります。
- これらの地道な作業はデータカタログとしての検索性の向上、組織を横断するデータ活用などを目的としています。つまりデータ提供者にとっては脳内の情報を明文化するという、ある意味苦痛を伴う作業であり、運用コストでもあります。
- メタデータの充実化には、やはりデータスチューワードのような専任を用意してデータ提供者に協力を継続的に働きかける必要がありますし、多くの場合データ提供者にはなんらかのインセンティブが必要になるはずです。
- サービスの今後の課題としては、DataZoneが各種データの利用率を計測できる簡易的なグラフやメトリクスの提供、またはプロジェクト内メンバーを勇気づけ利用促進させるような通知機能など、サービス拡充が期待されます。
メタデータを一通り編集・承認したら、今度はこれを他のプロジェクトから参照できるようにする必要があります。
インベントリデータの公開
「インベントリデータ」にある状態では、プロジェクトメンバーしかテーブルを確認することができません。
メタデータ確認後、「公開(パブリッシュ)」することで、やっとデータカタログとして他のプロジェクトメンバーにお披露目できます。
対象のインベントリデータを選択し、画面右上の「アセットを公開」を選びます。
未承認のメタデータがなければ、以下のような確認ダイアログがでます。
正常に公開されたら、「データ」タブをみると「公開されたアセット」が1つ増えていることがわかります。そのまま「公開されたデータ」メニュー、または「公開されたアセット」の数字をクリックします。
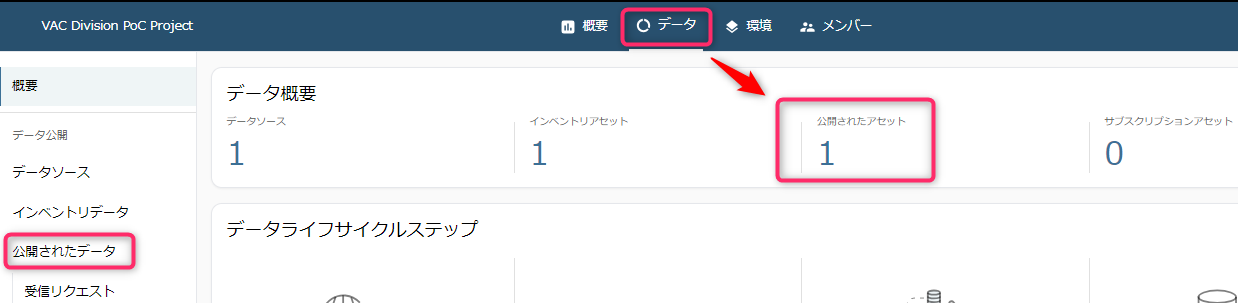
データが公開されたことが確認できました。
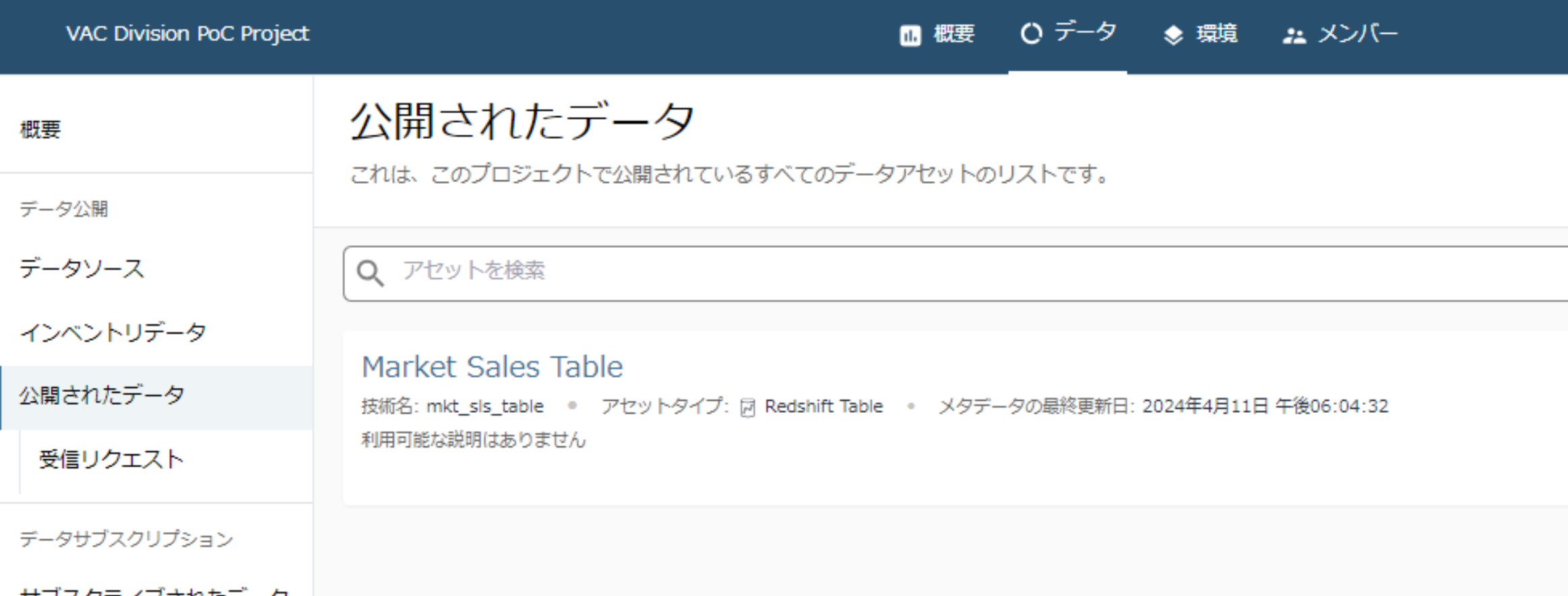
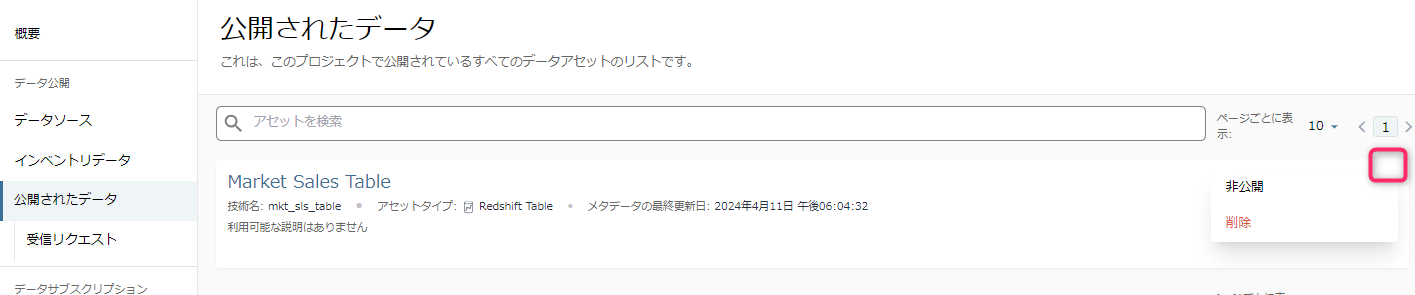
- なお、この公開データは非公開に戻すことができます。
- 公開データ一覧の、対象のデータの右にある三点リーダをクリックすると、非公開または削除が選択できます。
- ここで、「削除」をするとインベントリデータも消えてしまうため、注意してください。「非公開」を選択すれば、「インベントリデータ」に残り、「公開されたデータ」からは消える状態になります。
いったん本記事ではここまでとします。
DataZoneユーザによる実際のデータ利用方法については追って別記事で作成します。
おわりに
- 本記事ではDataZoneのデータソースにRedshiftのプロビジョンド版を登録する手順について説明してきました。
振り返り
- 本記事を振り返って。
- 全体的な印象
- 利用ユーザにとって最初の一歩が直感的に操作できない点に、やや問題があるように感じます。データソースを登録するために「環境」という概念を覚えなければならず、しかも「ブループリント」->「環境プロファイル」->「環境」という親子構造を頭に入れておく必要があり、最初の認知負荷的なハードルの高さがあります。
- 公式の情報の少なさ(2024年4月時点)
- 先述した「Redshfitデータベース内にDataZone専用スキーマが作成される」という点も、公式情報がほぼなく、なんのために使うものなのかわからず初見殺し感があります。
- データソースについて
- 現時点では残念ながらAWSサービスのDataWareHouse(Redshift)あるいはDataLake(Athena+Glue)しかブループリントが用意されていません。
- SQLクエリを書ける人には大きな恩恵がありますが、「Excelで社内のデータをちょっと参照したいだけなんだけど・・」という方には、データカタログ機能しか恩恵はないと思います。
- また、AWS外部のデータソースを参照するには、基本的にAppFlowなどでS3に連携したデータをDataLake(Athena+Glue)でアクセスするという、やや面倒なデータパイプラインの敷設が必要です。
- 現時点では残念ながらAWSサービスのDataWareHouse(Redshift)あるいはDataLake(Athena+Glue)しかブループリントが用意されていません。
- 全体的な印象
AWSへの要望
- AWSへの要望
- DataZoneが独自にAWS外部サービスへのコネクタを備えるようにしてほしい。
- ユーザ管理に大規模データメッシュ的なアーキテクチャを採用しているわりには、データソースが狭い。
- ユーザフレンドリな直感的な操作ができるようにしてほしい。
- とくに「環境」まわりの認知負荷を減らしてほしい。
- データのプレビューができるようにする、オプションでデータのダウンロードを可能にするなど、SQLベースではない手段を用意してほしい。
- DataZoneが独自にAWS外部サービスへのコネクタを備えるようにしてほしい。
私が考えるユースケース
- 私が考えるユースケース
- 本書執筆時点(2024年4月)では、以下のような条件すべてにあてはまるユーザであれば、利用に適しているような気がします。
- 利用しているデータソースが主にAWSサービスである。
- データソースが多く、一元管理が必要。
- エンタープライズ企業など、データ提供者・利用者が複数部署にまたがる。
- データカタログ利用者が、SQLスキルを持っている。
- 本書執筆時点(2024年4月)では、以下のような条件すべてにあてはまるユーザであれば、利用に適しているような気がします。
以上です。