はじめに
Rubyは毎年12月25日にアップデートされます。
Ruby 2.6については2018年12月6日にrc1がリリースされました。
この記事ではRuby 2.6で導入される変更点や新機能について、サンプルコード付きでできるだけわかりやすく紹介していきます。
2018.12.26追記: 内容を一部更新しました
2018年12月23日と、Ruby 2.6.0リリース後の2018年12月26日にそれぞれ内容を一部更新しました。
具体的な変更点は以下のdiffをご覧ください。
本記事の情報源
本記事は以下のような情報源をベースにして、記事を執筆しています。
- Ruby 2.6.0のリリースノート
- Ruby 2.6.0のNEWS
- リリースノートやNEWSに記載されている各種issue
また、issueを追いかけてもピンと来なかった内容については、ブログ「PB memo」のコミット解説を参考にさせてもらいました(nagachikaさん、どうもありがとうございます!)。
動作確認したRubyのバージョン
本記事は以下の環境で実行した結果を記載しています。
$ ruby -v
ruby 2.6.0rc1 (2018-12-06 trunk 66253) [x86_64-darwin18]
(2018.12.26追記)正式リリースされたRuby 2.6.0でも動作確認済みです。
$ ruby -v
ruby 2.6.0p0 (2018-12-25 revision 66547) [x86_64-darwin18]
動作確認用のコード
動作確認に使ったコードは以下のGitHubリポジトリに置いています。
フィードバックお待ちしています
本文の説明内容に間違いや不十分な点があった場合は、コメント欄や編集リクエスト等で指摘 or 修正をお願いします🙏
それでは以下が本編です!
言語仕様上の変更点
rescue節のないelse節がシンタックスエラーとして扱われるようになった
実験段階(experimental)の仕様変更点です。
例外処理を扱う構文として、begin/rescue/else/ensure/endがありますが、このうちbegin/else/endだけの組み合わせで例外処理を書くと、Ruby 2.6では構文エラーとして扱われるようになります。
begin
1 / 0
else
# do something
end
# => SyntaxError (else without rescue is useless)
とはいえ、エラーメッセージにもあるとおり、ほとんど意味がない(useless)コードなので、こんなコードを書く人はおそらく滅多にいないと思います。
キーワード引数のキーがシンボル以外だとエラーが発生するようになった
少しややこしいコード例ですが、Ruby 2.5では次のようなコードが実行可能になっていました。
# varargsは可変長引数、keywordsはoptionalなキーワード引数
def m(*varargs, **keywords)
puts "varargs: #{varargs}"
puts "keywords: #{keywords}"
end
# 次のようなシンボル以外のキーが含まれるハッシュを渡すと、
# ハッシュの要素が可変長引数とキーワード引数に分割される
m("a" => 1, b: 1)
# => varargs: [{"a"=>1}]
# keywords: {:b=>1}
Ruby 2.6ではキーワード引数のキーがシンボル以外だとエラーが発生します。
def m(*varargs, **keywords)
puts "varargs: #{varargs}"
puts "keywords: #{keywords}"
end
m("a" => 1, b: 1)
# => ArgumentError (non-symbol key in keyword arguments: "a")
とはいえ、begin/else/endの件と同様に、意図的にこのようなコードを書いていた人はほとんどいないんじゃないかと思います。
非アスキー文字の大文字が定数として扱われるようになった
Rubyは大文字で始まる識別子が定数として扱われます。
これまではアスキー文字(いわゆる英語のアルファベット)の大文字だけが定数として扱われてきましたが、Ruby 2.6ではキリル文字の大文字など、非アスキー文字の大文字でも定数と見なされます。
# МはアルファベットのMではなくキリル文字のМで、Ruby 2.6では
# 定数と見なされるため、クラス名として利用できる
class Мир
# ...
end
ブロック変数がブロック外の変数をシャドーイングしても警告が出なくなった
Ruby 2.5以前では以下のようなコードは警告が出ていました。
(注: あくまでシャドーイングの説明をするためのコードなので、コード自体に意味はありません)
a = [1]
# ブロック変数のaが、上で宣言したローカル変数aと同じ変数名であるため、
# シャドーイングが発生する(つまりブロック内からはローカル変数aにアクセスできない)
a.each do |a|
a = 3
end
# 上のコードを構文チェックすると警告が出力される
$ ruby -cw sample.rb
sample.rb:6: warning: shadowing outer local variable - a
Syntax OK
しかし、実際書くコードではシャドーイングが発生することを理解した上で、意図的にローカル変数と同じブロック変数名を付けることもよくある、ということで、Ruby 2.6からはこの警告は表示されなくなりました。
# Ruby 2.6では警告が出ない
$ ruby -cw sample.rb
Syntax OK
フリップフロップ構文を使うと警告が出るようになった
フリップフロップ構文(参考)はRuby 3.0で削除される予定になっています。
これにともない、Ruby 2.6からはフリップフロップ構文を使うと警告が出るようになりました。
numbers = 1..10
numbers.each do |n|
# フリップフロップ構文を使うと警告が出る
if (n % 3 == 0)..(n % 2 == 0)
puts n
end
end
# => warning: flip-flop is deprecated
# 3
# 4
# 6
# 9
# 10
2019.12.24追記:この変更はRuby 2.7で撤回されました
フリップフロップ構文はRuby 2.6で一度非推奨となりましたが、再びRuby 2.7で撤回され、今後も使用可能になりました。
The flip-flop syntax deprecation is reverted. [Feature #5400]
パフォーマンスに関する改善点
JIT (Just-in-time) コンパイラが導入された
実験段階(experimental)の変更点です。
Ruby 2.6ではJIT (Just-in-time) コンパイラが導入されました。
--jit オプションをコマンドライン、またはRUBYOPT環境変数で指定すると、JITコンパイラが有効になります。
# コマンドラインで--jitオプションを指定
$ ruby --jit test/ruby_test.rb
# 環境変数に--jitオプションを指定
$ RUBYOPT=--jit ruby test/ruby_test.rb
リリースノートによると、
Ruby 2.6.0の時点で、OptcarrotというCPU負荷中心のベンチマークにおいてRuby 2.5の約1.7倍の性能向上を達成しました。一方、Railsアプリケーションなどのメモリ負荷の高い環境における性能は現在改善中で、まだ性能向上が期待できる状態には達しておりません。詳細はRuby 2.6 JIT - Progress and Futureをご覧ください。
とのことです。
Proc#callやブロック引数のblock#callが速くなった
Ruby 2.6ではProc#callを呼び出したり、ブロック引数のProcオブジェクトに対してcallを呼び出したりしたときの実行速度が速くなりました。
# Proc#callを呼び出す
def proc_call pr
pr.call(1, 2, 3)
end
# ブロック引数に対してcallを呼び出す
def proc_bp_call &pr
pr.call(1, 2, 3)
end
Ruby Conf 2018の笹田さんの発表資料によると、前者が1.4倍、後者が2.62倍高速になったとのことです。

参考
- Feature #14318: Speedup `Proc#call` to mimic `yield`
- Bug #10212: MRI is not for lambda calculus
- Feature #14330: Speedup `block.call` where `block` is passed block parameter.
- Feature #14045: Lazy Proc allocation for block parameters
- http://www.atdot.net/~ko1/activities/2018_rubyconf2018.pdf
Transient Heapが導入され、寿命の短い配列やハッシュのパフォーマンスが向上した
Ruby 2.6ではTransient Heap(theap)の導入により、寿命の短い配列やハッシュのパフォーマンスが1.5倍から2.0倍程度向上しています。
(ハッシュの場合は要素数が8以下の場合にtheapが使われます)
以下のグラフはRuby Conf 2018の笹田さんの発表資料から引用したものです。

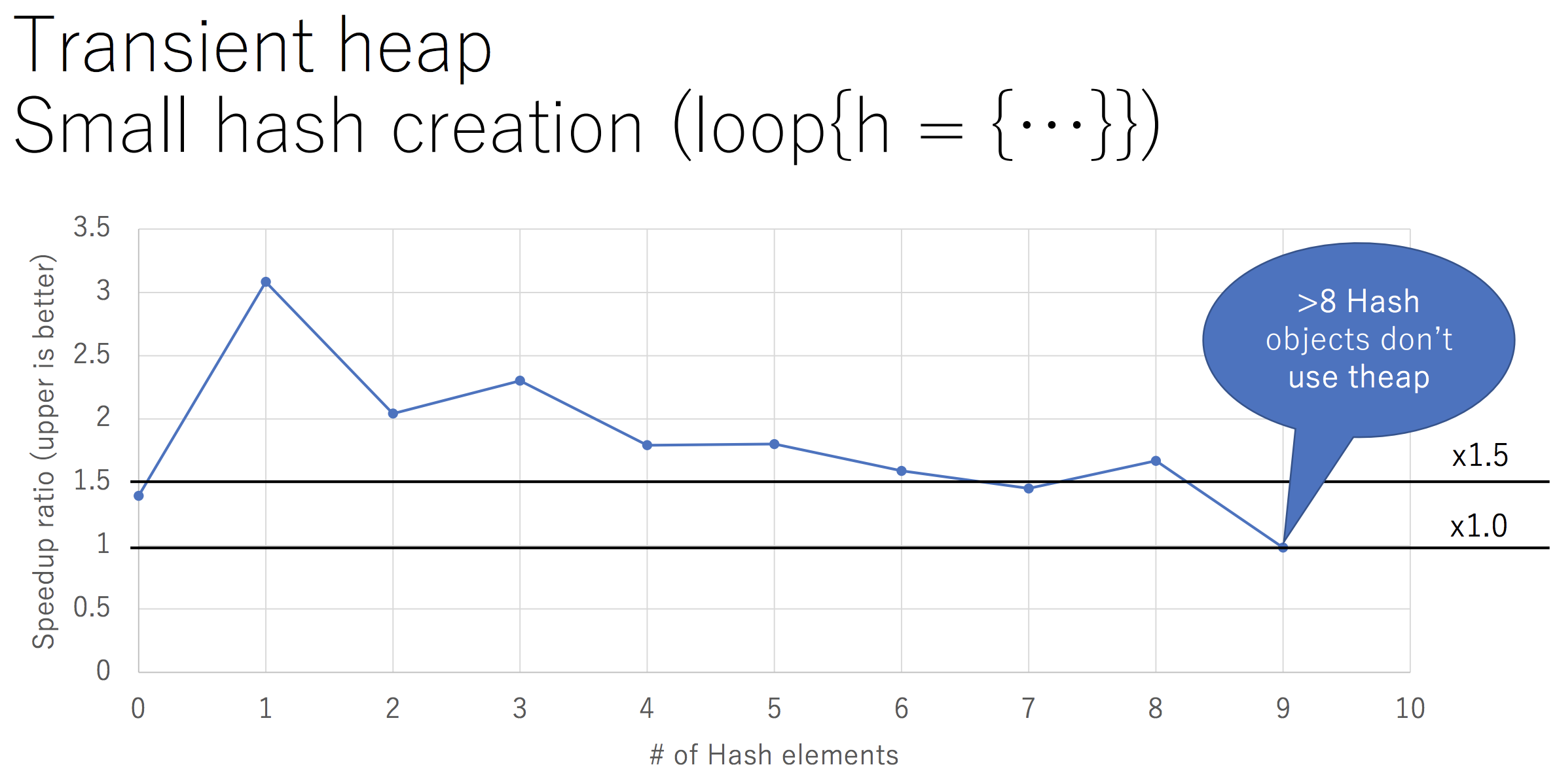
その他、theapの詳細や特性については以下のissueや発表資料を参考にしてください。
- 参考: Bug #14858: Introduce 2nd GC heap named Transient heap
- 参考: http://www.atdot.net/~ko1/activities/2018_rubyconf2018.pdf
Coroutineの実装がネイティブ化されたことにより、Fiberのパフォーマンスが向上した
Ruby 2.6ではcoroutineの実装がネイティブ化され、Fiberのパフォーマンスが大幅に向上しました。
こちらのブログ記事に載っていたグラフを見る限り、最大で5.7倍ぐらい速くなったみたいです。
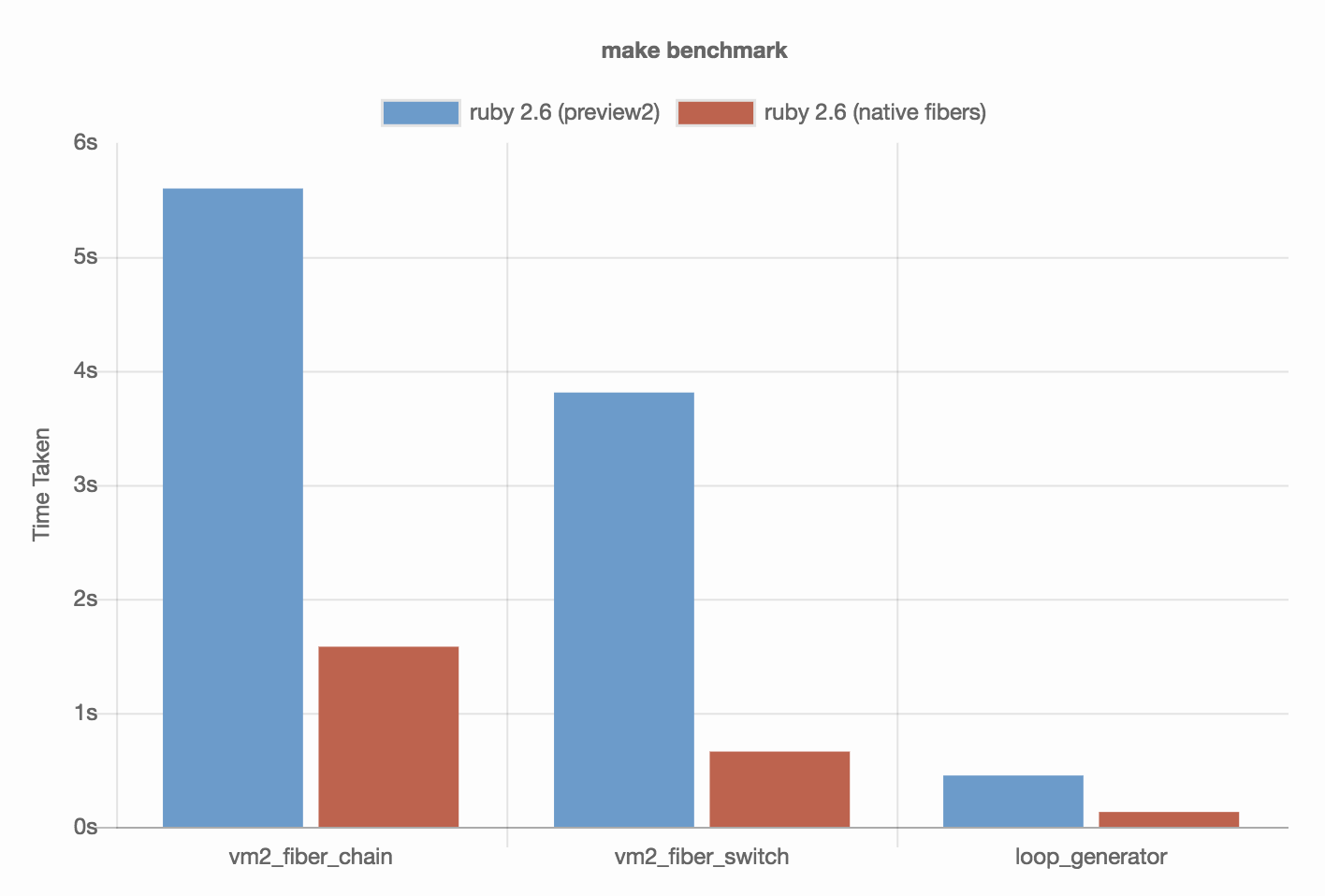 Image from https://www.codeotaku.com/journal/2018-06/improving-ruby-fibers/index
Image from https://www.codeotaku.com/journal/2018-06/improving-ruby-fibers/index
ただし、今回高速化されるのは以下のビルド環境に限定されます。
arm32, arm64, ppc64le, win32, win64, x86, amd64
Range(範囲)オブジェクトに関する新機能や変更点
終端を省略できるようになった
Ruby 2.6では範囲(Range)リテラルで、終端を省略できるようになりました。
a = [0, 1, 2]
a[1..] #=> 1, 2
a[1...] #=> 1, 2
"abcde"[2..] #=> "cde"
"abcde"[2...] #=> "cde"
ちなみに上のようなコードの場合、Ruby 2.5以前では終端に-1を指定することで同じことが実現できます。
a = [0, 1, 2]
a[1..-1] #=> 1, 2
"abcde"[2..-1] #=> "cde"
stepのエイリアスとして%が使えるようになった
RubyではRange#stepメソッドを使って、次のようなコードが書けます。
# 1から6まで、2つおきに要素を取得する
(1..6).step(2).to_a #=> [1, 3, 5]
Ruby 2.6では%をstepメソッドのエイリアスとして利用できます。
((1..6) % 2).to_a #=> [1, 3, 5]
Rangeの===が判定時にinclude?だけでなく、cover?も利用するようになった
後方互換性のない変更点です。
Ruby 2.5以前ではRangeの===はRange#include?メソッドでオブジェクトが範囲内に含まれているかどうかを判定していました。
Ruby 2.6では===を呼びだしたとき、Range#include?メソッドで判定不能だった場合はRange#cover?メソッドで範囲内かどうかをチェックするようになります。
これにより、オブジェクトが<=>メソッドさえ実装していれば===で比較できる(つまりcase文で使える)ようになります。
# <=>メソッドを実装したクラスを定義する
class MyClass
attr_reader :i
def initialize(i)
@i = i
end
def <=>(o)
i <=> o.i
end
end
range = MyClass.new(0)..MyClass.new(10)
# 始点が整数に変換できないのでinclude?はエラーになる
range.include?(MyClass.new(2))
# => TypeError (can't iterate from MyClass)
# MyClassは<=>を実装しているので、cover?で判定できる
range.cover?(MyClass.new(2))
# => true
# Ruby 2.5以前の場合
# 常にinclude?が使われるのでエラーになる
range === MyClass.new(2)
# => TypeError (can't iterate from MyClass)
# Ruby 2.6の場合
# include?が使えない場合はcover?で判定されるためエラーにならない
range === MyClass.new(2)
# => true
謝辞: Rubyのissueだけでは何がどう変わったのか理解しづらかったので、ブログ「PB memo」のコミット解説を参考にさせてもらいました。どうもありがとうございました!
Range#=== は Range#include? メソッドでチェックしていたのですが、rb_funcall() で実際にメソッド呼び出しはやめて range_include_internal() で include? 相当のチェックをしてみて、include? で判定不能だった時には cover? 相当の処理で判定するようにしています。 Range#include? は始点が整数に変換可能か、文字列かでないと処理できないのでこれ以外の要素による Range の時には <=> メソッドの大小関係のみで判定できる cover? のほうがより汎用的に使えるということのようです。
Range#cover?メソッドがRangeオブジェクト同士の範囲を比較できるようになった
後方互換性のない変更点です。
Ruby 2.6ではRange#cover?メソッドがRangeオブジェクト同士の範囲を比較できるようになりました。引数の範囲がレシーバの範囲内に収まっていればtrueになります。
# Ruby 2.5では常にfalse
(1..5).cover?(2..3) #=> false
(1..5).cover?(2..6) #=> false
(1..5).cover?(0..3) #=> false
# Ruby 2.6では引数がレシーバの範囲内に収まっていればtrue
(1..5).cover?(2..3) #=> true
(1..5).cover?(2..6) #=> false
(1..5).cover?(0..3) #=> false
ちなみに、include?や===を使った場合はRuby 2.6でも常にfalseになります。
# Ruby 2.5でも2.6でも常にfalse
(1..5).include?(2..3) #=> false
(1..5).include?(2..6) #=> false
(1..5).include?(0..3) #=> false
# Ruby 2.5でも2.6でも常にfalse
(1..5) === (2..3) #=> false
(1..5) === (2..6) #=> false
(1..5) === (0..3) #=> false
stepメソッドに関する変更点
ブロックなしのRange#stepとNumeric#stepがEnumerator::ArithmeticSequenceを返すようになった
後方互換性のない変更点です。
Ruby 2.6ではブロックなしのRange#stepとNumeric#stepがEnumerator::ArithmeticSequenceクラスのインスタンスを返すようになりました。
# Ruby 2.5以前
(1..3).step.class #=> Enumerator
2.step(5).class #=> Enumerator
# Ruby 2.6以降
(1..3).step.class #=> Enumerator::ArithmeticSequence
2.step(5).class #=> Enumerator::ArithmeticSequence
ちなみにEnumerator::ArithmeticSequenceはRuby 2.6から登場した新しいクラスで、Enumeratorのサブクラスです。
Enumerator::ArithmeticSequence.superclass #=> Enumerator
コレクション型のオブジェクト(配列、ハッシュ等)に関する新機能や変更点
to_hメソッドでブロックを受け取れるようになった
Ruby 2.6ではto_hメソッドがブロックを受け取れるようになりました。
ブロックの中で [キー, 値] となるような配列を返すと、それが要素になるハッシュが生成されます。
# シンボルに変換した名前をキーに、名前の長さを値にしたハッシュを生成する
['alice', 'bob', 'carol'].to_h { |name| [name.to_sym, name.size] }
# => { alice: 5, bob: 3, carol: 5 }
ブロックを受け取れるto_hメソッドは以下のクラス/モジュールに実装されています。
- Array
- Enumerable
- ENV
- Hash
- Struct
- OpenStruct
参考
select/select!のエイリアスメソッドとしてfilter/filter!が追加された
Ruby 2.6ではselect/select!のエイリアスメソッドとしてfilter/filter!が追加されました。
a = [1, 2, 3, 4, 5, 6]
# 3で割り切れる数値を抽出する(selectと同じ)
a.filter { |el| el % 3 == 0 }
# => [3, 6]
# filter!はレシーバ自身が変更される破壊的メソッド(select!と同じ)
a.filter! { |el| el % 3 == 0 }
# => [3, 6]
a #=> [3, 6]
filter/filter!メソッドは以下のクラス/モジュールに追加されています。
- Array
- Enumerable
- Enumerator::Lazy
- Hash
- Struct
- Set
issueによるとfilterが追加された理由は、他の言語ではselectではなくfilterと呼ばれることが多く、他の言語からRubyにやってきた人が迷わないようにするため、とのことです。
繰り返し可能なオブジェクトを連鎖できるEnumerable#chain、Enumerator#+
Ruby 2.6ではEnumerable#chainやEnumerator#+を使って、繰り返し可能なオブジェクトを連鎖できるようになりました。
# Enumerable#chainで他の配列やRangeと連鎖させる
e = (1..3).chain([4, 5], (6..8))
e.to_a
# => [1, 2, 3, 4, 5, 6, 7, 8]
# Enumerator#+で他の配列やRangeと連鎖させる
e = (1..3).each + [4, 5] + (6..8)
e.to_a
# => [1, 2, 3, 4, 5, 6, 7, 8]
Enumerable#chainやEnumerator#+の戻り値は、Enumerator::Chainクラス(Ruby 2.6から導入された新しいクラス)のインスタンスです。
Enumerator::ChainはEnumeratorのサブクラスで、繰り返し可能なオブジェクトを連鎖させ、1つの繰り返しオブジェクトとして扱います。
e = (1..3).chain([4, 5], (6..8))
e.class
# => Enumerator::Chain
Enumerator::Chain.superclass
# => Enumerator
配列に関する新機能や変更点
和集合と差集合を返すunion/differenceメソッド
Ruby 2.6では2つの配列の和集合と差集合を返すunion/differenceメソッドが追加されました。
これはこれまで|や-演算子で実現していた機能と同じですが、複数の引数を同時に取れるメリットがあります。
a = [1, 2, 3]
b = [3, 4, 5]
c = [4, 5, 6]
# a | bと同じ
a.union(b)
# => [1, 2, 3, 4, 5]
# a | b | cと同じ
a.union(b, c)
# => [1, 2, 3, 4, 5, 6]
a = [1, 2, 3, 4, 5]
b = [0, 1, 2]
c = [5, 6, 7]
# a - bと同じ
a.difference(b)
# => [3, 4, 5]
# a - b - cと同じ
a.difference(b, c)
# => [3, 4]
ハッシュに関する新機能や変更点
merge/merge!/updateメソッドに複数のハッシュを渡せるようになった
これまでmerge/merge!/updateメソッドの引数は1つだけでしたが、Ruby 2.6では複数のハッシュを渡せるようになりました。
ちなみに、updateはmerge!のエイリアスメソッドです。
a = { a: 1 }
b = { b: 2 }
c = { c: 3 }
# aに2つのハッシュをマージする(非破壊的)
a.merge(b, c)
# => { a: 1, b: 2, c: 3 }
# aに2つのハッシュをマージする(破壊的)
a.merge!(b, c)
# => { a: 1, b: 2, c: 3 }
a #=> { a: 1, b: 2, c: 3 }
参考
- Feature #15111: Make the number of arguments of `Hash#merge` variable
- C言語わからないマンでもRuby2.6に新機能を追加できた話 - Qiita
文字列に関する新機能や変更点
splitメソッドがブロックを受け取れるようになった
Ruby 2.6ではString#splitメソッドがブロックを受け取れるようになりました。
ブロック引数には分割された部分文字列が順に渡されます。
s = "1,2,3,4,5"
s.split(',') { |el| puts el.to_i * 10 }
# => 10
# 20
# 30
# 40
# 50
ちなみに、ブロックを使った場合、splitメソッド自身の戻り値は元の文字列になります。
s = "1,2,3,4,5"
# ブロックを使った場合、splitメソッドの戻り値は元の文字列になる
# (ブロック内の処理は無関係)
ret = s.split(',') { |el| el.to_i * 10 }
ret #=> "1,2,3,4,5"
ランダムなバイト文字列を返すRandom.bytes
Ruby 2.6ではランダムなバイト文字列を返すRandom.bytesが追加されました。
Random.bytes(1)
# => "\xBD"
Random.bytes(3)
# => "\x9A\xEE\x06"
サポートされるUnicodeバージョンが11になった
Ruby 2.6ではサポートされるUnicodeバージョンが11になりました。
今後のTEENYリリースで、12、そして12.1への更新が予定されているとのことです。
- 参照: リリースノート
Objectクラスに関する変更点
Object#=~を使うと警告が出るようになった
'gooooogle' =~ /goo+gle/のように、正規表現のマッチ判定でよく使われる=~演算子ですが、実はこの演算子はObjectクラスに定義されています(知らなかった!)。
しかし、文字列や正規表現以外のオブジェクトを左辺に置いて=~で比較しても、nilが返るだけであまり役に立ちません。
['foo'] =~ /foo/ #=> nil
役に立たないだけでなく、むしろ予期しない不具合の原因となるので、Object#=~は将来的に削除されることになりました。
その前準備として、Ruby 2.6ではObject#=~が使われているコードを-Wオプション付きで実行した場合に警告が出るようになっています。
# ['foo'] =~ /foo/のようなコードが含まれるスクリプトを実行すると警告が出る
$ ruby -W sample.rb
sample.rb:1: warning: deprecated Object#=~ is called on Array; it always returns nil
警告が出ないのは文字列や正規表現、nilなど、明示的に=~を実装している場合だけです。
(nilの=~は互換性維持のためにRuby 2.6から明示的に実装されました。)
# 警告が出ないのは文字列と正規表現とnil
# (nil =~ something は常にnilを返す)
'foo' =~ /foo/
/foo/ =~ 'foo'
nil =~ /foo/
!~は多くの場合、=~に処理を委譲しているので、!~を使った場合も同じように警告が出力されます。
# !~も警告が出る
['foo'] !~ /foo/
# => warning: Object#=~ is deprecated; it always returns nil
ですが、Object#!~は=~を実装しているクラスが処理を委譲するために利用されるため、今後も削除される予定はないそうです。
Kernelモジュールに関する新機能や変更点
yield_selfのエイリアスメソッドとしてthenが追加された
Ruby 2.5で追加されたKernel#yield_selfのエイリアスメソッドとして、Ruby 2.6ではKernel#thenが追加されています。
yield_self/thenは、レシーバがブロックの引数になり、ブロックの結果がそのまま戻り値になるメソッドです。
# 文字列を大文字にし、それから逆順にする
"Hello, world!".then(&:upcase).then(&:reverse)
# => "!DLROW ,OLLEH"
issueを見ていると、yield_selfという名前がしっくりきていない人が多いらしく、then以外にもいろいろと代替案が出ていました。
Kernel#Integer等の数値変換メソッドに:exceptionオプションが追加された
RubyにはKernel#Integerのように、渡されたオブジェクトを数値に変換するメソッドがあります(大文字で始まっていますが、これはメソッドです)。
# Integerメソッドを使って整数値に変換する
Integer(10) #=> 10
Integer("20") #=> 20
数値に変換できなかった場合はこれまで必ず例外が発生していましたが、Ruby 2.6では:exceptionオプションを使って、例外発生の有無を選択できるようになりました。
# Ruby 2.5までは変換に失敗すると例外が発生していた
Integer("abc")
# => ArgumentError (invalid value for Integer(): "abc")
# Ruby 2.6では:exceptionオプションで例外の発生を制御できるようになった
Integer("abc", exception: false)
# => nil
:exceptionオプションは以下のメソッドに追加されています。
- Kernel#Complex
- Kernel#Float
- Kernel#Integer
- Kernel#Rational
また、(組み込みライブラリではない)標準ライブラリのBigDecimalも同じように:exceptionオプションが追加されています。
require 'bigdecimal'
BigDecimal('a')
# => ArgumentError (invalid value for BigDecimal(): "a")
BigDecimal('a', exception: false)
# => nil
Kernel#systemメソッドに:exceptionオプションが追加された
これまでKernel#systemメソッドを使ってシステムコマンドを実行して失敗した場合はnilが返ってきていました。
# システムコマンドの実行に成功した場合
system 'which ruby'
# => true
# システムコマンドの実行に失敗した場合
system 'whichh ruby'
# => nil
Ruby 2.6では:exceptionオプションが追加され、失敗時に例外を発生させることができます。
# :exceptionオプションを指定して、コマンドの実行失敗時に例外を発生させる
system 'whichh ruby', exception: true
# => Errno::ENOENT (No such file or directory - whichh)
ProcやMethodオブジェクトに関する新機能や変更点
関数を合成する>>メソッドと<<メソッド
Ruby 2.6ではProcやMethodオブジェクトに合成した関数を返す>>メソッドと<<メソッドが追加されました。
以下はProc#>>を使うコード例です。
# テキストを行ごとに分割する関数
f_split_lines = -> (str) { str.split("\n") }
# 配列をソートする関数
f_sort = -> (elements) { elements.sort }
# 配列の各要素を改行文字で連結する関数
f_join = -> (elements) { elements.join("\n") }
# Proc#>>メソッドを使って関数を合成する
f = f_split_lines >> f_sort >> f_join
# ランダムに人名が並んだテキストを用意
text = <<TEXT
carol
dave
bob
ellen
alice
TEXT
# 上で合成した関数を使って、テキストの行を並び替える
puts f.call(text)
# => alice
# bob
# carol
# dave
# ellen
# Ruby 2.6で追加されたthenを使うのもよいかも
puts text.then(&f)
# => alice
# bob
# carol
# dave
# ellen
Method#>>でも同じことができます。
def split_lines(str)
str.split("\n")
end
def sort(elements)
elements.sort
end
def join_lines(elements)
elements.join("\n")
end
# Method#>>メソッドを使って関数を合成する
f = method(:split_lines) >> method(:sort) >> method(:join_lines)
puts f.call(text)
# => alice
# bob
# carol
# dave
# ellen
<<メソッドは>>メソッドとは逆で、右辺、左辺の順に関数を実行します。
# f1、f2の順に実行される
f = f2 << f1
例外に関する新機能や変更点
ネストした例外の場合、causeも自動的に出力されるようになった
以下のコードのように、例外処理の途中で別の例外が発生すると、元の例外情報が例外オブジェクトのcauseプロパティに格納されます。
def exec
# オリジナルの例外(ZeroDivisionError)
1 / 0
rescue => e
# 例外処理中にtypo等で別の例外が起きる
# (ZeroDivisionErrorはこの例外のcauseプロパティに格納される)
e.messagee
end
Ruby 2.6ではその例外がrescueされなかった場合に限り、causeの詳細情報も一緒に表示されます。
# Ruby 2.5の場合、causeの情報は必要最小限しか出力されない
$ ruby test/cause_sample.rb
Traceback (most recent call last):
2: from ./test/cause_sample.rb:10:in `<main>'
1: from ./test/cause_sample.rb:1:in `exec'
./test/cause_sample.rb:7:in `rescue in exec': undefined method `messagee' for #<ZeroDivisionError: divided by 0> (NoMethodError)
Did you mean? message
# Ruby 2.6の場合、causeのバックトレースも一緒に出力される
$ ruby test/cause_sample.rb
Traceback (most recent call last):
2: from test/cause_sample.rb:10:in `<main>'
1: from test/cause_sample.rb:3:in `exec'
test/cause_sample.rb:3:in `/': divided by 0 (ZeroDivisionError)
2: from test/cause_sample.rb:10:in `<main>'
1: from test/cause_sample.rb:1:in `exec'
test/cause_sample.rb:7:in `rescue in exec': undefined method `messagee' for #<ZeroDivisionError: divided by 0> (NoMethodError)
Did you mean? message
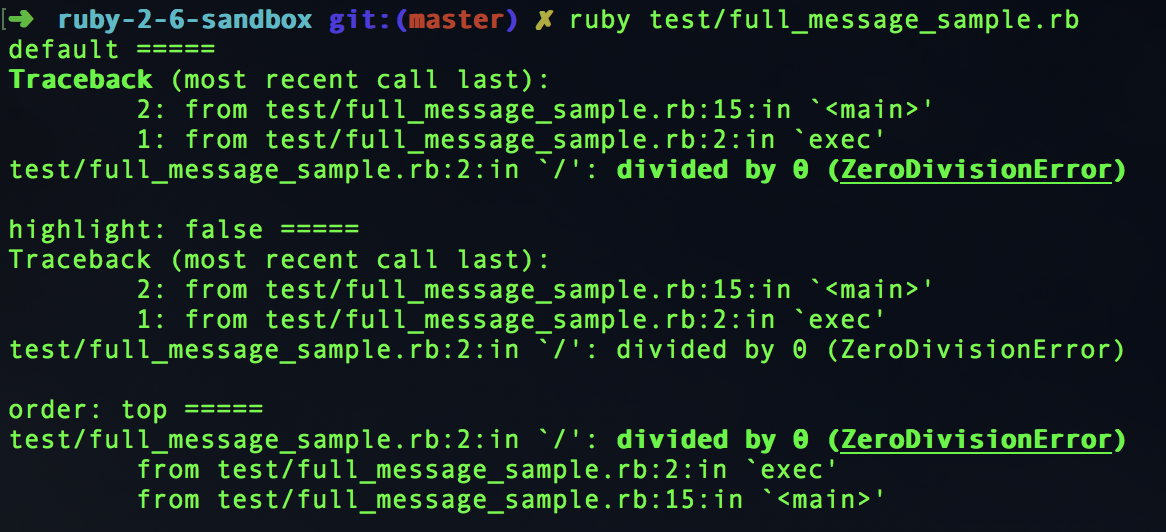
Exception#full_messageでハイライトの有無とバックトレースの出力順を指定できるようになった
Ruby 2.5で導入されたException#full_messageメソッドで:highlightと:orderのオプションが指定できるようになりました。
デフォルト値は:highlightがtrueで、:orderが:bottomです。
ただし、厳密にはこのオプションはRuby 2.6ではなく、Ruby 2.5.1から利用できるようになっています。
以下はこれらのオプションを指定した場合の出力例です。
def exec
1 / 0
rescue => e
puts "default ====="
puts e.full_message
puts
puts "highlight: false ====="
puts e.full_message(highlight: false)
puts
puts "order: top ====="
puts e.full_message(order: :top)
puts
end
exec
上記コードの実行結果
KeyError.new等で、receiverやkeyをRuby上から設定できるようになった
KeyErrorが発生すると、例外オブジェクトにレシーバや見つからなかったキーの情報が格納されます。
h = { a: 1 }
begin
h.fetch(:b)
rescue KeyError => e
puts "receiver: #{e.receiver} / key: #{e.key}"
end
# => receiver: {:a=>1} / key: b
ただし、Ruby上から自分でKeyError.newを呼び出す場合は、receiverやkeyを設定することはできませんでした。
Ruby 2.6ではKeyError.newにreceiverやkeyをオプションとして渡せるようになっています。
h = { a: 1 }
e = KeyError.new('Error!', receiver: h, key: :b)
e.receiver #=> {:a=>1}
e.key #=> :b
同様の考え方で、NameError.newとNoMethodError.newにもreceiverをオプションとして渡せるようになっています。
ファイル操作関連の新機能や変更点
インスタンスメソッドのDir#each_childとDir#childrenが追加された
Ruby 2.5では"."や".."を返さない、クラスメソッドのDir.each_childとDir.childrenが追加されました。
Ruby 2.6ではこれらのインスタンスメソッド版が追加されています。
dir = Dir.new('./test/dir_a')
filenames = []
dir.each_child { |name| filenames << name }
filenames
# => ['code_a.rb', 'text_a.txt']
dir.children
# => ['code_a.rb', 'text_a.txt']
新規ファイルに排他的にアクセスするxオプションの追加
Ruby 2.6では、新規ファイルに排他的にアクセスできるxオプションが追加されました。
これを使うと、間違って既存のファイルを上書きしてしまう可能性を排除できます。
File.exist?('./test/dir_a/text_a.txt')
# => true
# 従来のwオプションだと誤って上書きする恐れがある
open('./test/dir_a/text_a.txt', 'w') do |f|
# write file...
end
# xオプションを付けると、新規のファイルしか開けない
# (既存のファイルがあれば例外が発生する)
open('./test/dir_a/text_a.txt', 'wx') do |f|
# write file...
end
# => Errno::EEXIST: File exists @ rb_sysopen - ./test/dir_a/text_a.txt
xオプションを使わない場合は、「ファイルの存在チェックをして、なければ書き込み」というロジックを書く必要がありますが、これはロジックが増えるだけでなく、「書き込みする直前に別のプロセスが同名のファイルを作成するリスク」がゼロではありません。
xオプションを使えば、このリスクを確実に回避できます。
その他いろいろ
以下の変更点に関してはサンプルコードなしで、概要だけを紹介します。
詳細については参考リンクとして挙げている各issueを参照してください。
- ディレクトリの内容から再帰的にハードリンクを作成するFileUtils.cp_lr(参考)
- Dir.globメソッドにセパレータとしてNULL文字(
"\0")を渡すと警告が出るようになった(参考) - 以下の各メソッドで、パイプ(
|)で始まるパスを外部コマンドとして実行しなくなった(参考)- File.read, File.binread, File.write, File.binwrite, File.foreach, File.readlines
- Pathname#read, Pathname#binread, Pathname#write, Pathname#binwrite, Pathname#each_line Pathname#readlines
Timeクラスに関する新機能や変更点
Time.newやTime#getlocalメソッドにタイムゾーンオブジェクトが渡せるようになった
Time.newやTime#getlocalメソッドには、"+09:00"のような文字列を渡してタイムゾーンを指定できます。
t = Time.new(2018, 12, 8, 10, 00, 0, "+09:00")
# => 2018-12-08 10:00:00 +0900
Ruby 2.6では文字列の代わりに、タイムゾーンオブジェクトを渡すことができます。
以下はtimezone gemで取得でしたタイムゾーンオブジェクトを渡すコード例です。
# timezone gemは事前にインストールする(gem install timezone)
require 'timezone'
tz = Timezone.fetch('Asia/Tokyo')
# タイムゾーンオブジェクトを渡してタイムゾーンを指定する
t = Time.new(2018, 12, 8, 10, 00, 0, tz)
# => 2018-12-08 10:00:00 +0900
上の例ではtimezone gemを使いましたが、タイムゾーンオブジェクトは特定のクラスや特定のgemに依存するものではなく、local_to_utcメソッドやutc_to_localといったメソッドを実装していれば、どんなオブジェクトでも使用可能なようです(いわゆるダックタイピング)。
ですので、次のようにtimezone gemの代わりにtzinfo gemを利用することもできます。
# tzinfo gemは事前にインストールする(gem install tzinfo)
require 'tzinfo'
tz = TZInfo::Timezone.get('Asia/Tokyo')
t = Time.new(2018, 12, 8, 10, 00, 0, tz)
# => 2018-12-08 10:00:00 +0900
タイムゾーンオブジェクトに要求される詳細な仕様は、以下のドキュメントを参照してください。
Refinementsに関する変更点
&foo、public_send、respond_to?で呼び出されたときもrefinementsが効くようになった
Ruby 2.6からは&foo、public_send、respond_to?で呼び出されたときもrefinementsが効くようになりました。
# refinementsでStringに独自のメソッドを追加する
using Module.new {
refine String do
def to_proc
# 渡された引数に対して、メソッド名=自分自身の文字列となるメソッドを呼び出す
# (Symbol#to_procと考え方は同じ)
-> (arg) { arg.send(self) }
end
def upcase_reverse
self.upcase.reverse
end
end
}
# map(&:upcase)と同じような形で、Stringに追加したto_procメソッドを呼び出す
['a', 'b', 'c'].map(&"upcase")
# => ['A', 'B', 'C']
# public_sendでStringに追加したメソッドを呼び出す
"hello!".public_send(:upcase_reverse)
# => "!OLLEH"
# respond_to?でStringに追加したメソッドの有無を確認する
"hello!".respond_to?(:upcase_reverse)
# => true
参考
- Feature #14223: Refinements で定義した #to_proc が &hoge 時に呼ばれないのを緩和する提案
- Feature #15326: Proposal: Enable refinements to `#public_send`
- Feature #15327: Proposal: Enable refinements to `#respond_to?`
標準ライブラリに関する変更点
BundlerがDefault gemsとして標準添付された
Ruby 2.6ではBundlerがDefault gemsとして標準添付されました。これにより、わざわざgem install bundlerしなくてもbundleコマンドが使えるようになります。
Ruby 2.6.0-rc1ではBundler 2.0.0がインストールされています。
Ruby 2.6.0ではBundler 1.17.2がインストールされています。
$ bundle --version
Bundler version 1.17.2
RubyGemsのバージョンが3.0.1になった
Ruby 2.6ではRubyGems 3.0.0.beta3がインストールされます(betaなのはRuby 2.6がまだrc1だから?)。
Ruby 2.6.0ではRubyGems 3.0.1がインストールされます。
$ gem --version
3.0.1
RubyGems 3.0では--[no-]riと--[no-]rdocオプションは使えなくなったので、代わりに--[no-]document [TYPES]を使う必要があります。
# ドキュメントなしでgemをインストールする
$ gem install faker --no-document
Fetching faker-1.9.1.gem
Successfully installed faker-1.9.1
1 gem installed
# gemインストール時にRDocを生成する
$ gem install faker --document rdoc
Successfully installed faker-1.9.1
Parsing documentation for faker-1.9.1
Installing darkfish documentation for faker-1.9.1
Done installing documentation for faker after 1 seconds
1 gem installed
その他いろいろ
このほかにも標準ライブラリ関連の変更点がいくつかあります。
詳細についてはリリースノートやNEWSを参照してください。
- irbやostructなど、いくつかの標準ライブラリがデフォルトgemとして切り出された。これにより、Ruby本体のバージョンアップを待たずにライブラリ単体でアップデートできるようになった。
- ERB、URI、Matrix、Net、REXML、RSS、BigDecimal、Coverage、Psych、nkf、CSV、RDocといったライブラリで機能追加や仕様変更、ライブラリのバージョンアップが行われた。
参考: デフォルトでインストールされるgem一覧
Ruby 2.6.0と同時にインストールされるgemの一覧は以下のとおりです。
$ ruby -v
ruby 2.6.0p0 (2018-12-25 revision 66547) [x86_64-darwin18]
$ gem list
*** LOCAL GEMS ***
bigdecimal (default: 1.4.1)
bundler (default: 1.17.2)
cmath (default: 1.0.0)
csv (default: 3.0.2)
date (default: 1.0.0)
dbm (default: 1.0.0)
did_you_mean (1.3.0)
e2mmap (default: 0.1.0)
etc (default: 1.0.1)
fcntl (default: 1.0.0)
fiddle (default: 1.0.0)
fileutils (default: 1.1.0)
forwardable (default: 1.2.0)
io-console (default: 0.4.7)
ipaddr (default: 1.2.2)
irb (default: 1.0.0)
json (default: 2.1.0)
logger (default: 1.3.0)
matrix (default: 0.1.0)
minitest (5.11.3)
mutex_m (default: 0.1.0)
net-telnet (0.2.0)
openssl (default: 2.1.2)
ostruct (default: 0.1.0)
power_assert (1.1.3)
prime (default: 0.1.0)
psych (default: 3.1.0)
rake (12.3.2)
rdoc (default: 6.1.0)
rexml (default: 3.1.9)
rss (default: 0.2.7)
scanf (default: 1.0.0)
sdbm (default: 1.0.0)
shell (default: 0.7)
stringio (default: 0.0.2)
strscan (default: 1.0.0)
sync (default: 0.5.0)
test-unit (3.2.9)
thwait (default: 0.1.0)
tracer (default: 0.1.0)
webrick (default: 1.4.2)
xmlrpc (0.3.0)
zlib (default: 1.0.0)
その他の新機能や変更点
普段あまり使わない機能についてはよいコード例が思いつかなかったので、簡単に概要を紹介するだけに留めます。
詳しい方がいたら、補足説明をお願いします!
-
$SAFEはプロセスグローバルで扱われることになると共に、0以外を設定した後に0に戻せるようになりました(リリースノートより引用、参考) -
Binding#source_locationの追加(リリースノート、参考1、参考2) -
RubyVM::AbstractSyntaxTree(AST、抽象構文木)モジュールの追加。ただし、実験段階なので互換性は保証されていないとのこと(リリースノート参照) - TracePoint関連のメソッドやイベントの追加(NEWSページ参照)
- Thread関連の仕様変更(参考1、参考2)
まとめ
というわけで本記事ではRuby 2.6の新機能や変更点をまとめてみました。
個人的には関数型言語っぽく書けるProc#>>やMethod#>>が「おおっ、なんか面白そう!」と思いました。
ブロックを渡せるようになったto_hメソッドもハッシュの作成にとても便利そうです。
パフォーマンスの改善も興味深いですね。特にJITコンパイラは今後どう発展していくのか非常に楽しみです!
毎年楽しいクリスマスプレゼントを届けてくれるMatzさんとコミッタのみなさんに感謝しつつ、今年も新しくなったRubyでいろいろ遊んでみようと思います。
みなさんもぜひRuby 2.6の新機能を試してみてください!
あわせて読みたい
この記事を公開した後に気づいたんですが、Ruby 2.6のアドベントカレンダーがありました。(ネタかぶり、すいません・・・💧)
僕が説明を端折った機能も丁寧に解説されているので、こちらも一緒にチェックすることをお勧めします!
Ruby 2.6 Advent Calendar 2018 - Qiita
こちらの記事では、Rubyコミッタの笹田さんと遠藤さんが「Ruby 2.6でなぜそのような変更が行われたのか」という背景を解説されています。こちらもあわせて読むと、Ruby 2.6の新機能をより深く理解できるはずです。
プロと読み解く Ruby 2.6 NEWS ファイル - クックパッド開発者ブログ
Ruby 2.3〜2.5の新機能は以下の記事にまとめてあります。
こちらもあわせてどうぞ。
- サンプルコードでわかる!Ruby 2.3の主な新機能 - Qiita
- サンプルコードでわかる!Ruby 2.4の新機能と変更点 - Qiita
- サンプルコードでわかる!Ruby 2.5の主な新機能と変更点 Part 1 - Qiita
- サンプルコードでわかる!Ruby 2.5の主な新機能と変更点 Part 2 - Qiita
PR: 本記事を読んでもよくわからなかったRuby初心者の方へ
「本文に一通り目を通してみたけど、ProcやらRefinementsやら、なんかよくわからない用語がたくさん出てきて、イマイチちゃんと理解できなかった😣」というRuby初心者の方は、拙著「プロを目指す人のためのRuby入門」(通称チェリー本)を読んでみてください。
本書の内容を一通り理解すれば、この記事の内容も問題なく読みこなせるはずです!

ちなみに本書の対象バージョンはRuby 2.4.1ですが、Ruby 2.5や2.6で発生する記述内容との差異は、それぞれ以下の記事にまとめてあります。なので、多少バージョンが古くても安心して読んでいただけます😊