はじめに
テストコードを書くことは重要です。
テストコードがないアプリケーションよりもテストコードがあるアプリケーションの方が望ましいことは間違いありません。
ですが、テストコードも書き方を間違えると、アプリケーションが壊れているのに正しく検知できないテストを書いてしまう可能性があります。
この記事ではそんな「アプリケーションが壊れているのに正しく検知できないテスト」のコード例を「〜するべからず(〜してはいけない)」の形式で紹介し、その修正方法を説明していきます。
サンプルコードはRSpecで書いてます(でも他の言語でも考え方は同じはず)
サンプルコードはRailsアプリケーションをRSpecでテストする場合を想定したものになっていますが、基本的な考え方自体は他の言語やテスティングフレームワークでも適用可能なはずです。
RSpecのイロハについて先に学んでおきたいかたは「使えるRSpec入門・その1「RSpecの基本的な構文や便利な機能を理解する」をざーっと眺めてからこの記事に戻ってきてください。
おことわり:RSpecに詳しいみなさんへ
本記事ではRSpecに不慣れな人がこの記事を読むことも想定して、あえてRSpecらしいテストコード(RSpecに詳しくないと理解しづらいコード)を避けている部分があります。
# たとえば、こんなふうにbe_truthyを使ったり・・・
expect(user.adult?).to be_truthy
# be_adultのように書いたりする方がRSpecらしいですが・・・
expect(user).to be_adult
# 本記事ではあえて、こんなふうに書いています。
expect(user.adult?).to be true
RSpecに詳しい人は「あれ?なんでこんな書き方なの??」と思われる部分がところどころにあるかもしれませんが、その点は「あえてそうしている」ということでご理解ください。
それでは、以下が本編です。
アサーション(エクスペクテーション)が1つもないテストを書かない
以下のようにアサーション(RSpecではエクスペクテーション)が1つもないテストを書いてはいけません。
何も検証していないので、結果がなんであれテストがパスしてしまいます。
# NG!!
example 'ユーザー名が表示される' do
visit users_path
# このメソッドはtrue/falseを返すだけで、成功失敗を検証するメソッドではない
# よって、結果がなんであれ常にパスする
page.has_content? 'Alice'
end
テスティングフレームワークには専用のアサーションメソッドがあるはずなので、それを使いましょう。
# OK
example 'ユーザー名が表示される' do
visit users_path
# expect + have_textを使えば、指定された文字列が見つからないときにテストが失敗する
expect(page).to have_content 'Alice'
end
「〜ではないこと」だけ検証して終わらない
「〜ではないこと」だけを検証すると、仕様を満たしていないのにテストがパスする可能性があります。
以下はユーザーを削除して「そのユーザーが表示されないこと」だけをテストしている例です。
# NG!!
example 'ユーザーの削除' do
# ...
# ユーザーAliceを削除
click_link 'Destroy'
# Aliceが表示されていないからOK、ではない!!
expect(page).to_not have_content 'Alice'
end
仕様を満たしていないのにテストがパスする場合というのは、たとえば「権限がないため、ホーム画面にリダイレクトされる」という結果になったときです。

ですので、次のように必ず「〜であること」という肯定的な条件もテストしましょう。
# OK
example 'ユーザーの削除' do
# ...
click_link 'Destroy'
expect(page).to_not have_content 'Alice'
# 「削除完了」のメッセージが表示されていることも一緒に検証する
expect(page).to have_content 'User was successfully destroyed.'
end
この内容については以下の記事で詳しく説明しています。
モデルスペックなどでも考え方は同じ
(2025.8.22追記)
「〜ではないこと」だけ検証して終わらせたらダメなのは、モデルスペックなどでも考え方は同じです。
たとえば以下のテストコードを見てください。
# NG
example '対象者にボブは含まれないこと' do
users = User.target
expect(users).not_to include bob
end
expect(users).not_to include bobでボブが含まれていないことを検証していますが、これだと適切な対象者(たとえばアリス)がusersに含まれていることを担保できません。
example '対象者にボブは含まれないこと' do
users = User.target
# usersにaliceが含まれていてもいなくてもテストがパスしてしまう
expect(users).not_to include bob
end
ですので、to eqやto contain_exactlyを使って「含まれてほしいもの」と「含まれてほしくないもの」の両方を検証できるようなテストを書きましょう。
# OK
example '対象者にボブは含まれないこと' do
users = User.target
# これなら対象者であるaliceだけが含まれて、bobが含まれないことを担保できる
expect(users).to eq [alice]
# aliceとcarolだけが含まれていてほしいが順番は問わない、
# というケースはcontain_exactlyを使う
# expect(users).to contain_exactly [alice, carol]
end
網羅性や境界値判定が不完全なテストを書かない
たとえば、次のような「ユーザーが大人かどうか」を判定するメソッドがあったとします。
class User
# ...
def adult?
age >= 20
end
end
このとき、以下のようにtrueを返す場合だけを検証するテストを書いて満足してはいけません。
# NG!!
example '20歳以上ならadult?メソッドはtrueを返す' do
user = User.new(age: 20)
# trueを返す場合しかテストしていない
expect(user.adult?).to be true
end
なぜなら、このテストは以下のような実装になっていてもテストがパスしてしまうからです。
def adult?
# 常にtrueでも上のテストはパスしてしまう!!
true
end
次のように、falseを返す場合も必ずテストしましょう。
# OK
example '20歳以上ならadult?メソッドはtrueを返す' do
user = User.new(age: 20)
expect(user.adult?).to be true
# falseを返す場合も必ずテストする
user = User.new(age: 19)
expect(user.adult?).to be false
end
また、境界値をきちんとテストすることも重要です。
先ほどのメソッドであれば「20歳以上が大人」という仕様なので、19歳と20歳の間が境界になります。
ですので、先ほどのテストコードのように19歳のときと20歳のときを検証するのが正解です。
以下のように5歳と50歳を検証するようなテストコードだと、6歳から49歳のときにどういう結果になるか、テストで担保できません。
# NG!!
example '20歳以上ならadult?メソッドはtrueを返す' do
# 境界値を正しくテストできていない(6歳から49歳のときに不具合が発生しうる)
user = User.new(age: 50)
expect(user.adult?).to be true
user = User.new(age: 5)
expect(user.adult?).to be false
end
「テスト技法」をきちんと学ぼう
この項で述べた内容はいわゆる「テスト技法」の代表的な確認項目です。
このほかにもさまざまなテクニックがあるので、「テスト技法」を学んでおけばヌケ・モレのないテストを書くことができます。
ちゃんと学んだことがない人は、以下のような書籍を読んでしっかり学習しておきましょう。
異なる項目の出力結果を同じ値にしない
たとえば、学校の定期試験の平均点を教科ごとに求めるプログラムがあったとします。
このとき、以下のようにどの教科も同じ平均点になるようなテストを書いてはいけません。
# NG!!
example '教科ごとに平均点を出す' do
# 以下のようなテストデータを用意する
# | 名前 | 英語 | 数学 | 国語 |
# |-------|------|------|------|
# | Alice | 70 | 80 | 90 |
# | Bob | 80 | 90 | 70 |
# | Carol | 90 | 70 | 80 |
points = {
'Alice' => {
'English' => 70,
'Math' => 80,
'Japanese' => 90
},
'Bob' => {
'English' => 80,
'Math' => 90,
'Japanese' => 70
},
'Carol' => {
'English' => 90,
'Math' => 70,
'Japanese' => 80
}
}
# 教科ごとの平均点を算出する
avg = calc_avg(points)
# 教科ごとに平均点を検証する??
expect(avg['English']).to eq 80
expect(avg['Math']).to eq 80
expect(avg['Japanese']).to eq 80
end
上のようなテストコードになっていると、どの教科も同じ80点なので、本当に教科ごとに平均点を出せているかわかりません。
(もし英語の平均点と国語の平均点が入れ替わっていても、誰も気づけない!)
ですので、ちゃんと教科ごとに異なる平均点が出力されるテストデータを用意しましょう。
# OK
example '教科ごとに平均点を出す' do
# 先ほどのテストデータを一部修正
points = {
'Alice' => {
'English' => 40, # 変更
'Math' => 80,
'Japanese' => 90
},
'Bob' => {
'English' => 80,
'Math' => 90,
'Japanese' => 100 # 変更
},
'Carol' => {
'English' => 90,
'Math' => 70,
'Japanese' => 80
}
}
avg = calc_avg(points)
# これなら教科ごとに別々の平均点が出力されるはず!
expect(avg['English']).to eq 70
expect(avg['Math']).to eq 80
expect(avg['Japanese']).to eq 90
end
ここで紹介した悪い例は少し極端だったかもしれません。
ですが、「すべての項目が全部同じ」とまではいかなくても、適当にテストデータを作った結果、数多くある項目のうち、一部の値が重複するということはたまにあると思います。
プログラムを作った人間からすると「いやいや、中ではちゃんと別々に処理してるから大丈夫!」と言いたくなるかもしれませんが、なるべく誰が見ても「これなら大丈夫そうだな」と安心してもらえるようなテストデータ(=項目ごとにユニークな値が得られるテストデータ)を用意しましょう。
呼び出されないlet(=作成されないテストデータ)を作らない
これはRSpec特有の問題です。
RSpecのletは遅延評価されるため、場合によっては一度も呼び出されることなくテストが終了するということが起こりえます。
この特性を理解していないと、「パスすべきでない状況でパスしてしまうテスト」を書いてしまう可能性があります。
たとえば、「管理者権限がないと閲覧できないデータ」があったとします。
このとき、次のようなテストコードになっていると、実は管理者権限がなくても閲覧できる可能性があります。
# NG!!
describe '権限管理' do
# AliceもBobも管理者ではない
let(:alice) { create :user, name: 'Alice', admin: false }
let(:bob) { create :user, name: 'Bob', admin: false }
example '管理者権限がないと他のユーザーは見えない' do
# Aliceとしてログインする
sign_in(alice)
# 自分のデータは表示されるが、Bobのデータは表示されない(とは限らない!!)
visit some_path
expect(page).to have_content 'Alice'
expect(page).to_not have_content 'Bob'
end
end
上のコードの問題点がわかるでしょうか?
実はlet(:bob)はどこからも呼び出されていないため、そもそもデータベースにデータが作成されていないのです。(let(:alice)はsign_in(alice)で呼び出される)
そのため、権限があろうとなかろうと、「データそのものがないので常に表示されない」という結果になります。
正しいテストコードは次のようにlet!を使うことです。
let!は遅延評価ではないので、一度も呼び出されないときでもテストを実行する前にそのデータが作成されます。
# OK(let!を使えば、Bobも確実に作成される)
let!(:bob) { create :user, name: 'Bob', admin: false }
とはいえ、うっかりletとlet!の使い分けを間違う可能性もあるので、念のため画面の表示だけでなく、次のようにDB上のデータ件数を検証しておくのもひとつの手です。
# OK
example '管理者権限がないと他のユーザーは見えない' do
sign_in(alice)
visit some_path
expect(page).to have_content 'Alice'
expect(page).to_not have_content 'Bob'
# DB上にデータが2件あることを検証する
# (Bobが作成されていないと1件だけなのでテストが失敗する)
expect(User.count).to eq 2
end
絞り込みが甘いテストを書かない
検証内容の絞り込みが甘いと、「テスト対象の項目ではなく、別の項目のおかげでテストがパスしてしまう」という可能性があります。
たとえば「名前の必須チェックが機能しているかどうか」をテストしたいとします。
このとき、以下のようなテストコードになっていると、必須チェックが機能していなくてもテストがパスしてしまう可能性があります。
# NG
example '名前は必須' do
user = User.new(name: '', locale: 'jp')
# 名前の必須チェックで検証エラーになった、とは限らない!!
expect(user.valid?).to be false
end
上のコードではlocaleがjpになっていますが、もしこれが「jpは無効(jaが正しい)」という項目チェックに引っかかっていると、名前の必須チェックが機能してようと、していまいとテストがパスしてしまいます。
# もしかしたらアプリケーション側のコードがこうなっているかも?
class User < ApplicationRecord
# ...
# localeに設定できるのはjaまたはenのみ(jpは無効)
validates :locale, inclusion: { in: ['ja', 'en'] }
# ...
end
「名前の必須チェック」を検証するのであれば、次のように検証内容をもっと絞り込むべきです。
# OK
example '名前は必須' do
user = User.new(name: '', locale: 'ja')
expect(user.valid?).to be false
# nameに必須入力エラーが設定されていることまで検証する
expect(user.errors.added?(:name, :blank)).to be true
end
もしくは、検証エラーが起きる状態と起きない状態の両方をテストするのもひとつの手です。
# OK
example '名前は必須' do
user = User.new(name: '', locale: 'ja')
expect(user.valid?).to be false
# 名前を設定すれば検証エラーがなくなることを検証する
# (名前以外の項目で検証エラーが起きていればここで失敗する)
user.name = 'Alice'
expect(user.valid?).to be true
end
システムスペックで検証する文字列にも注意
絞り込みが甘い、という意味ではシステムスペックでも同じような問題が発生します。
たとえば以下のようなテストを書いたとしましょう。
example 'ユーザーの登録' do
sign_in(@admin)
visit new_user_path
fill_in '名前', with: 'Alice'
click_button '登録'
expect(page).to have_content 'Alice'
end
このテストではユーザー情報として"Alice"を入力し、それを登録したら画面上に"Alice"という名前が表示されていることを検証しています。
一見、何も問題がないように見えますが、実はユーザーの登録に失敗していても、検知できない可能性があります。
それはなぜか?
こちらの画面をご覧ください。
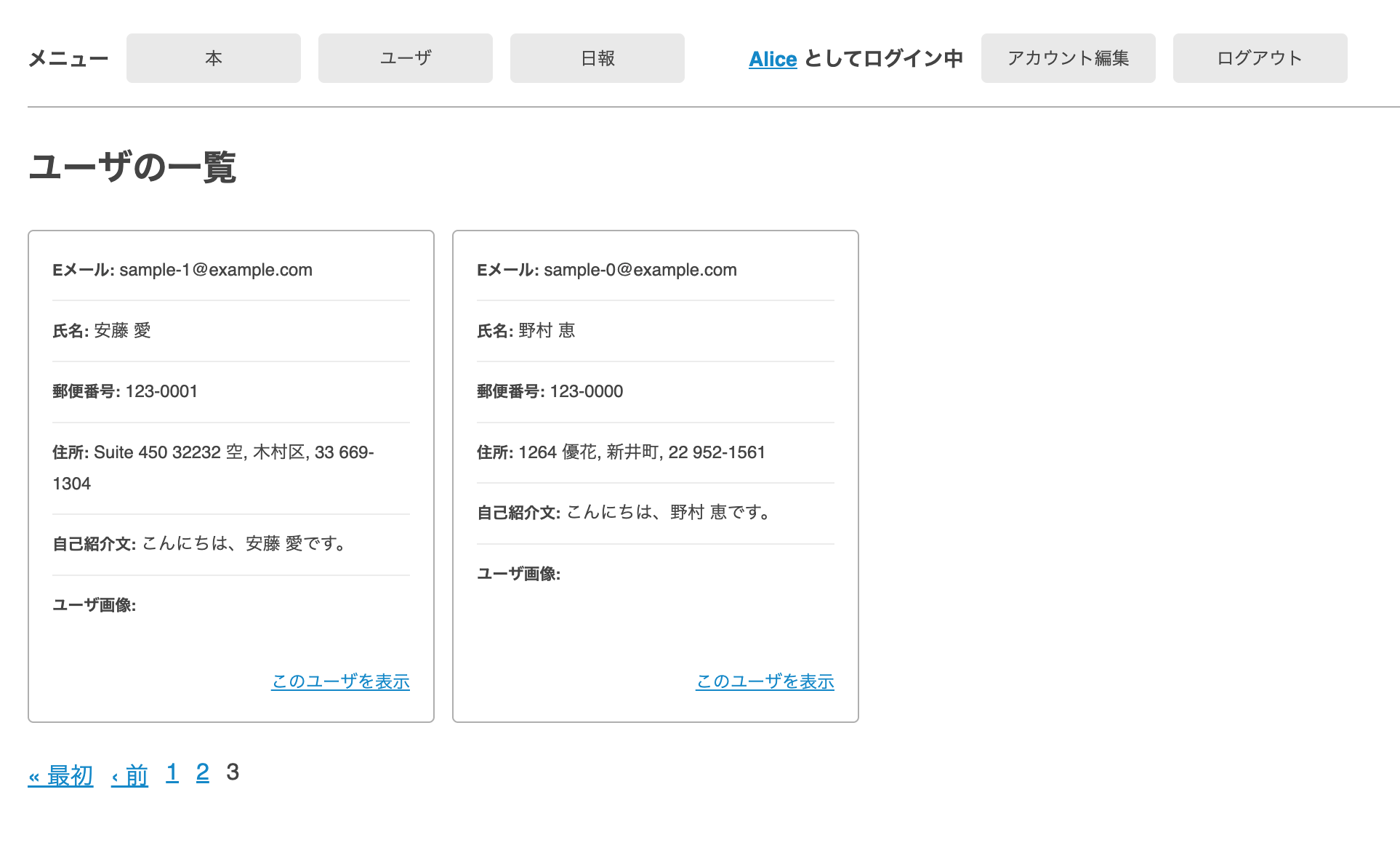
おわかりいただけただろうか……?

ログイン中の管理者も"Alice"で、その情報がnavbarに表示されていますね。
こういう状況だとexpect(page).to have_content 'Alice'はどんなケースでもパスしてしまいます!
この問題を回避するには、「画面上のどこかに"Alice"が表示されていること」から「ユーザー一覧の中に"Alice"が表示されていること」というようにテストを修正しましょう。
# ユーザー一覧の中に表示されている"Alice"を検証する
within '.users' do
expect(page).to have_content 'Alice'
end
こうすれば、navbarに表示されている"Alice"は対象外になるため、ユーザー登録・失敗を適切に検知できます。
ただし、「既存のユーザーに"Alice"が登録されていた」というような場合は、やはり同じ問題が起こりえます。
テストコードのコンテキストを確認して、既存のデータと被らないようなデータを登録するようにしてください。
検証したい文字列が別の文字列の一部分に含まれないようにする
もうひとつ、失敗を検知できないシステムスペックの例を紹介しましょう。
以下のテストを見てください。
example 'ユーザーを10人表示する' do
visit users_path
expect(page).to have_content 'ユーザー1'
expect(page).to have_content 'ユーザー2'
expect(page).to have_content 'ユーザー3'
expect(page).to have_content 'ユーザー4'
expect(page).to have_content 'ユーザー5'
expect(page).to have_content 'ユーザー6'
expect(page).to have_content 'ユーザー7'
expect(page).to have_content 'ユーザー8'
expect(page).to have_content 'ユーザー9'
expect(page).to have_content 'ユーザー10'
end
上のテストではユーザーが10人表示されていることを検証しています。
はい、何も問題がなさそうですね。
・・・本当に!?
これ、実はユーザーが9人しか表示されていなくてもテストは落ちません。
それはなぜか?
この2人を見てください。
expect(page).to have_content 'ユーザー1'
expect(page).to have_content 'ユーザー10'
もうわかりましたか?
"ユーザー1"という文字列は"ユーザー10"の一部分と見なすことができます。
よって、画面上に"ユーザー1"が表示されていなくても、"ユーザー10"がいればテストはパスしてしまうのです!
この問題を回避する方法のひとつは、別の文字列の一部分になるような文字列を作らないようにすることです。
たとえば、連番をゼロ埋めすれば、"01"と"10"は完全に別の文字列になります。
# ゼロ埋めすれば"01"と"10"は被らない
example 'ユーザーを10人表示する' do
visit users_path
expect(page).to have_content 'ユーザー01'
expect(page).to have_content 'ユーザー02'
expect(page).to have_content 'ユーザー03'
expect(page).to have_content 'ユーザー04'
expect(page).to have_content 'ユーザー05'
expect(page).to have_content 'ユーザー06'
expect(page).to have_content 'ユーザー07'
expect(page).to have_content 'ユーザー08'
expect(page).to have_content 'ユーザー09'
expect(page).to have_content 'ユーザー10'
end
もうひとつはexactオプションを使う方法です。
こうすると、部分一致ではなく、完全一致で文字列を検証することができます。
# exact: trueを付けることで部分一致ではなく完全一致で検証する
example 'ユーザーを10人表示する' do
visit users_path
expect(page).to have_content 'ユーザー1', exact: true
expect(page).to have_content 'ユーザー2', exact: true
expect(page).to have_content 'ユーザー3', exact: true
expect(page).to have_content 'ユーザー4', exact: true
expect(page).to have_content 'ユーザー5', exact: true
expect(page).to have_content 'ユーザー6', exact: true
expect(page).to have_content 'ユーザー7', exact: true
expect(page).to have_content 'ユーザー8', exact: true
expect(page).to have_content 'ユーザー9', exact: true
expect(page).to have_content 'ユーザー10', exact: true
end
個人的にはexactオプションを付ける方法は「うっかり付け忘れる」という問題が起きやすいので、最初から被りにくいテストデータを用意する方がいいと思います。
同じような理由で、こういうテストも望ましくないです。
example 'プロフィールページに名前と自己紹介を表示する' do
visit profile_path(@alice)
expect(page).to have_content 'Alice'
expect(page).to have_content 'はじめまして、Aliceです。'
end
ここまで記事を読んだ人はもうわかりますね?
そう、"Alice"という名前が自己紹介欄にも表示されています。
なので、以下のようにもし名前の欄に"Alice"が表示されていなくてもテストはパスしてしまいます。
名前:
自己紹介: はじめまして、Aliceです。
これも何らかの方法で部分一致を避けるようにテストを修正しましょう。
example 'プロフィールページに名前と自己紹介を表示する' do
visit profile_path(@alice)
expect(page).to have_content '名前: Alice'
expect(page).to have_content '自己紹介: はじめまして、Aliceです。'
end
一般的に短くてシンプルな文字列は部分一致を引き起こしやすいです。
たとえば、
example '本文を表示する' do
visit book_path(@book)
example(page).to have_content 'あ'
end
よりも
example '本文を表示する' do
visit book_path(@book)
example(page).to have_content '吾輩は猫である。名前はまだ無い。'
end
の方が部分一致を引き起こしにくいのは見て明らかでしょう。
テストデータを用意する際は、なるべく他のデータと被りにくいユニークなデータを使うようにしてください。
並び順の通りにテストデータを作成しない
2026.4.16追記
たとえば以下のようなscopeがあったとします。
class User < ApplicationRecord
# 年齢が若い順に並び替える
scope :order_by_age, -> { order(:age) }
このとき、以下のようなテストコードを書くのはイマイチです。
describe '.order_by_age' do
before do
# 年齢が若い順にユーザーを作成する・・・??
create(:user, name: 'Alice', age: 10)
create(:user, name: 'Bob', age: 20)
create(:user, name: 'Carol', age: 30)
end
example '年齢が若い順に並ぶ' do
names = User.order_by_age.pluck(:name)
expect(names).to eq %w[Alice Bob Carol]
end
end
なぜならこのテストは、order_by_ageがid順だったり、created_at順だったりした場合でもパスしてしまうからです。
class User < ApplicationRecord
# もし作成日順に並ぶロジックになっていても、上のテストはパスしてしまう
scope :order_by_age, -> { order(:created_at) }
ですので、並び順をテストする場合は、なるべくランダムにデータを作成するようにしましょう。
たとえば以下のようなテストであればid順やcreated_at順に並ぶ可能性を排除できます。
describe '.order_by_age' do
before do
# あえてバラバラの順番でテストデータを作成する
create(:user, name: 'Bob', age: 20)
create(:user, name: 'Carol', age: 30)
create(:user, name: 'Alice', age: 10)
end
example '年齢が若い順に並ぶ' do
names = User.order_by_age.pluck(:name)
expect(names).to eq %w[Alice Bob Carol]
end
end
「失敗すること」を一度も確認しないまま、テストコードをコミットしない
テストファーストは必須ではない、が・・・!!
「テストコードを書くときはテストファーストで書くのが良い」とよく言われます。
僕個人としては「なるべくテストファーストで実装すべきだが、テストは後回しにして先に実装しても構わない」というスタンスです。
テストファーストが向いているのは以下の条件を同時に満たす場合です。
- これから実装しようとしている機能のインプットとアウトプットが明確に決まっている
- 「こういうテストコードを書けば検証できる」というイメージが、最初から頭の中にある
実装する機能の複雑さや、コードを書く人のスキルによっては上記の条件を両方満たすことは難しいかもしれません。
その場合は先にコードを実装し、そのあとにテストコードを書くというスタイルでも構いません。
ただし、その場合は必ず一度、そのテストコードをわざと失敗させてください。
わざと失敗させないと不完全なテストコードをコミットしてしまう例
たとえば、あなたは「ユーザー一覧ページを作成する」というタスクを与えられたとします。
あなたはテストコードの書き方がわからなかったので、先にユーザー一覧ページを作成しました。
それからネット記事を参考にしたりしながら、以下のようなテストコードを書きました。
# パスするけど、NG!!
describe 'ユーザー一覧' do
let!(:user) { create :user, name: 'Alice' }
example 'ユーザー名が表示される' do
visit users_path
page.has_content? 'Alice'
end
end
このテストコードを実行するとちゃんとテストがパスしました。
めでたし、めでたし・・・ではありません!!
本記事の最初の方で述べたとおり、has_content?はtrue/falseを返すだけのメソッドなので、"Alice"が表示されてもされなくてもテストがパスしてしまいます。
わざと失敗させれば、テストがちゃんと機能しているかどうかがわかる
こういううっかりミスを防ぐために、一度テストをわざと失敗させてみましょう。
先ほどのテストコードであれば、ユーザーデータの作成処理をコメントアウトすると、"Alice"が表示されなくなってテストが失敗するはずです。
describe 'ユーザー一覧' do
# データを作成しなければ、テストは失敗するはず!!
# let!(:user) { create :user, name: 'Alice' }
example 'ユーザー名が表示される' do
visit users_path
page.has_content? 'Alice'
end
end
しかし、このテストコードだとコメントアウト後もテストがパスしてしまいます。
このときに「あれ、何かがおかしい🤔」と気づけるわけです。
以下のようにテストコードを修正すれば、ちゃんとテストが失敗するはずです。
describe 'ユーザー一覧' do
# let!(:user) { create :user, name: 'Alice' }
example 'ユーザー名が表示される' do
visit users_path
# expect + have_textを使えば、指定された文字列が見つからないときにテストが失敗する
expect(page).to have_content 'Alice'
end
end
テストが失敗することを確認したら、コメントアウトした部分を元に戻し、再度テストがパスすることをチェックしてコードをコミットしてください。
これで作業完了です!
# OK
describe 'ユーザー一覧' do
# コメントアウトした行を元に戻し、テストがパスすれば完了!
let!(:user) { create :user, name: 'Alice' }
example 'ユーザー名が表示される' do
visit users_path
expect(page).to have_content 'Alice'
end
end
なお、テストファーストでテストコードを書いた場合は、先に「失敗するテストコード」ができあがるので、ここで説明したような問題は発生しにくくなります。
DRYを追求しない
良いプログラムの条件のひとつはDRYであることです。
(DRYとはDon't repeat yourselfの略で、「コードの重複を避けること」の意味です)
しかし、テストコードを書くときは必ずしも「DRY = 善」とは限りません。
たとえば以下のようなテストコードは「DRYだが最善ではないテストコード」です。
# NG!!
describe '商品の購入' do
let(:user) { create :user }
let(:item) { create :item, name: 'チェリー本', price: 3278 }
example '商品を購入できる' do
sign_in(user)
# (あれこれステップが続いて商品の購入が完了する)
# 購入履歴ページを開く
visit order_history_path
# 商品名が表示されていることを確認する??
expect(page).to have_content item.name
end
end
上のテストコードでは一番最後のステップでitem.nameのように書いて、購入した商品が表示されていることを検証しています。
こうすれば、"チェリー本"という文字列を2回書かなくていいので、テストコードとしてはたしかにDRYになります。
しかし、もし途中でメソッドの予期せぬ副作用等でnameの中身が空文字になったりする可能性が絶対ないとは言いきれません。
もし空文字になっていると、商品名が表示されようとされまいとテストがパスしてしまいます。
example '商品を購入できる' do
sign_in(user)
# ...
# なんらかの理由でnameに空文字が設定されてしまった
item.name = ''
# ...
visit order_history_path
# nameの中身は空文字なので、商品名が画面上にあってもなくてもテストパスしてしまう
expect(page).to have_content item.name
end
ですので、検証したい値はリテラルを使ってベタ書きしましょう。
ベタ書きした文字列で検証すれば、確実にその値の有無を検証できます。
# OK
expect(page).to have_content 'チェリー本'
画面の操作をするときも同じです。
たとえば、
# NG!!
click_link item.name
とするよりも、
# OK
click_link 'チェリー本'
のようにベタ書きする方がテストコードとして確実です。
「item.nameが突然空文字になる」というのは少し極端な例かもしれませんが、ここでみなさんに理解してもらいたいのは「テストコードを書くときはDRYが最善とは限らない」ということです。
2025-07-02追記
同じようなパターンで、以下のようなテストコードも問題ありです。
# ❌ アリスとボブの住所が表示されていればパス(?)
expect(page).to have_content alice.prefecture
expect(page).to have_content bob.prefecture
たとえ、prefectureの中身が空文字列じゃなかったとしても、以下のような条件なら不具合を検知できません。
- aliceもbobも
prefectureに格納されている文字列が"兵庫県"だった - viewに不具合があり、先頭のユーザー(alice)しか画面に表示していなかった
変数を使わなければそもそもテストコードとしておかしいことに気づけるはずです。
# あれっ、アリスもボブも兵庫県か!
expect(page).to have_content "兵庫県"
expect(page).to have_content "兵庫県"
同じ値ではなく異なる値で検証する必要がありますよね。
# ✅ アリスとボブでそれぞれ異なるprefectureをセットして、それを明示的に検証する
expect(page).to have_content "兵庫県"
expect(page).to have_content "大阪府"
また、この場合はテストコード内で明示的にprefectureの値をセットするようにしましょう(FactoryBotのデフォルト値を暗黙的に参照するのはテストの可読性が下がるのでNG)。
# NG: FactoryBotのデフォルト値を使うと、prefectureに何がセットされているのかわかりにくい
let!(:alice) { create :user, name: "Alice" }
let!(:bob) { create :user, name: "Bob" }
# OK: テストコード内で参照する値はテストコード内で明示的にセットする
let!(:alice) { create :user, name: "Alice", prefecture: "兵庫県" }
let!(:bob) { create :user, name: "Bob", prefecture: "大阪府" }
参考:文字列以外の値もベタ書きしよう
上のサンプルコードでは文字列リテラルを使いましたが、文字列以外のデータ型を扱う場合も同様です。
以下にいくつか具体例を挙げておきます。
# 数値
expect(user.age).to eq 20
# true/false
expect(user.admin?).to be true
# nil
expect(user.supervisor).to be nil
# 日付(Rubyには日付リテラルがないので、文字列をパースして代用する)
expect(user.date_of_birth).to eq Date.parse('2020/01/29')
# Railsならto_dateメソッドのような変換メソッドも使える
expect(user.date_of_birth).to eq '2020/01/29'.to_date
補足:テスト実行時に動的に決まる値は例外です
この記事ではベタ書きを推奨していますが、テスト実行時に動的に決まる値についてはベタ書きしなくて良いです。(むしろ、してはいけません)
「テスト実行時に動的に決まる値」というのは、たとえばRuby on Railsでいうと、レコードをデータベースに保存したときに割り当てられるid値がその代表例です。
以下に悪いテストコード例とその修正例を示します。
# NG!!
example 'ユーザー情報ページが表示できる' do
# idは本来自動的に割り当てられる値なので、明示的に指定するのは良くない
user = User.create(id: 1, name: 'Alice')
# ユーザー情報ページを開く
visit user_path(user)
# idは本来、動的に決まるはずなのでベタ書きしない方が良い
expect(page).to have_content "Alice (id = 1)"
end
# OK
example 'ユーザー情報ページが表示できる' do
# idは指定しない(自動的に割り当てられる値を使う)
user = User.create(name: 'Alice')
visit user_path(user)
# idは動的に割り当てられる値なので、例外的に変数の値を参照しても良い
expect(page).to have_content "Alice (id = #{user.id})"
end
ちなみに、システム日時も動的に決まる値のひとつと言えますが、もしテスト実行時にシステム日時をモック化できるライブラリや便利メソッドがある場合は、それを使って特定の日時に固定化する方が良いでしょう。
# OK
example 'トップページに現在日時を表示する' do
# Railsに用意されているtravel_toメソッドを使って、システム日時を書き換える
travel_to '2010/12/31 23:59:59' do
visit root_path
expect(page).to have_content '現在の日時は2010年12月31日 23時59分59秒です'
end
end
ロジカルなテストコードも避ける
テストコードにDRYさを求めると、次のようにテストコードにループ処理が登場することもよくあります。
# NG!!
example 'ユーザーが全員表示されること' do
visit users_path
# DBから全ユーザーを取得し、ループさせながら全員が表示されていることを検証する??
User.all.each do |user|
expect(page).to have_content user.name
end
end
しかし、これもテストコードとして望ましくありません。
もし何らかの理由でDBからユーザーが1件も取得できなければ、ループ処理は一度も実行されないので、何もテストできていないことになります。
# 何らかの理由でユーザーが0件になっていたら?
User.count
#=> 0
# ユーザーが0件ならexpectは一度も実行されないままテストが終了する
User.all.each do |user|
expect(page).to have_content user.name
end
ループ処理を使えばDRYでスマートなテストコードが書けた気分になりますが、テストコードはDRYでスマートであることよりも、不具合を確実に検知できることの方が重要です。
ここは愚直に全ユーザーをベタ書きしましょう。
# OK
example 'ユーザーが全員表示されること' do
visit users_path
# ループ処理を使わず、愚直にユーザー名をベタ書きする方が良い
expect(page).to have_content 'Alice'
expect(page).to have_content 'Bob'
expect(page).to have_content 'Carol'
end
上から下に自然に読み下せるドキュメントのようなテストコードを目指そう
ほかにもif文やcase文のような条件分岐を登場させて、「いろんな条件に対応できる賢いテストコード」書きたくなることがあるかもしれません。
# NG!!
example '国籍によって表示する名前の種類を切り替える' do
visit users_path
# ループするわ、条件分岐するわ、もう何でもアリかい!
User.all.each do |user|
if user.japanese?
expect(page).to have_content user.japanese_name
else
expect(page).to have_content user.english_name
end
end
end
しかし、テストコードがロジカルになればなるほど、テストコード自体の不具合が発生する可能性が高まります。
そうなると「テストコードをテストするためのテストコード」が必要になってきます。
そんな状況では、もはや何のためにテストを書いているのかわかりません。
さらに、ロジカルなテストコードはテストコード自体の不具合が発生しやすくなるだけでなく、「第三者が読んだときに何をテストしているのかよくわかない」という問題も引き起こします。
テストコードは仕様書のように、できるだけ上から下に自然に読み下せるドキュメントに近い方が望ましいです。
# OK(上から下に読み下せる。テストコード自体の不具合が発生する可能性も低い)
example '国籍によって表示する名前の種類を切り替える' do
visit users_path
expect(page).to have_content '太郎'
expect(page).to have_content 'Bob'
expect(page).to have_content '花子'
end
もちろん、すべてをベタ書きするとあまりにも非効率な場合は、一部をDRYにすることを検討しても構いません。
大事なポイントは「ベタ書きを原則として、DRYを例外とする」というマインドでテストコードを書くことです。(逆はダメです!!)
テストコードを書くときは、アプリケーション側のコードを書くときと考え方を切り替える必要があります。
なお、この話は以下の記事でも詳しく説明しています。
その他
この項ではテストコードの書き方そのものには問題はないものの、観点として意識しておかないと、やはり「アプリケーションが壊れているのに正しく検知できないテスト」になってしまうポイントを説明します。
モックに依存しすぎないようにしよう
Twitter APIのような外部リソースへのアクセスが必要になる場合や、テスト実行のパフォーマンスを改善するために、モックを使ったテストを書くことがあると思います。
# 出典:使えるRSpec入門・その3「ゼロからわかるモック(mock)を使ったテストの書き方」
# https://qiita.com/jnchito/items/640f17e124ab263a54dd
it 'エラーなく予報をツイートすること' do
twitter_client_mock = double('Twitter client')
allow(twitter_client_mock).to receive(:update)
weather_bot = WeatherBot.new
allow(weather_bot).to receive(:twitter_client).and_return(twitter_client_mock)
expect{ weather_bot.tweet_forecast }.not_to raise_error
end
モックはたしかに便利な面もあるのですが、モックはモックに過ぎません。
つまり、「本物のふりをするニセモノ」に過ぎないのです。
モックを使ったテストがパスしているからといって、本番環境でそのコードが絶対に動くという保証はありません。
なので、テストがパスしたあとも手作業で動作確認するなどして、本物のコードもちゃんと動くことを確認しておきましょう。
テストカバレッジ(テスト網羅率)も把握しておこう
「テストコードはある。でも、大事な機能がテストできていなかったからバグってしまった!」では、テストコードを書いた意味がありません。
おそらく言語ごとにテストカバレッジを測定するためのツールやライブラリが用意されているはずなので、これを活用しましょう。
たとえば、RubyであればSimpleCovというツールがあります。
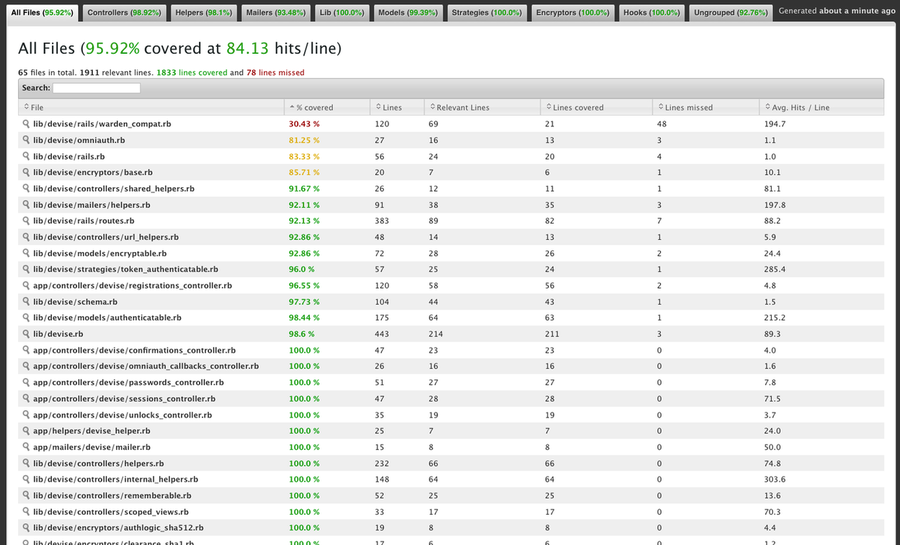
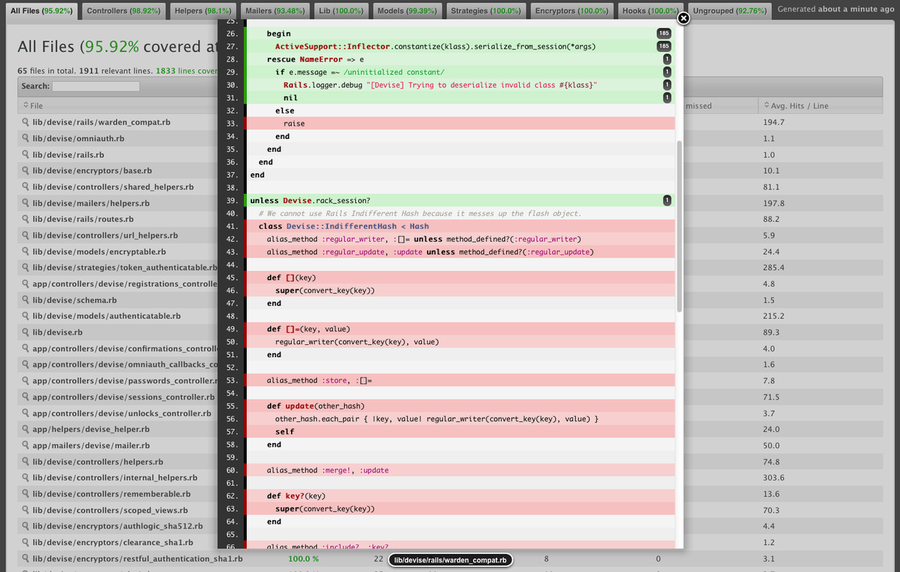
画像の出典: https://github.com/colszowka/simplecov
こういったツールを使って、アプリケーション全体のうち、何%ぐらいのコードをテストで実行できているのか、テストできていない処理は具体的にどのあたりなのか、といったポイントをときどき確認しましょう。
カバレッジは無理に100%を目指す必要はありません。
100%を目指すと費用対効果が悪くなったり、テスト全体の実行時間が遅くなったり、テストコードのメンテナンスに工数を取られたり、と、それはそれで弊害が出てきます。
テストコードが必要になるのは、「テストを書いておかないと不安になる部分」です。
たとえば、何か仕様変更や機能追加をして本番リリースするときに、「うまく動いてほしい」と祈る自分がいたら、それはテストが不足している証拠です。
どういった処理にテストを書くべきかという具体的な観点については、以下の記事を参考にしてみてください。
また、カバレッジ測定ツールはあくまで「その行を実行したかどうか」ということしか教えてくれない点にも注意してください。
たとえカバレッジ率が100%でも、検証内容が不十分だったので不具合が発生してしまった、ということは十分ありえます。
(なので、そうならないようにこの記事を書いています!)
コラム:壊れているのに検知できない=偽陰性(false negative)?
この記事では「アプリケーションが壊れているのに正しく検知できないテスト」を紹介していますが、これをもっと短く表現できる用語は何かないでしょうか?
たとえば、がんの検査などでは「偽陰性」や「偽陽性」という用語があります。
偽陰性(false negative:FN)
がんがあるにもかかわらず、検査で「陰性」と判定されるもの。
偽陽性(false positive:FP)
がんがないにもかかわらず、検査で「陽性」と判定されるもの。
この観点で考えると、「アプリケーションが壊れているのに正しく検知できないテスト」は「偽陰性が起こりうるテスト」と呼ぶことができるかもしれません。
反対に「アプリケーションが壊れていないのに失敗と判定されるテスト」は「偽陽性が起こりうるテスト」になります。(ローカル環境ではパスするのに、CI環境ではなぜか失敗するテストなどがこれですね)
自動テストの世界で偽陰性や偽陽性という言葉をあまり聞いたことはありませんが(僕が知らないだけかも)、こういった言葉を知っておくとチーム内のコミュニケーションが素早く終わることがあるかもしれません。(たとえば、「このテスト、偽陰性が起きそうだよ!」みたいな感じで)
まとめ
というわけで、この記事では「アプリケーションが壊れているのに正しく検知できないテスト」のコード例と、その修正方法を説明しました。
せっかくテストを書いたのに、そのテストがアプリケーションが壊れていることを検知できなくて不具合を作ってしまうのは非常にもったいないです。
ここで説明したようなポイントに注意しながら、「アプリケーションが壊れたら必ず検知できるテストコード」を目指していきましょう💪
なお、この記事の公開後に新たなアンチパターンを見つけた場合は随時この記事に追記していきます。
追記したときには通知を送りますので、追記のお知らせを受け取りたい方は記事のストックをお願いします。
また、「こういうテストコードも不具合を見逃す可能性があるよ!」という知見をお持ちの方はコメント欄で教えてもらえると嬉しいです。(言語やテスティングフレームワークは問いません)
みなさん、よろしくお願いします🙏
あわせて読みたい
そもそもなんでテストコードが必要なの?どういうことを考えながらテストを書けばいいの?という基礎的な話を知りたい方は以下のスライドやQiita記事を参照してください。
- なぜテストを書くの?(または書かないの?) 〜テストコードの7つの役割〜 / #tamarubykaigi01 - Speaker Deck
- 【初心者向け】テストコードの方針を考える(何をテストすべきか?どんなテストを書くべきか?) - Qiita
RailsでRSpecを使ったテストコードがスラスラ書けるようになりたい!という方は、僕が翻訳した電子書籍「Everyday Rails - RSpecによるRailsテスト入門」をどうぞ💁🏻♂️