はじめに
画像分類タスクに取り組むにあたって、自分で画像を集め、ラベリングしてといった作業を行うと必ずと言っていいほど、同じ画像が混入してしまいます。特にこれはインターネットから画像をスクレイピングしてきたときに顕著で、画像収集の段階ではそれを防ぐのは難しいような気もします。
ということで、今回の記事ではその重複した画像をいかに楽をして探すか。これに焦点を当てていきたいと思います。
ちなみにはじめてのQiitaです!
よろしくお願いします!
画像の重複を見つける手段①
画像の重複、すなわち同じ画像同士はどのようにして発見することができるのか。まずはそこから考えていきましょう。
Qiitaを探していると以下のような記事を発見しました。
この記事では画像を任意次元の特徴ベクトル空間に配置して、その特徴ベクトルごとの距離を調べることによって画像の類似度を算出しています。
『距離』なので、小さいほど対象となる画像は類似しているということになります。
ということで……
この記事のコードを改良してフォルダにある画像全てにおいてこの距離を計算すれば重複した画像を検出できると考えたわけですが。。
とてつもなく重いです。
1000組ほどの対応を計算するだけでも、GoogleColabのCPUで15分はかかってしまいました。つまり1000枚の写真についてその重複を調べようと考えたときは莫大な時間がかかってしまうことになります。
これは現実的な方法ではありません。。
よくよく見てみると、RGBの画像を特徴ベクトルに変換する際には深層学習をベースにしたアーキテクチャを使用しているとのことでした。
そりゃ重いわ……
ということで別の方法を探してみることにしました。
画像の重複を見つける手段②
データ分析初心者の私が次に頼ったのはGPT-4君でした。以下がプロンプトとなります。
プロンプト
画像分類タスクにおいて、集めた画像データセットのなかに同じ画像が存在していないかを簡単に調べるためのコードを考えています。数千枚程度のなかから探すため、あまり重くならないような手法を考えています。 具体的なコードを考えてください。
GPT-4君
Pythonを使用して、画像データセットの中に重複画像が存在しないか確認するための一般的な方法はハッシュ関数を用いることです。これは非常に効率的で、通常は大量のデータでも問題なく処理できます。
以下にその一例を示します。このコードでは、Pythonのhashlibライブラリを用いてMD5ハッシュを生成し、各画像のハッシュ値を比較して重複を検出します。ただし、ここでは2つの仮定があります。
1.画像はすべて同じディレクトリにあります。
2.画像はすべて.jpg形式です(これはコード内で変更可能です)。
このような流れでGPT-4君と対話しながら目的のコードを改善しながら完成させていきました。
次の章では具体的にデータセットのなかから重複を検知してみたいと思います。コードはそのままコピペすれば活用できるものになっています(おそらくですが)
実装
実行環境
GoogleColab
用意した画像データ
・猫の写真(94枚)
・重複した写真(3組)→ 任意の写真3つのコピーを作成
・.jpg形式
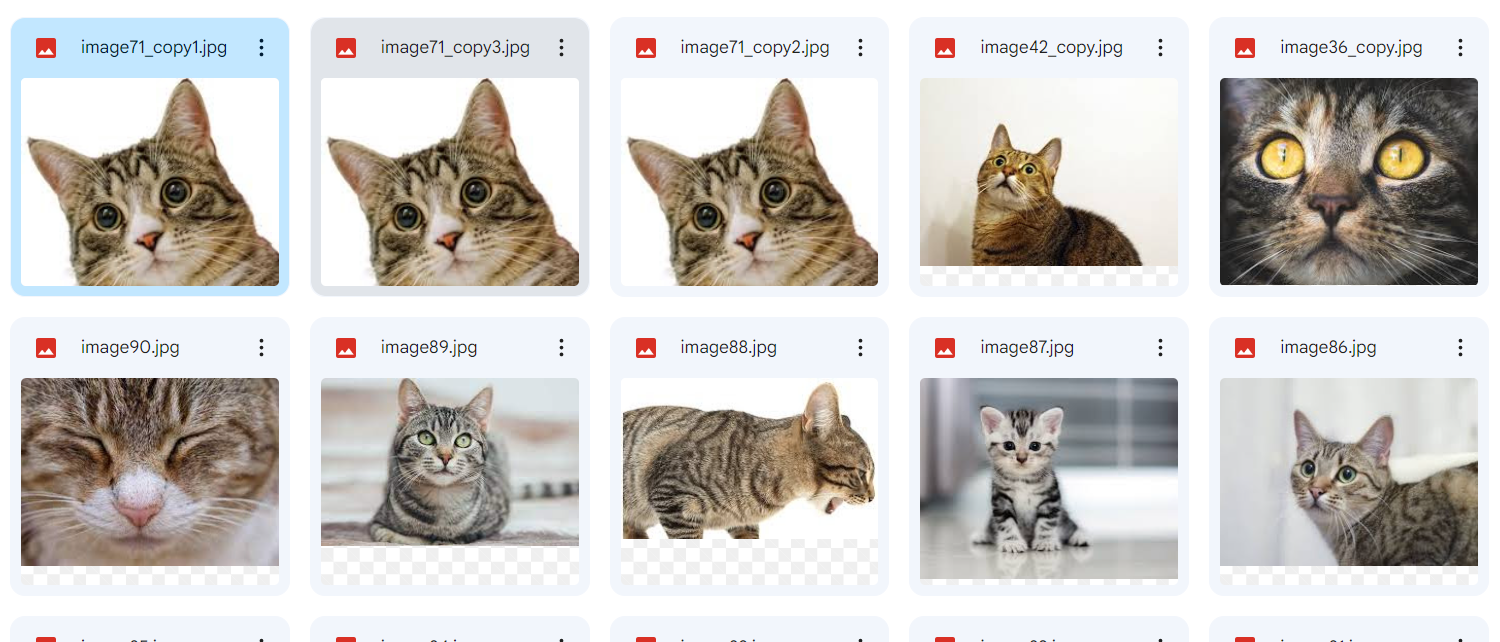
コード
GoogleDriveへのマウント
from google.colab import drive
# Googleドライブをマウントする
drive.mount('/content/drive')
ライブラリのインポート
#ライブラリのインポート
import os
import hashlib
from PIL import Image
import numpy as np
import base64
from IPython.display import display, HTML
from collections import defaultdict
中身のコード(画像が入ったフォルダのパスを忘れずにいれること)
# Function to get image in base64 format
def get_image_base64(image_path):
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode('utf-8')
def get_image_hash(image_path):
with Image.open(image_path) as img:
# Convert image to grayscale for consistency
img = img.convert("L")
# Resize for faster hashing
img = img.resize((8, 8), Image.ANTIALIAS)
# Convert image data to a string and hash it
image_hash = hashlib.md5(np.array(img).tostring()).hexdigest()
return image_hash
# specify your directory path here
directory_path = "画像フォルダのパスを入れてください"
# Dictionary to hold image hashes
hash_dict = defaultdict(list)
for filename in os.listdir(directory_path):
if filename.endswith(".jpg"):
file_path = os.path.join(directory_path, filename)
image_hash = get_image_hash(file_path)
# Append file_path to the list of files sharing the same hash
hash_dict[image_hash].append(file_path)
# Generate HTML for each group of duplicate images
html_str = ""
for file_paths in hash_dict.values():
if len(file_paths) > 1: # if there are duplicates
html_str += "<tr>"
for file_path in file_paths:
html_str += f'<td style="text-align:center">{os.path.basename(file_path)}<br><img src="data:image/jpeg;base64,{get_image_base64(file_path)}" width="200"></td>'
html_str += "</tr>"
# Create HTML table and display
html_str = '<table>' + html_str + '</table>'
display(HTML(html_str))
上記のコードを実行すると、うまく重複した画像が、ファイル名とともに表示されます。

簡単に説明すると、画像のハッシュ値を順番に『hash_dict』に格納していき、同じものがあった場合にその組み合わせを表示するといった感じです。
やっていること自体はとても簡単ですね。
計算量も非常に小さいようですし、かなり実用的な方法なのではないでしょうか。
おわりに
今回は集めた画像の規模が100枚程度でしたが、これがもっと大きくなって数万枚規模になったときに本記事の手法はとても活きてくると思います。
この記事には重複した画像のうち片方を削除するといったコードは書いていませんが、そのあたりを追加するとさらに実用度はあがるかもしれませんね。
みなさんも必要とあらば、ぜひ活用してみてください!
<追記>
以下のコードを実行すれば重複なしの画像データセット作成まで可能になります。この記事のコードに基づいて実行する限りは問題なく動作すると思います!ぜひに!
import shutil
#重複なしの画像データフォルダのパス
new_directory_path = "新しい画像フォルダのパスを入れてください"
# Create new directory if not exists
if not os.path.exists(new_directory_path):
os.makedirs(new_directory_path)
# Copy one of each group of duplicate images to the new directory
for file_paths in hash_dict.values():
# Copy only the first file in each group of duplicates
shutil.copy(file_paths[0], new_directory_path)
print("Duplicate removal complete.")