はじめに
最近神絵生成AIが話題ですね。
絵描きの端くれとしてこの波に乗り遅れるわけにはいかない!ということで、つい最近公開された Stable Diffusion を Google Colaboratory (以下Google Colab)上で実行して遊べるようにしてみました。 ![]()
こちら に記載されている diffusers library を使用してサクッと動かすのがゴールです。
以下環境構築をしてコードを動かすまでのまとめです。
作成したGoogle Colabのノートブックは GitHub で公開しているため、過程とかどうでもいいから使ってみたい方は こちら からどうぞ。
Stable Diffusionについて
オープンソースの画像生成AIです。
私は機械学習の専門家ではないので技術的なことは詳しくないですが、テキストから画像を生成するtext-to-imageのモデルだそうです。
処理に若干時間がかかりますが、こちらの デモサイト でとりあえず使用感を試せます。
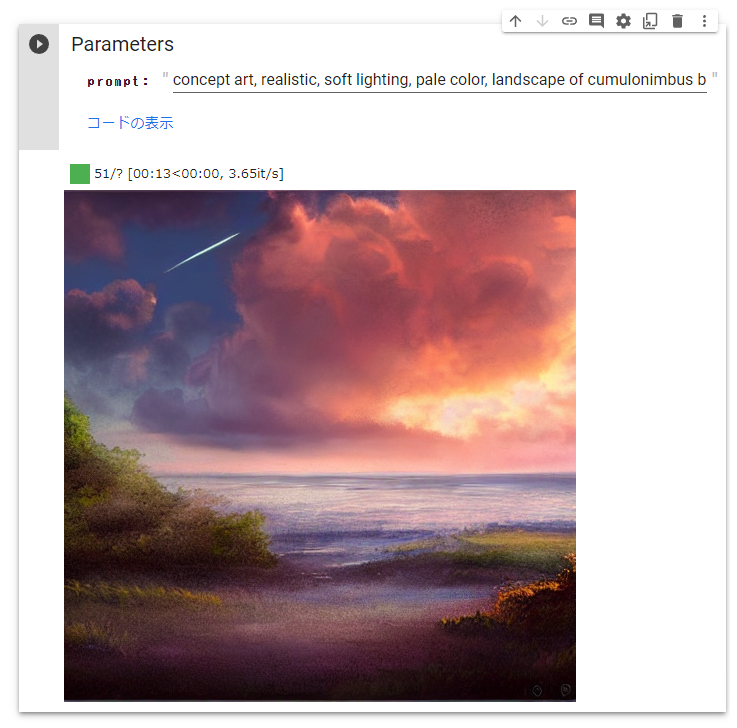
添付の画像は「concept art, realistic, soft lighting, pale color, landscape of cumulonimbus background, summer, sunset, twilight, coast, starry sky」というテキストから生成されたものです。

画像生成の処理を専用のサーバで行うことができる DreamStudio Beta というサービスも存在します。
こちらはアカウント登録が必要ですが、アカウント登録をすると2ポンド分のクレジットがもらえ、クレジットを使い切るまでは爆速での画像生成を体験できます。
・・・ということで、お試しで数回触ってみるだけであれば上記のサイトで十分です。
ただせっかくオープンソースで公開されていますし、実際に触ると分かりますが同じテキストでもランダムにいろいろ生成されるので神絵が出るまでガチャを繰り返したいという場合は自分で実行環境を用意するのがよさそうです。
Google Colaboratoryについて
ブラウザ上でPythonのコードを実行できるサービスです。 ![]()
もう少し詳しく言うと、Googleが提供しているJupyter Notebookのマネージドサービス的なものです。
こんな感じにコードを実行したり結果を表示したりできます。
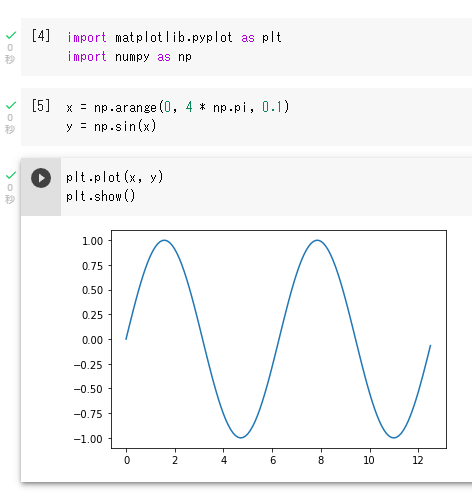
ブラウザ上でコードを実行できるサービスは他にもいろいろありますが、Google ColabではGPUが使えます、しかも無料で!
ということで機械学習の実行環境として重宝されています。
ただ無料で機能制限なく使い放題というわけではなく こちら にあるように制限も存在します。
有名なのが12時間ルールというもので、12時間経つと実行環境が初期化されてしまいます。
もちろん作成したコード、正確には「ノートブック」というドキュメントはちゃんと保存されており、ノートブック内のコードを再実行することで実行環境を再構築できます。
・・・ということで、今回はGoogle Colab上にStable Diffusionの実行環境を構築して、無料で爆速画像生成&神絵ガチャを回してみたいと思います!
Stable Diffusionを使うための事前準備
Google Colab上に実行環境を構築する前にStable Diffusionを使うための準備を行います。
Hugging Faceのアカウント作成
まずはStable Diffusionのモデルを使用するために Hugging Face へのユーザ登録を済ませます。
ページ右上の「Sign Up」から画面の指示に従ってポチポチしていってください。
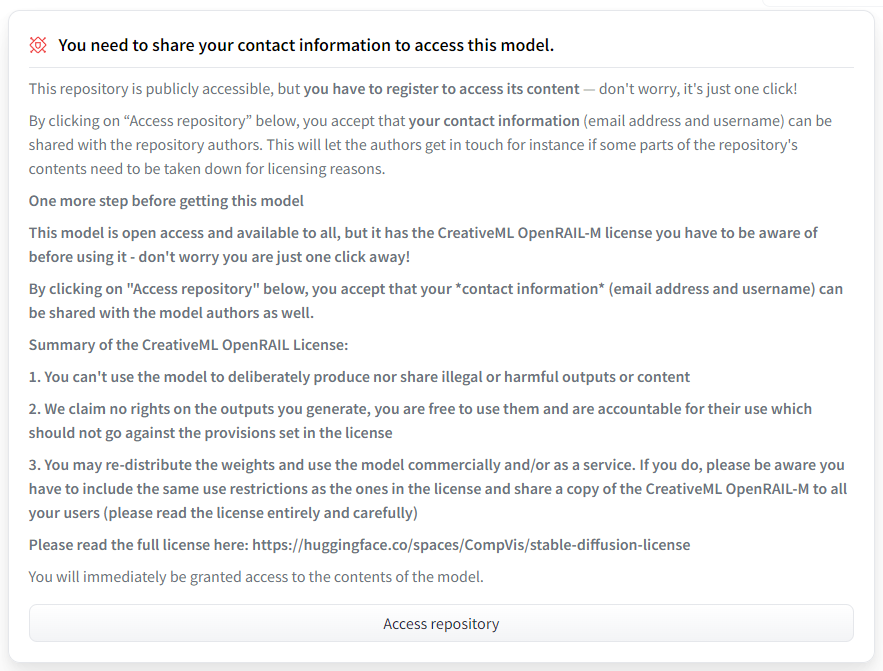
Stable Diffusionのモデルの使用に関する規約への同意
モデルを使用するにあたり、規約(CreativeML OpenRAIL-Mライセンス、およびメールアドレスとユーザー名がモデルの作成者と共有されること)に同意する必要があります。
こちら にアクセスし同意できる方は「Access repository」をクリックしてください。
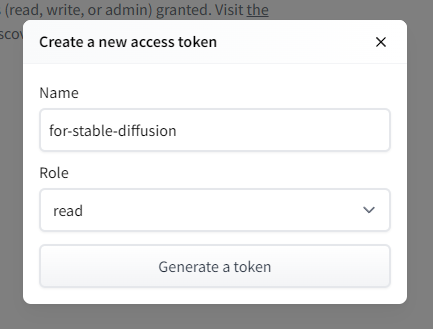
Hugging Faceのアクセストークンの発行
diffusers libraryを実行する際に使用するアクセストークンを発行します。
こちら にアクセスし「New Token」より自分のアクセストークンを発行し、控えておいてください。
トークンの名前は自分で分かるものであれば何でも構いません。
権限は「read」で十分でした。
Google Colabの実行環境構築
Stable Diffusionを使うための準備が終わったのでGoogle Colab上に実行環境を構築していきます。
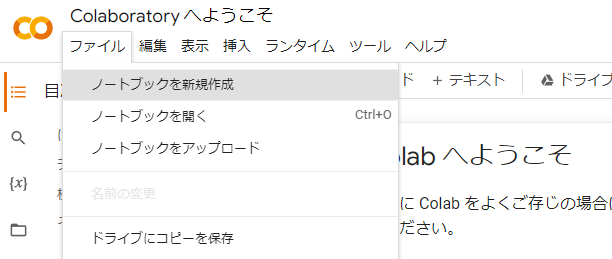
ノートブックの作成
Googleアカウントでログインした状態で こちら にアクセスし「ノートブックを新規作成」をクリックします。
作成したノートブックはGoogleドライブに自動で保存されます。
以下作成したノートブックにいろいろな処理を記載していきます。
GPUの使用
実行環境でGPUを使用するために「編集」→「ノートブックの設定」からGPUを割り当てます。
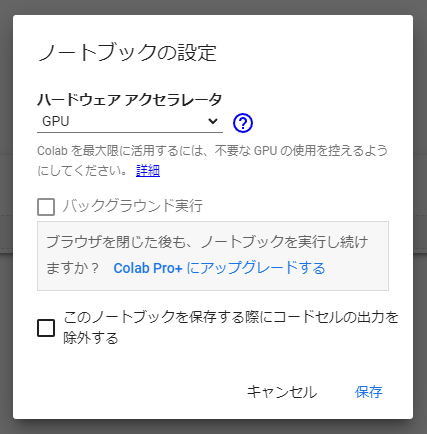
割り当てが問題なく行えているかどうかは以下のコードで確認できます。
!nvidia-smi -L
依存関係のインストール
以下のコードを実行し、必要なライブラリをインストールします。
!pip install --upgrade diffusers==0.12.1 transformers==4.26.0 accelerate==0.16.0 scipy==1.* ftfy==6.*
セットアップ
Stable Diffusionのモデルのダウンロードやパイプラインの構築を行います。
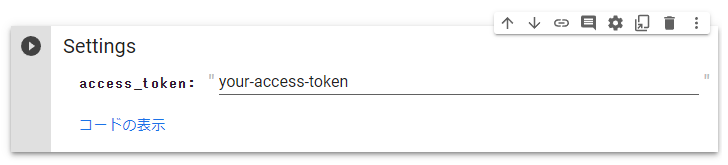
予め発行したHugging Faceのアクセストークンを access_token に設定し、以下のコードを実行します。
import torch
from diffusers import StableDiffusionPipeline
#@title Settings
access_token = "your-access-token" #@param {type:"string"}
# パイプラインを構築する。
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float16,
use_auth_token=access_token
).to("cuda")
画像生成
画像を生成します。
生成したい画像の内容を prompt に記述し、以下のコードを実行します。
from IPython.display import display_png, Image
from torch import autocast
#@title Parameters
prompt = "a description of the image" #@param {type:"string"}
# 画像を生成する。
with autocast("cuda"):
image = pipe(prompt).images[0]
# 画像を保存する。
file_name = "image.png"
image.save(file_name)
# 画像を表示する。
display_png(Image(file_name))
神絵ガチャを回す
自分で環境構築を行うとこういうことが自由に行えるのがいいですよね。
大量の画像を生成し、生成した画像をGoogleドライブに保存してみます。
なお、ガチャを回しすぎるとGoogle Colabのリソース制限に引っかかってしばらくGPUが利用できなくなるのでほどほどに(ドキュメントによると状況によって変動する動的な使用制限を設けているとのことで、どのくらい使ったら制限に引っかかるのかはよく分かりません・・・)。
まずはGoogleドライブをマウントするために以下のコードを実行します。
from google.colab import drive
drive.mount("/content/drive")
画像を生成します。
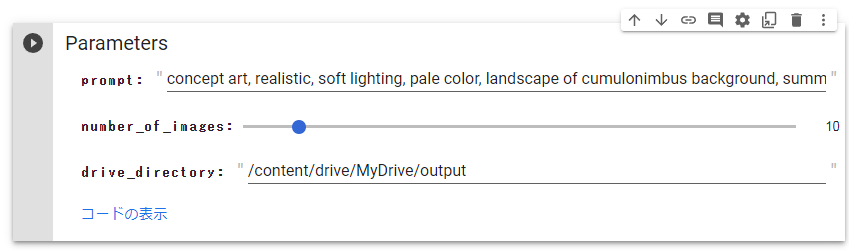
パラメータを設定して以下のコードを実行します。
-
prompt:生成したい画像の内容。 -
number_of_images:生成する画像数。 -
drive_directory:保存先ドライブのディレクトリ。
import datetime
import os
from torch import autocast
#@title Parameters
prompt = "a description of the image" #@param {type:"string"}
number_of_images = 10 #@param {type:"slider", min:1, max:100, step:1}
drive_directory = "/content/drive/MyDrive/output" #@param {type:"string"}
# 画像の保存先となるディレクトリがなければ作成する。
os.makedirs(drive_directory, exist_ok=True)
# 画像のファイル名が被らないようにするための文字列を用意する。
yyyymmddhhmmss = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
# 指定した回数、画像生成&保存を繰り返す。
for i in range(number_of_images):
with autocast("cuda"):
image = pipe(prompt).images[0]
file_path = os.path.join(drive_directory, f"image-{yyyymmddhhmmss}-{i:03}.png")
image.save(file_path)
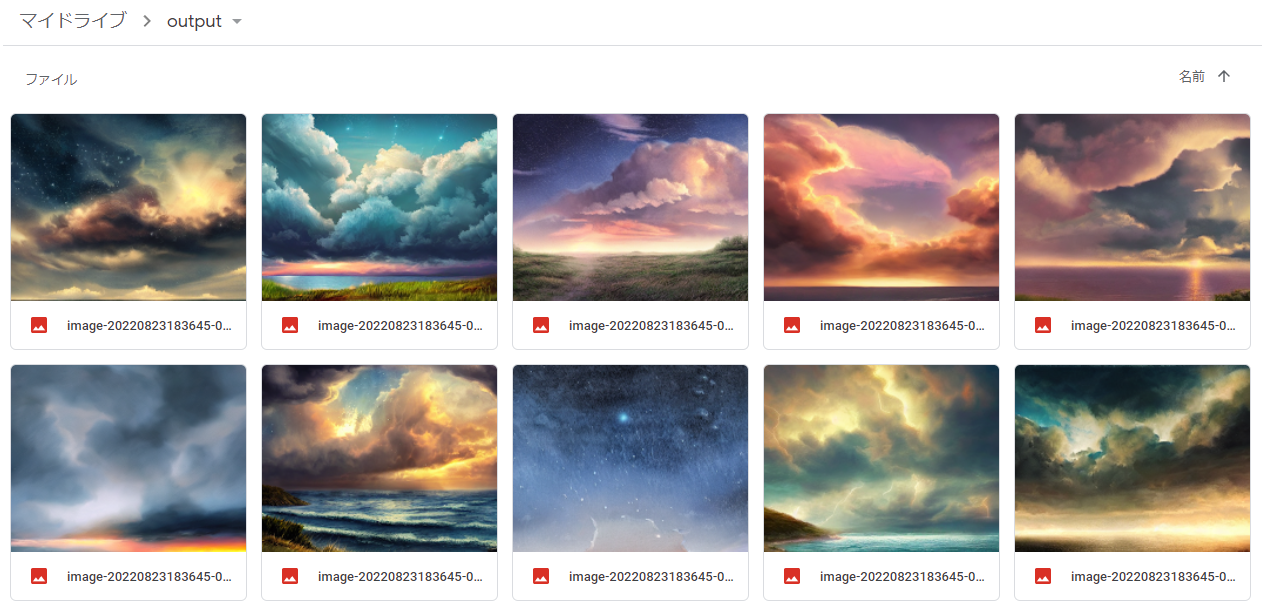
神絵ガチャ無料10連の結果です。
こんな感じに画像がマイドライブの output 配下に保存されます。 ![]()
今回はGoogleドライブに保存しましたが、他にもローカルにDLすることも可能です。
詳しくは こちら を参照ください。
まとめ
生成した画像の中からいい感じのものを選んでベースとして使えば、背景とか描くのだいぶ楽になりそうな予感。
今後はこういったツールもうまく使いこなしながら創作活動していきたいですね。
あと こちらのブログ によると画像生成時に他にもパラメータを設定できるようなので、気が向いたらまたいろいろ触ってみようと思います。
主な更新履歴
2023/02/05
2023/02/05現在 StableDiffusionPipeline.from_pretrained の実行時に TypeError: getattr(): attribute name must be string となってしまう件を修正しました。
- diffusersライブラリを0.2.4から0.12.1を使用するように変更しました。
- ライブラリのバージョンアップに伴い、使い方が変わった部分があるので一部コードを修正しました。