はじめに
RAGが認知されて2024年は、多くのRAGを用いたシステムが世の中に生み出された年だったように感じます。2025年もまだまだ、成長を続け世の中で活躍すると思われるRAGについて改めて、その性質や勘違いされやすい点を整理したいと思います。
こんな人にお勧めです
・RAGを用いたシステム開発を始める方
・RAGを用いたシステムを業務に取り入れる方
RAGとは
RAGとは、Retrieval-augmented generation(検索拡張生成)の略です。
事前にデータベースに取り込んだ情報をAIで検索することで、意味として近いものを使用して回答を生成することができます。ChatGptと仕組みが異なるのは元情報がないと基本的には回答を生成できない点です。
メリットは、一般的に検索に利用できない情報を利用して回答の生成が可能です。
反してデメリットは、元情報を登録するのにヘッダーや目次、一覧情報などを事前に削除したりする必要があるなど情報を準備するのに一定の制約のようなものがあります。
そんなRAGという技術は、当然万能な魔法のツールではありません。
というのも、このRAGという技術、Googleなどのキーワード検索と異なり、LLMが意味としてこうだろうというベクトル(数値)に置き換えたうえでその位置関係で検索を行うセマンティック検索という手法を用いています。
その為、全然関係がない情報でもベクトルさえ近ければ、何でも検索してきてしまうという欠点を抱えており、実はただ実装すればOKでは使えないのが辛いところです。
RAGの成果を出にくいよくある勘違い
➀ キーワード検索と同じ入力を行う
これは開発当初や利用者で多い勘違いなのですが、RAGを用いたシステムを実行する際、GooGleなどのキーワード検索するような入力をしてしまうことが多いです。
例えば、【コマンド 削除 コマンドプロンプト】など、キーワードを入力することでGoogleなどキーワード検索では求めている情報取得しようとします。
これが、RAGの場合はセマンティック検索という意味検索と呼ばれる生成AIを用いた文脈が理解できる文書を入力する必要があります。
先ほどの例でいえば、【コマンドプロンプトで削除する為のコマンドを教えてください】のように入力する必要があります。
この入力のやり方を間違えると、回答結果が出にくくなります。
また、抽出したい情報と同じキーワードを入力したからといって必ずその情報を抽出できるわけではありません。あくまで、抽出したい情報と意味として近い言葉を入力するという点を意識してください。
➁ RAGはどんな情報も回答できる
メリットばかりがフォーカスされて、社内規定など特定の団体しか持ちえない情報を取り込んで使用できるという点は知られていますが、デメリットとして知らない情報に関しては全く回答を生成できません。
その為、知らずになんでも質問をして、全然回答を生成できないと感じる場合があります。その場合は、必ず事前に取り込んだ情報なのかを確認する必要があります。
確認するイメージとしては、下の画像の一番左のデータベースの部分です。
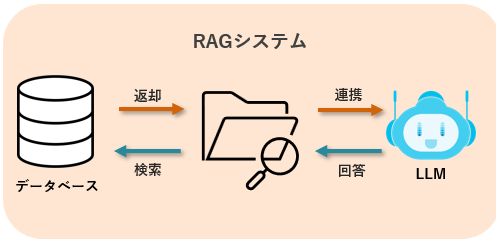
RAGシステムは、データベースに取り込んだ資料データをセマンティック検索を行ってその情報を抽出することで、LLMへ連携するデータを得ることが出来ます。
そのデータベースに情報自体が無い場合は当然回答も出来ない、という結果になります。その点を気を付けてください。
➂ 沢山情報を与えると回答精度が上がる
RAGの場合、情報量が多いほどハルシネーション(幻覚)が発生する可能性が高くなります。これには、与えられた情報の中から意味として近いものをLLMが抽出して回答を生成することに理由があります。情報が多いほど、ベクトルが近いと判断した誤った情報を抽出する可能性が上がり、結果想定していた正しい情報がLLMへ連携されなかったり、されたとしても無関係な情報が多いことで正しい回答を生成できない場合も増えます。
その為、RAGを利用する際は可能な限り、正しい情報を少ない情報でLLMへ連携させる必要があります。
➃ 回答速度が早い
うえの絵でも記載してありますが、セマンティック検索の場合は最初にセマンティック検索を行い、その抽出結果をLLMへ連携し、回答を生成してもらうため、GooGleなどのキーワードに比べて速度は遅くなります。
例えば、なんの工夫を行わずにただ実装した場合、1分はかかると考えていたほうがいいです。ただの検索としての利用を想定していた場合、この速度の遅さにがっかりして使えないと判断されがちです。
➄ どのモデルでも性能は変わらない
現行(令和7年1月時点)、ChatGptのGpt4o、CohereのCommand-R+、AnthropicのClaude3.5などいくつかのモデルがLLMには存在しています。それぞれに回答の精度や速度、API連携の金額、日本語の理解度が異なる為、どれが一番適しているかを試しながら実装してみることをお勧めします。
課題は解消できるのか?
これらの課題について、解消が可能なのか完璧ではないものの実用レベルでの解消は可能です、と回答致します。というのも、例えば回答精度を上げれば、回答速度が低下するなど二律背反となる部分が絶対に存在し、何を優先させるかを決めて開発することが求められるからです。
課題として解消したいものを定めて、それを解消できたところでその他にも着手していくことを最も重要となります。
終わりに
RAGは、その仕組みを知るともっと精度の高いシステムを構築したり、求めた回答を得ることが出来るようになります。どんな文章をLLMに与えたらよいのか、どのような質問をしたら良いのか、どのくらいの量に抑えたほうがLLMの回答精度が上がるのか、このようなことを意識しながら、RAGに触れて頂けたらと思います。