概要
脳死状態でもansible-Playbookを簡単に安全に実行できることを考えた末、Excel + Dynamic Inventoryに行き着きました。
経緯
Playbookをいくら汎用性が高く再利用できるものを使っていても、ホスト毎に変わるhost_varsの登録をyamlで登録するような運用フローだと、Gitのハードルやyamlの書き方で躓くケースがありました。
ユーザー側にこのあたりの運用を実施してもらうにあたって、通常のヘルプデスク業務の傍らで専門的な知識を吸収してもらうのは厳しい。
Surveyじゃだめなの?
以下の理由によりSurveyの利用は見送りました
・登録された情報をインベントリ情報として残しておきたい
・複数台同時実行の制御が難しい
・ホスト変数が10も20もあるようなケースだと登録が手間になる
動作確認環境情報
Ansible Tower 3.8.0
ansible 2.9.14
python 2.7.5
xlrd 1.2.0
※xlrdは2.0.0からxlsxがサポートされなくなるので、古めのものを使ってます
コード
長めです。
# !/usr/bin/python
# -*- coding: utf-8 -*-
import xlrd
import sys
import json
import os
book = xlrd.open_workbook(os.environ["XLSXFILENAME"]) # 環境変数XLSXFILENAMEで指定されたexcelファイルからBook作成
h_sheet_name = "hosts"
g_sheet_header = "groups" # グループ変数を「groups」から始まる名前のシート(「groups1」「groups2」など)に格納
# 型変換用関数指定のsheet,row,col列次第でvalを型変換した値を返す
def typeCheck(sheet , row , col , val):
typename = sheet.cell(row,col).value
if typename == "bool":
return bool(val)
elif typename == "int":
return int(val)
elif typename == "float":
return float(val)
elif typename == "string":
if (type(val) is unicode):
return str(val.encode('utf-8')) #2バイト文字の処理用
else:
return str(val)
else:
return val
# グループ変数辞書の作成
# g_sheet_header変数の文字列から始まるシートをグループ変数として辞書生成
# g_sheet_header変数の文字列後に「@」が続くシート名の場合は、「@」以降の文字列をグループ名として縦長形式で変数を記述する
groupvars = {}
groupvars["NoGroupMember"] = {}
groupvars["NoGroupMember"]["hosts"] = []
for g_sheet in book.sheets():
# 縦長形式の場合
if (g_sheet.name.startswith(g_sheet_header + "@")):
groupname = g_sheet.name.replace(g_sheet_header + "@", '', 1) #グループ名はシート名からヘッダ部分を除去したもの
groupvars[groupname] = {}
groupvars[groupname]["vars"] = {}
groupvars[groupname]["hosts"] = []
varnametmp = g_sheet.cell(0,0).value #シートの1列1行目がリストのトップレベル変数名
groupvars[groupname]["vars"][varnametmp] = []
gvar_name_row = 1 # 2行目にリスト内の変数名
gvar_type_row = 2 # 3行目にboolと入れていればbool値として登録。4行目は人間が見る用なので無視。
for g_row in range(4, g_sheet.nrows): # 5行目(row=4)以降からのデータをリストに格納。
for g_col in range(0, g_sheet.ncols):
# 最初の列の処理でappend。
ADDR = g_sheet.cell(gvar_name_row,g_col).value
if (g_col == 0):
groupvars[groupname]["vars"][varnametmp].append({ADDR: typeCheck(g_sheet,gvar_type_row,g_col,VAL) })
if (ADDR != ""): #変数名が空白の場合、それは処理しない
VAL = g_sheet.cell(g_row,g_col).value
if (VAL != ""):
groupvars[groupname]["vars"][varnametmp][-1][ADDR] = typeCheck(g_sheet,gvar_type_row,g_col,VAL)
# 横長形式の場合
elif (g_sheet.name.startswith(g_sheet_header)):
gvar_name_row = 0 # 最初の行に変数名を記載
gvar_type_row = 1 # 2行目に型を記入
for g_row in range(3, g_sheet.nrows): # 4行目以降、各グループごとのループ
groupname = g_sheet.cell(g_row,0).value
groupvars[groupname] = {}
groupvars[groupname]["vars"] = {}
groupvars[groupname]["hosts"] = []
for g_col in range(1, g_sheet.ncols): # 2列目以降、各変数ごとのループ
ADDR = g_sheet.cell(gvar_name_row,g_col).value
if (ADDR != ""): #変数名が空白の場合、それは処理しない(計算用に作ったダミーセルなど)
VAL = g_sheet.cell(g_row,g_col).value
if (VAL != ""):
if (ADDR.count(".") == 0):
groupvars[groupname]["vars"][ADDR] = typeCheck(g_sheet,gvar_type_row,g_col,VAL)
elif (ADDR.count(".") == 1):
if (ADDR.split(".")[0] not in groupvars[groupname]["vars"]): #新しいtop key
groupvars[groupname]["vars"][ADDR.split(".")[0]] = []
LAST = groupvars[groupname]["vars"][ADDR.split(".")[0]]
#リストが空、またはリストの最後の辞書に重複するキーがある場合は、リストの末尾に新しい辞書を追加
if ((not LAST) or (ADDR.split(".")[1] in LAST[-1])):
groupvars[groupname]["vars"][ADDR.split(".")[0]].append({ ADDR.split(".")[1]:typeCheck(g_sheet,gvar_type_row,g_col,VAL) })
#リストの最後の辞書に重複するキーが無い場合は、リストの最後の辞書にデータ追加
else:
groupvars[groupname]["vars"][ADDR.split(".")[0]][-1][ADDR.split(".")[1]] = typeCheck(g_sheet,gvar_type_row,g_col,VAL)
hostvars = {} # ホスト毎の属性を格納する
for sheet_tmp in book.sheets():
if (sheet_tmp.name == h_sheet_name): # hostsシートがある場合のみ処理。無い場合はgroupのみ登録
h_sheet = book.sheet_by_name(h_sheet_name) # ホスト変数を「hosts」シートに格納
# ホスト変数の辞書生成
hvar_name_row = 0 # 最初の行に変数名を記載
hvar_type_row = 1 # 2行目に型を記入。3つ目の行は人間が見る用なので無視。
for h_row in range(3, h_sheet.nrows): # 4行目以降、各ホストごとのループ
hostname = h_sheet.cell(h_row,1).value #2列名がホスト名
# グループ列の処理、グループ名は「,」区切りで記載。指定されたグループ変数hostsにホストを追加
for gstring in h_sheet.cell(h_row,0).value.split(","):
if (gstring == ""): # グループ指定が空文字の場合、グループに非所属。暫定でNoGrouupMemberに所属させる
groupvars["NoGroupMember"]["hosts"].append(h_sheet.cell(h_row,1).value)
elif (gstring in groupvars.keys()):
groupvars[gstring]["hosts"].append(h_sheet.cell(h_row,1).value) #1列目はグループ名なので、groupvarsにホストを追記
else:
print("ERROR: host + " + hostname + ": group name " + gstring + " not found. known group is " + ','.join(groupvars.keys()))
hostvars[hostname] = {}
for h_col in range(2, h_sheet.ncols): # 3列目以降、各変数ごとのループ
ADDR = h_sheet.cell(hvar_name_row,h_col).value
if (ADDR != ""): #変数名が空白の場合、それは処理しない(計算用に作ったダミーセルなど)
VAL = h_sheet.cell(h_row,h_col).value
if (VAL != ""):
if (ADDR.count(".") == 0):
hostvars[hostname][ADDR] = typeCheck(h_sheet,hvar_type_row,h_col,VAL)
elif (ADDR.count(".") == 1):
if (ADDR.split(".")[0] not in hostvars[hostname]): #新しいtop key
hostvars[hostname][ADDR.split(".")[0]] = []
LAST = hostvars[hostname][ADDR.split(".")[0]]
#リストが空、またはリストの最後の辞書に重複するキーがある場合は、リストの末尾に新しい辞書を追加
if ((not LAST) or (ADDR.split(".")[1] in LAST[-1])):
hostvars[hostname][ADDR.split(".")[0]].append({ ADDR.split(".")[1]:typeCheck(h_sheet,hvar_type_row,h_col,VAL) })
#リストの最後の辞書に重複するキーが無い場合は、リストの最後の辞書にデータ追加
else:
hostvars[hostname][ADDR.split(".")[0]][-1][ADDR.split(".")[1]] = typeCheck(h_sheet,hvar_type_row,h_col,VAL)
# NoGroupMemberグループの内容をレイヤを上げてall配下にする(そうすると、グループに所属しないホストとして取り込まれる)
groupvars["all"] = groupvars["NoGroupMember"]["hosts"]
del groupvars["NoGroupMember"]
# 2つのデータを結合して出力
output_dict= groupvars
output_dict["_meta"]={}
output_dict["_meta"]["hostvars"] = hostvars
print(json.dumps(output_dict, sort_keys=True, indent=4))
Excelサンプル
hostsシート

hostsシートにはホスト情報を登録します。
1行目には変数名を、2行目には変数の型を記入します。
3行目以降はユーザーに記入してもらう箇所になりますので、ユーザーがわかりやすい名前をつけます。
HDDのようなネストする必要のある変数はドット区切りで記入します。
グループが空白の場合は、どのグループにも所属しません。
groupsシート
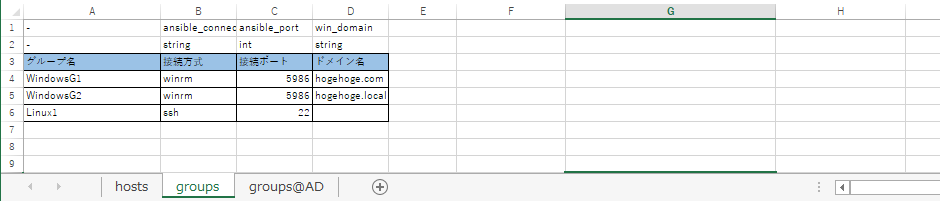
groupsシートにはグループ共通の情報を登録します。
登録方法はhostsシートと変わりません。
groups@ シート(オプション)
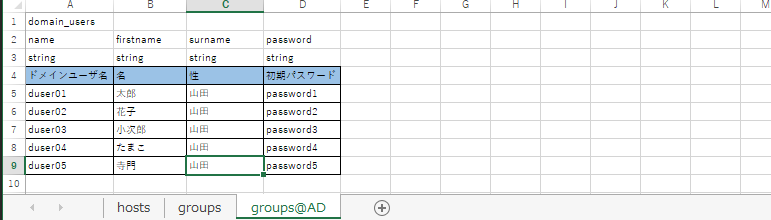
@マークの後ろはグループ名を登録します。
hostsシート等では、複数ホストの変数を登録する場合に向いていますが、単一ホストでループするような処理(ドメインユーザの登録ような)だと見づらいので、横長ではなく縦長に登録していくことを想定しています。
ここではADグループのサーバに対して登録する変数を記載してます。
使い方
事前設定
環境変数としてXLSXFILENAMEをansibleサーバに設定します。
xlsxの保管場所になります。以下は例です。
XLSXFILENAME=/usr/local/share/sample.xlsx
必要に応じてSAMBA共有するといいでしょう。
ansibleの場合
上記のコードをinventory.pyなどのファイル名で保存し、ansible-playbookコマンドで実行
ansible-playbook -i inventory.py sample-playbook.yml
ansible towerの場合
以下を参考にカスタムインベントリとして登録します。
参考文献
基本的には上記をベースにさせていただき、ネストされた変数への対応やExcel側で変数を制御できるような改修を加えています。