JTPA ML勉強会向けに、基本となるクラシックなDL論文をまとめておきます。
2014-2016はファンダメンタルなテクニック/アーキテクチャについての論文が多く、導入することで一気にパフォーマンスが上がったり収束しやすくなったりして大変エキサイティングな あげあげ〜 な時代でした。
今では何気なく普通に使われているものばかりですが、それぞれの論文がどんな問題にフォーカスをあて、どうやって解決してきたのかを見ておくことでML/DLの本質が理解しやすいと思っています。
みんなで読もう、DL!
基本テクニック系 論文
1. ReLU
“Rectified Linear Units Improve Restricted Boltzmann Machines” (2010) Cited by 9,076
DLの立役者ヒントン先生の論文。それまでに使われていたシグモイドやtanhなどの伝達関数では、入力の値が大きくなると出力値の傾きがゼロに近くなってしまって学習時にバックプロパゲーションでフィードバックを与えることができないという問題がありました。
ReLUを使うとx>0なら傾き(微分値)は常に1となり計算コストがかからず、それでいて非線形性も担保できます。これによりDLでレイヤーを重ねることのコストが大幅に下がりました。

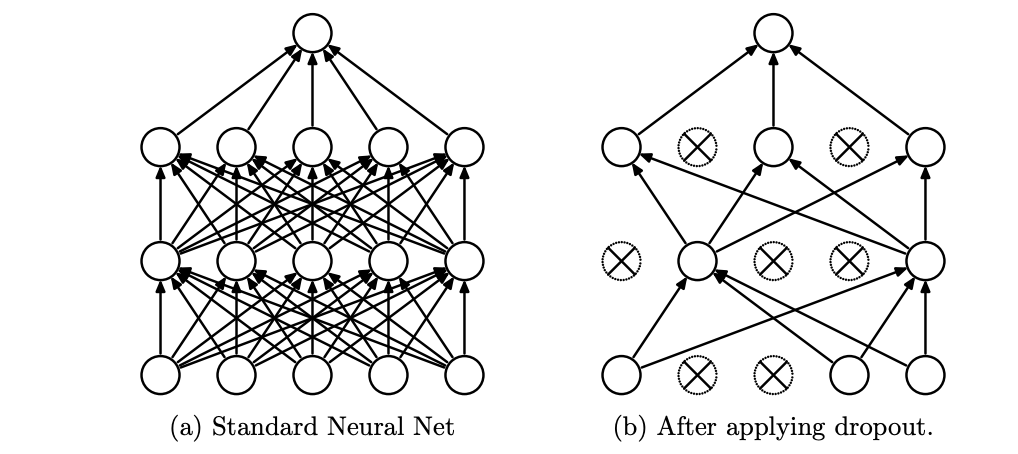
2. Dropout
“Dropout: A Simple Way to Prevent Neural Networks from Overfitting” (2014) Cited by 19,126
これもヒントン先生の論文。学習中にランダムにノードの出力をカットすることで、まだ学習の進んでいないセル・経路の学習を促すテクニックです。例えば一つ前のレイヤーで有能なノードが現れて後段の皆がそれに迎合する出力を出すようになったところで、突然その有能なノードが消えたため他の情報を使って推測することを促されるイメージです。あるいは汎化性能をあげることにも役立ちます。
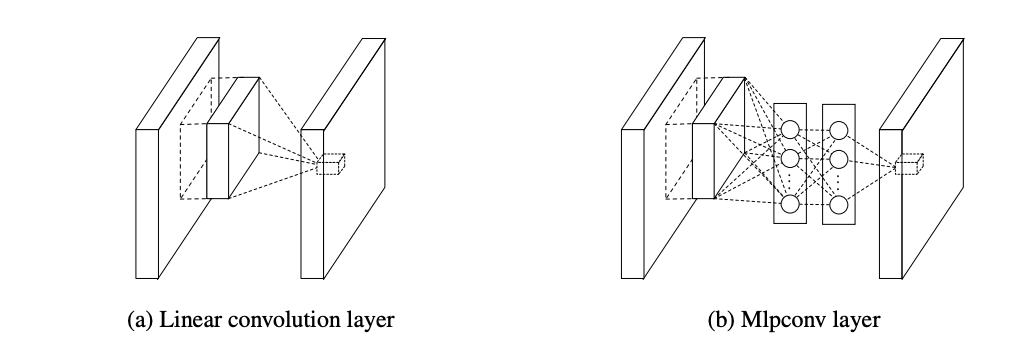
3. Network In Network
“Network In Network” (2013) Cited by 3,688
”CNNの一つのセルの中にさらにNeural Netを入れたもの”と聞くと何やら複雑に聞こえますがこれは単に1x1のCNNです。これを使って入力データの次元を削減し新しい特徴量にマッピングし直したり、後述するResidual Blockに入れるために次元数を合わせることができます。複数のレイヤーからの入力をマージしたり、安価に非線形性をあげたりなどシンプルで使いやすいアーキテクチャです。
4. Heの初期化
“Delving deep into rectifiers: Surpassing human-level performance on imagenet classification” (2015) Cited by 7,668
tensorflowなどのフレームワークを用いた場合、大抵のウェイトはデフォルトでこの論文の方法で初期化されていると思います。
例えば初期のウェイトが大きすぎた場合、各層の出力値は層を経るごとにどんどん大きくなり発散しオーバーフローしてしまいます。逆にウェイトが小さすぎた場合は値が減衰し最終レイヤーに到達する前に消失してしまいバックプロパゲーションで学習することができません。この論文では利用する伝達関数ごとに、各レイヤーでの出力値の分散が一様になるように初期値を決める方法を提案しています。
ただし後述するBatch Normalization, Adam optimizer, ResNetなどのアーキテクチャが浸透するにつれ、現在では初期値はあるていど適当でも大丈夫な気もしますが。
5. Adam オプティマイザ
“Adam: A Method for Stochastic Optimization” (2014) Cited by 41,484
個人的なDL3種の神器の一つ。全てのパラメータに共通の学習係数を持つのではなく、各パラメータごとに学習係数を保持しておく手法です。最初は学習係数を小さくすることで初期のパラメータの発散を抑え、さらにはパラメータ探索時にモーメントを持たせることで勾配が小さいところでもパラメータ探索を進めることができます。
これと合わせて学習係数のdecay(減衰)を組み合わせることで比較的簡単にモデルの最高性能を得ることができます。
6. Batch Normalization
“Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” (2015) Cited by 17,501
個人的なDL3種の神器の一つ。BN(Batch Normalization)は、各レイヤーの特徴量の出力を平均が0で分散が一定になるように整流してくれます。
これが何故重要かというと、例えばあるレイヤーが学習をした結果、パラメータ(ウェイト+バイアス)が更新されたとします。その場合次のレイヤーに入ってくる値の分布が変わることになり、次のレイヤーは学習済みのパラメータを新しい入力値に合わせて修正しないといけません。それがどんどん次のレイヤーに伝播していくことになり、モデルのレイヤー数が増えると前段の学習時に後段のモデルの修正に大きな時間がかかりどんどん不安定になってしまいます。
またBNを使うと入力特徴量がノーマライズされていなかったりダイナミックレンジが高い状態でもDLを適用することができ、大変便利なテクニックです。
CNN/画像処理アーキテクチャ系 論文
とりあえず下記の論文をさらっと読んで構造を確認しておくと、ネットワークの構成やハイパーパラメータ(CNNのサイズ、レイヤー数、フィルタ数、プーリング)にあたりをつけるのに役立ちます。
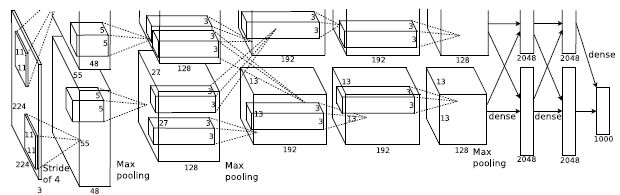
1. AlexNet
“ImageNet Classification with Deep Convolutional Neural Networks” (2012) Cited by 60,985
大規模画像認識コンテスト(ILSVRC)で優勝し、DLが着目される発端となったモデルです。当時の他の画像処理アルゴリズムに対してシンプルな構成にも関わらず大量のパラメータ(約6000万)を使って高い性能を出しました。CNN + Max pooling + Dropout + FCN の基本構成(8レイヤー)です。
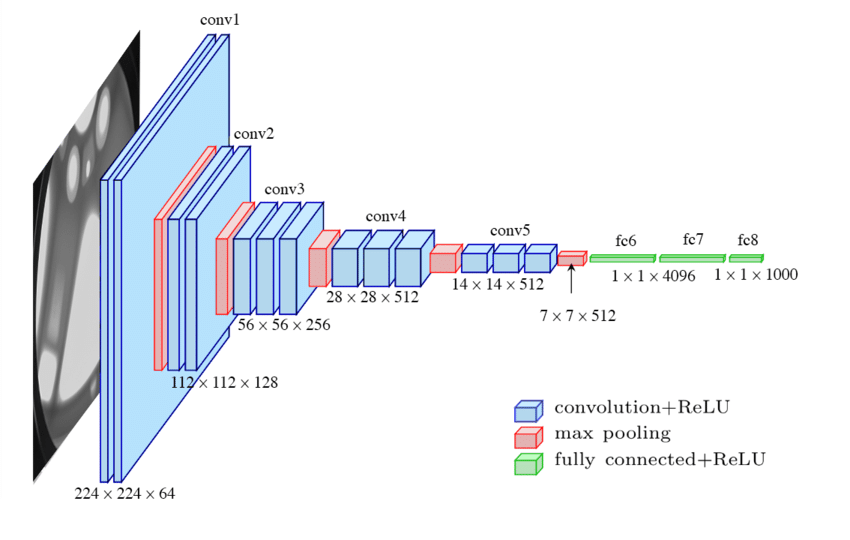
2. VGGNet
“Very deep convolutional networks for large-scale image recognition” (2014) Cited by 36,846
3x3の最小のCNNを使うことで学習の負担を減らし、代わりに計19レイヤーまで深さ方向に拡張して非線形な表現力を上げました。このネットは画像から特徴を抽出するのに便利で、学習済みモデルは特徴抽出機としても今でも良く使われてます。
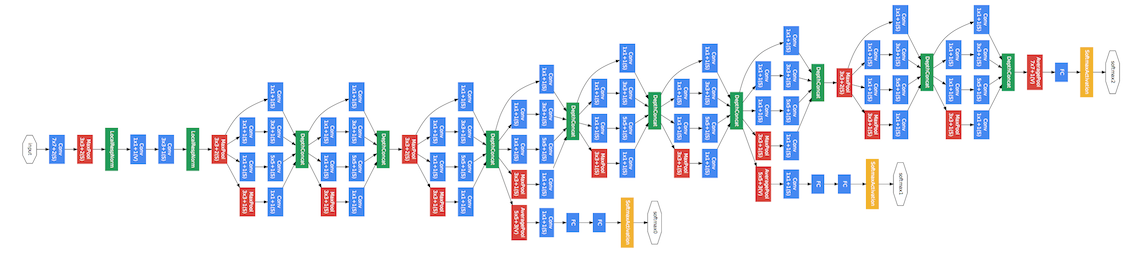
3. GoogLeNet
“Going Deeper with Convolutions” (2015) Cited by 20,961
CNNを並列に構成することで複数サイズのカーネルを使って特徴を計算できるだけでなく、計算資源の有効活用も図られています。さらには推論の出力も三箇所用意されていて、複雑なモデルでも部分的に学習することが可能です。
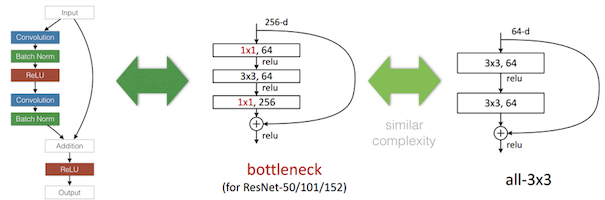
4. ResNet
“Deep Residual Learning for Image Recognition” (2015) Cited by 44,206
レイヤーの入力値を、複数のCNNで構成される中間層のアウトプットに足しこんだボトルネットと呼ぶ構造を提案しました。Residual(残差あるいは差分)だけを学習するようにして、学習の最初期段階でも出力が安定していて発散しにくく、152層という非常に深いモデルでも学習できるようになっています。

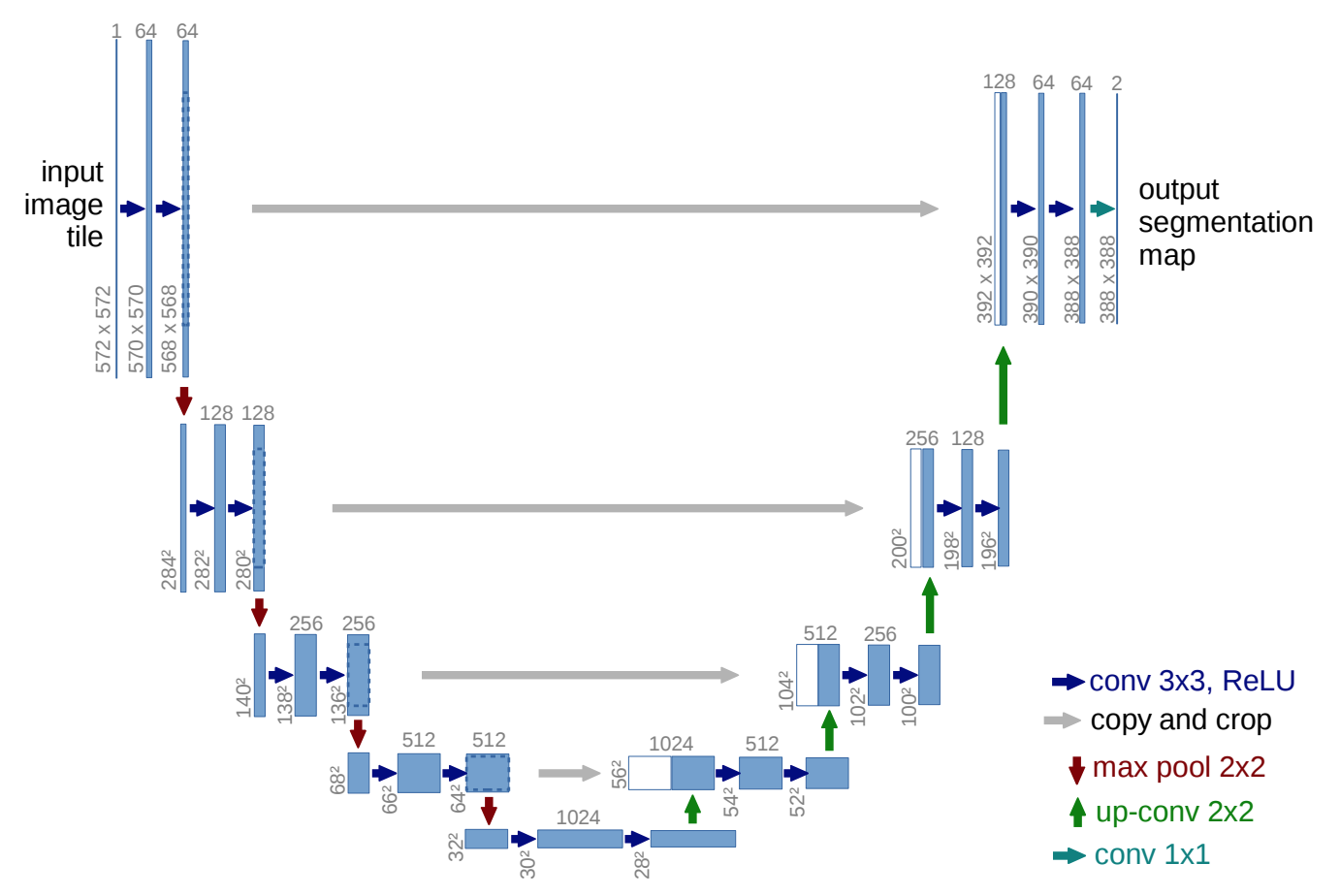
5. U-Net
[“U-Net: Convolutional Networks for Biomedical Image Segmentation”]
(https://arxiv.org/pdf/1505.04597.pdf) (2015) Cited by 13,442
今まで上で見たモデルは全て、画像内の各部から得られた情報を集約し最終的に一つの答えを出すものでした。こちらは各ピクセルごとに情報を出力できます。医療系の画像診断や、写真内に写っている人や背景を分離する時などに良く使われます。
各CNNブロックの出力を保持しておき、pooling(縮小)を経てより広域のサマライズされた情報を抽出した後、それをup sampling(拡大)しながら浅いレイヤーのローカルな情報と合わせて最終的な情報を出力します。
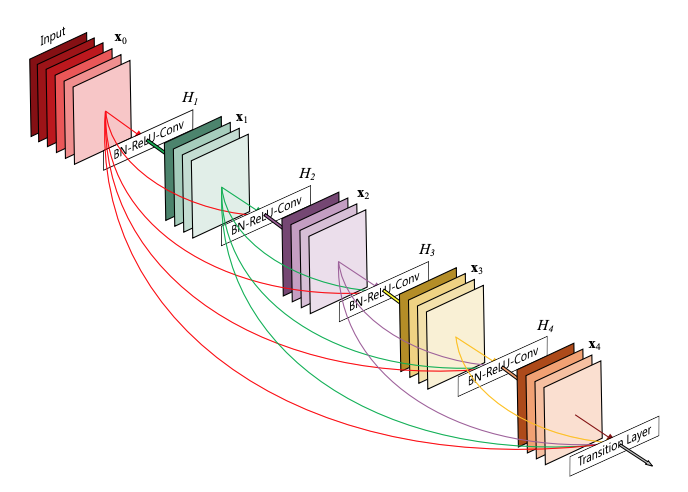
6. DenseNet
[“Densely Connected Convolutional Networks”]
(https://arxiv.org/pdf/1608.06993.pdf) (2016) Cited by 8,513
イメージとしてはResNetをより広域のブロックに適用したものです。各CNNブロックの出力を単に次のブロックに送るのではなく、それより前のブロックの出力を入力に使うことでreceptive fieldの狭いより一次入力に近い値も合わせて使うことができます。
時系列処理/重要アーキテクチャ系 論文
1. RNN
“Sequence to sequence learning with neural networks” (2014) Cited by 10,067
例えば時系列データ処理において、前フレームのモデルの出力層の一つ前の中間層出力を保持しておき、次のフレームで入力データと共に別の入力値として利用する構造です。
今までのDNNでは常に決まったサイズの入力しか入れられなかったものが、可変長のサイズの入力を受け取りまた可変長の出力を出すことができる点でも画期的なものでした。これにより一気に文章や音声のような時系列データの処理にDLが応用されていきます。

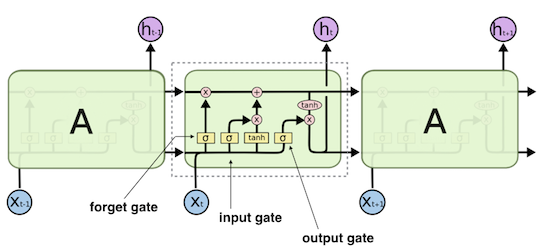
2. LSTM
“Long short-term memory” (1997) Cited by 30,320
個人的なDL3種の神器の一つ。例えばRNNで文章を処理する場合、ずっと前の段落で言及された内容を保持しておくことは構造的にほぼ不可能でした。LSTM(Long Short Term Memory) では内部にstateを持つことができ、時系列でのパターン認識能力が格段に向上しています。
3. GAN
“Generative adversarial nets” (2014) Cited by 17,929
"Unsupervised representation learning with deep convolutional generative adversarial networks" (2015) Cited by 6,010
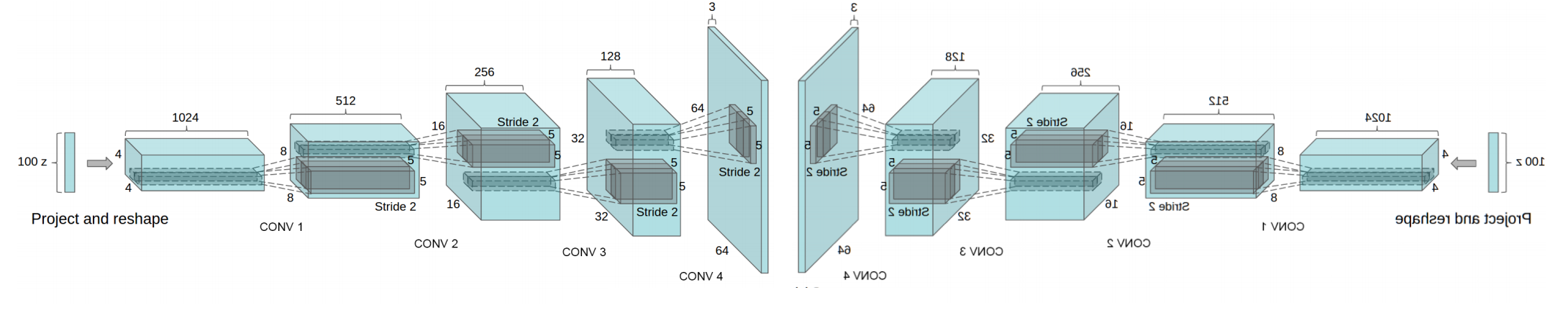
Generator(生成器,G)と、Discriminator(識別器,D)の2つのモデルを使って画像生成をするGANという技術です。まず、Gは与えられたランダムな入力パラメータから画像を生成します。Dは、この画像が通常の画像なのか、Gが生成した画像なのかを正しく識別するようトレーニングされます。その後、GはDが画像を識別できない画像を生成するようにトレーニングされこれを繰り返していきます。
ここで上記のGANに、DLのCNN技術や各種のテクニックを適用したDCGAN(Deep Convolutional Generative Adversarial Networks)が提案され、以降で非常に様々なGANの応用モデルが提案されることになります。DCGANでは生成機Gに対して丁度反対のアーキテクチャを持つモデルを識別器Dとして利用しています。
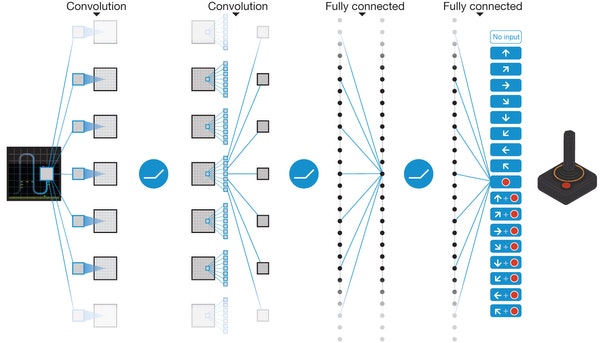
4. DQN
“Human-level control through deep reinforcement learning” (2015) Cited by 9,497
DeepMindの構築した強化学習の論文です。ある時点では一つの選択肢しか選べず、その結果からしか学習できない点で俗にいう"AI"のイメージに近いです。
Q Learningと呼ばれる古典的な強化学習の手法にプラスして、画像からの特徴抽出にCNNを使いさらにミニバッチやオプティマイザなどのDL技術を組み合わせて一気にパフォーマンスを上げた論文です。これを機にロボットの制御やボードゲームのAIなどへの応用が進みました。