前書き
今更GAE/pかよ! って感じですが、これがやっぱり良くできてるのですよ。
自分用に作ったAI論文検索ツールをGoogle App Engine/pythonでウェブサービス用にしてみたら結構さくっと動いてしまったので、またやる時のためにメモ書きとして残しておきます。
TL DR;
Facebook fasttext を使ったディープラーニング論文の検索/クラスタリングツールをwebサービスにする手順。使ったものは fasttext, scikit-klearn, GAE/p, jinja2です。無料でまずはパパッと公開しようぜ!

AI系論文のサイトがとても使いにくいポンコツ
ってこと、ありますよね。CVPR2018という画像処理のトップ学会があります。ディープラーニングブームを盛り上げて来た学会で、東京では毎年論文読み会が開催されています。皆さん是非参加してみて下さい。さて今年の採択論文も公開されて、さーこれで休日がはかどるぞと思いきやオフィシャルの検索ページがまた非常に使いにくい。
例えば顔認識関連の論文を検索しようとして試しに"face recognition"で検索してみるといきなり75件も出てきます。そこでDL関連の論文に絞るために"deep learning"をキーワードに追加して検索すると今度は350件ぐらいヒットします。あははは。全体の3-4割がヒットしてしまうともはや検索できないのと同じ。すぐ気がつくことですがキーワードの OR 条件で探していて、しかも論文のタイトルからしか検索していないのですね。。。
とりあえず自分用にキーワードをabstractからもAND検索できたり本文PDFをスクレイプして類似論文を探せるサービスを作ります。こっちで"face recognition"を検索すればこの通り。うむ。

しかも類似論文だって探せちゃうぜ!そう、僕のAIならね。

Google App Engineを使う(その前に)
実はAIは使えない
というわけで前置きが長くなりましたが、ここで前提として大事なことをまとめておきます。無料でホストするならGAEのスタンダードモードが個人的には一番です。ただしこのモードではpythonも2.7系統だし使えるnumpyも古いし、何よりtensorflowやscikitが使えません。 なのでここではトレーニング後の結果データはnumpyの配列や行列としておいて、サービス時にはtensorflowやscikitを使わずにnumpyの演算のみでサービスを実行できるようにしておくことが大切です。
ただしここさえクリアすれば後は楽チンです。
AI部分をスキップする場合は後半のGoogle App Engine 事始めへ
作るもの
単語ベクタを学習できるFacebook fasttextを使った論文検索ツールです。合計2,500件のCVPR採択論文を学習させ、各論文の特徴を表す論文ベクタを作成することで類似論文を探せます。
- 計2,500件/1000万ワードの論文PDFからコーパスを作成し論文ベクタを学習
- 論文を自動でクラスタリングして全体の傾向をつかめる
- キーワードを使って論文を検索できる
- さらに検索した論文の類似論文を見つけることができる
なんでfasttext?
いろいろ試した感じではWord2VecやDoc2Vecの方が精度が良さそうでした。ですが論文などもとのコーパスがクリーンであればsub word単位で類似度が上がる方が過去形や複数形など単語が近いものを考慮してくれる強みが出るのではと思ってfsttextにしています。あと、今回は自前で学習させましたがwikipediaから学習させた日本語のベクタが公開されているので他でも使えそうだと思ったのでした。
と言ってもNLP性能についてはまだまだです。少なくとも品詞の種類を考慮したり、論文間での各単語の頻出度合いを調べてより特徴的な言葉かどうか判定しそれによって重みをつける必要がありそうだと思います。ただまぁ、自分用には現状でも大変役に立ってるのでとりあえずウェブサービスにしてみました。
コーパスの作成、スクレイピング
AI部分については説明し始めるとかなり長くなってしまうしどこかで一応話したことがある気がするので、ここでは概要について一気に説明しておきます。
- CVPR2016/2017/2018の各サイトから論文タイトルやPDFをスクレイプしてきます。スクレイピングにはJava-play frameworkを使い、ローカルにMySQLを用意してhtmlunitを使ってスクレイプしたデータを片っ端から保存していきます。PDFからのテキスト抽出についてはPDFBoxを使いました。まぁここら辺は自分の慣れた構成でいきましょう。
htmlunitでxpathを使ってページ内のとあるリンクを検索しHTMLエレメントを配列で取得するにはこんな感じ
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage Page = webClient.getPage("url");
Elements = Page.getByXPath( "/html/body/div[@id='content']/dl/dt[@class='ptitle']/a" );
for( int i = 0; i < Elements.size(); i++ )
{
HtmlAnchor a = (HtmlAnchor) Elements.get(i);
String title = a.getTextContent();
String abstract_url = BaseURL + a.getHrefAttribute();
}
PDFBoxを使ってPDFファイルのURLからテキストを抜くにはこんな感じ
URL u = new URL("pdf_url");
PDDocument pddDocument = PDDocument.load(u.openStream() );
PDFTextStripper textStripper = new PDFTextStripper();
String doc = textStripper.getText(pddDocument);
便利な世の中ですな。
抽出したテキストについては下記の手順でコーパスを作る前の下準備をしておきます。一般的なサニタイズに追加して若干英語や論文特有の処理も追加しておきます。
- ハイフネーションされて次の行へ続いてる行を連結
- "http://"や特殊なキャラクタ(改行コードなど)の削除
- URLや人名、固有名詞の削除
- 一文字だけの言葉や数字を削除します。ただし"3D"などのように特別に数字を使う言葉については"3D"->"Three Dimensional”などに先に置換しておきます。
- [the, an in, on, and, of, to, is, for, we, with, as, that, are, by, our, this, from, be, ca, at, us, it, has, have, been, do, does, these, those]などの定冠詞や頻出単語を削除
- "Figure", "Table" など、どの論文にも登場して意あまり味を持たない単語も削除しておく
- 頻出する複数形の単語を単数形に変換しておきます。fasttextを使っているので本当はここらへんはあまり気にしなくて良いのかもしれません
- 大文字から小文字への変換
ある程度サニタイズができたら次は熟語の判定を行いましょう。"Deep Learning" や "Object Recognition" などの頻出する熟語は一つの単語として扱った方が精度が高くなるので__"Deep_Learning"__ や __"Object_Recognition"__などアンダースコアでつなげて一つの言葉とします。
正直言うとコーパスを作る時にやることが多すぎて、面倒くささのあまりに心がくじけそうになります。ですがいろいろやってみた感じでは、検索精度をあげるためには__いかに綺麗なコーパスを作るかが大変重要__です。まずはコーパスを作って学習させ幾つかの単語の相関関係を確認する、そしてもし違和感があればコーパスの作り方を修正するということを繰り返します。
fasttextでの学習 / 論文ベクタの作成
コーパスが作成できたらfasttextをダウンロードします。pipコマンドでインストールできるパッケージはかなり古くなってしまっているので、ここではgithubから最新のソースをダウンロードしてインストールしましょう。fasttextのレポジトリはこちらです。あるいはこんな感じでインストールします。
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ pip install .
fasttextを使えば、上記でコーパスとなるテキストファイルを作成しておけば、fasttext.train_unsupervised() を使って単語埋め込みベクタを学習できます。
model = fasttext.train_unsupervised(input=corpus_filename, model='skpigram', dim=75, minCount=5)
model.save_model(model_filename)
学習が終わったら学習後に返されるモデル(model)を使って単語ベクタを取得できます。ベクトル空間上で距離の近い単語を探せば意味の似てる単語が見つかります。
model.get_word_vector('target_word')
単語のベクトル表現ができたら、各論文のタイトルと概要に出てくる単語のベクトルを合算してその平均となるベクトルを作ってその論文を表すベクトルとしています。論文の概要よりも論文タイトルに採用されている単語の方がより重要だろうということで、今回はタイトルの単語に若干重みをつけています。他にも各論文間に共通して出現する単語は重みを下げるなどの工夫があるようですね。
ようやっと各論文を表すベクトルが作成できたぜ〜。早速サービス化したいところですが、その前にもう一つ試したかったことをやっておきましょう。論文の自動クラスタリングです。これぞ__教師なし学習の醍醐味!!__
まず、scikitのt-SNEを使って空間内の距離の大小関係をできるだけ保存したままベクトル空間の次元を2次元や3次元まで次元削除します。次元削減することで過学習を防ぎクラスタリングの性能が良くなったり、ビジュアライズしやすくなります。例えば2次元まで削減する場合はこんな感じです。paper_vectorsは [論文数 x 元の論文ベクタ] の2次元numpy arrayです。tsne.fit_transform()を使って [論文数 x 新しい2D論文ベクタ]に変換できます。まじ便利。
tsne = TSNE(perplexity=5, n_components=2, init='pca', n_iter=2000)
paper_vectors = tsne.fit_transform(paper_vectors)
元データは2016年のCVPRのものですが、得られた論文ベクトルにざっくりと色をつけてみるとそれなりに分野別に分かれているのが見えます。

次は同じくscikitのKMeansを使ってクラスタリングを試みます。paper_cluster_idsには各論文のクラスを表すインデックスが入ります。
estimator = KMeans(init='k-means++', n_clusters=10, n_init=10)
estimator.fit(paper_vectors)
paper_cluster_ids = estimator.labels_
各論文ベクトルを得られた削減された2D空間上にプロットして、クラスタリングされたインデックスに合わせて色付けをしてみます。まぁそれなり分かれている感じ。得られた各クラスタの中心にある論文などを表示して遊びます。
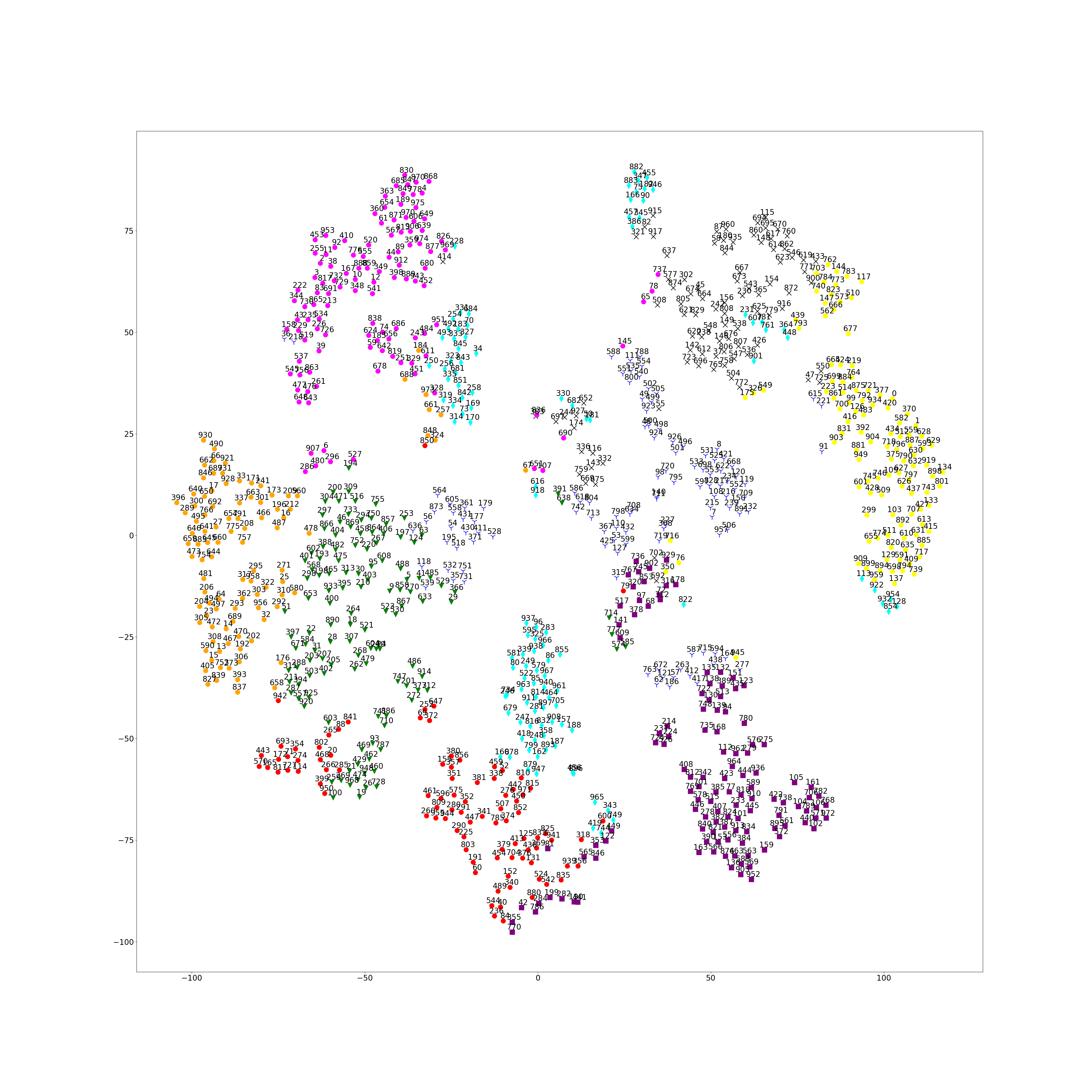
若干精度の悪いところもありましたがそれなりに判別できてるようなのでいよいよ論文検索サービスとして公開してみましょう。今までのステップで学習させた論文ベクタをnumpyの2D配列として保存しておき準備完了です。サービス時はfasttextなどを読み込まずにnumpyとwebapp2のみでホストします。そのために論文ベクタの__トレーニング用のクラスとサービス実行時のデータクラスを分離させて設計しておく__ことが大事です。
Google App Engine 事始め
大まかな手順:
- Google Cloud Platform上でプロジェクト生成
- ローカルマシン(本記事ではMac)にローカル/テスト環境を構築
- ほんとに無料?かどうかを確認
- Webサービス構築
- AIモジュールから情報を生成しhtmlページへ(テンプレートエンジン)
- AIモジュールへユーザーからの情報を渡す(Webフォーム)
GCP上でプロジェクト生成
まずグーグルさんのアカウントを使ってGoogle Cloud Platform(GCP)上でプロジェクトを作成します。
GCPコンソールを開きます。
下記のダイアログで [create] を選択し、プロジェクト名を設定します。その後リージョンを選び少し待つと作成が完了します。
次にGoogle Cloud SDKをインストールしローカルマシンにgcloud toolをセットアップします。このページの指示に従って足りないツールをインストールしたり、実行環境の初期化を行います。
インストールが済んだら一度ターミナルを閉じて立ち上げ直します。ここ大事。
ローカル/テスト環境の構築
SDKをダウンロードしたら下記コマンドを実行し、ダイアログに表示されるメニューに従って初期化します。
gcloud init
例えば最初は新しくプロジェクトを設定するので [2], 一度初期化されているディレクトリを再初期化する場合は[1]を選びます。その後使用するアカウントやプロジェクトを選択します。一度初期化したディレクトリでも同コマンドで簡単に他のプロジェクトにスイッチできるので、似たようなサービスを複数立ち上げる時に便利です。本githubでもICCV用とCVPR用で二つのサービスを立ち上げていますがソースは共通でデータだけ切り替えた後に上記のコマンドでスイッチさせています。
次にローカル実行用のpython環境を準備します。GAE/pスタンダードモードではpython2.7にしか対応していないため、virtualenvを使って2.7環境を用意します。
Macの場合恐らくデフォルトで2.7環境が入っていると思うので、virtualenvが入っていれば下記で2.7環境を構築します。
virtualenv --python=/usr/bin/python2.7 venv_p27
構築したらsourceコマンドを使ってその環境に切り替えます。(virtualenv環境を抜ける場合はdeactivateで)
source venv_p27/bin/activate
これでほぼ環境構築ができました。とりあえずサンプルコードを実行してみましょう。Google Cloud Platform Python Samples をクローンしてくるかDLしてきます。
git clone https://github.com/GoogleCloudPlatform/python-docs-samples
python-docs-samples の中の appengine/standard/hello_world/ へ移動します。ローカルでデバッグ環境を立ち上げるには下記を実行します。
dev_appserver.py app.yaml
その後、ブラウザで http://localhost:8000 を開きます。__「Hello, World!」__と表示されていればOKです。一旦Ctrl+Cでローカルデバッグ環境を落とましょう。次はいよいよクラウド上にアップロードしてみます。
gcloud app deploy
これで ブラウザから自分のアップエンジンのプロジェクトのURLでアクセスすれば同じように「Hello, World!」と表示されるページが開けるはずです。Yay!
ほんとに無料?かどうかを確認
ここで一応公開しているアプリの設定を確認しておきましょう。GAE ダッシュボードからプロジェクトを選択し、[課金ステータス]が無料となっていることを確認しましょう。サービスの負荷が高くなって無料の範囲を出てしまいそうかどうかはここで確認できます。

不安な場合は忘れずにプロジェクトを削除しておきましょう。GCP リソースマネージャを開き、該当のプロジェクトを選択します。左のメニューから[settings] -> [disable]あるいは[アプリケーションを無効にする]を選びます。
GAE/pではスタンダード環境とフレキシブル環境が選べますが、無料でホストするならスタンダード環境一択です。その代わりに使えるモジュールなどが限られてしまいますので、webサービス用モジュールはその範囲で実装するようにしておきましょう。使えるモジュールのリストはこちらです。
また無料の範囲でアプリを運用するためにはGoogle App Engineを無料で運用する方法のページが参考になります。軽く目を通しておくと良いです。
Webサービス構築
長いね。長かったね。。。
いよいよやっとサイトの構築を始めます。
とりあえずGoogle Cloud Platform Python Samplesの/appengine/standard/hello_world/ にある3つのファイルを雛形として実装してみましょう。
ページの新規追加
デフォルトのmain.pyではMainPageクラスが最初から追加されています。ページを増やすには同じように新しいクラスを作成して、ハンドラを追加すればよいのねってことでHogePageを追加してみましょう。
class HogePage(webapp2.RequestHandler):
def get(self):
self.response.headers['Content-Type'] = 'text/plain'
self.response.write('Hoge!')
app = webapp2.WSGIApplication([
('/', MainPage),
('/hoge', HogePage)
], debug=True)
忘れずに /hoge ページへのハンドラを追加しましょう。もう一度 "dev_appserver.py app.yaml"コマンドを使ってローカル環境を立ち上げます。今回は http://localhost:8080/hoge にアクセスしてみましょう。Hoge!

AIモジュールから情報を生成しhtmlページへ
pythonのソースコードからリストやオブジェクトを生成してページ側に受け渡して表示してみます。ここではテンプレートエンジンとしてjinja2を使用します。まずはテンプレートとなるhtmlを作ります。下記ファイルをfuga.htmlとして同じディレクトリに作成しましょう。イメージとしては message と objectの配列を渡してhtml側で整形して表示します。
<html>
<body>
{{ message }}
{% for object in objectList %}
<p>{{ object.subject }} {{ object.verb }} {{ object.complement }}</p>
{% endfor %}
</body>
</html>
次にテンプレートベースで表示を行うための基本クラスと、テンプレートに渡すオブジェクトのクラスを作ります。
import os
import jinja2
JINJA_ENVIRONMENT = jinja2.Environment(
loader=jinja2.FileSystemLoader(os.path.dirname(__file__)),
extensions=['jinja2.ext.autoescape'],
autoescape=True)
class BaseHandler(webapp2.RequestHandler):
def render(self, html, values={}):
template = JINJA_ENVIRONMENT.get_template(html)
self.response.write(template.render(values))
テンプレートに渡して表示するオブジェクトクラスも定義してみましょう。subject, verb, complementの3つの変数を持つクラスです。
class Object():
def __init__(self, subject, verb, complement):
self.subject = subject
self.verb = verb
self.complement = complement
次に、/fugaページを追加します。ここではobjectを複数生成してリストにしてテンプレートに渡します。テンプレートではリスト内の要素を順次表示していくようになっています。
class FugaPage(BaseHandler):
def get(self):
me = Object("I", "am", "Hoge.")
he = Object("He", "is", "Fuga.")
objects = [me, he]
values = {
'message': "Hello Jinja2!",
'objects': objects
}
self.render("fuga.html", values)
app = webapp2.WSGIApplication([
('/', MainPage),
('/hoge', HogePage),
('/fuga', FugaPage)
], debug=True)
最後に、忘れずにapp.yamlへjinja2を利用するライブラリとして追加しておきます。
libraries:
- name: jinja2
version: latest
これで準備は万端。python特有の軽い表記でサクサクオブジェクトを作れるのはいいですね!values にまとめてテンプレートに渡します。 http://localhost:8080/fuga にアクセスしてみましょう。

Fuga!
AIモジュールへユーザーからの情報を渡す
最後はフォームを使った情報の入力を試します。先ほど作ったfuga.htmlに下記フォームを追加します。どちらでも良いのですがとりあえずgetメソッドで渡してみましょう。
<form action="/fuga" method="GET">
Name:<input type="text" name="name">
<button type="submit">is foo?</button>
</form>
フォーム情報は request.get('name') で取得できます。 main.pyのFugaPage/get()にフォームからの情報を取得してobjectsに登録する部分を追加します。
me = Object("I", "am", "Hoge.")
he = Object("He", "is", "Fuga.")
objects = [me, he]
foo = self.request.get('name')
if foo is not "":
objects.append(Object("Is", foo, "Foo?"))
ではフォームに何か入力してボタンを押してみましょう。Foo- 完成!

実際のサイトではキーワードを受け取って論文を検索し、一度検索したらその類似論文を検索できるようになっています。必要ならtwitter bootstrapなどを使ってささっとサイトをお化粧しておきましょう。

まとめ
本当はもうちょっと論文ベクタ生成等の部分をじっくり書きたかったのですが、分量が増えてしまったので今回は詳細はgithubの方をみてもらえればと思います。ちなみにgithubのスターはすごいモチベーションが上がるので、参考になったという方は是非ぽちっとお願いします!
スター欲しさに意を決してFacebook上のfasttextコミュニティに行ってさりげなく宣伝してきました。おかげでスター3個Get!!
まぁ冗談はともかく他の人のプロジェクトについてもクローンする時は是非スターをポチってください。今回は初めてwebapp2 + jinja2 を触りましたが、pythonの軽い書き方にあった分かりやすいフレームワークで感心しました。
是非みなさんもご一緒に。
ここまで読んで頂いてありがとうございました!