はじめに
Twitter API で取得したデータをCSVファイルに保存したときに、改行コードが原因で苦労したのでメモ。
環境
Ubuntu 18.04.2
Anaconda 3 5.3.1
Python 3.7
Jupyter Notebook
問題
Twitter API で取得できるデータのうち、text・full_text・user->descriptionといった要素は、ユーザーが自分で文章を入力したデータになるので、改行コードが含まれる場合があります。
改行コードには\n・\r・\r\nの3種類があるのですが、Twitterユーザーが使用している環境によって、その種類が変わってきてしまいます(参考:改行コード一覧)。
例えばツイートのtextデータには
メッセージ\nメッセージ\nメッセージ
メッセージ\rメッセージ\rメッセージ
メッセージ\r\nメッセージ\r\nメッセージ
の3種類が含まれるのです。
さて本題。
Twitter APIで取得したデータをpandasのDataFrame型にした後、CSV形式でファイルとして保存したのですが、保存したファイルを読み込むと、データの行数が増えていたり、カラムにズレが生じていて、保存時の形を全く保っていなかったのです。
どういうことかというと、例えば以下のようなコードを実行すると、
# 改行コードが\rのとき
import pandas as pd
from IPython.display import display
df = pd.DataFrame([{ 'created_at': '12:00',
'text': 'メッセージ\rメッセージ\rメッセージ',
'tweet_id': 12345,
'user_id': 67890,
}])
display(df) # DataFrameを出力
df.to_csv('test.csv', encoding="utf-8") # CSV形式で保存
df = pd.read_csv('test.csv', index_col=0)
display(df) # 読み込んだCSVデータを出力
結果は以下のようになります。DataFrame(上)は正常ですが、一度CSV形式に変換すると崩れていますよね(下)。
\rを境に行が一段下がり、カラムと値がミスマッチしています(インデックスに値が入ってるしめちゃくちゃ...)。空いているデータはすべてNaNになっていますね。
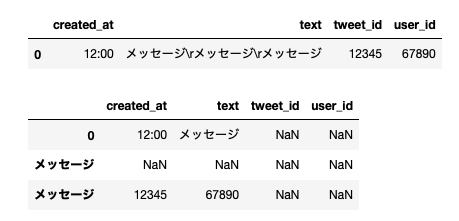
どうやら、問題児は改行コードの\rのみのようです。
\nや\r\nの場合は、データが崩れることなく保存できます↓
# 改行コードが\nのとき
df = pd.DataFrame([{ 'created_at': '12:00',
'text': 'メッセージ\nメッセージ\nメッセージ',
'tweet_id': 12345,
'user_id': 67890,
}])
display(df) # DataFrameを出力
df.to_csv('test.csv', encoding="utf-8") # CSV形式で保存
df = pd.read_csv('test.csv', index_col=0)
display(df) # 読み込んだCSVデータを出力

# 改行コードが\r\nのとき
df = pd.DataFrame([{ 'created_at': '12:00',
'text': 'メッセージ\r\nメッセージ\r\nメッセージ',
'tweet_id': 12345,
'user_id': 67890,
}])
display(df) # DataFrameを出力
df.to_csv('test.csv', encoding="utf-8") # CSV形式で保存
df = pd.read_csv('test.csv', index_col=0)
display(df) # 読み込んだCSVデータを出力
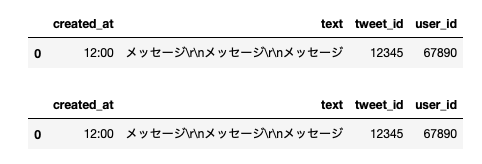
解決方法
その1
\rを\nに置換する。
\r\nに含まれる\rは、置換してしまうと改行が1つ増えてしまうので、注意する必要があります。
df = pd.DataFrame([{ 'created_at': '12:00',
'text': 'メッセージ\rメッセージ\rメッセージ',
'tweet_id': 12345,
'user_id': 67890,
}])
display(df) # DataFrameを出力
# \r\nの場合は除いて、\rを\nに置換する
if ('\r' in df['text'][0]) and not ('\r\n' in df['text'][0]):
df['text'][0] = df['text'][0].replace('\r', '\n')
df.to_csv('test.csv', encoding="utf-8") # CSV形式で保存
df = pd.read_csv('test.csv', index_col=0)
display(df) # 読み込んだCSVデータを出力

追記
改行コードを全部\nに統一した方が良さそうですね。以下のコードで\r\nと\rの両方を置換できます。
置換する順序を間違えると、\r\nが\n\nになってしまうので気をつけましょう。
df['text'][0] = df['text'][0].replace('\r\n', '\n').replace('\r', '\n')
df.to_csv('test.csv', encoding="utf-8") # CSV形式で保存
df = pd.read_csv('test.csv', index_col=0)
display(df) # 読み込んだCSVデータを出力
その2
pickleを使用する。
df = pd.DataFrame([{ 'created_at': '12:00',
'text': 'メッセージ\nメッセージ\nメッセージ',
'tweet_id': 12345,
'user_id': 67890,
}])
display(df) # DataFrameを出力
df.to_pickle('test.pickle') # pickle形式で保存
df = pd.read_pickle('test.pickle')
display(df) # 読み込んだpickleデータを出力

pickleファイルはコードで読み込まない限り中身を確認することができない(Excel等で開くことができない)ので、簡単にデータを確認できるようにしたいようなら、\rを\n置換してCSV形式で保存する方法が良いと思います。
以上