HuggingFace Spaceで下記の文章類似AIのデモアプリを作ってみて、まとめました。
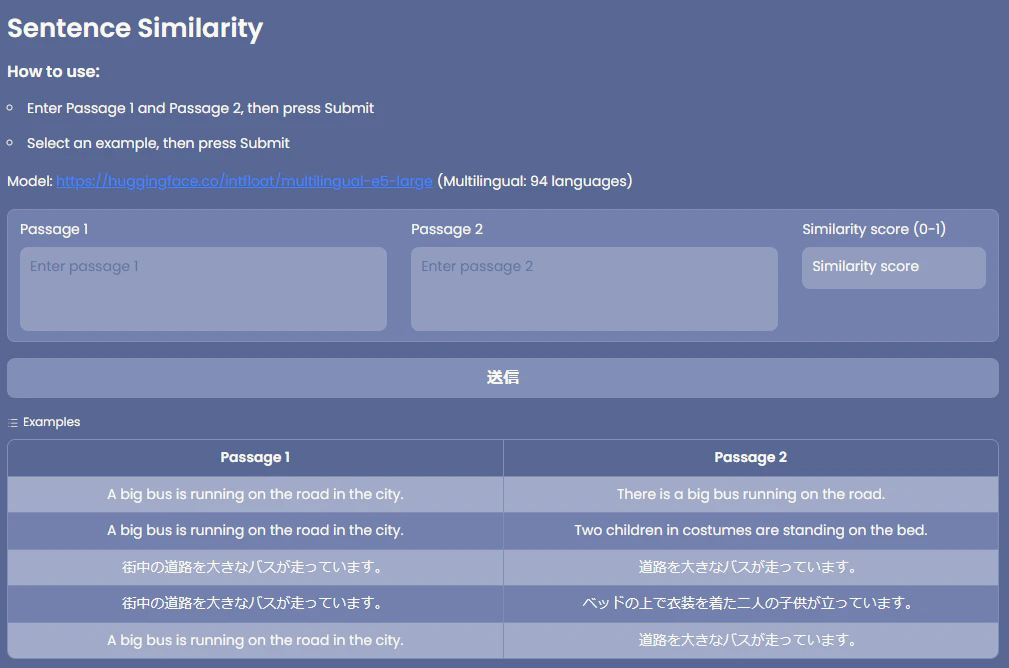
https://huggingface.co/spaces/jingwora/language-sentence-similarity
目次:
- はじめに
- HuggingFace Spaceとは
- モデル
- コード
- モデルの説明
- gradioの説明
はじめに
この記事では、HugginFace🤗にAIでもアプリをデプロイして、GradioというUIライブラリで画面を作成することを紹介します。
HuggingFace Spaceとは
HuggingFace Spaceは、Hugging Face社が提供するサービスです。このサービスでは、機械学習を使ったデモを簡単に作成して公開できます。HuggingFace Spaceは、Hugging Face Hubと連携しており、モデルやデータセットを共有したり、他のユーザーとコラボレーションしたりすることができます。HuggingFace Spaceは、StreamlitやGradioなどのフレームワークをサポートしており、Pythonのコードを書くだけでデモを作成できます。
モデル
文章類似は複数方法があります。今回は埋め込みモデルを利用したいです。埋め込みモデルは、テキストの入力を数値ベクトルに変換することで、理解した言語の知識を表現します。
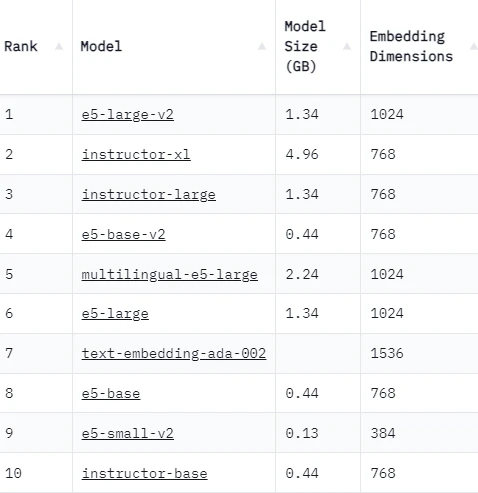
mteb leaderboardはテキスト埋め込みモデルの性能を様々なタスクで評価するためのベンチマークです。ランクは英語のデータセットテストに基づいています。多言語モデルの場合は、multilingual-e5-largeが一番優れていると考えます。
コード
少なくともapp.pyとrequirements.txtの2つのファイルが必要です。
app.py には ml モデルと Gradio が含まれています。
requirements.txtは、アプリで必要なモジュールやパッケージのリストを記述したテキストファイルです。
app.py
from transformers import pipeline
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
from torch.nn.functional import cosine_similarity
import gradio as gr
# モデル
def average_pool(last_hidden_states: Tensor, attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# 文章類似の計算
def get_similarity(sentence1, sentence2):
input_texts = [sentence1, sentence2]
# Tokenize and compute embeddings
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors="pt")
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict["attention_mask"])
similarity = cosine_similarity(embeddings[0].unsqueeze(0), embeddings[1].unsqueeze(0))
similarity = round(similarity.item(), 4)
return similarity
# モデルとトークナイザー
checkpoint = "intfloat/multilingual-e5-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)
# gradio
demo = gr.Blocks(theme="freddyaboulton/dracula_revamped")
with demo:
gr.Markdown("# Sentence Similarity")
gr.Markdown("### How to use:")
gr.Markdown("- Enter Passage 1 and Passage 2, then press Submit")
gr.Markdown("- Select an example, then press Submit")
gr.Markdown("Model: https://huggingface.co/intfloat/multilingual-e5-large (Multilingual: 94 languages)")
with gr.Row():
p_txt1 = gr.Textbox(placeholder="Enter passage 1", label="Passage 1", lines=3, scale=2)
p_txt2 = gr.Textbox(placeholder="Enter passage 2", label="Passage 2", lines=3, scale=2)
o_txt = gr.Textbox(placeholder="Similarity score", lines=1, interactive=False, label="Similarity score (0-1)", scale=1)
submit = gr.Button("Submit")
gr.Examples(
[
["A big bus is running on the road in the city.", "There is a big bus running on the road."],
["A big bus is running on the road in the city.", "Two children in costumes are standing on the bed."],
["街中の道路を大きなバスが走っています。", "道路を大きなバスが走っています。"],
["街中の道路を大きなバスが走っています。", "ベッドの上で衣装を着た二人の子供が立っています。"],
["A big bus is running on the road in the city.", "道路を大きなバスが走っています。"]
],
inputs=[p_txt1, p_txt2]
)
submit.click(
get_similarity,
[p_txt1, p_txt2],
o_txt
)
demo.launch()
requirements.txt
gradio==3.36.1
transformers==4.30.2
torch==2.0.1
モデルの説明
average_pool関数は、BERTモデルの出力で、各文のトークンを計算して平均を取ります。
get_similarity関数は、2つの文(sentence1とsentence2)の類似性スコアを計算します。
AutoTokenizer.from_pretrainedおよびAutoModel.from_pretrainedを使用して、Hugging Faceのモデルとトークナイザーを読み込みます。
gradioの説明
gr.Blocks(theme="freddyaboulton/dracula_revamped")により、デモの外見やテーマが設定されます。
gr.Markdownを使用して、テキストを表示します。
gr.Textboxは、テキストを入力するためのテキストボックスを作成します。p_txt1とp_txt2は、それぞれ「Passage 1」と「Passage 2」のテキストボックスを表します。
gr.Examplesは、デフォルトの例を提供します。ユーザーはこれらの例を選択してテキストボックスに入力することができます。
gr.Buttonは、「Submit」というラベルを持つボタンを作成します。
submit.click()で、「Submit」ボタンがクリックされたときの振る舞いを設定します。get_similarity関数が呼び出され、p_txt1とp_txt2に入力された文の類似性スコアが計算され、o_txtに表示されます。
最後に、demo.launch()により、アプリケーションが起動されます。
補足:
gradioのチュートリアル:https://www.gradio.app/guides/quickstart