はじめに
深層学習コミュニティは、大規模言語モデル(LLM)の限界を押し広げ続ける一方で、これらのモデルの計算要件はトレーニングと推論の両方で指数関数的に増加しています。
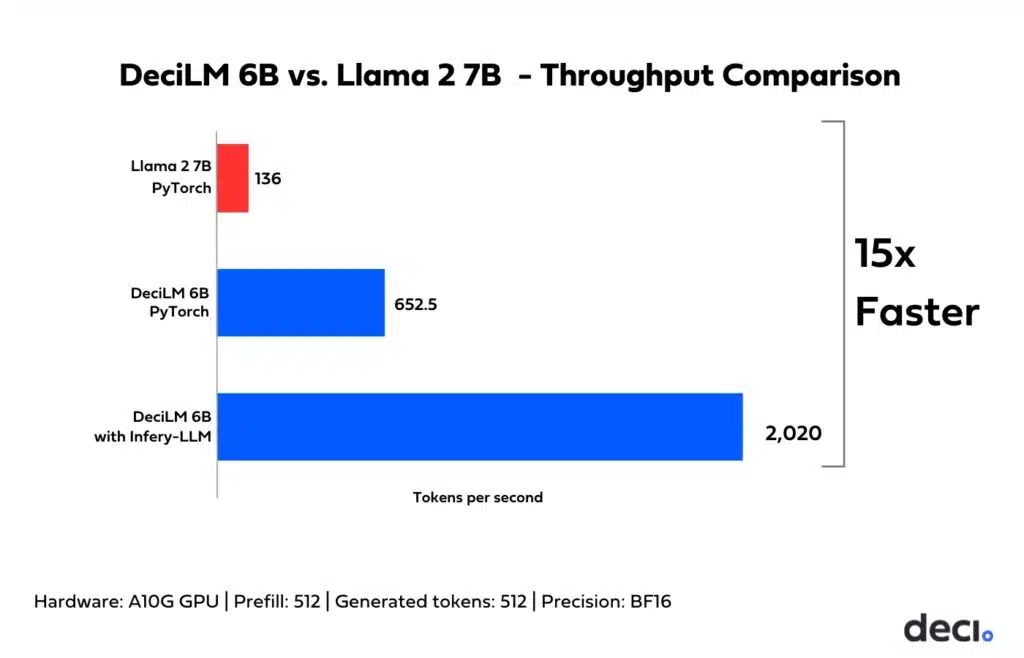
今回は、オープンソースのLLMであるDeciLM 6Bを紹介します。DeciLM 6Bは57億のパラメータを持ち、Llama 2 7Bと比較可能な品質を維持しつつ、スループットが15倍高速です。
DeciLMの概要
開発元:Deci
モデルタイプ:DeciLMは、最適化されたトランスフォーマーデコーダーアーキテクチャを使用した自己回帰型言語モデルで、可変のGrouped-Query Attentionを含んでいます。
言語(自然言語処理):英語
ライセンス:ホスティングサービスプロバイダーに関するDeciの拡張を含むLlama 2コミュニティライセンス契約。
モデルのバージョン:
- DeciLM 6B(ベース)
- DeciLM 6B-Instruct
「DeciLM 6B」から指示に従うためにFine-tuned(微調整)されたものです
特徴
DeciLM 6Bの特徴は、効率的なフロンティアを拡張するためにDeciの最先端のニューラルアーキテクチャサーチエンジンであるAutoNACを使用して生成された独自のアーキテクチャにあります。さらに、DeciLM 6BをDeciの推論SDKと組み合わせることで、大幅なスループット向上が実現します。
Grouped-Query Attention(GQA)
MQAはモデルの計算およびメモリ効率を向上させますが、モデル品質の劣化をもたらすことがあります。GQAは、MQAの向上版として導入され、メモリと計算効率、モデル品質の優れたバランスを提供するように設計されました。
- クエリのグルーピング:GQAでは、クエリはグループに分割され、各グループが単一のK(キー)とV(値)の計算を共有します。これにより、一定のパラメータの共有が提供されますが、MQAほどではありません。
- 特殊なアテンションパターン:各クエリグループに異なるキーと値を与えることで、モデルは入力内のより広範な関係を識別でき、MQAよりも洗練されたアテンションパターンが生まれます。

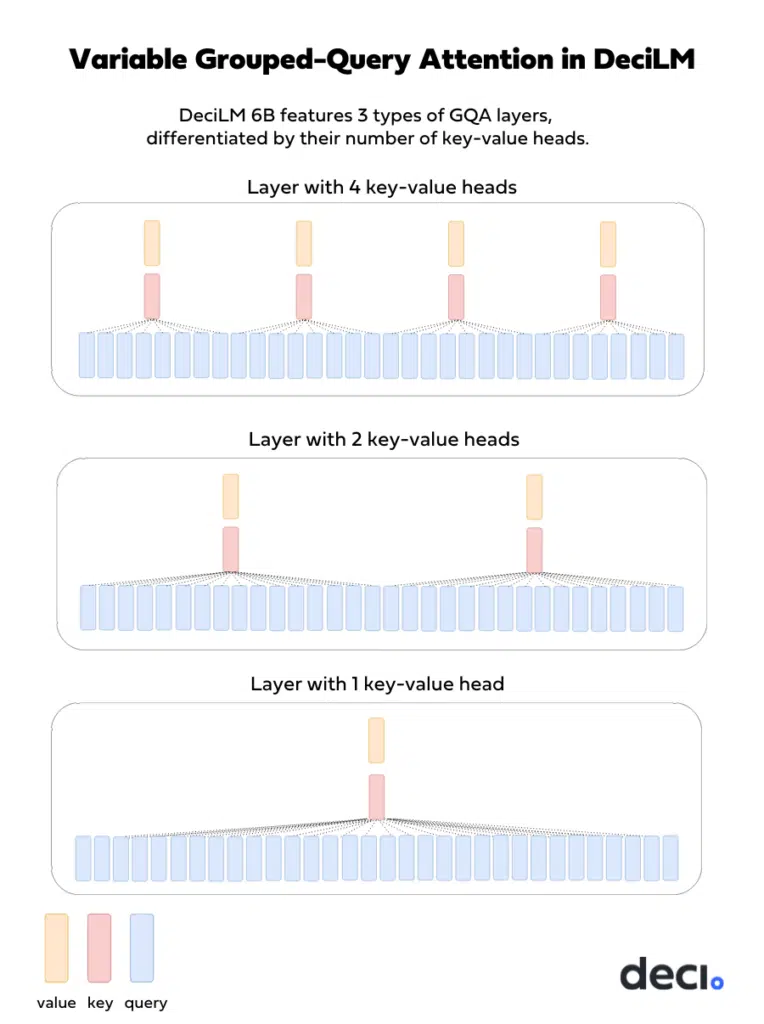
DeciLMにおける可変なGrouped-Query Attention
DeciLMでは、効率とモデル品質のトレードオフをさらに最適化するために、可変なGQA(Grouped-Query Attention)を導入します。他のモデル(例:Llama 2 70B)がすべてのレイヤーで一貫して同じ数のグループを適用するのとは異なり、DeciLMはそのアプローチに変動性を導入します。具体的には、各レイヤーで32のクエリ/ヘッドを維持しながら、DeciLMのレイヤーはGQAグループのパラメータにバラエティを持たせます:
- 一部のレイヤーでは、4つのグループを使用し、グループごとに8つのクエリとレイヤーごとに4つのK(キー)と4つのV(値)ヘッドがあります。
- 他のレイヤーでは、2つのグループを適用し、グループごとに16のクエリとレイヤーごとに2つのKと2つのVパラメータがあります。
- 特定のレイヤーでは、1つのグループを持ち(MQAと同様)、そのグループ内に32のすべてのクエリと1つのキーと値ヘッドがあります。
モデル評価
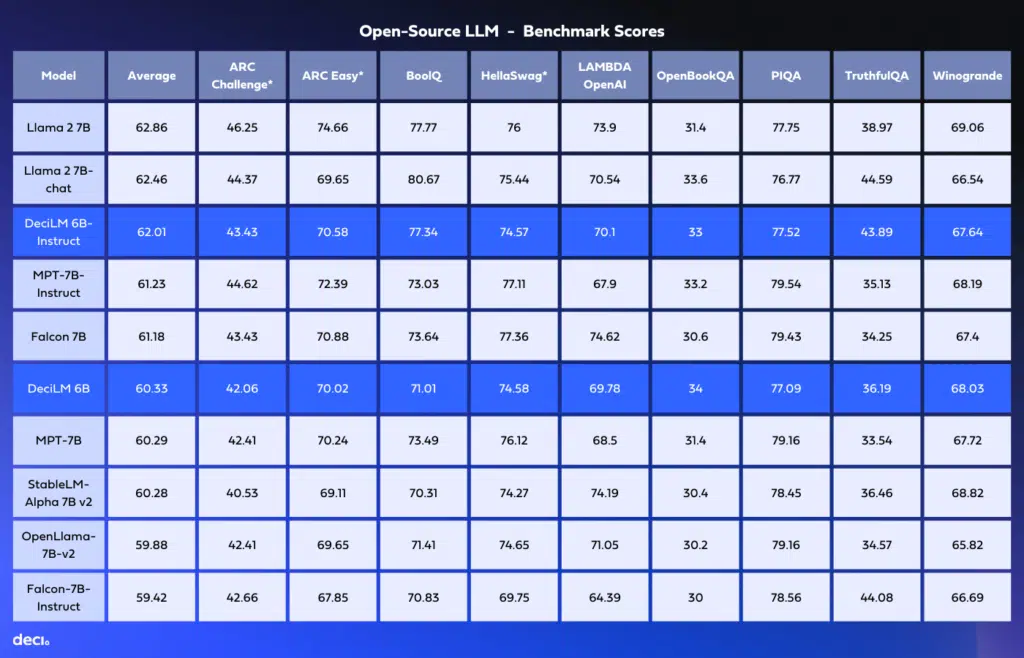
DeciLMが同僚モデルの中で際立つ指標
DeciLM 6BおよびDeciLM 6B-Instructを、Llama 2 7B、Llama 2 7B-Chat、Falcon 7B、およびMPT-Instructなど、7億のパラメータクラスの主要なオープンソースモデルと比較しました。パラメータ数がはるかに少ないにも関わらず、DeciLM 6B-Instructは、Llama 2 7Bにほんの1%未満の差で追随し、3番目の位置を獲得しました。
まとめ
DeciLM 6Bは57億のパラメータを持つオープンソースの言語モデルで、Llama 2 7Bと比較してスループットが15倍向上し、品質を維持しています。AutoNACを使用して生成された独自の可変Grouped-Query Attention(GQA)アーキテクチャは、他のモデルと一線を画しています。7億のパラメータクラスの同僚モデルとのベンチマークでは、DeciLM 6B-Instructが3番目の位置を確保し、その優れた性能を示しました。
参照: