現場で役立つシステム設計の原則 を読んで、
その内容をチームに伝えるようにまとめたメモです
ドメインモデルとは
業務で扱う(最小)単位でデータとロジックをひとまとめにして整理する技法
ドメインモデルが実現する世界
- どこに何のロジックが書いてあるか、(ソースを見るだけで)わかる
- 改修しやすいプログラム
ドメインモデルで解決したい問題
どこに何のロジックが書いてあるかわからない問題
- わからないから適当に書く→適当に書くからわからない → わからないから・・・
- ある修正をしようと思っても、どこまでが影響範囲かわからない
- 使用している箇所全grepして調査
- 同じような処理、分岐が重複してしまう
これを解決したい。これだけを考える。
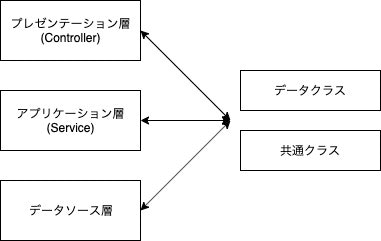
なぜ(今までのシステムは)改修は難しいのか
- 機能クラスと、データクラスをわけてしまうから
- そのデータクラスを呼べる箇所 = 業務ロジックがかけてしまう
- どこになにが書いてあるかわからなくなる
- そのデータクラスを呼べる箇所 = 業務ロジックがかけてしまう
- 共通クラス、Utilクラスを作ってしまうから
- 誰でも呼べる = そのクラスを使って何をやっているのか、影響範囲が大きくなる
- 微妙にニーズが違うせいで、関係ない分岐まで混ざってしまう
- 肥大化して結局どこに何が書いてあるかわからなくなる
- 重複コードが生まれる
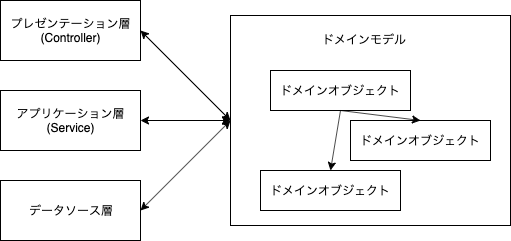
じゃあどうすればいいのか
- データとロジックを一体化することで、業務ロジックを整理する
- 三層+ドメインモデルの構成にする
- すべての業務ロジックをドメインモデルに集める
- 他の層は、判断、加工、計算はドメインモデルに任せる
実装する上でのポイント
値オブジェクトを使う
なにかの料金クラスがあるとして、そのインスタンス変数をInteger moneyとしない。
専用の型(クラスやインターフェース)で、不適切な値は混入させない。
値オブジェクトを用意すると、コードが安定する。
値オブジェクトは不変にする
値が書き換わるときは、別オブジェクトをnewして返すこと
内部で値を書き換えてしまうのは副作用が大きすぎる。
コードを読むときに、この変数はどこで値が変わっているか、を気にしないといけなくなる
→改修の手間(調査)が一気に面倒になる
変数の値は変わらない。だからコードが安定する。
悪い例
Money price = new Money(3000);
price.setValue(2000); // × 値は書き換えている
price = new Money(4000); // 1つの変数に別の値を代入している
良い例
Money basePrice = new Money(3000);
Money discount = basePrice.Minus(1000); // minusメソッドは、内部で引数を元に計算した値をnewして返す
Money option = new Money(2000); // 変数は上書きしない
クラスを使う側にロジックを一切書かせない
従業員 classがあった場合
Employee class {
// 入社日時 (データ
JoinDate joinDate;
// 生年月日 (データ
Birthday birthday;
// 職種 (データ
JobType jobType;
// 年齢取得メソッド(ロジック
Integer Age () {
// 生年月日から年齢を返す
}
// エンジニア判定メソッド
boolean isEngineer () {
// jobTypeがエンジニアならtrueを返す
}
// クリエイター判定メソッド
boolean isCreator () {
// jobTypeがエンジニアorデザイナならtrueを返す
}
}
getterは基本的に使わない
→利用するクラスはgetしたデータでなにをしようとしている?
→データを使って、加工/判断/計算をする場合は、ドメインオブジェクトに必ず閉じ込める
→そのデータを使うロジックは、ドメインオブジェクトを見ればわかるようにする
利用側のクラスが↓こんな感じで判断してはいけない
if (employee.getJobType() == エンジニア) {
XX処理
}
クラスをデータの入れ物として考えない
あるクラスを「データの入れ物」と考えてしまうと、そのクラスからデータをgetして、自分でロジックを書くのが当たり前になってしまう
データを持つクラスのメソッドを「ロジックの置き場所」と考えれば、そのクラスが、判断、加工、計算までやってくれる、便利な部品になる
メソッドの書かれている場所の妥当性を考える
インスタンス変数を使わないメソッドは、そのクラスのメソッドとして不適切
(インスタンス変数でない引数だけを使うメソッドはだめ→どこに何が書いてあるかわからなくなる原因)
→つまりそれは、その処理で使っているクラスのメソッドであるべき(データの近くにロジックを置く)
その他実装のポイント
- 短いメソッド、小さいクラスを使って、コードを整理する
- 値オブジェクトを作る
- クラス名や、メソッド名を業務の用語と一致させる
クラスがたくさんできる、、、?
できます。
クラスがたくさんできるので、それをパッケージ(ディレクトリ)に分けて、管理しましょう。
パッケージが増えてきたらサブパッケージで管理。
階層が増えてきたり、ある階層には1クラスしかない、とかもあると思う。
けど、それでもよい。
大事なのは、どこに何があるかをわかりやすくすること。
その階層を見るだけで、どこに何が書かれているかわかるようにする。
また、パッケージをわけ、それの使う、使われるの依存関係をはっきりすることで、ロジックの重複を避けることができる
知らないでいいことを知りすぎたり、責任を誰が持つのかを明確にする
補足
- 設計初期の段階から、完璧なドメインモデルは作れない
- むしろ作りながら、育てていく(リファクタしまくろう
ドメインモデルの設計が難しいと言われるのはなぜか
- オブジェクト指向の経験不足
- 手続き型の発想から抜け出せていない。
- データとロジックを1つのクラスにまとめる考えのメリットが感覚的にわかっていない
- 要件定義、分析のやり方が間違っている
まとめ
- 変更が大変になるのは、データクラスと機能クラスをわけるから
- データクラスを使うと、業務ロジックの重複が増える
- 全体の見通しを良くするために、データとロジックを一体にする設計を徹底する
- 業務ロジックは、業務データの近くにまとめる(ドメインオブジェクト
- ドメインモデルは、画面やDBの都合から独立させる
- 他の層は、業務的な判断/加工/計算ロジックをドメインモデルに任せることでシンプルになる
謝辞
この記事を書いたところ、この本「現場で役立つシステム設計の原則」の著者である増田さんからお褒めの言葉を頂きました。
https://twitter.com/masuda220/status/1191627212903964673
こちらこそ大変参考にさせて頂いております。素晴らしい本を書いてくださりありがとうございます。