ベイズ推定や統計では(多変量)ガウス分布からサンプルを行う場面が度々あると思います.サンプリングの機能は汎用ライブラリから提供されていますが,実際にどうやって確率変数をサンプルするのか疑問に思ったので,調べた結果を記事にしてまとめておきます.ここでは,$(0,1)$上の$N$個の一様乱数 $x_n$ を用いて,多変量ガウス分布に従う$N$個の乱数を生成する(多変量ガウス分布からサンプリングを行う)方法を説明します.
N個の独立な標準ガウス分布に従う乱数の生成
一様乱数から標準ガウス分布に従う乱数を生成する方法としてはボックス=ミュラー法があります.これを用いれば,次の式により標準ガウス分布の乱数 $y_n$ を得ることができます.
y_1 = \sqrt{-2 \log x_1} \cos{2\pi x_2} \\
y_2 = \sqrt{-2 \log x_1} \sin{2\pi x_2} \\
\vdots \\
y_{n-1} = \sqrt{-2 \log x_{n-1}} \cos{2\pi x_{n}} \\
y_n = \sqrt{-2 \log x_{n-1}} \sin{2\pi x_{n}} \\
\vdots
($N$が奇数の場合は,$N+1$個の乱数を生成し,1つを棄却します.)
ボックス=ミュラー法
$y_1, y_2$ が独立に標準ガウス分布に従うとすれば,その同時確率分布は,
p(y_1, y_2) = p(y_1)p(y_2) = \frac{1}{2 \pi} \exp \left( -\frac{y_1^2 + y_2^2}{2}\right)
で表すことができます.極座標変換により $(y_1, y_2) \to (r, \theta)$ と変数変換を行うと,
p(r, \theta) = p(y_1, y_2)\left| \frac{\partial (y_1, y_2)}{\partial (r, \theta)} \right| = \frac{1}{2 \pi}r \exp \left( -\frac{r^2}{2}\right) \\
p(\theta) = \int_{0}^{\infty} p(r, \theta) dr = \frac{1}{2\pi}
となります.よって,$\theta$ の従う分布は $(0, 2\pi)$ 上の一様分布となります.
次に,$r^2=y_1^2+y_2^2$ が従う分布を考えてみます.これはカイ二乗分布と呼ばれ,
p \left( r^2 \right) \propto \exp \left( -\frac{r^2}{2} \right)
が成り立つことが知られています.$z = \exp \left( -\frac{r^2}{2} \right)$ の変換を行えば,
p \left( z \right) = p\left( r^2 \right)\left| \frac{\partial \left( r^2 \right)}{\partial z} \right| \propto \exp \left( -\frac{r^2}{2} \right)\exp \left( \frac{r^2}{2} \right)=const.
となります.従って,$z$ も $(0,1)$ 上の一様分布に従うことがわかります.
以上から,$y_1, y_2, \theta, z$を結びつけて,
y_1 = r\cos\theta = \sqrt{-2 \log z} \cos\theta \\
y_2 = r\sin\theta = \sqrt{-2 \log z} \sin\theta
の式を得ます.
多変量ガウス分布に従う乱数の生成
標準ガウス分布から独立にサンプルする方法が分かったところで,これを多変量ガウス分布に従う変数へ変換する方法を考えましょう.いま,
\mathbf y = \left( y_1, y_2, \cdots, y_N \right) \sim \mathcal{N}\left( \mathbf y\mid \mathbf 0, \mathbf I \right)
であり,目標のガウス分布は $\mathcal{N}\left( \mathbf z\mid \boldsymbol \mu, \mathbf \Sigma \right)$ であるとします.
まず,$\mathbf y$ を $\mathbf t \sim \mathcal{N}\left( \mathbf t\mid \mathbf 0, \mathbf \Sigma \right)$ へ変換することを考えます.これが出来れば,$\mathbf z = \mathbf t + \boldsymbol \mu$ で簡単に $\mathbf z$ を求められます. $\mathbf y \to \mathbf t$ の変換を $ \mathbf t = \mathbf P \mathbf y $ とします.ここで興味があるのは共分散行列が $\mathbf \Sigma$ となるよう $\mathbf P$ を構成する方法なので,ヤコビアンは省略し(線形変換なので),余計な係数も省いて $\mathbf t$ の分布を考えていきます.すると,
p(\mathbf t) \propto p(\mathbf y=\mathbf P^{-1}\mathbf t) \propto \exp\left( -\frac{1}{2} \mathbf t^T {\mathbf P^{-1}}^T \mathbf I \mathbf P^{-1} \mathbf t \right)
より, $\mathbf \Sigma^{-1} = {\mathbf P^{-1}}^T \mathbf P^{-1}$ ,すなわち $\mathbf \Sigma = \mathbf P \mathbf P^T$ であることがわかります.$\mathbf \Sigma$ は半正定値の実対称行列であり, $\mathbf P$ はコレスキー分解あるいは固有値分解によって求めることができます.
実装
最後に,Pythonによる実装を示します.泥臭い部分は結局,汎用ライブラリに頼っているのでコード自体は非常に単純です.
import numpy as np
M = 10000 # サンプル数
N = 2 # 次元数
x_s = np.random.rand(N, M)
# ボックス=ミュラー法
y_s = x_s * 0
y_s[0,:] = np.sqrt(-2.0 * np.log(x_s[0,:])) * np.cos(2.0 * np.pi * x_s[1,:])
y_s[1,:] = np.sqrt(-2.0 * np.log(x_s[0,:])) * np.sin(2.0 * np.pi * x_s[1,:])
mu = np.array([0.5, 0.4])[:,None] #平均
Sig = np.array([[0.4 ** 2, 0.3 ** 2], [0.3 ** 2, 0.4 ** 2]]) #共分散行列
# コレスキー分解
P = np.linalg.cholesky(Sig)
# z ~ N(z | mu, Sig)
z_s = P.dot(y_s) + mu
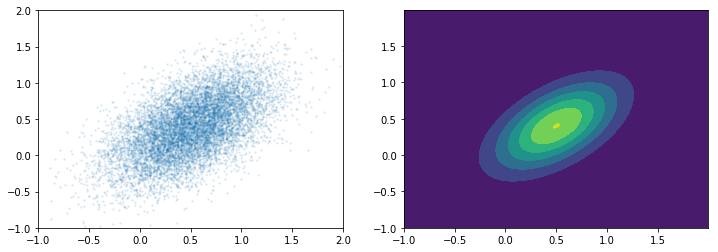
このプログラムによりサンプリングした結果が下図(左)です.右に示す実際の確率分布に従ってサンプルされていることが確認できます.
参考元
Wikipedia,『ボックス=ミュラー法』
捨てられたブログ,『多変量正規分布にしたがう乱数の生成』,https://blog.recyclebin.jp/archives/4077