[Agenda]
1.Introduction
2.Conclusion
3.Development_environment
4.Data_preparation
5.Learning
6.Result
1. Introduction
レゴブロック遊んでいますか?片付けでドカッと箱にいれるとブロックが混ざって次遊ぶときに手間取るのが困りますよね。そこで片付け仕分け自動機を作れんもんかと、先ずキー技術になるディープラーニングを利用した画像判別に挑戦しました。レゴに限らずブロック類の画像識別を調べている方の参考になれば幸いです。
+この記事でわかること
- 学習データの準備方法 「どうやってレゴ画像を集めたか」
- 学習設定とコーディング 「どのような学習を行ったか」
- 学習結果 「識別精度」
「このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。」
2. Conclusion
12種類の型番を対象として判別精度84%を得ました。アプリとして公開しています。
https://lego-app.onrender.com/

3. Development_environment
- Google Colaboratory
- Visual Studio Code
- Jupyter notebook
4. Data_preparation
レゴブロック種類と対象
レゴには皆さんがまず思い浮かべるシステム系と呼ばれる普通のレゴに加え、幼児用の大きなサイズの「Duplo」やそして細かい表現まで実現する大人用の「テクニック」という大枠の種類があり、それぞれ互換性をもっています。ちなみに、これら本場デンマークのレゴに対し、Kawadaさんから「diablock」、「nanoblock」といった似た商品もあります。
普通のレゴの種類を調べてみると下表の表になります。
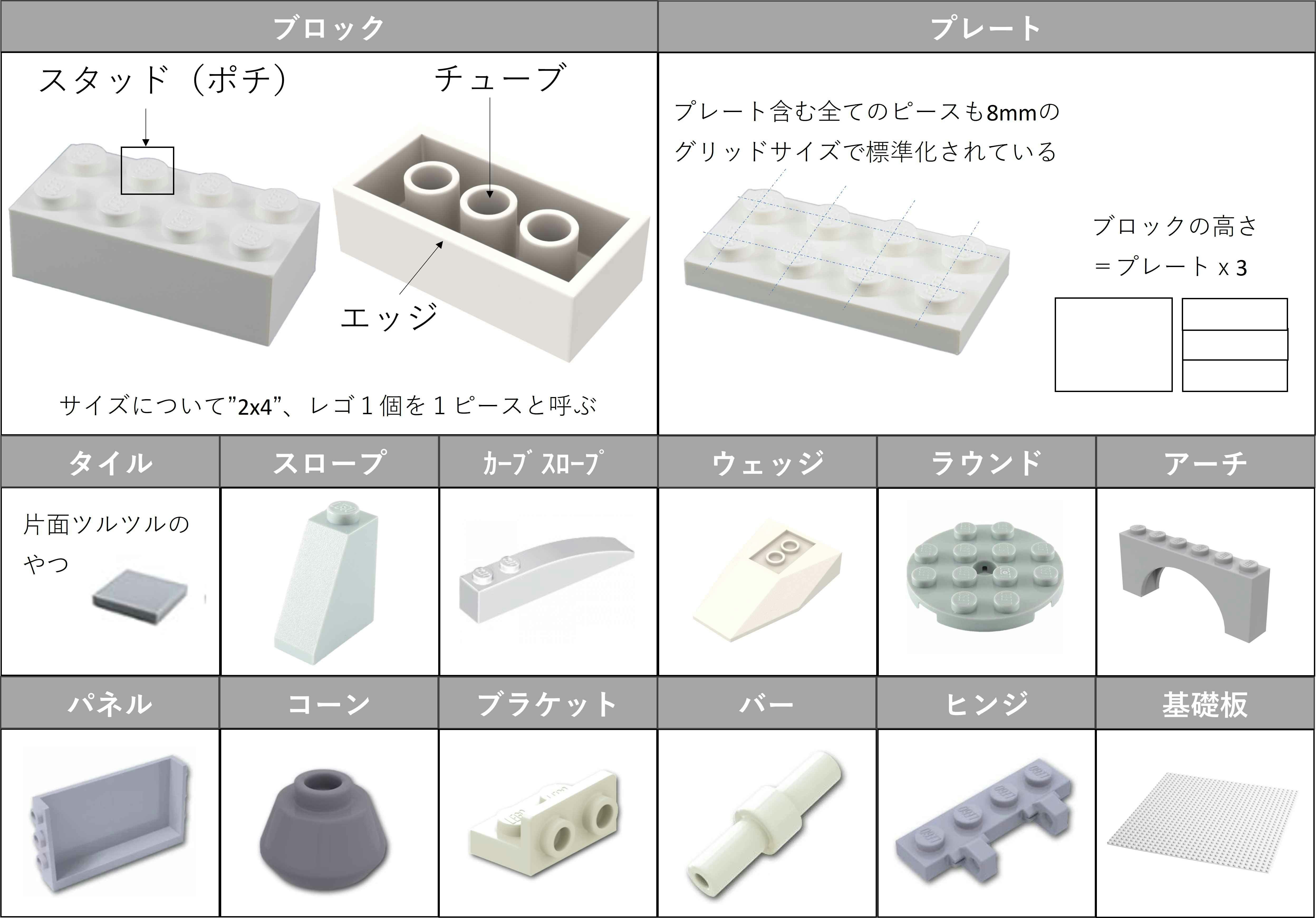
表からわかる通り種類豊富ですので最初から全種類狙わず、スモールスタートで効果を確認する方針とします。子供の玩具箱から失敬して手持ちブロックから次の12種類に対象を絞りました。各ブロック写真の上にあるのが、商品型番で種類とさらにブロックサイズで型番が決まっています。

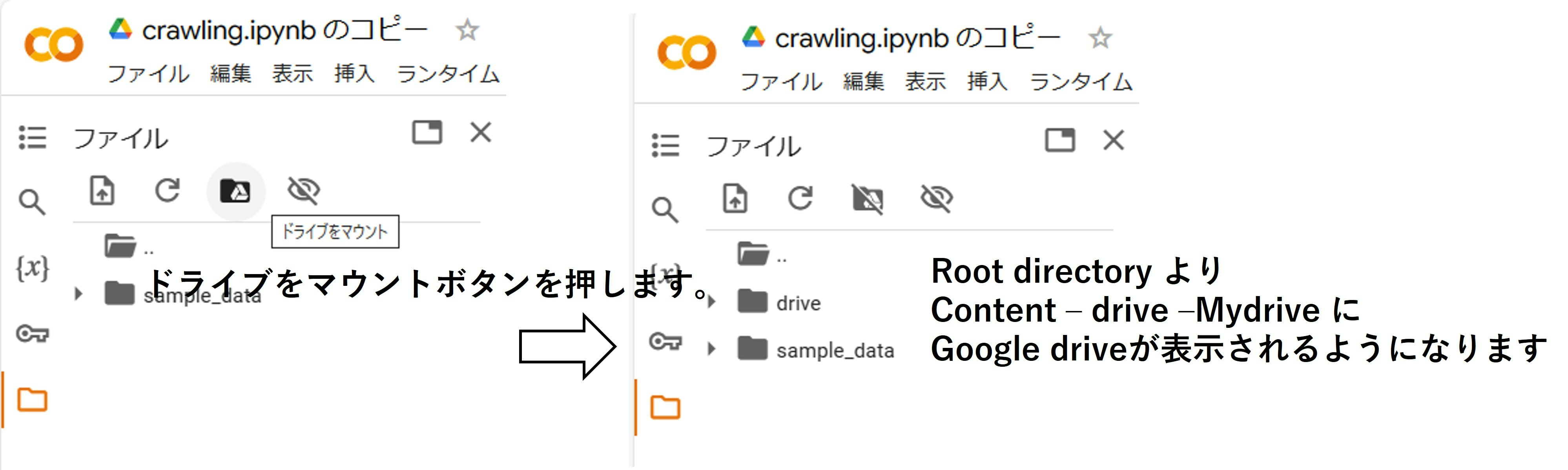
ネットより学習用データ(型番ごとの写真)収集
グーグルからgoogle colaboratoryというブラウザ上でpythonを記述、実行できる無料サービスがあります。これを使って画像を収集します。ただし大量画像をcolabにて保存することはできないので、colabにgoogle driveをマウントさせ、そちらに収集した画像を保存するようにします。
画像収集にはpythonライブラリのicrawlerが便利です。コーディングはicrawlerインストールと、収集の以下2つになります。今回は検索エンジンに BingImageを指定して、各型番で500枚の画像収集させてみました。
!pip install icrawler
from icrawler.builtin import BingImageCrawler
keywords = ['lego brick 3005','lego brick 3004','lego brick 3010','lego brick 3009',
'lego brick 3003','lego brick 3002','lego brick 3001','lego brick 2456','lego brick 3022',
'lego brick 3021','lego brick 3020','lego brick 3795']
for keyword in keywords:
crawler = BingImageCrawler(storage = {'root_dir':'/content/drive/MyDrive/Aidemy_outcome/'+keyword})
crawler.crawl(keyword = keyword, max_num = 500)
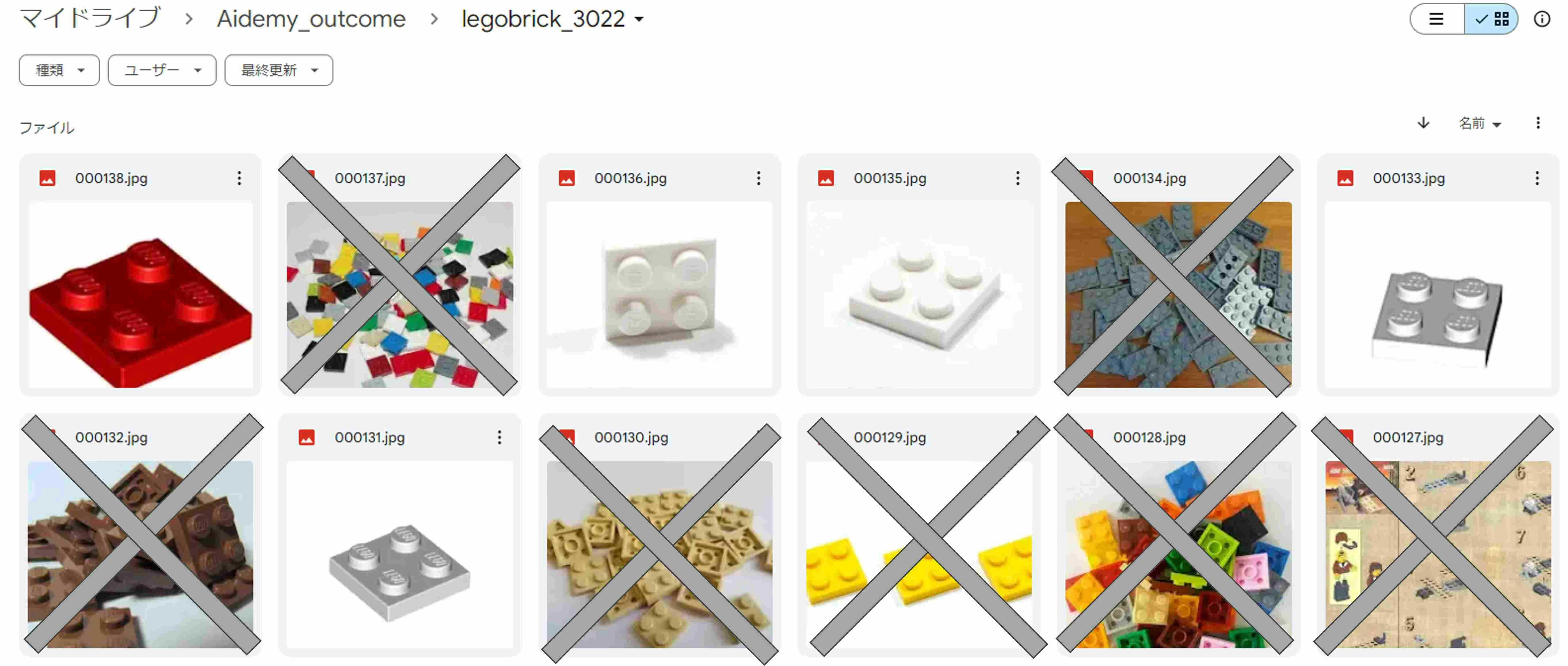
実際に収集された画像枚数は下表の通りです。Bingにて画像検索したイメージを収集するだけですので、そもそも検索ヒットした分しか集まらないのと、ダウンロードエラー ERROR:Downloaer:Response status code 404も出てきて、100枚程度しか集まりませんでした。さらに中には欲しくない学習データもあります。例えばブロックが複数映っている写真やレゴとは全く関係ない写真では学習が困難なので、これらは手作業で削除します。なお削除ですがgoogle driveをmicrosoft edgeで開くとファイルが写真アイコンとなっているので1枚1枚ファイルを開くことになりますが、google chromeで見てみるとアイコンでなく縮小画像で表示されますので、こちらで作業するのが圧倒的に速いですよ。結果、学習データとして集まった画像枚数について下表を参照ください。
| 型番 | 収集画像枚数 | 学習向きでない画像削除後の枚数 |
|---|---|---|
| #3005 | 132 | 110 |
| #3004 | 147 | 121 |
| #3010 | 83 | 64 |
| #3009 | 110 | 97 |
| #3003 | 120 | 100 |
| #3002 | 156 | 124 |
| #3001 | 94 | 64 |
| #2456 | 178 | 107 |
| #3022 | 138 | 96 |
| #3021 | 152 | 104 |
| #3020 | 153 | 90 |
| #3795 | 172 | 131 |
↓削除写真
現物から画像収集
実はネット画像だけでは枚数が少ないためか8種類に絞っても学習精度53%しか得られませんでした。なので地道にスマホで写真撮りもしました。連写性能の良いXcameraという無料アプリを使って下図のように写真とりました。

写真ですが、レゴの上下も変えて写真撮りしました。学習のことを考えるとレゴのスタッドは良い形状特性で精度に効いてきそうですが、実用のことを考えると表裏を選べませんから両方取得しました。

私は単純作業のストレス耐性がありませんので、1種類10分程度のyoutube動画を流しながら撮影で動画が終わったら撮影もお終いと決めて作業しました。最終的に集めた画像は下表の通りです。
| 型番 | 学習向きでない画像削除後の枚数 | 撮影した写真枚数 | トータル枚数 |
|---|---|---|---|
| #3005 | 110 | 480 | 590 |
| #3004 | 121 | 747 | 868 |
| #3010 | 64 | 638 | 702 |
| #3009 | 97 | 704 | 801 |
| #3003 | 100 | 568 | 668 |
| #3002 | 124 | 707 | 831 |
| #3001 | 64 | 401 | 465 |
| #2456 | 107 | 1294 | 1401 |
| #3022 | 96 | 467 | 563 |
| #3021 | 104 | 907 | 1011 |
| #3020 | 90 | 1388 | 1478 |
| #3795 | 131 | 1348 | 1479 |
5. Learning
画像認識の技術はエラー率を指標に進化してきました。ILSVRC主催コンペの歴史を見ますと30%弱のエラー率程度しか得られてませんでしたが、2012年にトロント大学よりCNN(畳み込みニューラルネットワーク)を利用したAlexNetが17%と圧倒的に低いエラー率を達成し、CNNブームが巻き起こりました。2014年にOxford大学が発表したVGG16はエラー率7.3%を達成し、2015年はMicrosoft ResearchのResNetが人間のエラー率5%を下回るまで進化し、AI実用化元年の幕開けになりました。
今回は一昔前の学習モデルになりますが、そのぶん利用しやすくなっているVGG16を使ってレゴ識別させてみます。なお代表的なアーキテクチャーについてはリンクの記事を読んでみてください。
https://ai-kenkyujo.com/artificial-intelligence/ai-architecture-02/
コーディングは以下の通りです。はじめはgoogle colabで学習させていたのですが、学習よりも画像の読み込みの方で40分以上と時間を要してました。そこでjyupyter notebookによるローカル開発に切り替えたところ1分程度で読み込みと学習を終えることができましたので、お勧めします。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
path_3022 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3022')
path_3021 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3021')
path_3020 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3020')
path_3795 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3795')
path_3003 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3003')
path_3002 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3002')
path_3001 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3001')
path_2456 = os.listdir('E:/JE work space/06_python/python practice/legobrick/2456')
path_3005 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3005')
path_3004 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3004')
path_3010 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3010')
path_3009 = os.listdir('E:/JE work space/06_python/python practice/legobrick/3009')
img_3022 = []
img_3021 = []
img_3020 = []
img_3795 = []
img_3003 = []
img_3002 = []
img_3001 = []
img_2456 = []
img_3005 = []
img_3004 = []
img_3010 = []
img_3009 = []
for i in range(len(path_3022)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3022/' + path_3022[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3022.append(img)
for i in range(len(path_3021)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3021/' + path_3021[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3021.append(img)
for i in range(len(path_3020)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3020/' + path_3020[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3020.append(img)
for i in range(len(path_3795)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3795/' + path_3795[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3795.append(img)
for i in range(len(path_3003)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3003/' + path_3003[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3003.append(img)
for i in range(len(path_3002)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3002/' + path_3002[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3002.append(img)
for i in range(len(path_3001)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3001/' + path_3001[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3001.append(img)
for i in range(len(path_2456)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/2456/' + path_2456[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_2456.append(img)
for i in range(len(path_3005)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3005/' + path_3005[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3005.append(img)
for i in range(len(path_3004)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3004/' + path_3004[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3004.append(img)
for i in range(len(path_3010)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3010/' + path_3010[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3010.append(img)
for i in range(len(path_3009)):
img = cv2.imread('E:/JE work space/06_python/python practice/legobrick/3009/' + path_3009[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_3009.append(img)
X = np.array(img_3022 + img_3021+ img_3020+ img_3795+img_3003 + img_3002+ img_3001+ img_2456+img_3005 + img_3004+ img_3010+ img_3009)
y = np.array([0]*len(img_3022) + [1]*len(img_3021)+ [2]*len(img_3020)+ [3]*len(img_3795)+ [4]*len(img_3003)
+ [5]*len(img_3002)+ [6]*len(img_3001)+ [7]*len(img_2456)+ [8]*len(img_3005)+ [9]*len(img_3004)
+ [10]*len(img_3010)+ [11]*len(img_3009))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
input_tensor=Input(shape=(50,50,3))
vgg16=VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
top_model=Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256,activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(12,activation='softmax'))
model=Model(inputs=vgg16.input,outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable=False
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4,momentum=0.9),metrics=['accuracy'])
history=model.fit(X_train, y_train, batch_size=100, epochs=10, validation_data=(X_test, y_test))
model.summary
# 画像を一枚受け取り、ブロック型番を判定して返す関数
def pred_brick(img):
img=cv2.resize(img,(50,50))
pred=np.argmax(model.predict(np.array([img])))
if pred==0:
pred_brick='#3022'
elif pred==1:
pred_brick='#3021'
elif pred==2:
pred_brick='#3020'
elif pred==3:
pred_brick='#3795'
elif pred==4:
pred_brick='#3003'
elif pred==5:
pred_brick='#3002'
elif pred==6:
pred_brick='#3001'
elif pred==7:
pred_brick='#2456'
elif pred==8:
pred_brick='#3005'
elif pred==9:
pred_brick='#3004'
elif pred==10:
pred_brick='#3010'
elif pred==11:
pred_brick='#3009'
return pred_brick
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# 学習モデルの保存
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'model.h5'))
VGG16はcifar10という10種類の画像を識別するもので、そのエッセンスは5回の畳み込み層の処理と、そこから10種類のどれに分類されるかというアウトプットにつなげる全結合層から構成されています。レゴ12種類を分類したいので、前者はそのまま流用、後者を12種類用にアレンジします。上記コーディングから以下の部分になります。このような学習の方法は転移学習と呼ばれます。
top_model=Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256,activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(12,activation='softmax'))
model=Model(inputs=vgg16.input,outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable=False
また学習のパラメータは以下になります。誤差関数にはcategorical_crossentropyを、最適化関数はSGDを、バッチサイズ100、エポック数を10としました。ニューラルネットワークとは、人間の脳の様に多数のニューロンが結びついた構造をしていて、任意の画像のINPUTを受けて、それが何であるかのOUTPUTを出します。そして、それぞれのニューロンで行う処理の重みづけを変えることで、正答率を上げていきます。すなわち、予測と正解の差をクロスエントロピー誤差と定義し、その差分の埋め方にSGDという最適化関数を選んだわけです。この最適化関数は損失関数が最小値をとるまでの過程なので正しい選択をしないと学習に悪影響を及ぼします。
model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-4,momentum=0.9),metrics=['accuracy'])
history=model.fit(X_train, y_train, batch_size=100, epochs=10, validation_data=(X_test, y_test))
model.summary
6. Result
エポック数(学習回数)に応じて下図のように精度向上しました。accuracyは学習データにて、val_accuracyは検証用データを使った時の精度のことです。実用には至りませんでしたが、5項の冒頭で述べた通り、CNNを用いたからこそ達成可能な精度レベル83.5%を得ることができました。
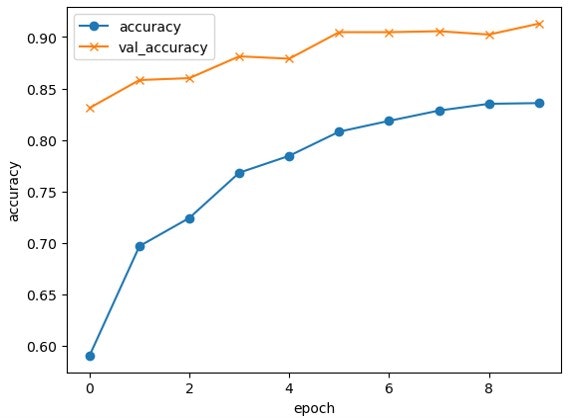
自分なりにモデルを検証しますと、ブロックの色で間違えているケース、いずれの写真でも2x3プレート(#3020)と間違えるケースが多いと感じました。前者からはカラー→モノクロへの画像前処理、後者は各画像データ数をそろえておくべきだったという反省が得られました。一方で外形の輪郭を判断しているのか、レゴの表裏という要素については問題なく識別できているようです。ここまでわかりましたので今回は、ここでアプリ開発を区切りたいと思います。
記事を読んでくださいまして、ありがとうございます。