この記事は ドワンゴ Advent Calendar 2014 の23日目の記事です。
昨日は hiroki_kanaさん でした。
最近、Sparkというソフトウェアがデータ解析界隈でこれからくる計算基盤になるのではと注目を浴びています
こいつを使って、ちょっと簡単なTwitterネガポジ分析をしてみましょう
TL;DR
- sparkは比較的新しい分散処理基盤
- その中にStreamを扱うライブラリがある
- ec2で手軽にクラスタを組んで試せる
- ec2でspark streamingを使って、ドワンゴに関する文字で検索した結果からネガポジ分析してみた
Sparkって何?
最近Scala界隈だったりデータ分析界隈で賑わっている、比較的あたらしい分析処理基盤になります
http://spark.apache.org/
このページを見ると、一番上にこう書いてあります
Run programs up to 100x faster than Hadoop MapReduce
100倍ってちょっとどういうことなの?ってなりますが、ここらへんの概念的な解説はちょろちょろ記事が出ているので、google先生に聞くといいです。
一言でいうと、Reduceした結果をDiskに入れずにメモリに保持しておくから早いという話ですね。
あと個人的に好きな特徴として、Scalaライクにクエリを記述出来るということがあります。ワードカウント処理はいかのように記述できます 1
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Scalaのコレクションライブラリライクな構文で問い合わせできるので、読みやすくていいです
Spark Streamingって?
Sparkの中にあるライブラリの一つです。Sparkは単純な処理基盤だけじゃなくて、いくつか大規模なデータを扱う上で便利なライブラリを提供しています
- MLlib(ML)
- Streaming
- SQL
- GraphX
MLlibは機械学習用のライブラリ、SQLはでクエリを発行するライブラリ、GraphXは有向/無向グラフをサポートするライブラリになります。
Streamingは、入力データにストリームデータを扱えるようにするライブラリです。StreamデータをSQLライクに取り出して、学習データとして使う、とかいうことも出来そうです。
EC2で使う
Sparkは分散処理基盤なので、多くのノードで動かしたいです。でもそんなたくさんサーバ持ってない(◞‸◟)
そういう時のために、SparkはEC2上のノードに環境を構築してくれる便利なスクリプトがあります
http://spark.apache.org/docs/latest/ec2-scripts.html
今回はこいつを使って分散処理環境を作ってクエリを流してみます
クエリを書く
クエリはPython, Scala, Javaで記述出来ます。
SparkはScalaプロダクトなので、ここはスタンダードにScalaで記述します
今回作ったコードはこちらです。これをsbt assemblyしてjarを用意しておきます
build.sbtは適当なのでひどいjarが出来ます
簡単に言うと、ドワンゴとかニコニコとかで引っかかったツイートに対して簡単なネガポジ判定を行い、その間スコアを吐き出し続けるスクリプトです
各ツイートの平均を扱うのではなく、各ツイートを形態素で分解し、ネガポジを判定できた場合、得られたスコアを単純に足していくだけの簡単なスクリプトですね
ネガポジ判定には、東工大奥村研の高村氏の単語感情極性対応表を利用させて頂きました
ec2上にクラスターを構築する
ec2のkeypairを用意したら、公式サイトかgithubからSparkを落としてきて、以下のようなオプションでec2インスタンスを立ち上げましょう
./spark/ec2/spark-ec2 -k spark-test -i ~/.ssh/spark-test.pem -s 8 --instance-type=r3.large --region=ap-northeast-1 --spot-price=0.04 launch spark-streaming-test
上のコマンドで、東京リージョンにインスタンスタイプをr3.large、上限$0.04で、スポットインスタンスを9台立てます
-s はスレーブ数の指定ですが、スレーブの他にマスターも立ちますので合計9台になります
余談
Sparkのノードは4つに分かれます
- Client
- Master
- Slave
また、Slaveも以下の二種に分かれます
- Driver
- Executor
Clientは、ユーザのJarをマスターに登録する動作のエントリポイントです
Masterは、ユーザアプリケーションが登録されたりした際に、各スレーブを制御するSupervisorです
Driverは、ユーザアプリケーションを評価し、タスクを分割、スケジューリングしてExecutorに割り振ります
Executorは、Driverから割り振られたタスクを実行し、Driverへ返します
MasterはSlaveの制御のみを行うため、例えばソース中に標準出力を混ぜていたりすると、Driverや各種計算しているノードの標準出力に現れたりするので注意してください
また、client <-> Master <-> Slaveと疎通を取るので、必ずそれぞれがネットワーク的に見える位置にないと使えないから注意してください
動かす
疎通が取れればどこでもいいですが、今回はec2側にjarを配置して動かしました。
jarをscpとかで配備すればOKです
クラスタ構築スクリプトを立ち上げたあとであれば、それぞれにMasterとSlaveが立っています。Sparkを動かすときには必ずMasterの位置を知らなければならないので、AWSコンソールで調べましょう
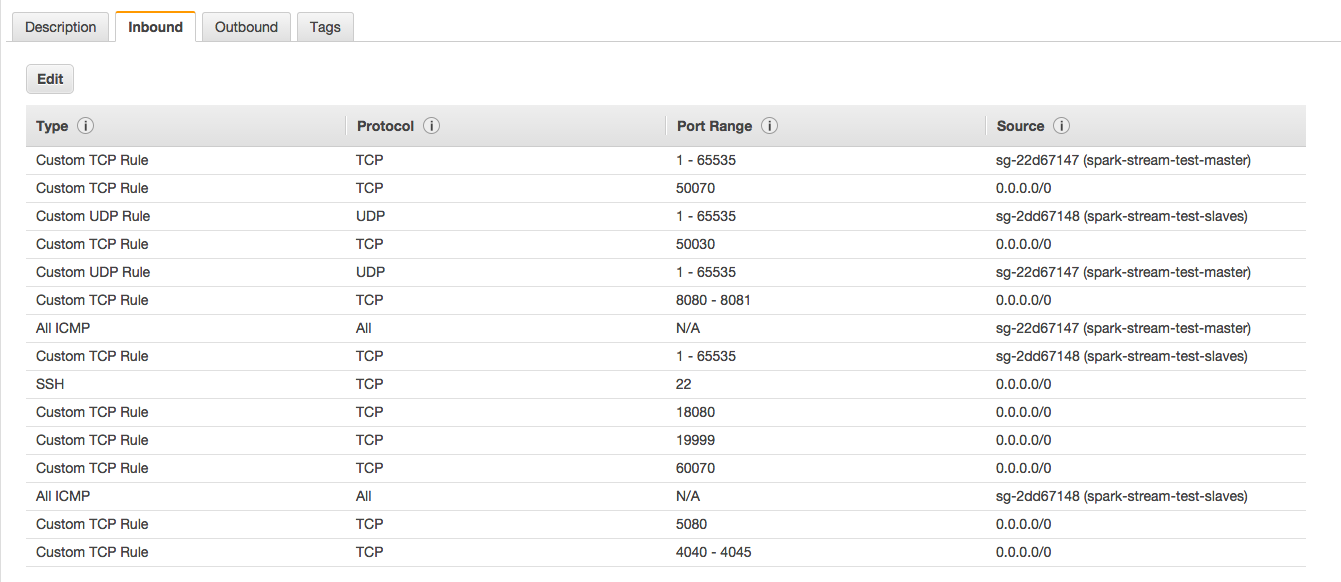
launchの時の名前で自動でSecurityGroupが作られているのでここを見ます。通信に7077を使用しますが、なぜか最初は開いてません。
外から通信する場合は、Masterのinboundに7077の穴を設定してやるといいと思います
このMasterに対してscpして、sshログインしてから、spark-submitコマンドを使ってsparkクラスタにクエリを流します
spark/bin/spark-submit --class jp.co.jagaximo.sparktest.TwitterStream --master spark://ec2-xx-xx-xx-xx.ap-northeast-1.compute.amazonaws.com --num-executors 8 --driver-memory 5g --executor-memory 10g /home/ec2-user/spark-stream-test-assembly-0.1-SNAPSHOT.jar > result.txt
これで後は計算が始まり、結果を待つだけになります
今回はcollectしてからreduceしているので 2 、Clientに結果が帰ってきて、標準出力されているはずです!
ちなみに結果値は、マイナスにいけばいくほどネガティブ、プラスにいけばいくほどポジティブです!
$ tail -f result.txt
-1.960453
-6.2110934
-11.106579
-20.666113
-43.860996
-24.150688
-4.315246
-9.761276
-4.6580086
-11.316431
-33.602352
-4.067742
-17.903742
-12.507953
-17.765516
-17.9638
-15.614052
-18.031628
-15.58922
-10.353515
基本マイナス推移で進行してますね……
二重否定みたいな難しい構文をきちんと解析しているわけじゃないし、まぁこんなものでしょう!
まとめ
- dwango、ドワンゴ、ニコニコ、niconicoで検索して引っかかったツイートでネガ・ポジ判定をしてスコアを加算するだけのクエリを書いた
- 基本、ネガティブ進行だった。悲しい
というわけでSparkStreamingをAmazon EC2で使う、でした。
明日はドワンゴのアイドル、瀧澤さんになります。お楽しみを。