GraphQLは実装内容に合えばタイタニックの救命ボードのように混沌から救い出してくれる。だからと言って全てのプロジェクトがタイタニックな訳ではないので、使い所が合わなければそんな救命ボードにもあまり意味は無い、という話。
先日、個人開発して公開したプロジェクト「node-node-node」のバックエンドはRails APIにGraphQLを使っていて、このプロジェクト内容に対しては最高の親和性を発揮してくれた。
GraphQLのメリットを一言で言えば「クライアント=サーバー間での複雑なトランザクション処理の全てをGraphQLが吸収してくれる」ということに尽きる。ややこしい技術の詳細を書いたところでメリットはこれ以外に無い。
/usersや/postsというそれぞれのエンドポイントにリクエストを投げていたのがRESTful。
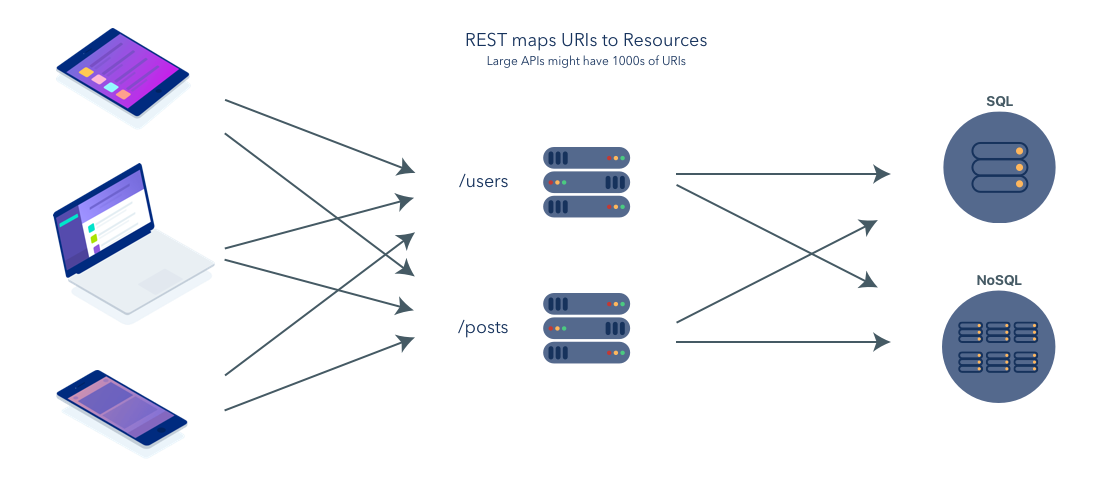
GraphQLにするとエンドポイントを気にすることなく「これとこれが欲しい」という感じで投げればGraphQLが理解してレスポンスを返してくれる。
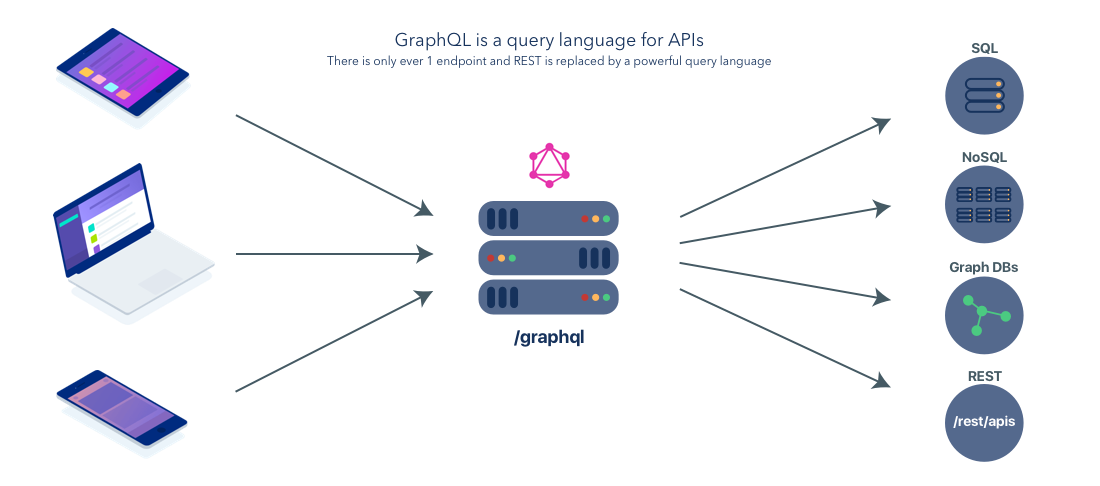
なぜ個人開発のプロジェクトにGraphQLが大ハマりしたかを書く。このプロジェクト実装のポイントはRESTで言う複雑なGETにあった。
親子関係が何回も続く階層構造になったノードがサーバー側のDBにあって、クライアントは適切なノード情報をサーバーから取り寄せる必要がある。全てのノードは以下のようになっていて、親子関係がずっと続く。
ジジイ、ババア、ジジイ、ババア
|
親、親、親、親
|
本人、兄弟、兄弟、兄弟
|
子、子、子、子
|
孫、孫、孫
できるだけサクサク感を出すためにクライアントはユーザが今アクセスしているノードから次にクリックするかもしれないノードの情報を非同期でサーバーから集めている。ユーザーがクリックするころには既に裏側で集めておいた情報を出すだけ、とした。
この設計の場合、ユーザの置かれた状況によって、裏側で集めるべきノードが異なってくる。
例えば上のジジイ側から本人へ下りてきたユーザの場合、裏側で集めるべきノード情報は子や孫だけになる。なぜならジジイ側から下りてくる過程で既に本人より上の親ノードの情報は持っているから。
逆に孫側から上ってきたユーザーの場合は集めるべきは親やジジイになる。上がってくる過程で子ノード以下の情報は持っていることになるから。
兄弟の兄側から来た場合は末っ子側のノード情報が必要になる。
で、これを丁寧にRESTfulで書いていくとすごい数のエンドポイントになっていった。
ざっくりと親から、子から、兄弟からと3パターンだけ示したが、それ以外にもLikeした情報がある場合、無い場合、とかそれぞれのエンドポイントに独自の情報の有り無しを加えていったのでパラメータまで煩雑な状態となっていた。私はDHHのルーティングを支持しているのでCRUDアクションindex、show、new、edit、create、update、destroyのみを使うようにして、これ以外が必要な時は新しいコントローラーを作っていた。するとスゲー数のエンドポイントになって、Reactで作ったクライアントは状況に合わせてエンドポイントを使い分ける必要があって、どれがどれか混乱してきて「キー!」となった。
で、これをGraphQLに移行することでクライアント=サーバー間にあったややこしい部分をクエリ言語が全て吸収してくれた。クライアントからは欲しい情報を書いてリクエストすれば、それをそのままサーバーが返してくる仕組み。
そしてエンドポイントはたったひとつに、バージョンも何もない、ただひとつ!
例えば親側から来たユーザー向けに子情報が欲しい時のリクエストがこれ。要はchildrenをよこせ、と。
# client => server へのリクエスト(query)
query {
Nodes {
id
message
children {
id
message
}
}
}
するとサーバーからのレスポンスはこうなる
# client <= server レスポンス
"data": {
“Nodes”: {
“id”: 3,
“message”: “Hi I’m CEO.”,
"children": [
{
“id”: 4,
“message”: “Hi, I’m CTO.”
}
]
}
}
つまりリクエストとまったく同じ形でレスポンスが返ってくる。
親情報が欲しければただリクエストにparentをつければいいだけ。めちゃ楽ちん。
ページネーションはこんな感じに実装した。例えばたくさん子ノードがあって3ページ目が欲しい場合はchildren(page: 3)とするように。
query {
Nodes {
id
children(page: 3) {
id
message
}
}
}
ほとんどのウェブサイトにおいてクライアントが欲しい情報が1種類ではない。記事情報とユーザー情報とそのユーザーへの通知情報、となったりする。RESTfulの場合はそれぞれを
GET api/v1/users
GET api/v1/posts
GET api/v1/notifications
という感じで3回リクエストしてそれぞれの情報を集める。
GraphQLの場合は全てを1発のリクエストにして放り込める。
例えばこんな感じで、PostsとUsersとNotificationsをまとめてよこせよ、と。
query {
Posts(page: 0) {
id
message
}
User {
id
name
}
Notifications {
id
status
}
}
するとこの型のまま記事とユーザーと通知の情報の入ったレスポンスがひとかたまりで得られる。クライアントからすれば欲しい時に指定した欲しい情報だけが取れる。(最初これを実装して本当にその通りにレスポンスが返ってきた時になぜが声出して笑った。)
限りなく薄いGraphQLが理想
ある記事でRailsにGraphQLを入れた場合、MVCで言うところのMVC全てがGraphQLに集約されてしまう、みたいなのを読んだ。これ明らかにおかしい。初めてGraphQLに出会った際には「これスゲー!」と興奮してなんでもGraphQLに入れ込みたい気持ちは分かるが、そんなことしろなんて公式サイトのどこ見ても書いてない。ファットコントローラーと同じくファットGraphQLはメンテナンス不能でたちが悪い。
GraphQLの作者Lee Byron氏も言うように「なんでもできるGraphQLだが、GraphQLはできるだけ薄く保つのがいい」と。GraphQLの責務と役割はquery(RESTfulのGET)とmutation(POSTもしくはPATCH)だけであって、それ以外は無い。したがってresolve ->(obj, args, ctx)の中にロジックがあったら、その責務はどこが持つべきか考えてそこに移すべき。
GraphQLが遅いって?それ設計の問題では
GraphQLのディスり記事にスピードに関する言及が多かった。例えば「まともにキャッシュが効かねー」とか。これは間違い。もう既に数々のキャッシュ方法がクライアント、サーバー共に提案されている。実際、前述のnode-node-nodeにおいてもキャシュを入れている。大きめのqueryでキャッシュ無しだと300msかかっているレスポンスがキャッシュで3msとかで返すことができている。そこはキャッシュ使うので当たり前なんだけど、スピードを議論するのであればキャッシュどうこうではなく、クライアントが欲しい情報を何msで取れるのか、とすべき。GraphQLのあるクエリがちょっと遅かったとしてもリクエストを1発でまとめて入れてるのでRESTfulで5、6回繰り返して「はいできました」となるまでにかかる時間と比較して必ずしも遅いとはならない。
N+1問題
GraphQLはN+1問題を誘発する、というディスり記事もあった。もうこれはハッキリしていてN+1問題なんて出てる時点でそれをクエリ言語のせいにするのはお門違い。確かに気付かないところでN+1を含むおそれはあるが、百歩譲ってもそれGraphQLじゃなくて、あなたの設計の問題ですから、と。
GraphQLはちゃんとハマればハッピー
本記事の冒頭でGraphQLをタイタニックの救命ボートに例えたが、既存のプロジェクトの船底に穴が空いて沈みかけてるのに船の上で上品なお食事を楽しんでいる人達みたいに気付いていないだけ、というのがよくある。熱い技術なのでGraphQLが現行のプロジェクトに合うかどうかぐらいは確かめた方がいいと思う。
以上がGraphQLを使ってみて得た雑感でした。
これがGraphQLで実装したプロジェクト「エンジニアの集合知をノードグラフで図解するSNS(デスクトップ版)」。
エンジニアの集合知をノードグラフで図解するSNS。
「node-node-node(ノード ノード ノード)デスクトップ版」
https://node-node-node.netlify.com/