操作変数法とは何か?
調整・観測できない交絡のある構造下で平均因果効果を推定しようとした時に、交絡を調整することなく操作変数と言う変数を用いて因果効果を推定する手法です。
特に観測できない交絡がたくさん考えれる社会科学のデータ分析だと有用されています。
以下ではDAG(Directed Acyclic Graph)と呼ばれる、それぞれの変数の因果関係を表したグラフである。このDAGを使って操作変数を使うとなぜAからYへの因果効果が推定できるかを説明していきます。
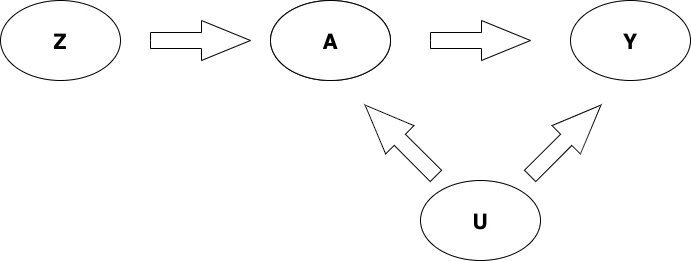
ここで、
- A: 施策/処置
- Y: Outcome変数
- Z: 操作変数
- U:観測できない交絡変数
と言う4つの変数があり、それぞれ矢印で結ばれている。DAGでは
矢印を指している側の変数が、刺されている側の変数に影響を及ぼしている
と解釈する。
今、A(施策)のYへの効果を推定したいとする。
しかし、AとY両方に相関するUという変数のせいで、A,Y間の相関を因果として解釈できなくなってしまっている。
今回はUが観測できない時に、その交絡を調整しないでこの因果関係を推定する手法としてIV法というものを紹介する。(cf:欠落変数バイアス)
ここで改めて操作変数とはなんなのか?を説明したい。
操作変数とは、
- 施策変数Aと相関しており、
- 施策変数Aを通してのみ目的変数Yに因果関係を持つ(除外制約)
ような変数のことである。
DAGをご存知の方はお分かりだと思うが、ZはAを介してのみ、Yとつながっている。上記の1.2の条件はこのDAGによってうまく描写されている。
この時、
$\displaystyle \frac{Cov(Z, Y)}{Cov(Z, A)}$と言う推定量を考えてあげると、これがAからYへの平均因果効果の不偏推定量となります。1
この推定量(以下、IV推定量と呼ぶ)がなぜ不偏推定量となるのか?
ここでは山口(2019)2を参照しつつ、直感的な説明をしたいと思います。
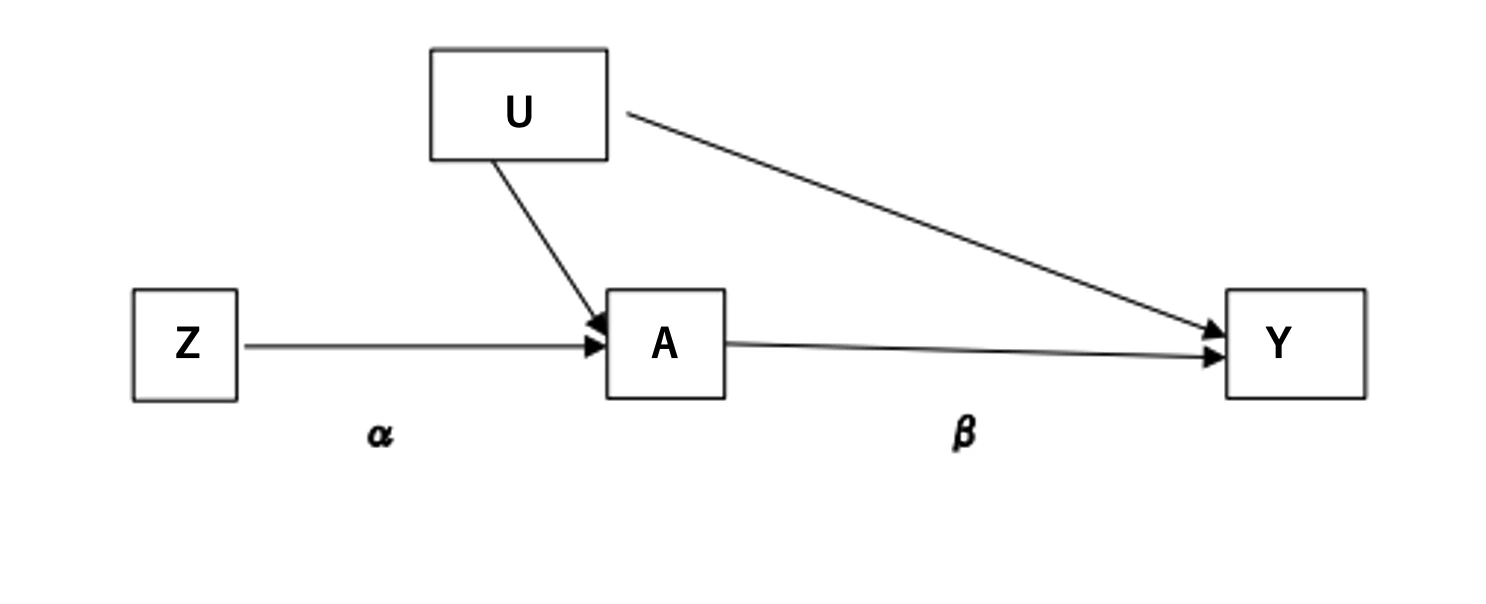
仮に、ZからAへの因果効果が$\alpha$, AからYへの因果効果が$\beta$と言う値をとるとします。
この時、$\displaystyle \frac{Cov(Z, Y)}{Cov(Z, A)}$の分母が$\alpha$の推定量となり、分子が$\alpha\beta$の推定量になります。
したがって、分子を分母で割り算をしてあげることで、推定したかった$\beta$が推定できます。
とまぁ、これが、細かいことを削ぎ落とした操作変数法の説明です。3
以下では、実際に上記のDAG的な状況をsimulateして、操作変数推定してみましたのでご紹介致します。
Simulation using Python
- 説明変数A, 操作変数Z,及び交絡変数Uを多変量正規分布$N(\mu, \Sigma)$から生成する
- $\mu = [\mu_A = 0.5, \mu_Z = 1.5, \mu_U = 20.0]$
- $\Sigma:$分散共分散行列、$Cov(Z, A) = 0.4,Cov(A, U) = -0.7, Cov(Z, U) = 0.0$を満たすと仮定する。
import numpy as np
Sigma = np.eye(3)
# 1行/列目がA, 2行/列目がU, 3行/列目がZに対応する。
Sigma[1, 0] = -0.7
Sigma[0, 1] = -0.7
Sigma[2, 0] = 0.4
Sigma[0, 2] = 0.4
# 説明変数A, 操作変数Z,及び交絡変数Uを多変量正規分布$N(\mu, \Sigma)$から生成する
d = np.random.multivariate_normal([0.5, 1.5, 20.0], Sigma, size=10000)
>>> Sigma
array([[ 1. , -0.7, 0.4],
[-0.7, 1. , 0. ],
[ 0.4, 0. , 1. ]])
- 目的変数yは以下のように定式化されているとする。
- $y = 2 A + 6U + \epsilon$
- where $\epsilon \sim N(0, 1)$
# error term
e = np.random.randn(len(d))
# d matrixを分解してそれぞれの変数を作成
A = d[:, 0]
u = d[:, 1]
Z = d[:, 2]
# 目的変数の真のモデル
# y = 2 A + 6U + \epsilon
y = A*2 + 6*u + e
# 相関関係の確認
print("Cov(A, u)=", np.corrcoef(A, u)[0, 1])
print("Cov(Z, u)=", np.corrcoef(Z, u)[0, 1])
print("Cov(A, Z)=", np.corrcoef(A, Z)[0,1 ])
Cov(A, u)= -0.701004490456518
Cov(Z, u)= 0.0043542162380179215
Cov(A, Z)= 0.39744458663706667
$Cov(Z, U)$はほぼ0になっている、と言えるし、$\Sigma$で設定したそれぞれの変数の関係はDAGの状況を再現しているといえます!
ここで、単純にAとYの関係を散布図でみてみると?
g=sns.scatterplot(x=A, y=y, )
g.set_ylabel("y");g.set_xlabel("A");
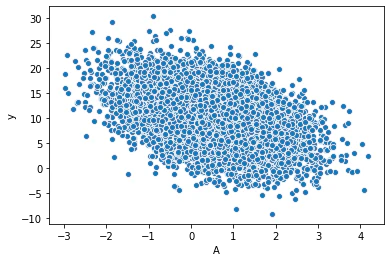
このように負の相関関係にあるように見えますね!
しかし、上の定式では、$y = 2 A + 6U + \epsilon$ であり、AのYへの因果効果は2です。
これは、UがAとY両方に影響しているために起きています。
実際に、
g = sns.scatterplot(x=A, y=y-6*u, hue=u)
g.set_ylabel("outcome variable")
g.set_xlabel("Explainary variable")
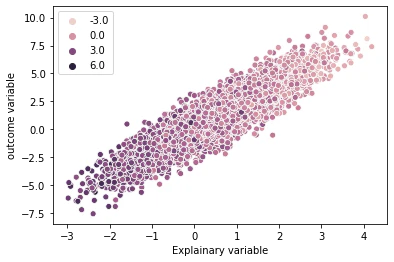
AとUに負の相関関係があるのでがAが大きくなるに従って、Uが小さくなっていることがわかります。
from statsmodels.regression.linear_model import OLS
lm = OLS(endog=y, exog=np.c_[A, u])
results = lm.fit()
results.params
# ordinary least squares
X = sm.add_constant(A)
>>> print("単純にXでyを回帰すると", OLS(X, y).fit().params[0])
>>> print("交絡要因を組み込んで重回帰してあげると、", results.params[0])
単純にAでyを回帰すると -2.1853899626462927
交絡要因を組み込んで重回帰してあげると、 2.022653523550131
交絡要因Uを観測できていれば今回の真のモデルでは重回帰してあげることで平均因果効果を推定できます。
操作変数法を使ってみる
$\displaystyle \frac{Cov(Z, Y)}{Cov(Z, A)}$を計算する以下のような関数を導入して実際にIV推定してみたいと思います。
def IV(A, y, z):
denom = np.cov(A, z)[1, 0]
nomi = np.cov(z, y)[1, 0]
return nomi/denom
print("操作変数法を用いて推定した時の因果効果", IV(A, y, Z))
操作変数法を用いて推定した時の因果効果 2.0858603407321765
うまくUの影響を受けずに平均因果効果を推定してあげることができました!
終わりに
IV法を用いると、交絡変数Uが観測できなくとも、AのYへの平均因果効果が推定できることがわかりました。
しかし2点注意しないといけないことがあります。
- 除外制約はデータからは立証できない!
残念ながら、実際にZが上記で説明したDAGのような状況下で生成された変数なのかどうかを確かめる術はありません。(Uが観測できないため)
実際に研究で利用する際は、ドメイン知識などを駆使・自然実験的な状況下でランダムに生成された変数などを利用して、上記のDAGのような状況が起きていることを説得する必要があります。 - AとZの相関が弱いと推定量の分散が大きくなる。(Weak instruments problem)
実際に上記の設定で$Cov(A, Z)$の値だけを動かして、推定量がどう推移するかを検証してみたところ、
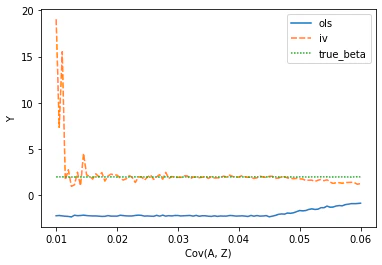
あまりに$Cov(A, Z)$が小さすぎると、IV法による推定値が真の値から大きくかけ離れた推定値になってしまうことが確認できます。
以上が、操作変数法に関する簡単な導入、シミュレーションデータを使った説明でした。
計量経済学のテキストを読むと必ず出てくる推定方法なので、是非勉強してみてください!
関連資料
また、TokyoRにて@mns_econさんがIV法を紹介されていたので、こちらも合わせて紹介致します。
-
この資料によると正確には不偏推定量ではないそうです。こちら私の理解不足でした。あくまで一致推定量であるとのことです。$\frac{Cov(Z, Y)}{Cov(Z, A)}= \frac{Cov(Z, 2A + 6U + \epsilon)}{Cov(Z, A)}= 2 + \frac{Cov(Z, U)}{Cov(Z, A)}$の$\frac{Cov(Z, U)}{Cov(Z, A)}$の部分が、漸近的に0に収束すると言うお話でした。ちょっと不偏性と一致性の理解不足な気がしているのでまた復習します。 ↩
-
グラフは山口先生のRIETI discussion paper から参照致しました。https://www.rieti.go.jp/jp/publications/dp/19j003.pdf ↩
-
実際には、上記の推定量はさらに各個人でAのYへの因果効果が同質的であると言う仮定が必要になります。 ↩