はじめに
アンサンブル学習は、複数の機械学習モデルを組み合わせることで性能の高い予測値を獲得する手法です。基本的に精度向上が望めるのでこの手法を使うのは一般的です。アンサンブルでは多様性が重要になるので得意分野の異なるモデルを組み合わせたり、似たようなモデルでもハイパーパラメータや特徴量を変えたりします。バギング、ブースティング、スタッキングなどの手法がありますが、まずは基本となる提出ファイル結果の多数決でアンサンブルを実施します。
多数決によるアンサンブル
これまで作成したランダムフォレストと2種類のLightGBMによる提出ファイルを利用します。それぞれスコアは0.79186, 0.77751, 0.76315です。
- submission_rf_0.79186.csv
- submission_lightgbm_0.77751.csv
- submission_lightgbm_0.76315.csv
LightGBMのベースラインモデルでは0.77033を記録していますが、間違えてLightGBMのスコア0.76315を使ってしまいました。
次に、類似していないもの同士でアンサンブルするために相関係数が低い結果を選択していきます。今回使う結果は3つですが選択肢が多いに越したことはありません。
import pandas as pd
import numpy as np
import os
# RandomForestの予測結果
rf = pd.read_csv("/kaggle/input/titanic-submit-files/submission_rf_0.79186.csv")
# LightGBMの予測結果
lightgbm = pd.read_csv("../input/titanic-submit-files/submission_lightgbm_0.77751.csv")
base_lightgbm = pd.read_csv("../input/titanic-submit-files/submission_lightgbm_0.76315.csv")
df = pd.DataFrame({"rf":rf["Survived"],
"lightgbm":lightgbm["Survived"],
"base_lightgbm":base_lightgbm["Survived"]})
# 相関行列
df.corr()
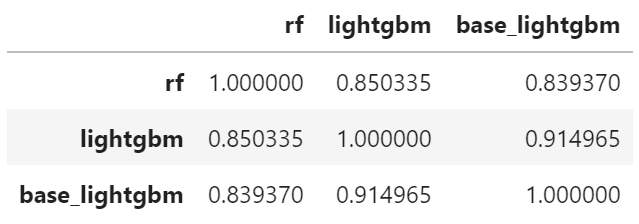
0.95を超えないことが1つの基準になるようです。クリアしているのですべてをアンサンブルに採用します。
多数決で予測値を決定します。3ファイルの予測値部分を合計し、合計が2以上の場合は全体としての予測値を1とします。
# 予測値の多数決
sum_pred = rf["Survived"] + lightgbm["Survived"] + base_lightgbm["Survived"]
pred = np.where(sum_pred >= 2, 1, 0)
ensemble = pd.DataFrame({"PassengerId": rf["PassengerId"], "Survived":pred})
ensemble.to_csv("ensembele_rf_lgbm_lgbm.csv", index=False)
最終的なアンサンブルの結果は0.77990となったので、ランダムフォレスト単体より劣る結果となってしまいました。原因と対策をまとめます。
今後の課題
- 決定木系モデルのみを使用したので多様性に欠けた
- モデルを大量に作成して選択肢を増やす
- 予測値の相関係数が低い(r<0.9)結果を選抜する
- 0.76315のスコアを出した単体LightGBMの精度が低い
- 予測クラスではなく予測確率を使うことで丸め込まれたデータより多くの情報量を活用する