ご覧の皆様、初めまして
今年の9月に株式会社アドベンチャーに入社した松本と申します。
主にサービスのインフラを担当しています。
この記事を書いているのが11月中旬なので、まだ試用期間という事になります。
さて、弊社では「スカイチケット」という航空券の販売代行を行なっています。
まだ知らない方は、「スカイチケット」や「格安航空券」でググって下さい。
後に続くエンジニアの方達は、きっとガチ目の記事を書くと思います。
私もインフラエンジニアとして ピークタイムで●●UUを処理するインフラの話 をしたいのですが、まだ社歴が浅い私がドヤれる事は何も無いので、今回は表題の話を書きたいと思います。
(ポエムと言われないよう、記事中盤にpython3.7でスクレイピングのコードを載せておきます)
なぜアドベントカレンダーを起案したのか?
きっかけは以下のツイートでした。

BtoCのサービスなので、SNS上には良い意見、悪い意見がありますが、
「会社の地名度が低すぎやろ・・・」 という残念な気持ちと同時に「そうや!アドベントカレンダーの企業枠で参加して社名をバンバン出してみよう!!」 という気持ちが混じり、開発部内で起案しました。
STEP1: マネージャー層への提案
まず最初に、社内でアドベントカレンダーを実施したいと言う事を偉い人達に伝えなければなりません。
部長にアドベントカレンダーを行いたい旨を直談判し、「次の開発定例で議題に入れるから話して見なよ」との快諾を頂きました。
同時に、各チームのリーダーにも事前に話を持っていきます。
いわゆる、ロビー活動ですね。
後は開発定例で、
- 情報を整理しアウトプットする事で、知識の深掘りと定着ができる
- 会社の地名度を上げる事による様々なプラス効果
などを適当にいい感じに説明し、参加者全員からの納得を得ました。
STEP2: 参加者の募集
次は、もっとも重要な参加者の募集フェーズです。
日本人の国民性か最初は「様子見」がかなり多いです。
気にはなる・・・
誰々さんが参加するなら自分も・・・
こんな意見はどの会社でも出ると思います。
現在の参加状況を、わざわざQiitaにアクセスして確認して貰う事は、あまり効果的ではありません。
時間が無いから参加状況を見ていない、と言い訳を容認する事にもなりますので、Adventカレンダーの参加状況をスクレイピングし、全員が参加しているchatworkのグループに報告するスクリプトを作成しました。
# !/bin/env python3.7
import os
from datetime import datetime, timedelta
import urllib.request
from bs4 import BeautifulSoup
import json
import requests
calendar_url = 'https://qiita.com/advent-calendar/2018/adventure'
schedule_file = 'schedule_file'
def get_schedule(calendar_url):
response = urllib.request.urlopen(calendar_url).read()
soup = BeautifulSoup(response,'lxml')
result = {}
result['title'] =soup.title.string
result['day'] = soup.findAll('div', class_='adventCalendarItem_date')
result['user'] = soup.findAll('img', class_='adventCalendarCalendar_authorIcon')
result['comment'] = soup.findAll('div', class_='adventCalendarItem_comment')
l = {}
for (day, user, commit) in zip(result['day'],result['user'],result['comment']):
day = datetime.strptime(day.string ,'%m / %d')
day_str = datetime.strftime(day, '%m/%d')
l[day_str] = user.get('alt'),commit.string
diff_file = '/tmp/advent_diff.tmp'
if not os.path.exists(diff_file):
with open(diff_file,"w") as diff :
diff.write(json.dumps(l, ensure_ascii=False)+'\n')
else :
with open(diff_file,"r") as diff :
yst_data = json.load(diff)
start = datetime.strptime('2018/12/01', '%Y/%m/%d').date()
message_list = []
for i in range(0,25) :
day = (start + timedelta(i)).strftime('%m/%d')
if yst_data.get(day) and l.get(day):
message_list.append(day + " " + " ".join(l[day]))
elif not yst_data.get(day) and l.get(day):
message_list.append(day + " " + " ".join(l[day]) + ' NEW(cracker)')
else:
message_list.append(day + " " +'空いてるよ')
# chatworkに送信
title = '2018年度のアドベントカレンダーです!\nみんなで盛り上げましょう;)\nhttps://qiita.com/advent-calendar/2018/adventure'
message = '\n'.join(message_list)
payload = {}
headers = {'X-ChatWorkToken': 'xxxxxxxxxxxxx'}
url = 'https://api.chatwork.com/v2/rooms/xxxxxxxx/messages'
payload = {'body': f'{title}[info]{message}[/info]'}
r = requests.post(url, headers=headers, data=payload)
with open(diff_file,"w") as diff :
diff.write(json.dumps(l, ensure_ascii=False)+'\n')
if __name__ == '__main__':
get_schedule(calendar_url)
これを実行すると以下のようにchatworkにメッセージが送信されるのでcronで回します。

STEP3: ランキングをつけてみる
これは完璧に蛇足ですが、せっかくみんなで記事を書くのでランキングをつけてみる事にしました。
アドベントカレンダーのいいね数でのバトルです!
簡易的な集計なので、同数の場合の順位とかは気にしていません。
# !/bin/env python3.7
import os
from datetime import datetime, timedelta
import urllib.request
from bs4 import BeautifulSoup
import json
import requests
calendar_url = 'https://qiita.com/advent-calendar/2018/adventure'
schedule_file = 'schedule_file'
def get_iine_count(item_url):
response = urllib.request.urlopen(item_url).read()
soup = BeautifulSoup(response,'lxml')
like = int(soup.find('a', class_='it-Actions_likeCount').string)
return like
def get_schedule(calendar_url):
response = urllib.request.urlopen(calendar_url).read()
soup = BeautifulSoup(response,'lxml')
result = {}
result['title'] =soup.title.string
result['day'] = soup.findAll('div', class_='adventCalendarItem_date')
result['user'] = soup.findAll('img', class_='adventCalendarCalendar_authorIcon')
result['item'] = soup.findAll('div', class_='adventCalendarItem_entry')
dict = {}
for (day, user, item) in zip(result['day'],result['user'],result['item']):
# 日付に全角「/」が入っているので、半角に直す
day = datetime.strptime(day.string ,'%m / %d')
day_str = datetime.strftime(day, '%m/%d')
# qiitaの記事からいいね数を取得する
item_url = item.a.get("href")
like = get_iine_count(item_url)
# いいね数 ユーザー名 記事名を配列として辞書に入れる
if like != 0 :
dict[day_str] = [like ,day_str, user.get('alt'), item.string]
# 順位(いいね数での降順)
list = sorted(dict.values(),reverse=True)
# ランキング上位10件を洗い出してメッセージを作成
# TOPxxを変更する場合は、[:10]の値を変える
if len(list) >= 5 :
message_list = []
count = 1
for i in list[:10] :
if count <= 3 :
point = (str(i[0]) + "いいね")
message = (str(count) + "位 " + point + " " + " ".join(i[1:]) + "[hr]")
message_list.append(message)
count += 1
else :
point = (str(i[0]) + "いいね")
message = (str(count) + "位 " + point + " " + " ".join(i[1:]))
message_list.append(message)
count += 1
## chatworkに送信
title = 'アドベントカレンダーのランキングTOP10です!\nあなたの記事は上位に入っているかな?っているかな;)\nhttps://qiita.com/advent-calendar/2018/adventure'
message = '\n'.join(message_list)
payload = {}
headers = {'X-ChatWorkToken': 'xxxxxxxxx'}
url = 'https://api.chatwork.com/v2/rooms/xxxxxxxx/messages'
payload = {'body': f'{title}[info]\n{message}\n[/info]'}
r = requests.post(url, headers=headers, data=payload)
if __name__ == '__main__':
get_schedule(calendar_url)
実行すると、以下のようにchatworkに通知されます。
(以前に勤めていた会社のアドベントカレンダーを集計した画像です)
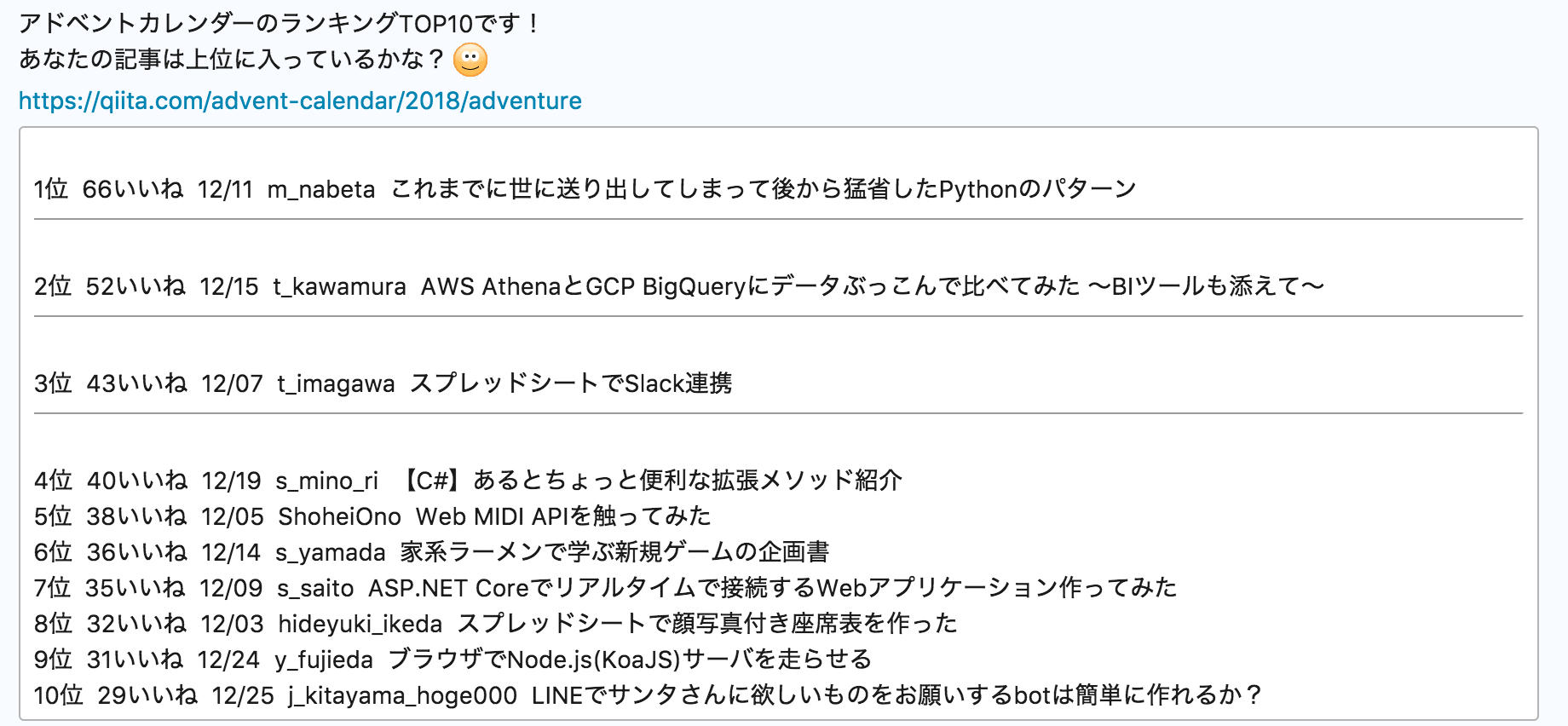
これで、投稿者のモチベーションがちょっとでも上がれば良いなと思っています。
最後に
アドベントカレンダーを推進して感じましたが、アドベントカレンダーに限らずアウトプットを行いたく無い理由はアバウトなものが多く、最初は「書くことが無い」と言っていた人も、何度か話を行うことで「じゃあ、やってみるわ」となります。
簡単に私が受けた質問と回答をまとめておきます。
-
書くことが無い(私のレベルでは・・・)
- エンジニアは日々勉強する必要がある。レベルは読み手によって変わるので、あなたが新しく知った事は、「すでに誰かが経験した事」かも知れないが、「これから誰かの為になる可能性」もある。
- 文字に起こすということは、新しく習得した知識をより深く理解する必要があるので、アウトプットを行う事は自分の為にもなる。
- コメントで指摘されると、さらに自分の能力がプラスされる
-
書けない(時間的に)
- アウトプットする事が一番大事。
-
最近Qiitaは炎上してるじゃん?
- 炎上しているのは、「自分はこう考える!異論は認めない!」系の俺様記事
- それが無いように、社内で簡単な検閲は行ってから公開する
また、個人的にも後に続くエンジニアメンバーがどのような記事を書くのか、非常に楽しみです。