よく見かけるRepositoryパターンのアンチパターンの紹介と対策です。
Repositoryパターンとは
Repositoryパターンとは永続化を隠蔽するためのデザインパターンで、DAO(DataAccessObject)パターンに似ていますが、より高い抽象度でエンティティの操作から永続化ストレージを完全に隠蔽します。
例えばDBコネクションやストレージのパス等はReposiotoryのインターフェースからは隠蔽され、Repositoryのユーザは永続化ストレージが何であるか(例えばMySQLやRedis等)を意識することなく保存や検索の操作を行うことができるようになります。
これによりRepositoryを利用するロジックは業務的な操作に集中できるようになる他、データベースの移行等の永続化層の変更が発生した際にロジックへの影響を切り離すことができるようになります。
// 例) ユーザの永続化、参照を行うためのリポジトリ(実装は割愛)
public interface UserRepository {
User findBy(Long userId);
User store(User user);
}
// Repositoryの利用クラス
public class FooService {
private UserRepository userRepository;
public FooService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void registerUser(String userName) {
// Repositoryを利用してUserを保存するが、永続化の方法には左右されない
User user = new User(userName);
userRepository.store(user);
}
}
とても便利で使いやすいパターンですが、現場では色々な使われ方をしていて変なバグの温床になっていることも多かったので、今回はこれらをアンチパターンとしてまとめてみました。
Repository実装時にありがちなアンチパターン
機能やロールでRepositoryを分ける
一つのエンティティに対して、機能や役割に応じて複数のRepositoryを作ってしまうパターンです。
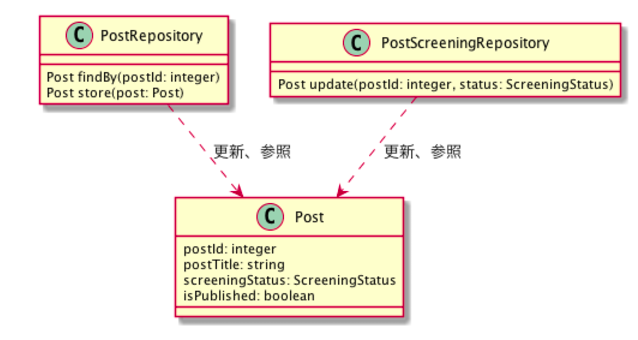
例えば審査制で記事が投稿できるシステムで、一般ユーザによる記事の更新や参照の操作はPostRepository、記事の審査や公開に関わる操作はPostScreeningRepositoryというように機能単位でRepositoryを分けてしまいます。
問題点
このパターンでは、そもそもぱっと見でどのRepositoryを使えばいいのかが分からない上、ビジネス上の振る舞いに関するロジックが複数のリポジトリに散らばってしまい、データやロジックの整合性が取れなくなる恐れがあります。
例えば審査がOKでないと公開できないビジネス要件があるシステムで、記事の審査OK/NG時の状態変更処理をPostScreeningRepositoryに実装したのに、うっかり他の人がPostScreeningRepositoryを経由せずに無理やり公開状態を更新してPostRepositoryで保存してしまった場合、ビジネス要件上正しく無いデータができてしまいます。
対策
状態更新に関わる振る舞いはEntityやServiceに実装します。
また、状態の操作に関する処理は可能な限り可視性を制御して無理やり変更が出来ないようにします。
Repositoryは単なるストレージへのアクセス手段として利用し、複雑なビジネス上のロジックを持たないように心がけましょう。
今回のケースであれば、例えばPostScreeningServiceのみを他のパッケージに公開し、PostScreeningServiceの審査メソッドを通してしか公開ステータスを変更できないようにしたり、Postエンティティに公開メソッドを用意し、審査NGのときに公開しようとすると例外を投げるようにする等すれば、ビジネスルールを安全に強制することができます。
子テーブルに対して沢山Repositoryを作る
よく見かけるパターンです。
例えば「ユーザ」というエンティティが「住所」「連絡先」という要素を持っており、それらがユーザの子テーブルで表現されている時に、UserRepository、ContactRepository、AddressRepositoryのようなリポジトリを作成してしまうケースです。
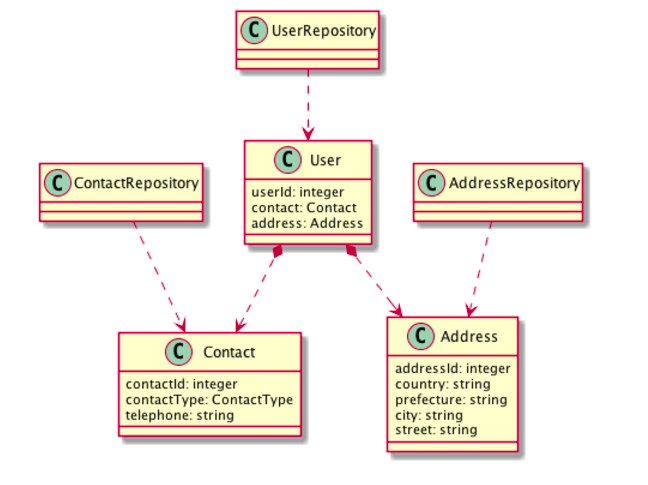
問題点
例えば、以下のようなビジネス要件の場合を考えます。
- 「連絡先」の種類には「自宅」「携帯電話」があり、「ユーザ」は最低限どちらか一つの連絡先を持つ必要がある。
ContactRepositoryを作ってしまうと、上記のビジネス要件のチェックロジックをRepositoryが持たなければいけなくなったり、チェック処理を迂回して連絡先の保存・削除が行える不具合を作り込む原因になってしまいます。
対策
これを防ぐためにはDDDの集約というテクニックが非常に役立ちます。
集約は、あるEntityと関連するオブジェクトを一つの塊として捉え、集約の更新は必ず集約ルートを経由してしか行えないようにすることで、集約内でのデータ整合性を担保するテクニックです。
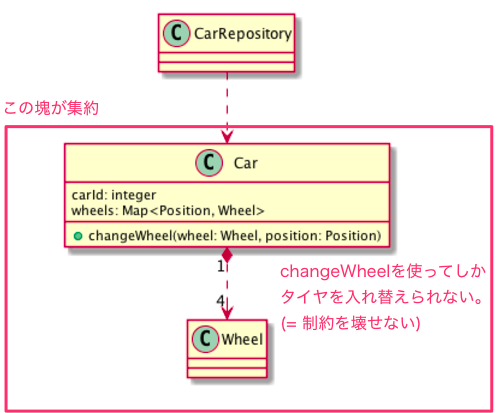
例えば「車」「タイヤ」というエンティティがあり、車には必ずタイヤが4つなければいけないという制約がある場合、車を集約ルートとしてこれらを一つの集約として扱います。
タイヤを交換したいときは集約ルートである車のchangeWheelメソッドを使うことで、車に必ず4つのタイヤが付いていることを保証します。
集約ルートの中のオブジェクトを直接更新することはできず、利用側は必ず車リポジトリを介して車の集約を取得し、changeWheelを使ってタイヤ交換を行い、再度リポジトリを使って更新された車の集約を永続化ストレージに保存します。
問題のケースでは、「ユーザ」を集約ルートとして「連絡先」「住所」を含む集約を定義し、ユーザを介して連絡先の更新を行うことでデータの整合性を担保することができます。
例えば住所だけ欲しい場合にも必ず集約を経由してデータを取得しますが、クエリが複雑だったりデータ量が多くなりすぎるような場合は次のパターンを参考にしてください。
複雑なクエリをRepositoryで頑張って発行する
これもよくやってしまいがちなパターンです。
大体どのORMでやっても酷いことになります。
問題点
よくあるのが以下のようなビジネス要件を満たそうとした場合です。
- 会員ステータスが「退会済み」ではなく、登録日が過去3ヶ月以内で、直近1ヶ月以内に10件以上の商品を購入したユーザ
恐らく、ユーザのIDをキーに購入履歴テーブルをジョインし、購入日で絞り込んだ件数をcountするクエリをORMで頑張って実現しようとするでしょう。
これらのクエリは大抵プログラム的にもメンテナンスしづらいものとなり、更にユーザ一覧画面などで複数件実行するとパフォーマンス上の問題を引き起こしたりします。
対策
シチュエーションや求められるパフォーマンスによっていくつかの解決案があります。
-
リポジトリを分割して愚直に複数回クエリを投げる
一つのリポジトリで頑張ろうとせず、ユーザリポジトリから「退会済み以外」「過去3ヶ月以内に登録」したユーザを取得し、それらのIDをキーに購入履歴リポジトリから「過去1ヶ月以内」に購入した件数を取得し、アプリケーションレイヤーでこれらの情報を結合します。
アクセスの少ないサービスであればこの方法でも事足りるでしょう。 -
CQS(Command Query Separation)を適用してクエリを切り出す
CQRSの話をするとややこしくなるのでここでは一旦CommandとQueryの分離のみの話に絞ります。
CQSというのはBertrand Meyerが提唱した原則で、すべてのメソッドは副作用を発生させる「Command」か、値を返す「Query」のどちらかに分類できるというものです。
集約に対する操作は必ずRepositoryを介して行うというお話をしましたが、これは変更(Command)操作を行うときの原則となります。
一方複雑なクエリが必要になるケースというのは大抵問い合わせ(Query)操作のときのみで、これらは主にアプリケーション固有の要求からくることが多いです。(このケースで言うと「ユーザの一覧画面に最近購入した商品数を表示したい」等)
そこで、このようなクエリはRepositoryに実装するのではなく、直接アプリケーションレイヤーのサービスからクエリビルダーを介して直接クエリを発行します。
jOOQやScalikeJDBCのようなタイプセーフなクエリビルダを使ってもよいですし、直接jdbcを使ったりMyBatisのようなSQLが書けるORMを使ってもかまいません。
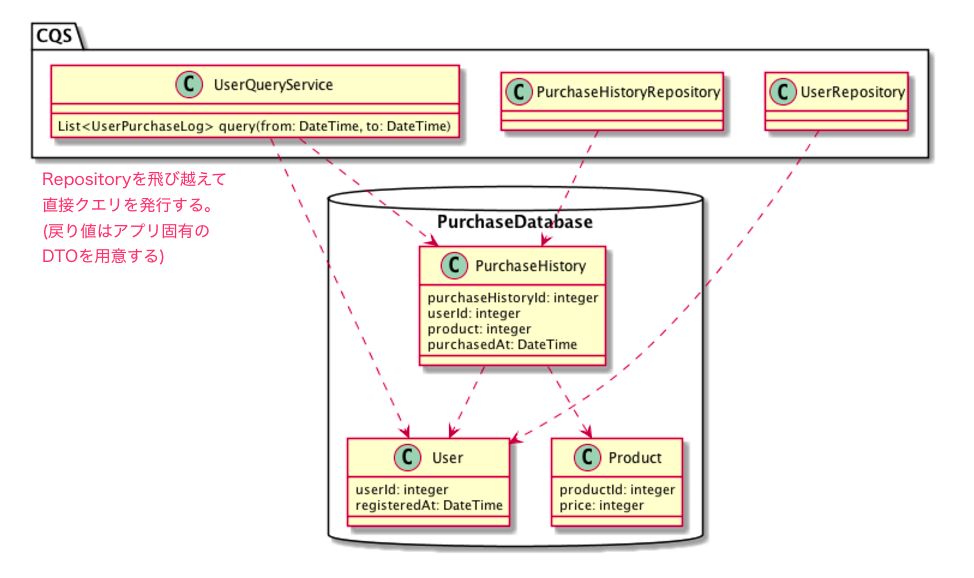
アプリ固有の複雑な処理はQueryService、エンティティの永続化や取得はRepositoryという風に責務を分離することで、不必要にRepositoryが複雑化することを避けることができます。
最後に
Repositoryは永続化層の抽象として非常に便利な概念ですが、使い方を間違うとすぐに複雑さをロジックに持ち込んでしまいます。
DDDの集約やCQSにはこれらを回避するための非常に有益なテクニックが詰まっているので、Repositoryパターンを使う際は是非併せて学ぶことをおすすめします。