この記事は全文検索エンジン「Elasticsearch」の入門チュートリアルです。
Elasticsearch とは
Elasticsearch は Elastic 社が開発しているオープンソースの全文検索エンジンです。
大量のドキュメントから目的の単語を含むドキュメントを高速に抽出することができます。
Elasticsearch では RESTful インターフェースを使って操作しますが、「Elasticsearch SQL」を使って SQL 文でクエリを記述することもできます。
Oracle や MySQL などのリレーショナルデータベースに慣れている人にとっては、最初はとっつきにくいと感じるかもしれません。
しかし、Elasticsearch の API はとてもシンプルなので、心配しなくても大丈夫です。
Elastic Stack とは
Elastic Stack は Elasticsearch 関連製品の総称です。
バージョン 2.x 以前は「ELK」と呼ばれていましたが、バージョン 5.0 からは名称を改め「Elastic Stack」となりました。
| 製品名 | 機能 |
|---|---|
| Elasticsearch | ドキュメントを保存・検索します。 |
| Kibana | データを可視化します。 |
| Logstash | データソースからデータを取り込み・変換します。 |
| Beats | データソースからデータを取り込みます。 |
| X-Pack | セキュリティ、モニタリング、ウォッチ、レポート、グラフの機能を拡張します。 |
※Logstash については、別記事「はじめての Logstash」を参照してください。
動作環境
- Mac OS X 10.14.6
- Elasticsearch 8.1.0
- Kibana 8.1.0
インストール
Mac のターミナルを開いて、必要なソフトウェアをインストールします。
Elasticsearch をダウンロードするのに wget コマンドを使用しますので、インストールしておきます。
$ brew install wget
Elasticsearch と日本語検索プラグイン「 kuromoji 」をインストールします。
バージョン 8.0 以降では M1 Mac に対応していますが、ダウンロード URL が分かれているのでご注意ください。
・Intel Mac 用のダウンロード URL
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.0-darwin-x86_64.tar.gz
・M1 Mac 用のダウンロード URL
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.0-darwin-aarch64.tar.gz
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.1.0-darwin-x86_64.tar.gz
$ tar -xzf elasticsearch-8.1.0-darwin-x86_64.tar.gz
$ cd elasticsearch-8.1.0
$ bin/elasticsearch-plugin install analysis-kuromoji
バージョン 8.0 以降では、デフォルトでセキュリティが有効になっていますが、このチュートリアルでは一時的に無効にします。
config/elasticsearch.yml を編集して、「xpack.security.enabled」に false を設定してください。
# Enable security features
xpack.security.enabled: false
Elasticsearch を起動します。
$ bin/elasticsearch
ブラウザを開いて、http://localhost:9200/ にアクセスしてみましょう。
以下の JSON が表示されれば、起動は成功しています。
"name" : "username.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qJnOX-ukSU-nX6hjUViLnA",
"version" : {
"number" : "8.1.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "3700f7679f7d95e36da0b43762189bab189bc53a",
"build_date" : "2022-03-03T14:20:00.690422633Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
もしエラー「ERR_CONNECTION_REFUSED」が表示される場合は、config/elasticsearch.yml を開いて、「xpack.security.enabled」に false が設定されているか確認してみてください。
続いて、Kibana をインストールします。
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.1.0-darwin-x86_64.tar.gz
tar -xzf kibana-8.1.0-darwin-x86_64.tar.gz
cd kibana-8.1.0-darwin-x86_64/
Kibana を起動します。
$ bin/kibana
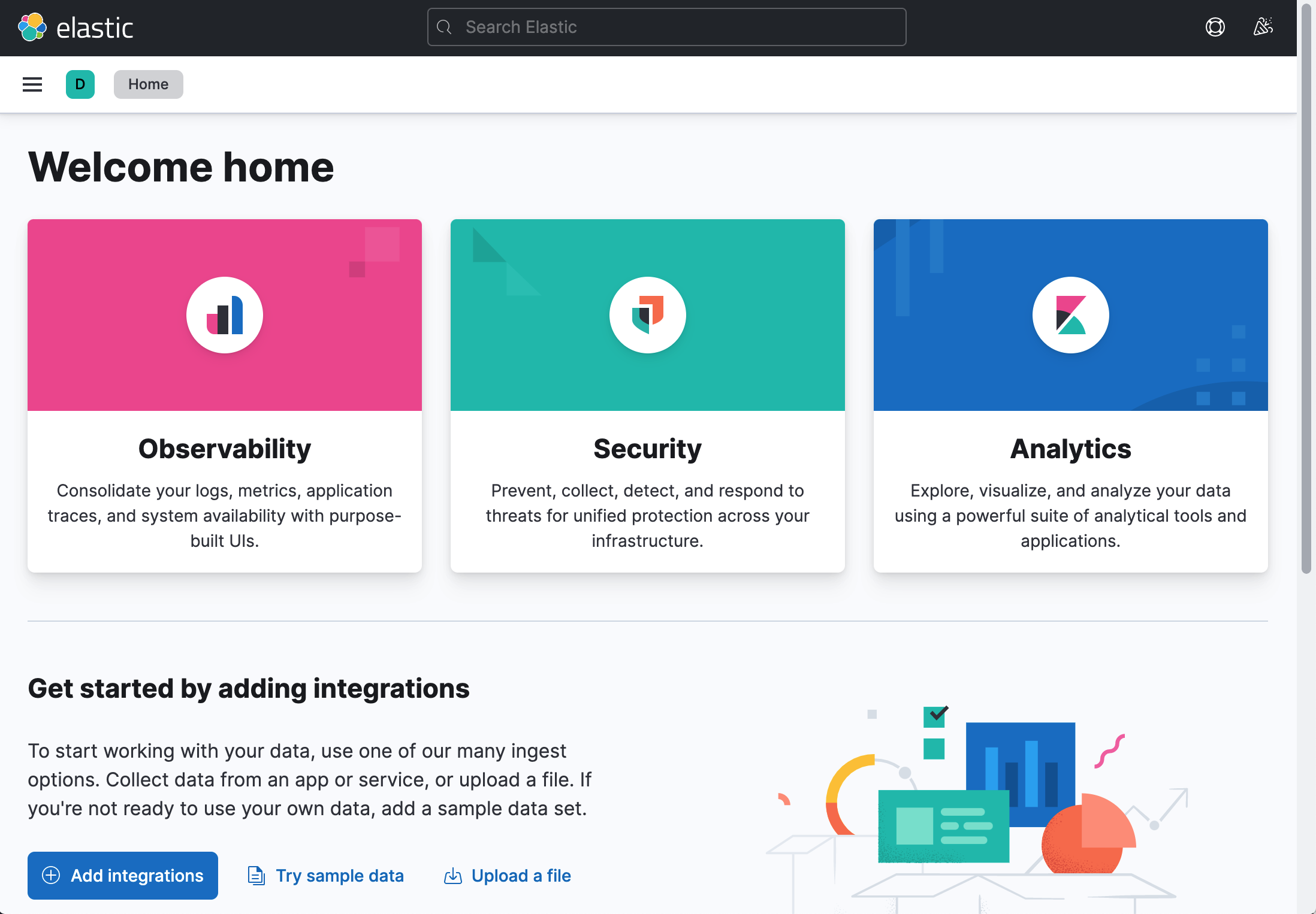
ブラウザを開いて、http://localhost:5601/ にアクセスしてみましょう。
以下のような画面が表示されれば、起動は成功しています。
チュートリアルをはじめる前に
この記事で使用しているコマンドは GitHub で公開していますので参考にしてください。
https://github.com/nskydiving/elasticsearch_examples
Elasticsearch は RESTful インターフェースで操作できますが、このチュートリアルでは Kibana の「Dev Tools」を使用します。
Kibana のメニューの中から「Dev Tools」を選択してください。
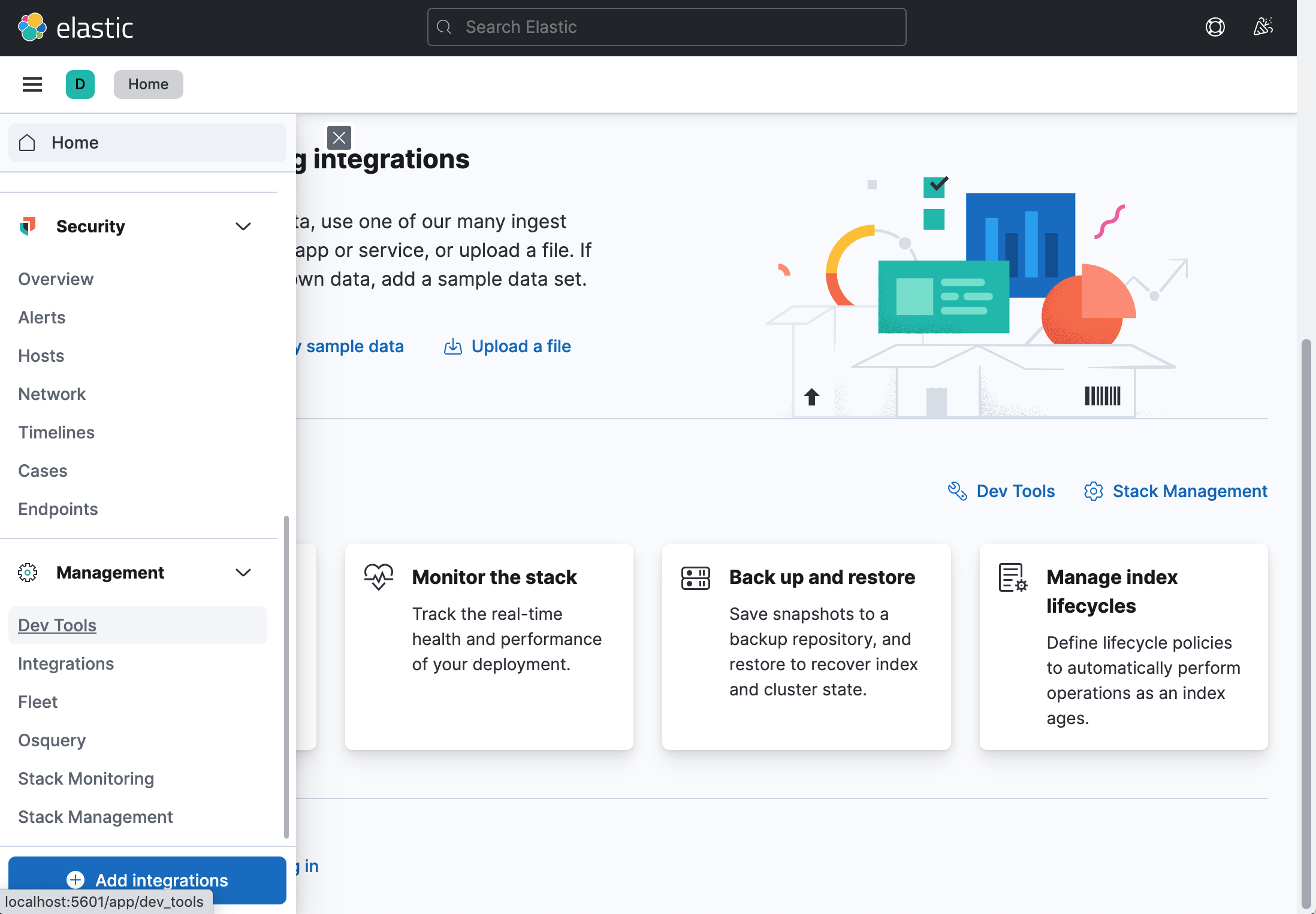
以下のような画面が表示されます。
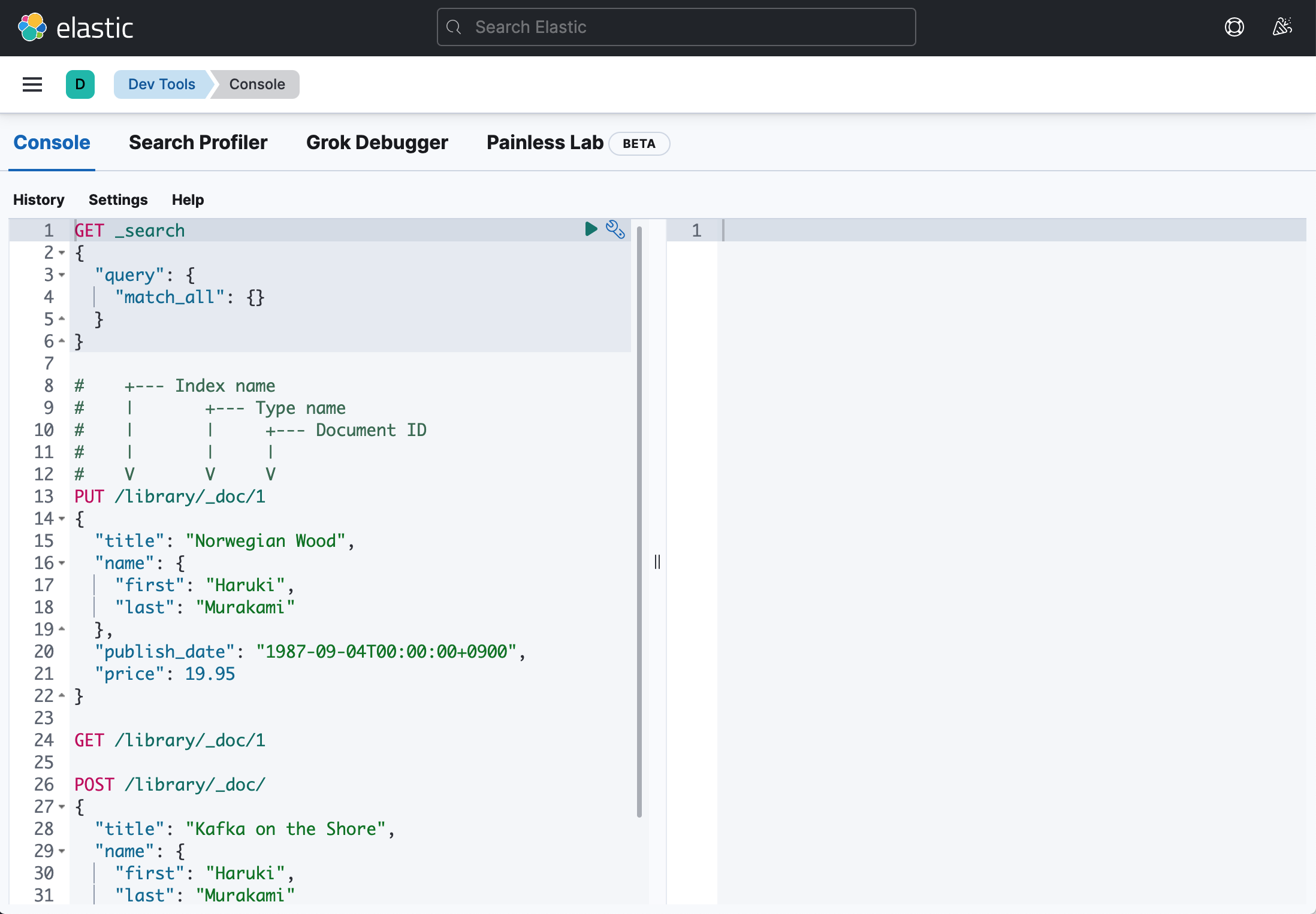
Console の左側エリアにコマンドを入力して実行ボタン(緑色の再生ボタン)をクリックすると、選択されたコマンドが実行され、右側エリアに実行結果が表示されます。
試しに以下のコマンドを実行してみましょう。
GET _search
{
"query": {
"match_all": {}
}
}
右側エリアに実行結果が表示されれば成功です。
※Mac 以外の環境の人は以下のリンクを参照してください。
https://www.elastic.co/jp/downloads/elasticsearch
https://www.elastic.co/jp/downloads/kibana
CRUDオペレーション(RESTful API)
Elasticsearch ではリレーショナルデータベースとは異なる用語を使用しますが、概ね以下のように理解しておけば良いでしょう。
| Elasticsearch | リレーショナルデータベース |
|---|---|
| Index | データベース |
| Type | テーブル |
| Document | レコード |
※バージョン 6.0 以降では、「Type」の指定が非推奨となり、タイプ名の代わりに「_doc」を指定するようになりました。
### ドキュメントを作成
ドキュメントを作成するには、PUT で「/インデックス/タイプ/ドキュメントID」にアクセスし、ドキュメントの中身を JSON で渡します。
コマンド
# +--- Index name
# | +--- Type name
# | | +--- Document ID
# | | |
# V V V
PUT /library/_doc/1
{
"title": "Norwegian Wood",
"name": {
"first": "Haruki",
"last": "Murakami"
},
"publish_date": "1987-09-04T00:00:00+0900",
"price": 19.95
}
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 15,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 22,
"_primary_term" : 1
}
### ドキュメントを取得
ドキュメントを取得するには、GET で「/インデックス/タイプ/ドキュメントID」にアクセスします。
コマンド
GET /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 15,
"_seq_no" : 22,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Norwegian Wood",
"name" : {
"first" : "Haruki",
"last" : "Murakami"
},
"publish_date" : "1987-09-04T00:00:00+0900",
"price" : 19.95
}
}
### ドキュメントIDを指定せずにドキュメントを作成
ドキュメントIDを指定せずにドキュメントを作成すると、自動的にドキュメントIDが割り当てられます。
自動的に割り当てられたドキュメントIDは実行結果で確認できます。
コマンド
POST /library/_doc/
{
"title": "Kafka on the Shore",
"name": {
"first": "Haruki",
"last": "Murakami"
},
"publish_date": "2002-09-12T00:00:00+0900",
"price": 19.95
}
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "q2aZVmoBFWFSqRl8nY0k",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 23,
"_primary_term" : 1
}
### 「ドキュメントIDを指定せずにドキュメントを作成」の確認
コマンド
# POST /library/_doc/ で取得した id を指定してください
GET /library/_doc/q2aZVmoBFWFSqRl8nY0k
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "q2aZVmoBFWFSqRl8nY0k",
"_version" : 1,
"_seq_no" : 23,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Kafka on the Shore",
"name" : {
"first" : "Haruki",
"last" : "Murakami"
},
"publish_date" : "2002-09-12T00:00:00+0900",
"price" : 19.95
}
}
### ドキュメントを上書き更新
ドキュメントを上書き更新するには、PUT で「/インデックス/タイプ/ドキュメントID」にアクセスします。
コマンド
PUT /library/_doc/1
{
"title": "Norwegian Wood",
"name": {
"first": "Haruki",
"last": "Murakami"
},
"publish_date": "1987-09-04T00:00:00+0900",
"price": 29.95
}
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 18,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 26,
"_primary_term" : 1
}
### 「ドキュメントを上書き更新」の確認
コマンド
GET /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 18,
"_seq_no" : 26,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Norwegian Wood",
"name" : {
"first" : "Haruki",
"last" : "Murakami"
},
"publish_date" : "1987-09-04T00:00:00+0900",
"price" : 29.95
}
}
### ドキュメントを部分的に更新
ドキュメントを部分的に更新するには、POST で「/インデックス/_update/ドキュメントID」にアクセスし、 JSON で "doc" クエリを指定します。
コマンド
POST /library/_update/1
{
"doc": {
"price": 10
}
}
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 19,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 27,
"_primary_term" : 1
}
### 「ドキュメントを部分的に更新」の確認
コマンド
GET /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 19,
"_seq_no" : 27,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Norwegian Wood",
"name" : {
"first" : "Haruki",
"last" : "Murakami"
},
"publish_date" : "1987-09-04T00:00:00+0900",
"price" : 10
}
}
### ドキュメントに項目を追加
コマンド
ドキュメントに項目を追加するには、POST で「/インデックス/_update/ドキュメントID」にアクセスし、JSON で "doc" クエリを指定します。
POST /library/_update/1
{
"doc": {
"price_jpy": 1800
}
}
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 20,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 28,
"_primary_term" : 1
}
### 「ドキュメントに項目を追加」の確認
コマンド
GET /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 20,
"_seq_no" : 28,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Norwegian Wood",
"name" : {
"first" : "Haruki",
"last" : "Murakami"
},
"publish_date" : "1987-09-04T00:00:00+0900",
"price" : 10,
"price_jpy" : 1800
}
}
### ドキュメントを削除
ドキュメントを削除するには、DELETE で「/インデックス/タイプ/ドキュメントID」にアクセスします。
コマンド
DELETE /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_version" : 21,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 29,
"_primary_term" : 1
}
### 「ドキュメントを削除」の確認
コマンド
GET /library/_doc/1
実行結果
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"found" : false
}
### インデックスを削除
インデックスを削除するには、DELETE で「/インデックス」にアクセスします。
コマンド
DELETE /library
実行結果
{
"acknowledged" : true
}
### 「インデックスを削除」の確認
コマンド
GET /libray/_doc/2
実行結果
{
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [libray]",
"resource.type" : "index_expression",
"resource.id" : "libray",
"index_uuid" : "_na_",
"index" : "libray"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [libray]",
"resource.type" : "index_expression",
"resource.id" : "libray",
"index_uuid" : "_na_",
"index" : "libray"
},
"status" : 404
}
ドキュメントの検索
インデックスに保存されたドキュメントを検索します。
下準備として、インデックスを一度削除して、テストデータのドキュメントを作成します。
複数のドキュメントを一気に作成するには、POST で「/インデックス/タイプ/_bulk」にアクセスします。
コマンド
DELETE /library
POST /library/_bulk
{"index": {"_id": 1}}
{"title": "The quick brown fox", "price": 5}
{"index": {"_id": 2}}
{"title": "The quick brown fox jumps over the lazy dog", "price": 15}
{"index": {"_id": 3}}
{"title": "The quick brown fox jumps over the quick dog", "price": 8}
{"index": {"_id": 4}}
{"title": "Brown fox and brown dog", "price": 2}
{"index": {"_id": 5}}
{"title": "Lazy dog", "price": 9}
### すべてのドキュメントを検索
すべてのドキュメントを検索するには、GET で「/インデックス/タイプ/_search」にアクセスします。
また、「/library/_search?size=3」のように size パラメータで検索件数を指定することもできます。
コマンド
GET /library/_search
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox",
"price" : 5
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"title" : "Brown fox and brown dog",
"price" : 2
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "Lazy dog",
"price" : 9
}
}
]
}
}
### 指定した単語を含むドキュメントを検索
指定した単語を含むドキュメントを検索するには、GET で「/インデックス/_search」にアクセスし、JSON で "match" クエリを指定します。
ここでは "title" に "fox" を含むドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"match": {
"title": "fox"
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.32951736,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.32951736,
"_source" : {
"title" : "The quick brown fox",
"price" : 5
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.30488566,
"_source" : {
"title" : "Brown fox and brown dog",
"price" : 2
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.23470737,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.23470737,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
}
]
}
}
### OR条件でドキュメントを検索
OR条件でドキュメントを検索するには、GET で「/インデックス/_search」にアクセスし、JSON で "match" クエリを指定します。
ここでは "title" に "quick" または "dog" を含むドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"match": {
"title": "quick dog"
}
}
}
検索結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.8762741,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.8762741,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6744513,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6173784,
"_source" : {
"title" : "The quick brown fox",
"price" : 5
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.3930218,
"_source" : {
"title" : "Lazy dog",
"price" : 9
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.30488566,
"_source" : {
"title" : "Brown fox and brown dog",
"price" : 2
}
}
]
}
}
### 空白を含む単語を含むドキュメントを検索
空白を含む単語を含むドキュメントを検索するには、GET で「/インデックス/_serach」にアクセスし、JSON で 「match_phrase」 クエリを指定します。
ここでは "title" に "quick dog" を含むドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"match_phrase": {
"title": "quick dog"
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.67445135,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.67445135,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
}
]
}
}
### ドキュメント検索のスコアを表示
ドキュメントを検索するときに、指定された単語との関連性がスコアとして計算されます。
コマンドに explain パラメータを指定することで、どのようにスコアが計算されたか確認することができます。
コマンド
GET /library/_search?explain
{
"query": {
"match": {
"title": "quick"
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.64156675,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.64156675,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6173784,
"_source" : {
"title" : "The quick brown fox",
"price" : 5
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.43974394,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
}
]
}
}
### AND条件でドキュメントを検索
AND条件でドキュメントを検索するには、GET で「/インデックス/_search」にアクセスし、JSON で "bool" クエリを指定します。
ここでは、"title" に "quick" と "lazy dog" の両方を含むドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "quick"
}
},
{
"match_phrase": {
"title": "lazy dog"
}
}
]
}
}
}
実行結果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3887084,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.3887084,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
}
]
}
}
### ドキュメント検索のスコアに重み付け
ドキュメント検索のスコアに重み付けするには、GET で「/インデックス/_search」にアクセスし、JSON で "boost" クエリを指定します。
ここでは、"title" に "quick dog" を含むドキュメントのスコアを半分にしています。
コマンド
GET /library/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "quick dog",
"boost": 0.5
}
}
},
{
"match_phrase": {
"title": {
"query": "lazy dog"
}
}
}
]
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.5890584,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.5890584,
"_source" : {
"title" : "Lazy dog",
"price" : 9
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9489645,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.33722568,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
}
]
}
}
### ドキュメント検索結果をハイライト表示
ドキュメント検索結果をハイライト表示するには、GET で「/インデックス/_search」にアクセスし、JSON で "highlight" クエリを指定します。
検索でヒットした文字列が em タグで囲われて出力されます。
コマンド
GET /library/_search
{
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "quick dog",
"boost": 0.5
}
}
},
{
"match_phrase": {
"title": {
"query": "lazy dog"
}
}
}
]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
実行結果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.5890584,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.5890584,
"_source" : {
"title" : "Lazy dog",
"price" : 9
},
"highlight" : {
"title" : [
"<em>Lazy</em> <em>dog</em>"
]
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9489645,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
},
"highlight" : {
"title" : [
"The quick brown fox jumps over the <em>lazy</em> <em>dog</em>"
]
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.33722568,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
},
"highlight" : {
"title" : [
"The quick brown fox jumps over the <em>quick</em> <em>dog</em>"
]
}
}
]
}
}
### フィルタリングしてドキュメントを検索
フィルタリングしてドキュメントを検索するには、GET で「/インデックス/_search」にアクセスし、JSON で "filter" クエリを指定します。
ここでは、"price" が 5 〜 10 のドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"bool": {
"filter": {
"range": {
"price": {
"gte": 5,
"lte": 10
}
}
}
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"title" : "The quick brown fox",
"price" : 5
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.0,
"_source" : {
"title" : "The quick brown fox jumps over the quick dog",
"price" : 8
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.0,
"_source" : {
"title" : "Lazy dog",
"price" : 9
}
}
]
}
}
### 他のクエリとフィルタリングを組み合わせてドキュメントを検索
他のクエリとフィルタリングを組み合わせてドキュメントを検索するには、GET で「/インデックス/_search」にアクセスし、JSON で 他のクエリと "filter" クエリを合わせて指定します。
ここでは、"title" に "lazy dog" を含み、"price" が 5 以上のドキュメントを検索しています。
コマンド
GET /library/_search
{
"query": {
"bool": {
"must": [{
"match_phrase": {
"title": "lazy dog"
}
}],
"filter": {
"range": {
"price": {
"gte": 5
}
}
}
}
}
}
実行結果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.5890584,
"hits" : [
{
"_index" : "library",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.5890584,
"_source" : {
"title" : "Lazy dog",
"price" : 9
}
},
{
"_index" : "library",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9489645,
"_source" : {
"title" : "The quick brown fox jumps over the lazy dog",
"price" : 15
}
}
]
}
}
Mapping
Elasticsearch はスキーマレスのデータベースですが、あらかじめマッピングを設定しておくこともできます。
下準備として、インデックスを一度削除して、テストデータのドキュメントを作成します。
コマンド
DELETE /library
POST /library/_bulk
{"index": {"_id": 1}}
{"title": "The quick brown fox", "price": 5}
{"index": {"_id": 2}}
{"title": "The quick brown fox jumps over the lazy dog", "price": 15}
{"index": {"_id": 3}}
{"title": "The quick brown fox jumps over the quick dog", "price": 8}
{"index": {"_id": 4}}
{"title": "Brown fox and brown dog", "price": 2}
{"index": {"_id": 5}}
{"title": "Lazy dog", "price": 9}
### マッピングを取得
コマンド
GET /library/_mapping
実行結果
{
"library" : {
"mappings" : {
"properties" : {
"price" : {
"type" : "long"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
### マッピングを追加
新しいマッピング "my_new_field" を追加します。
コマンド
PUT /library/_mapping
{
"properties": {
"my_new_field": {
"type": "text"
}
}
}
実行結果
{
"acknowledged" : true
}
### 「マッピングを追加」の確認
コマンド
GET /library/_mapping
実行結果
{
"library" : {
"mappings" : {
"properties" : {
"my_new_field" : {
"type" : "text"
},
"price" : {
"type" : "long"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
### アナライザを設定してマッピングを追加
マッピングに設定するアナライザは "analyzer" クエリを指定します。
コマンド
PUT /library/_mapping
{
"properties": {
"english_field": {
"type": "text",
"analyzer": "english"
}
}
}
実行結果
{
"acknowledged" : true
}
### 「アナライザを設定してマッピングを追加」の確認
コマンド
GET /library/_mapping
実行結果
{
"library" : {
"mappings" : {
"properties" : {
"english_field" : {
"type" : "text",
"analyzer" : "english"
},
"my_new_field" : {
"type" : "text"
},
"price" : {
"type" : "long"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
### マッピングは変更することはできない
一度追加したマッピングは変更することはできないため、以下のコマンドはエラーとなります。
コマンド
PUT /library/_mapping
{
"properties": {
"english_field": {
"type": "double"
}
}
}
実行結果
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [english_field] of different type, current_type [text], merged_type [double]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [english_field] of different type, current_type [text], merged_type [double]"
},
"status": 400
}
### 型の違いによる検索結果への影響
「/log」へ id が「234571」と「1392.223」の2つのドキュメントを追加し、検索条件に「id が 1392 以上」を指定して検索を実行します。
「234571」と「1392.223」の両方が検索にヒットすることが期待されますが、実際には「234571」しかヒットしません。
コマンド
POST /log/_doc
{
"id": 234571
}
POST /log/_doc
{
"id": 1392.223
}
GET /log/_search
{
"query": {
"bool": {
"filter": {
"range": {
"id": {
"gt": 1392
}
}
}
}
}
}
実行結果
# POST /log/_doc
{
"_index" : "log",
"_type" : "_doc",
"_id" : "r2axVmoBFWFSqRl86Y1N",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
# POST /log/_doc
{
"_index" : "log",
"_type" : "_doc",
"_id" : "sGayVmoBFWFSqRl8S414",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
# GET /log/_search
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "log",
"_type" : "_doc",
"_id" : "r2axVmoBFWFSqRl86Y1N",
"_score" : 0.0,
"_source" : {
"id" : 234571
}
}
]
}
}
### 「型の違いによる検索結果への影響」の確認
マッピングを取得すると "id" の型は long 型です。
また、すべての "log" インデックスを検索すると、"id" の型が合わない「1392.223」のドキュメントも追加されていることが分かります。
コマンド
GET /log/_mapping
GET /log/_search
実行結果
# GET /log/_mapping
{
"log" : {
"mappings" : {
"properties" : {
"id" : {
"type" : "long"
}
}
}
}
}
# GET /log/_search
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "log",
"_type" : "_doc",
"_id" : "r2axVmoBFWFSqRl86Y1N",
"_score" : 1.0,
"_source" : {
"id" : 234571
}
},
{
"_index" : "log",
"_type" : "_doc",
"_id" : "sGayVmoBFWFSqRl8S414",
"_score" : 1.0,
"_source" : {
"id" : 1392.223
}
}
]
}
}
Analysis
Elasticsearch がどのように文字列を分析しているのか確認することができます。
下準備として、インデックスを一度削除して、テストデータのドキュメントを作成します。
コマンド
DELETE /library
POST /library/_bulk
{"index": {"_id": 1}}
{"title": "The quick brown fox", "price": 5}
{"index": {"_id": 2}}
{"title": "The quick brown fox jumps over the lazy dog", "price": 15}
{"index": {"_id": 3}}
{"title": "The quick brown fox jumps over the quick dog", "price": 8}
{"index": {"_id": 4}}
{"title": "Brown fox and brown dog", "price": 2}
{"index": {"_id": 5}}
{"title": "Lazy dog", "price": 9}
### 文字列の分析結果を表示
"Brown fox brown dog" の分析結果を表示します。
"Brown" "fox" "brown" "dog" の 4 つの単語に分解されていることが分かります。
コマンド
GET /library/_analyze
{
"tokenizer": "standard",
"text": "Brown fox brown dog"
}
実行結果
{
"tokens" : [
{
"token" : "Brown",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "fox",
"start_offset" : 6,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "dog",
"start_offset" : 16,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
### フィルターを指定して文字列の分析結果を表示
"filter" クエリに "lowercase" を指定すると、文字列を小文字に変換して分析します。
最初の "Brown" が "brown" として分析されていることが分かります。
コマンド
GET /library/_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Brown fox brown dog"
}
実行結果
{
"tokens" : [
{
"token" : "brown",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "fox",
"start_offset" : 6,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "dog",
"start_offset" : 16,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
### 複数のフィルターを指定して文字列の分析結果を表示
"filter" クエリに "lowercase" と "unique" を指定すると、文字列を小文字に変換し、さらに重複する単語を削除して分析します。
"Brown" が小文字に変換され、重複した 2 つ目の "brown" は削除されていることが分かります。
コマンド
GET /library/_analyze
{
"tokenizer": "standard",
"filter": ["lowercase","unique"],
"text": "Brown brown brown fox brown dog"
}
実行結果
{
"tokens" : [
{
"token" : "brown",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "fox",
"start_offset" : 18,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "dog",
"start_offset" : 28,
"end_offset" : 31,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
### トークナイザの違いによる分析結果を表示
トークナイザに "standard" を指定した場合と、"letter" を指定した場合で、分析結果を比較します。
"quick.brown_fox" の部分の分析結果が異なることが分かります。
コマンド
GET /library/_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "THE quick.brown_FOx Jumped! $19.95 @ 3.0"
}
GET /library/_analyze
{
"tokenizer": "letter",
"filter": ["lowercase"],
"text": "THE quick.brown_FOx Jumped! $19.95 @ 3.0"
}
実行結果
# GET /library/_analyze
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "quick.brown_fox",
"start_offset" : 4,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "jumped",
"start_offset" : 20,
"end_offset" : 26,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "19.95",
"start_offset" : 29,
"end_offset" : 34,
"type" : "<NUM>",
"position" : 3
},
{
"token" : "3.0",
"start_offset" : 37,
"end_offset" : 40,
"type" : "<NUM>",
"position" : 4
}
]
}
# GET /library/_analyze
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "fox",
"start_offset" : 16,
"end_offset" : 19,
"type" : "word",
"position" : 3
},
{
"token" : "jumped",
"start_offset" : 20,
"end_offset" : 26,
"type" : "word",
"position" : 4
}
]
}
### 日本語を含むドキュメントの分析結果を表示
Elasticsearch は標準で日本語に対応したトークナイザがインストールされないため 、kuromoji プラグインをインストールしておく必要があります。
コマンド
GET /library/_analyze
{
"tokenizer": "kuromoji_tokenizer",
"text": "記者が汽車で帰社した"
}
実行結果
{
"tokens" : [
{
"token" : "記者",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "が",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "汽車",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 2
},
{
"token" : "で",
"start_offset" : 5,
"end_offset" : 6,
"type" : "word",
"position" : 3
},
{
"token" : "帰社",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 4
},
{
"token" : "し",
"start_offset" : 8,
"end_offset" : 9,
"type" : "word",
"position" : 5
},
{
"token" : "た",
"start_offset" : 9,
"end_offset" : 10,
"type" : "word",
"position" : 6
}
]
}