Shapとは
Shap値は予測した値に対して、「それぞれの特徴変数がその予想にどのような影響を与えたか」を算出するものです。これにより、ある特徴変数の値の増減が与える影響を可視化することができます。以下にデフォルトで用意されているボストンの価格予測データセットを用いて、Pythonでの構築コードと可視化したグラフを紹介します。
Shapの概要図

モデルの構築
XGBoostを使用します。
import xgboost
import shap
X,y = shap.datasets.boston()
X_display,y_display = shap.datasets.boston(display=True)
特徴変数の説明は以下の通り。
| 特徴変数 | 説明 |
|---|---|
| CRIM | 人口 1 人当たりの犯罪発生数 |
| ZN | 25,000 平方フィート以上の住居区画の占める割合 |
| INDUS | 小売業以外の商業が占める面積の割合 |
| CHAS | チャールズ川によるダミー変数 (1: 川の周辺, 0: それ以外) |
| NOX | NOxの濃度 |
| RM | 住居の平均部屋数 |
| AGE | 1940年より前に建てられた物件の割合 |
| DIS | 5つのボストン市の雇用施設からの距離 (重み付け済) |
| RAD | 環状高速道路へのアクセスしやすさ |
| TAX | $10,000ドルあたりの不動産税率の総計 |
| PTRATIO | 町毎の児童と教師の比率 |
| B | 町毎の黒人 (Bk) の比率を次の式で表したもの。1000(Bk – 0.63)^2 |
| LSTAT | 給与の低い職業に従事する人口の割合 (%) |
XGBboostでトレーニング
model = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
この時点で、特徴変数を用いて価格を予測するモデルが作成され、適切な「重み」が計算されている状態です。ここからモデルを用いてShap値を計算していきます。
Shapによる特徴変数が目的変数に与えた影響説明
# jupyter notebookにコードを表示させるためにjsをロード
shap.initjs()
explainer = shap.TreeExplainer(model=model, feature_dependence='tree_path_dependent', model_output='margin')
TreeExplainerは勾配ブースティング(XGBoost, LightGBM, CatBoostなど)で作成したモデルを読み込み、Shap値を導くためのインスタンスです。
feature_dependence:
SHAP値は条件付き期待値に依存しています。そのため、特徴変数の貢献度は特徴同士で「相関させるか独立させるか」で変わります。これには2つの設定値が存在します。
tree_path_dependent(デフォルト):
特徴同士を相関させるアプローチです。ツリー内のパスに沿って特徴の依存関係を考慮します。
independent:
特徴同士を独立させるアプローチです。
model_output:
モデルのどのように出力されるかの設定です。主に3つの設定があります。
margin(デフォルト):
生データのshape値を出力します。
probability:
確率空間に変換されたshape値を出力します。
log_loss:
Shap値が対数損失まで合計されるように、モデル損失関数の対数eを説明します。
※ 現在、probabilityおよびlog_lossオプションはfeature_dependence="independent"の場合にのみサポートされています。
特徴データからShap値を計算し出力する
shap_values = explainer.shap_values(X=X)
以下からは、Shape値に関する説明とShape値に対する特徴変数の貢献度を可視化するメソッドを紹介していきます。
特徴変数の貢献度を可視化
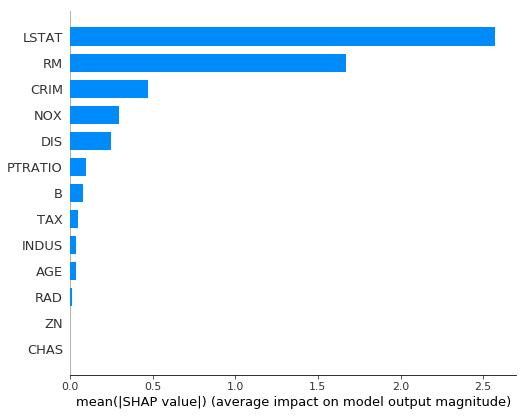
summary_plot:
SHAP要約プロットを作成します。特徴値によって色付けされています。
まずは、目的変数に対する各特徴変数の寄与度を図式化します。
住宅価格にはLSTAT(給与の低い職業に従事する人口の割合)とRM(住居の平均部屋数)の寄与度が高いことがわかります。
shap.summary_plot(shap_values, X, plot_type="bar")
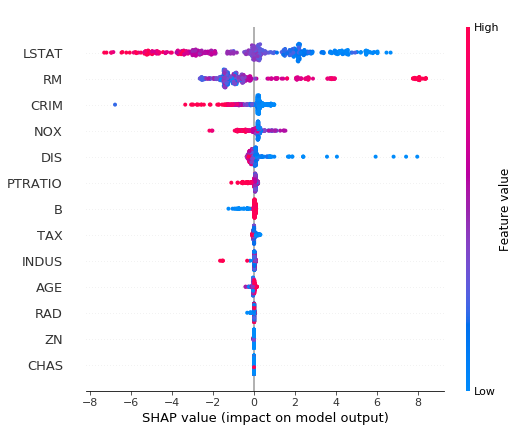
次に相関関係を確認します。
横軸が目的変数の値で縦軸が特徴変数の貢献度の高さです。赤が正の値を、青が負の値となります。例えば、LSTATは目的変数が大きく(右側)なるほど青い分布となり、目的変数が小さく(左側)なるほど赤い分布となります。つまり、目的変数とLSTATは負の相関があることを示します。
shap.summary_plot(shap_values, X)
force_plot:
force layoutを用いて与えられたShap値と特徴変数の寄与度を視覚化します。同時に、Shap値がどのような計算を行っているかもわかります。

次に全データを用いてグラフを作成してみます。
shap.force_plot(base_value=explainer.expected_value, shap_values=shap_values, features=X)


2つのグラフをみると、以下のことがわかります。
・LSTAT(給与の低い職業に従事する人口の割合)が高くなるほど、住宅価格が低くなる。
・RM(住居の平均部屋数)が高くなるほど、住宅価格が高くなる。
dependence_plot:
インタラクション機能によって色付けされた、SHAP依存関係プロットを作成します。 横軸に特徴値を縦軸に同じ特徴のShap値をプロットします。Shap値が特徴変数にどう影響するかを表します。
shap.dependence_plot(ind="RM", shap_values=shap_values, features=X)
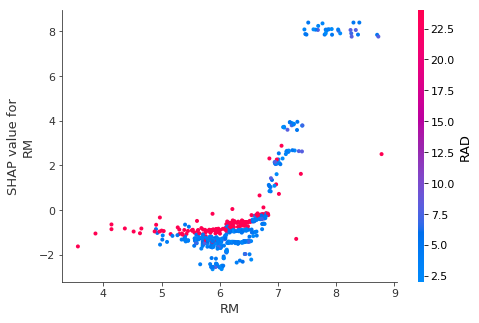
特徴変数のShap値と値に相関関係がみられるほど、目的変数への影響度も高いです。
最後に
Shapを使用することで機械学習モデルにおける目的変数と特徴変数の相関関係を把握することができたと思います。厄介だった、顧客へのモデル説明もこのツールである程度乗り越えられるのではないでしょうか。
※ 本記事は個人の見解であり、所属する団体の見解ではございません。私の理解に相違などあればコメントいただければ幸いです。
※ 参考にさせていただいた記事、サイトは以下となります。
https://speakerdeck.com/line_developers/machine-learning-and-interpretability
https://linus-mk.hatenablog.com/entry/2018/10/28/230410
https://shap.readthedocs.io/en/latest/