これは Enchant の開発者である Vinay Sahni さんが書いた記事「Best Practices for Designing a Pragmatic RESTful API」1を、ご本人の許可を得て翻訳したものです。
RESTful な WebAPI を設計しようとすると、細かなところで長考したり議論したりすると思います。また、他の API に倣ってやってはみたものの、本当にそれでいいのか、どうしてそうしているのか分からない、何てことも少なくはないと思います。
この記事では、そのようなハマリどころについて Vinay さんなりの答えを提示し、簡潔かつ明快に解説してくれています。
今後 WebAPI を設計される方は、是非参考にしてみてください。
なお、誤訳がありましたら編集リクエストを頂けると幸いです。
まえがき
アプリケーションの開発が進むにつれて、その WebAPI を公開する機会に出くわすかもしれません。ただ、いくらデータ設計がひと段落していたとしても、一度インターフェイスを公開してしまうと、そこからの変更はなかなか自由に出来ず、苦しめられることとなります。
今の時代、ネットで調べれば API 設計に関する情報はいくらでも手に入ります。しかし、幅広く受け入れられているスタンダードかつ万能な設計は存在せず、多くのことに悩むこととなります。フォーマットはどれにするとか、認証はどうやるとか、バージョンはつけるのかとか...
Enchant(Zendesk に変わるカスタマーサポートツール)の設計を通して、私はこれらの問いに対して実践的な答えを探ってきました。Enchant API を使いやすく、受け入れやすく、また、Enchant の機能を十分に活かせるものにしたかったのです。
API 設計の勘所
ネット上で目にする API 設計に関する議論は、少しアカデミックすぎたり、個々人の曖昧な主張が入り混じっていて、とても現実世界で通用するものではありません。私はこの記事を通して、実用的かつモダンな API 設計について説明しようと思います。誤解を防いだり、理解を早めていただくために、まずは私が思う API の勘所をお伝えします。
- できる限り Web の標準に従うこと
- 開発者に親切な作りにすること。また、ブラウザのアドレスバーから叩けるようにすること
- シンプルで一貫性を持たせ、直感的かつ心地よく使えるようにすること
- Enchant(本体のサービス)が提供する機能を十分に活用できるものにすること
- 様々な要件とのバランスを保ちつつ、効率的に開発ができるようにすること
API は開発者のための UI です。他の UI と同じように、UX にもとことんこだわりましょう!
RESTful な URL にしよう
WebAPI の分野で最も市民権を獲得している原則は REST です。REST は、Roy Fielding がネットワークソフトウェア設計に関する論文で言及したのが始まりです。
REST のキーとなる概念は、論理的に分割されたリソースを HTTP メソッド(GET, POST, PUT, PATCH, DELETE)で操作する、ということです。
では、「リソースを論理的に分割する」とはどういうことでしょうか。これは、API 利用者が客観的に見て意味がわかる名詞(動詞じゃありません!)を使って分割する、ということです。内部実装で利用しているモデルがそのままいい具合にリソースに対応するかもしれませんが、これは必ずしも一対一の関係でなくても構いません。重要なのは、内部実装につられて妙なデータ構造を表に晒すべからず、ということです。(Enchant API でもところどころ良くないところはあるのですが...)
リソースが定義できたら、次はそれらに対してどんなアクションが必要で、また WebAPI 上でどのように表現されるかを考えます。REST の原則に従うと、HTTP メソッドを使った CRUD 操作は以下のように定義されます。
-
GET /tickets- チケットのリストを取得する -
GET /tickets/12- 指定したチケットの情報を取得する -
POST /tickets- 新しいチケットを作成する -
PUT /tickets/12- チケット #12 を更新する -
PATCH /tickets/12- チケット #12 を部分的に更新する -
DELETE /tickets/12- チケット #12 を削除する
REST の素晴らしい点は、HTTP メソッドを活用することで /tickets という単独のエンドポイントに対して主要な機能を持たせられることです。命名規則など意識する必要ありませんし、URL 構造は明白かつ整然としたものとなります。これは素晴らしい!
では、エンドポイントの名前は単数形と複数形のどちらを使うのが適切でしょうか。KISS の原則に従えば、答えは「一貫して複数形を使う」です。単数のインスタンスを複数形で表すことに違和感を覚えるかもしれませんが、person/people, goose/geese といった奇妙な単複変換を扱わなくてよくなれば、API 利用者も快適になりますし、API 提供者が実装するのも簡単です(モダンなフレームワークであれば /tickets と /tickets/12 を同一のコントローラで扱えますので)。
関連データについてはどうしましょう。もしその関連データが、あるリソースに付随してのみ存在するのであれば、REST によって綺麗に解決されます。以下の例をみてください。Enchant のチケットにはたくさんのメッセージが紐付いているのですが、これらのメッセージは、以下のように表現されるのが自然でしょう。
-
GET /tickets/12/messages- チケット #12 に紐づくメッセージのリストを取得する -
GET /tickets/12/messages/5- チケット #12 に紐づくメッセージ #5 を取得する -
POST /tickets/12/messages- チケット #12 に新しいメッセージを作成する -
PUT /tickets/12/messages/5- チケット #12 のメッセージ #5 を更新する -
PATCH /tickets/12/messages/5- チケット #12 のメッセージ #5 を部分的に更新する -
DELETE /tickets/12/messages/5- チケット #12 のメッセージ #5 を削除する
これとは逆に、関連データがリソースから独立して存在する場合は、リソースのアウトプットに関連データの ID を含めるのが良いです。API 利用者はその内容を見て、関連データのエンドポイントにアクセスすることとなります。
とはいえ、親データと関連データが大体一緒に使われるようであれば、レスポンスに関連データを埋め込めるようにしておいて、何度もリクエストする手間を省いてもいいかもしれません。
最後に、CRUD の概念にフィットしないようなアクションについてはどうしましょうか。
これは難易度の高い問題ではありますが、いくつかのアプローチがあります。
1つは、アクションをリソースの項目の1つとして扱う方法で、これはアクションがパラメータを取らない場合に有効です。例えば、何かをアクティベートするようなアクションであれば、対象となる boolean 項目をサブリソースとして扱って、そこに対して PATCH リクエストを投げると考えます。GitHub API の例を見てみましょう。Gist にスターをつけるアクションを PUT /gists/:id/star としていて、スターを解除するアクションを DELETE /gists/:id/star としています。
一方で、REST の構造にマッチさせられないアクションもあると思います。例えば、複数のリソースを横断的に検索するようなアクションについては、特定リソースのエンドポイントに紐付けるのは、なんとも無理やりな感じがします。このような場合は、/search というエンドポイントを作ることで解決します。ちょっとルール違反な気もしますが、API 利用者から見ておかしくなく、混乱がないようにドキュメントにしっかりと書かれていれば問題ないのです。
いつ何時も、SSL 通信を使おう
通信については、何がなんでも SSL で暗号化しましょう。今の時代、WebAPI は図書館やコーヒーショップ、空港といった様々な場所からアクセスされます。これらのアクセスポイントは必ずしもセキュアではありません。暗号化しないで通信していると、簡単になりすましがされてしまいます。
SSL 通信を使う別のメリットとして、暗号化を保障しておくことで認証処理が簡潔にできることがあります。アクセストークンを使うことで、リクエストごとの認証処理を省略できるのです。
ひとつ気をつけたいのは、API の URL に非 SSL でのアクセスがあるケースです。こうしたアクセスを、対応する SSL の API にリダイレクトしてはいけません。代わりにきちんとしたエラーを投げてください。不適切な設定が行われたクライアントが、暗号化されていないエンドポイントにリクエストを送信して、それが実際の暗号化されているエンドポイントへと暗黙的にリダイレクトされるなんてことは最も避けたい事態でしょう。
かっこいい仕様書を作ろう
API の価値はそのドキュメントの良さが表すと言っても過言ではありません。ドキュメントは誰もが簡単に閲覧できるようにしておく必要があります。ほとんどの開発者は、API の利用を検討する際にまずはドキュメントをチェックしますが、それが PDF だったり、閲覧に何かしらの登録が必要だったりすると、彼らにリーチするのはとても難しくなってしまいます。
また、ドキュメントにはリクエストとそのレスポンスの例を記載しておきましょう。できれば、リクエストはブラウザやターミナルに簡単にペーストできるようにしておくと良いです。GitHub や Stripe の API 仕様書はこのあたりがとてもよくできています。
一度 API を公開したら、利用者への予告なしに下位互換性のない変更を入れることはできなくなります。ドキュメントには、そういった仕様廃止のスケジュールや、API の更新も掲載しましょう。更新情報については、ブログかメーリングリストでも配信すると良いですね(両方だと最高です!)。
バージョンは URL に含めよう
API は必ずバージョン管理しましょう。バージョン管理することで開発速度を速められますし、廃止された仕様でのリクエストを弾いたり、メジャーアップデートがあるような場合に、移行期間として過去バージョンと共存させることもできます。
API のバージョンに関して議論されることといえば、それを URL に含めるべきか、リクエストヘッダに含めるべきか、ということです。学術的に言えば、ヘッダに含めるのがいいのかもしれません。ただ、ブラウザからバージョンをしたリクエストをすることを考えると、URL に含めるのが妥当といえます(私が冒頭で述べたことを思い出してください)。
バージョン管理について、私は Stripe のアプローチがとても好きです。URL では API のメジャーバージョン(v1)が指定できて、リクエストヘッダでは日付ベースのマイナーバージョンが指定できるのです。これにより、メジャーバージョンで API の安定した動作を担保させつつ、マイナーバージョンで出力項目やエンドポイントの変更といった細かな調整ができるのです。
どんなに頑張っても、API を永らく安定させることは難しく、変更は避けられません。大切なのは、いかにしての変更を管理するかです。何かを廃止したい時は、移行までの期間を十分に確保して利用者に周知すれば、ほとんどの場合は受け入れられるのです。
フィルタ・ソート・検索はリクエストパラメータでやろう
ベースとなる URL はできるだけシンプルにしておくのが良いです。フィルタやソート、検索といった機能はリクエストパラメータで制御するのが良いです(もっとも、これは単一リソースに対するものに限ります)。これらについて、細かく見ていきましょう。
フィルタリング
各フィールドに対して、フィルタリングをするためのパラメータを用意しましょう。例えば、/tickets でチケットのリストを取得する際に、state が open のものだけに絞りたいことがあると思います。このような要望は GET /tickets?state=open のようにして実現させましょう。リソースの項目である state をそのまま、フィルタするためのリクエストパラメータとするのです。
ソート
並び順の指定については、 sort パラメータを用意して処理するようにしましょう。複雑なソートにも応えられるように、ソート対象とする項目をカンマ区切りで指定して、かつ、昇順・降順をネガポジで指定するようにします。いくつか例を挙げてみます。
GET /tickets?sort=-priority - チケットのリストを priority の降順で取得する
GET /tickets?sort=-priority,created_at - チケットのリストを priority の降順、かつ created_at の昇順で取得する
検索
フィルタクエリでは事足りず、全文検索が必要になることもあると思います。おそらく、ElasticSearch や他の Lucene ベースの検索エンジンを使うことになると思いますが、特定リソースに対して投げるクエリには、q パラメータを使いましょう。検索クエリはそのまま全文検索エンジンに伝えられ、API のアウトプットは普段と変わらない形式となります。
以上を組み合わせてみると、以下のような感じでリクエストパラメータが構築できます。
GET /tickets?sort=-updated_at - 最近更新されたチケットを取得する
GET /tickets?state=closed&sort=-updated_at - 最近クローズされたチケットを取得する
GET /tickets?q=return&state=open&sort=-priority,created_at - オープン状態で優先度の高いチケットのうち、「return」という単語を含むものを返す
よく使うクエリのエイリアス
API の UX をより良くするために、よく使われる検索クエリは REST のパスにしてしまうことを考えましょう。例えば、「最近クローズされたチケット」を取得するクエリは、以下のような URL にまとめることができます。
GET /tickets/recently_closed
レスポンスのフィールドを絞れるようにしよう
API 利用者は、常にリソースの全項目を必要としているわけではありません。レスポンスのフィールドを絞る手段を用意することは、API 利用者のネットワーク負荷を下げ、通信速度を向上させることに貢献します。
そのために、出力したいフィールドをカンマ区切りで指定できるパラメータを用意しましょう。例えば、以下のリクエストではオープン状態のチケットを更新日付順で並べて表示するのに必要な、最低限の情報のみを返します。
GET /tickets?fields=id,subject,customer_name,updated_at&state=open&sort=-updated_at
作成・更新の後は変更後の情報をフルで返そう
created_at や updated_at といった項目は、こちらが明示的に指定するものではなく、作成・
更新の際にサーバが自動で挿入するものです。API 利用者が作成・更新後のリソース情報を取得するためにもう一度 API を叩くのは大変なので、POST, PATCH, PUT リクエストのレスポンスには変更後のリソースの情報を含めるようにしましょう。
なお、POST で新しくリソースを作成した際には、ステータスコード 201 を返し、Location ヘッダに作成されたリソースへの URL を含めるのが良いです。
HATEOAS を採用するのは待とう
(API のレスポンスを踏まえて)次に進むべきリンクを API 利用者が構築するか、はたまた API が提供するかについては、賛否両論の様々な意見が飛び交っています。REST を拡張する形で提案された HATEOAS という概念では、エンドポイント同士のインタラクションは API のレスポンスに含めるべきだとされています。
確かに、いわゆる Web サイトはこの HATEOAS の原則通りに動いているように見えます。例えば、私たちはウェブサイトのトップページにアクセスしたら、そこに表示されているリンクを押しますよね。ただ、私はこれを API の世界で展開するには時期尚早だと思います。ウェブサイトではどのような遷移がされるかどうかの判断をアプリ自体ができます。一方、API の場合は次にどのようなリクエストが来るかどうかはその API を使ったアプリに依存するため、API レベルで行うことは難しいのです。もちろん、どうにか工夫をしてその判断を遅延させることはできるかもしれませんが、そこまでして得られるメリットはさほどないと思います。このことから、私は HATEOAS はとても前途有望ではあるものの、現時点ではまだ使うには早すぎると思うのです。これが標準化され、メリットが最大限に生かされるようになるためには、まだまだ議論が必要です。
現時点では API 利用者がドキュメントをちゃんと読むことを前提としつつ、リソースの ID からリンクを構築してもらうのが良いでといえるでしょう。ちなみに、ID にこだわるのにはいくつかの理由があります。まず、ネットワーク上で介されるデータ量が小さくなりますし、API 利用者が保存すべきデータも最小化されるからです(ID を含む URL を保存するのとはわけが違います)。
また、前章で URL はバージョン管理されるべきと言いましたが、これを考慮しても API 利用者には ID
のみを保存してもらう方が良いのです。ID を使えばバージョンに依存しない安定したアクセスができますが、URL ごと保存してしまうとそうもいかないからです。
可能な限り JSON で返そう
API レスポンス形式の分野において、XML の時代は終わりました。XML は冗長ですし、読むのもパースするのも大変です。また、XML のデータの持ち方はほとんどのプログラミング言語が扱うモデルと互換性がありませんし、得意としている拡張性についても、内部モデルを表現する上ではほとんど活用することはありません。
私がとやかく理由を述べるよりも、Youtube や Twitter, Box といった大御所の API が XML を廃止し始めているのを見れば、明白だと思います。
ちなみに、Google トレンドで「XML API」と「JSON API」を比較してみるとこんな感じです。
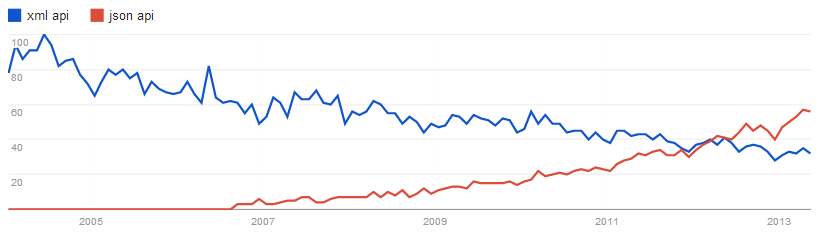
とはいえ、たくさんのエンタープライズの利用者を抱えていると、XML をサポートしなければいけない状況になることも無きにしも非ずです。そうなった時に、おそらく以下の疑問を抱くと思います
「レスポンス形式の指定はヘッダでやるの?それとも URL でやるの?」
例のごとくブラウザでの叩きやすさを考慮して、URL でやりましょう。URL の最後に .json や .xml といった拡張子を追加するのが良いと思います。
フィールドの命名規則を考えよう
もし API のレスポンス形式がデフォルトで JSON であれば、フィールドの名前は JavaScript の命名規則に従うのが「正しい」やり方でしょう。つまり、キャメルケースです。ただ、色々なプログラミング言語でクライアントライブラリを作るのであれば、各言語での命名規則に従うのが良いです。Java や C# であればキャメルケースで、Python や Ruby であればスネークケースといった感じです。
ちなみに、私はずっと、キャメルケースよりスネークケースの方が読みやすいと思っていました。この曖昧な感覚を証明する手段がなかったのですが、近年のアイトラッキングシステムを使った研究により、どうやらスネークケースの方が 20% 読みやすいということがわかったそうです。つまり、スネークケースを使った方が、API の利便性が上がったり、ドキュメントの読みやすさが向上したりするかもしれません。
ほとんどの JSON API ではスネークケースが採用されています。私が思うに、これは各々が利用している JSON シリアライズライブラリがその言語の命名規則に依存しているからです。もしかしたら、命名規則の違いに対応出来る JSON シリアライズライブラリを使った方がいいのかもしれません。
JSON はデフォルトで整形しよう
圧縮された状態の JSON をブラウザ上で見るのは、決して気持ちの良いものではありません。?pretty=true のようなパラメータで PrettyPrint することができるかもしれませんが、それであれば初めから PrettyPrint してある方が良いでしょう。gzip 圧縮してしまえば、余分な空白を転送するコストなど取るに足らないものとなります。
いくつかのユースケースを考えてみましょう。API 利用者がデバッグのために取得したデータを出力したとして、もしそれがそのまま読めたら?または、API 利用者が生成されたリクエスト URL をおもむろにブラウザに投げたとして、それがそのまま読めたら?些細なことではありますが、これらは API の UX を高める大切なポイントです。
とはいえ、余分なデータが転送されることは気になりますよね。
ホンモノのデータを使って検証してみましょう。GitHub API のレスポンスを使いますが、この API はデフォルトで PrettyPrint されているので、比較のためにちょっと加工します。
$ curl https://api.github.com/users/veesahni > with-whitespace.txt
$ ruby -r json -e 'puts JSON JSON.parse(STDIN.read)' < with-whitespace.txt > without-whitespace.txt
$ gzip -c with-whitespace.txt > with-whitespace.txt.gz
$ gzip -c without-whitespace.txt > without-whitespace.txt.gz
この結果、それぞれのファイルサイズは以下のようになりました。
-
without-whitespace.txt- 1252 bytes -
with-whitespace.txt- 1369 bytes -
without-whitespace.txt.gz- 496 bytes -
with-whitespace.txt.gz- 509 bytes
この例では、gzip 圧縮をしない状態だと空白の有無で 8.5% の差が生じ、gzip 圧縮をした状態だと 2.6% の差が生じることがわかります。一方で、gzip 圧縮自体が 60% のサイズ削減をすることもわかります。つまり、PrettyPrint により増加するサイズは数字で見ても比較的少なく、「gzip 圧縮かつ PrettyPrint」の状態で返すのがベストであることがわかります!
さらに付け加えると、Twitter の Streaming API では gzip 圧縮をしたことで 80% のサイズダウンに成功した例もありますし、StackExchange の API は圧縮した状態でしか返さない仕様となっています。
要素はラップせずに返そう
多くの API が、以下のように要素をラップした状態で返しています。
{
"data" : {
"id" : 123,
"name" : "John"
}
}
なぜラップをするのかというと、こうしておくと付加的なメタデータやページングのデータを埋め込みやすいからです。HTTP クライアントの中には、レスポンスヘッダの参照がしづらいものもあるかもしれませんし、JSONP のリクエストではヘッダを参照する術がありません。しかしながら、世の中のスタンダードは CORS になりつつありますし、RFC 5988 では Link というレスポンスヘッダの仕様が提案されています。つまり、要素をラップする必要はなくなりつつあるわけです。
将来的には、デフォルトの状態ではラップをしていなく、特殊なケースに対応するときのみラップするようになるでしょう。
では、ラップが必要な特殊ケースに出くわした時はどうしましょう。
先にも述べましたが、それが必要なのは JSONP を使ってクロスドメイン制約を解決するときと、HTTP クライアントがどうしてもレスポンスヘッダを扱えないときです。
JSONP のリクエストは、callback や jsonp といったリクエストパラメータと一緒に来ます。API はこのパラメータを見つけ次第、ラップモードへとスイッチが切り替わります。どんな状態であれステータスコード 200 を返し、本来のステータスコードはラップした内側に埋め込みます。さらに、従来レスポンスヘッダに入れていたデータも内包させるのです。
callback_function({
status_code: 200,
next_page: "https://..",
response: {
... actual JSON response body ...
}
})
HTTP クライアントが対応していないときも同様で、?envelop=true のような何かしらのパラメータをトリガーにラップモードを発動させれば良いです(もちろん、この場合 JSONP コールバックは不要です)。
追加・更新時のリクエストボディには JSON を使おう
ここまでの内容で、あなたはきっと全ての API アウトプットが JSON 形式であることには賛同してくれるでしょう。では、JSON をインプットに使うというのはどうでしょうか。
多くの API では、リクエストパラメータ同様、リクエストボディも key, value 形式のデータが詰められてやりとりされています。これはとてもシンプルですし、幅広く使われていて有効な手段です。
しかしながら、この方法には問題点があります。まず、データ型の概念がないため、受け取った側は文字列から integer や boolean といった値に変換する必要があります。また、階層構造を表現する方法もありません。key に対して [ ] をつけて無理やりに階層を表現する方法もありますが、JSON の表現力に比べたら貧弱なものです。
API がシンプルなものであれば、この方法でも問題ないでしょう。しかし、複雑な API に関して言えば、リクエストボディに JSON を使うことにを検討した方が良いです。いずれにせよ、両方採用するようなことはせず、首尾一貫した仕様にしてください。
JSON で POST, PUT, PATCH のリクエストを受け付ける場合は、Content-Type に application/json を指定してもらいましょう。さもなくば、応答するのは 415 Unsupported Media Type です。
ページング情報はレスポンスヘッダに入れよう
先にも述べましたが、ラップするのが大好きな API は往々にしてページング情報をその内側に含めます。私は決してそう言った仕様を責めるつもりはありません。なぜなら、つい最近まではそうするのが普通だったからです。ただ、今は RFC 5988 で提案されている Link ヘッダに倣って、レスポンスヘッダに含めるのが良いでしょう。
Link ヘッダには、API 利用者がいちいち URL を組み立てる必要がないよう「すぐに叩ける状態」の URL を含めましょう。そのためには、ページングはカーソルベースで指定できることがポイントとなります。以下に、GitHub API が返す Link ヘッダを例示します。
Link: <https://api.github.com/user/repos?page=3&per_page=100>; rel="next", <https://api.github.com/user/repos?page=50&per_page=100>; rel="last"
ただ、これだけでは API が返すページングの情報としては不完全です。たとえば、結果のトータル件数がなければ実装に困るでしょう。そういった付加的なものは、X-Total-Count のようなカスタムヘッダを使って返してあげましょう。
関連データを埋め込む手段を作ろう
API 利用者は、往々にしてレスポンス要素の関連データも必要とします。1つのモデルを完成させるのに何回も API を叩いてもらうのは大変ですし、必要に応じて関連データをレスポンスに含めてしまうことは非常に有用に思われます。
ただし、これは REST の原則に背くことでもあります。このルール違反に対する背徳感を少しでも和らげるべく、embed や expand のようなリクエストパラメータでだしわけするようにしましょう。
次の例では、embed パラメータで埋め込む関連データを複数指定し、また、ドット表記を使って取得する項目の指定もしています。
GET /tickets/12?embed=customer.name,assigned_user
これのレスポンスでは、以下のようにチケットに関連データが付与されます。
{
"id" : 12,
"subject" : "I have a question!",
"summary" : "Hi, ....",
"customer" : {
"name" : "Bob"
},
"assigned_user": {
"id" : 42,
"name" : "Jim",
}
}
もちろん、このようなことを実現するためには、API の内部実装を少なからず複雑にする必要があります。往々にして発生するのは、N+1 問題です。
HTTP メソッドを上書きしよう
HTTP クライアントの中には、GET と POST しか扱えないものもあります。こういった制約を持つクライアントでも不自由なく使ってもらえるよう、HTTP のメソッドを上書きする手段を用意しておきましょう。ただし、このやり方にはこれといったスタンダードが存在しません。強いて言うなら、X-HTTP-Method-Override というリクエストヘッダで上書きするメソッド(PUT, PATCH, DELETE)を指定するのが一般的です。
気をつける点としては、上書き可能なのは POST リクエストのみに限定しておくべき、ということです。REST の原則上、GET リクエストはいかなる場合でもサーバのデータを書き換えてはいけないからです!
リクエスト制限情報はレスポンスヘッダに入れよう
一般的に、API の乱用を避けるためにリクエストの回数には制限が入れられます。RFC 6585 でも、429 Too Many Request という HTTP ステータスコードが提案されています。
リクエスト制限を入れるとなると、API 利用者が現在の制限状態をチェックする方法が求められます。これについても、これといったスタンダードなやり方は存在しないのですが、多くの場合はレスポンスヘッダが利用されます。
最低限、以下の情報をヘッダ含めるようにしましょう(ちなみにこれは Twitter の命名規則に従ってします)。
-
X-Rate-Limit-Limit- 一定期間内でリクエストできる最大回数 -
X-Rate-Limit-Remaining- 次の期間までにリクエストできる回数 -
X-Rate-Limit-Reset- 次の期間が来るまでの秒数
ところで、X-Rate-Limit-Reset を日時形式にしないのはなぜでしょう?
日時形式はとても便利ですが、日付やタイムゾーンといった情報はこの用途では余分です。API 利用者が知りたいのは、あとどれくらいでリクエストができるようになるかであり、これに一番簡単に応えるのが秒数なのです。また、端末時計の誤差を無視するという目的もあります。
また、X-Rate-Limit-Reset に UNIX タイムスタンプを使っている API を見かけるかもしれませんが、これは絶対に真似しないでください!
どうしてこれがダメなのかというと、HTTP の仕様としてすでに RFC 1123 が日付のフォーマットについて提案していて、Date, If-Modified-Since, Last-Modified といった HTTP ヘッダで採用されているからです。もし日付の類を扱うヘッダを定義するのであれば、それは RFC 1123 に従う必要があるのです。
トークン認証を使おう
RESTful な API は状態を持ちません。つまり、認証に関して cookie やセッションを使うことはできず、代わりに認証クレデンシャルのようなものを使う必要があります。
SSL の利用を前提とすることで、このクレデンシャルは非常にシンプルなものになります。ランダムに生成された文字列をアクセストークンとして、BASIC 認証のユーザネームフィールドに入力してもらえば良いのです。この方法の優れている点は、ブラウザで扱いやすいことです。未認証の状態であれば、ブラウザはアクセストークンの入力を求めるプロンプトを表示するでしょう。
しかしながら、この BASIC 認証を使った仕組みは、API 利用者がその管理者からトークンをコピーしてもらえる状況でなければ有効ではありません。もしそれができないのであれば、OAuth2 の認証を使って安全に 3rd パーティ開発者用のトークンが発行できるようにしましょう。ちなみに OAuth2 自体も SSL 通信を前提としている点にご注意ください。
JSONP に認証を使う場合は、また別の方法が必要となります。というのも、JSONP のリクエストでは BASIC 認証も Bearer トークンも使えないためです。この場合は、access_token のようなパラメータを使ってトークンの受け渡しをすることになります。ただし、このやり方では、サーバ上のログにトークンが
残る可能性があり、セキュアな方法とはいえない点にご注意ください。
これら3つの方法はトークンの運び方が違うだけであって、本質的にはどれも「トークン認証」と言えます。
キャッシュの情報をレスポンスヘッダに入れよう
HTTP にはキャッシュのための機構が用意されています。API 開発者は、レスポンスにいくつかのヘッダを含め、リクエストのヘッダをバリデーションするだけで、キャッシュの恩恵に与れます。
これについて、ETag を使うやり方と Last-Modified を使うやり方があります。
ETag
レスポンスを送る際に、レスポンス内容のハッシュかチェックサムを ETag ヘッダに含めます。つまりこのヘッダは、レスポンス内容に変更があった際に変わるものとなります。これを受け取ったクライアントは、レスポンス内容をキャッシュしつつ、今後同一 URL のリクエストを投げる際に、ETag の内容を If-None-Match ヘッダに含めるようにします。API は、ETag 値と If-None-Match の内容が一致していれば、レスポンス内容の代わりに 304 Not Modified というステータスコードを返します。
Last-Modified
これは基本的には ETag と同様の概念ですが、タイムスタンプを使う点が異なります。Last-Modified ヘッダには RFC 1123 で提案された形式の日時データが含まれていて、これを If-Modified-Since ヘッダの内容と比較することでキャッシュを制御します。注意点としては、HTTP の仕様では3つの異なる日時形式が定義されていて、API サーバはそのいずれの形式でも許容できるようにする考慮する必要があるということです。
ちゃんとしたエラーメッセージを返そう
Web サイトのエラーページでは、訪問者にとって有益な情報が表示されます。API もこれと同じで、有益なメッセージを、使いやすい形式で返す必要があります。エラーメッセージだからと言って特別にすることはなく、他のリソースと同じように扱えるようにするのです。
HTTP のステータスコードのうち、エラー関連のものは大まかに2種類に分けられます。400 系のクライアント起因のものと、500 系のサーバ起因のものです。最低限、400 系のエラーについては、一通りそれ用の JSON を返すようにしましょう。可能であれば、500 系のエラーについてもそうすると良いです(もっとも、これはロードバランサやリバースプロキシの仕事ですが)。
エラーの内容には、開発者に向けていくつかの情報を含めるようにします。それは、分かりやすいエラーメッセージと、ユニークなエラーコード(これは、ドキュメントで詳細を検索するためのものです)、そして、可能であれば原因の説明です。これらを含めた JSON は以下のようになります。
{
"code" : 1234,
"message" : "Something bad happened :(",
"description" : "More details about the error here"
}
追加・更新時の入力値バリデーションエラーについては、さらにその内容をブレイクダウンした方が良いです。以下の例は、入力値エラーの原因となったフィールドと理由を含めたものです。
{
"code" : 1024,
"message" : "Validation Failed",
"errors" : [
{
"code" : 5432,
"field" : "first_name",
"message" : "First name cannot have fancy characters"
},
{
"code" : 5622,
"field" : "password",
"message" : "Password cannot be blank"
}
]
}
HTTP ステータスコードを有効活用しよう
HTTP ではたくさんのステータスコードが定義されて、これは API でも有効活用できます。これらを使うことは、API 利用者にとってレスポンスを適切に処理するための手助けとなります。是非とも使うべきステータスコードのリストを載せておきます。
-
200 OK- GET, PUT, PATCH, DELETE リクエストが成功した場合に応答。もしくは、POST リクエストが結果的に何もリソースを作らなかった場合に応答。 -
201 Created- POST リクエストがリソース作成に成功した場合に応答。なお、そのリソースへのリンクをLocationヘッダに含める必要がある。 -
204 No Content- 成功したDELETE リクエストで、ボディを返したくない場合に応答 -
304 Not Modified- HTTP キャッシュが有効な場合に応答 -
400 Bad Request- パース不可能なリクエストボディが来た場合に応答 -
401 Unauthorized- 認証がされていない、もしくは不正なトークンの場合に応答 -
403 Forbidden- 認証はされているが、認可されていないリソースへのリクエストに応答 -
404 Not Found- 存在しないリソースへのリクエストに応答 -
405 Method Not Allowed- 認可されていないメソッドでのリクエストに応答 -
410 Gone- 今は存在しないリソース(廃止されたAPIなど)で空要素を返す場合などに応答 -
415 Unsupported Media Type- 対応していない MediaType が指定された場合に応答 -
422 Unprocessable Entity- バリデーションエラーに対して応答 -
429 Too Many Requests- 回数制限をオーバーしたリクエストに対して応答
まとめ
冒頭で述べた通り、API は開発者のための UI です。機能性だけでなく、使い心地まで、とことん追求しましょう。
追記(2016/03/29)
@ryo88c さんが、本記事の説明で不足している「なぜそうすべきか」の具体的な根拠をまとめてくださいました!
また、アンチパターンとなっている箇所についても言及されています。
本質的な理解のため、ぜひこちらの記事も合わせてご確認いただければと思います。
「WebAPI 設計のベストプラクティス」に対する所感 - Qiita
追記(2016/07/19)
@howdy39 さんが、本記事の内容と Google の WebAPI の設計を比較してまとめてくださいました!
かなり詳細に照らし合わせて検証されています。
ぜひ、こちらの記事も合わせてご確認くださいませ。
GoogleのWebAPI設計とWebAPI設計のベストプラクティスを比較してみる - Qiita
-
2016年3月23日時点の内容を翻訳しています ↩