参照渡し、値渡しの定義とは
言語仕様を見よ
終
制作・著作
━━━━━━
ⓃⒽⓀ
C#における参照渡し
C++やPHPといった他の言語も含めた参照渡しの説明としては「呼び出し元の変数に影響が伝搬する呼び出し」あたりが無難でしょうか。C#では引数の前にrefキーワードをつけると参照渡しとなります。
public void sample() {
int i = 5;
value1( i ); //値渡し
Console.WriteLine(i); //=> 5
value2( ref i ); //参照渡し
Console.WriteLine(i); //=> 10
}
// 値型の値渡し
public void value1( int x ) {
x = 10;
}
// 値型の参照渡し
public void value2( ref int x ) {
x = 10;
}
値渡しをしているときはsample関数のiは書き換わりませんでしたが、参照渡しをしているときは書き換わっていることがわかります。
ref キーワード - C# リファレンス | Microsoft Docs
C#には値型、参照型、ポインタ型という概念が全部存在し、それぞれ値渡しと参照渡しを行えるため、参照という言葉を理解するのには便利です。もう少し詳しく見ていきます。
C#の用語や言語仕様
まず、C#に慣れていない方向けに、他言語と差異が出やすい用語や言語仕様を確認します。
値型 (valut type)
構造体(struct)で宣言された型は値型となります。intやfloatといった整数型のほか、SizeとかRectangleといったもう少し複雑な方も値型です。値型はローカル変数の場合はスタックに値が置かれます。参照型と比べ、ヒープ確保やGCといったパフォーマンスへの影響を最小限にできるメリットがあります。
JavaやJavaScriptでいうところの、プリミティブ型に近いものです。
参照型(reference type)
クラス(class)で宣言された型は参照型になります。string、List、配列などは参照型です。ヒープ領域に実体(インスタンス)があり、スタックにはそこへの参照(reference)のみが入っています。巨大なオブジェクトを値渡しすると発生する大量のコピーが防げるのがパフォーマンス上のメリットです。
(厳密な話はしませんが、コンピュータ的には参照とポインタはだいたい同じものです)
ポインタ型(pointer type)
C#にはWin32APIやC言語のDLLとのやり取りを主な目的に、ポインタが存在します。ただし、セキュリティやGCの都合から、非常に厳しい制限がかけられています。unsafeで修飾したり、コンパイラオプションを別途指定せなばならず、参照型のポインタを取得することはさらに規制がかかります。
値渡し(by Value)
C#では何もつけていない関数の引数は値渡しになります。VB.NETではByValをつけることもできます。
呼び出し先の関数で使うためににスタックに値自体をコピーします。
参照渡し(by Reference)
C#ではref out in(C#7.2以降)を引数の前につけると参照渡しになります。VB.NETではByRefをつけます。
呼び出し先の関数で使うためにスタックに値への参照(値の場所のアドレス)を書き込みます。
そのほか用語統一用の話
プリミティブ型
プリミティブ型はJavaなどでは重要な用語です。そして、「C#のプリミティブ型」と「CLR(共通言語ラインタイム)のプリミティブ型」も存在します。・・・が、Javaと違ってC#とCLRのプリミティブ型はあんまり深い意味のない用語です。最初期に定めたものの、値型と参照型の違いで事足りたのでしょう。
他の言語でも「プリミティブ型」の意味合いは仕様書やドキュメントで定義されている場合があるので、よく確認して使用してください。
小ネタ プリミティブ型 | ++C++; // 未確認飛行 C ブログ
オブジェクト
この単語は色々な意味合いで乱用される用語なので、この記事では使用を避けます。
ポインタ渡し
C#ではポインタを扱う事自体がレアケースなので、「ポインタ渡し」と呼ぶ場面はあまりなさそう。「ポインタの値渡し」と同義なので、この記事ではそう表記します。
コードと概念図
概念図はスタックとヒープをイメージしたものです。スタックの下半分が呼び出し元、上半分が呼び出し先の引数やローカル変数をイメージしてます。
概念図なのでアドレスや細かいところは適当です。実際のC#のスタック構造とは異なるので注意してください。
値型
public void valueSample()
{
int x = 10;
value1( x );
Console.WriteLine( x ); //=> 10
value2( ref x );
Console.WriteLine( x ); //=> 20
}
//値型の値渡し
public void value1( int y) {
y = 20;
}
//値型の参照渡し
public void value2( ref int y ) {
y = 20;
}
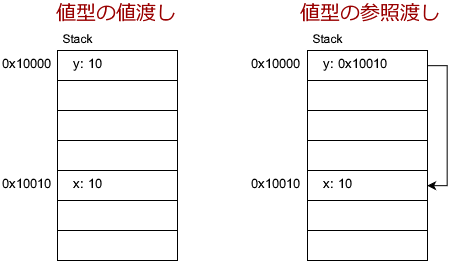
value1ではxそのもの(10)がyにコピーされています。
value2ではxのアドレスがyに書き込まれています。こちらではxの値を書き換えることができるのがわかります。
参照型
配列は参照型です。
public void refSample()
{
int[] x = new int[] {10,20,30};
ref1( x );
Console.WriteLine("[{0},{1},{2}]",x[0],x[1],x[2]); //=>[10,20,30]
ref2( ref x );
Console.WriteLine("[{0},{1},{2}]",x[0],x[1],x[2]); //=>[50,60,70]
}
// 参照型の値渡し
public void ref1( int[] y ) {
y = new int[] {50,60,70};
}
// 参照型の参照渡し
public void ref2( ref int[] y ) {
y = new int[] {50,60,70};
}
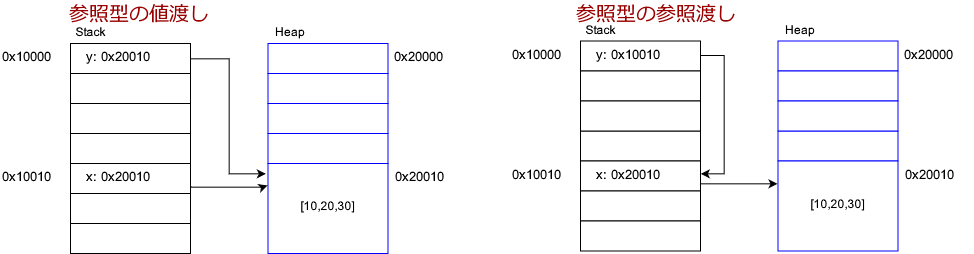
呼出後は以下のように変わります。スタックの書き換えられた位置を緑にしました。
(なんか矢印の先っぽが変な形になってますが、気になさらず)
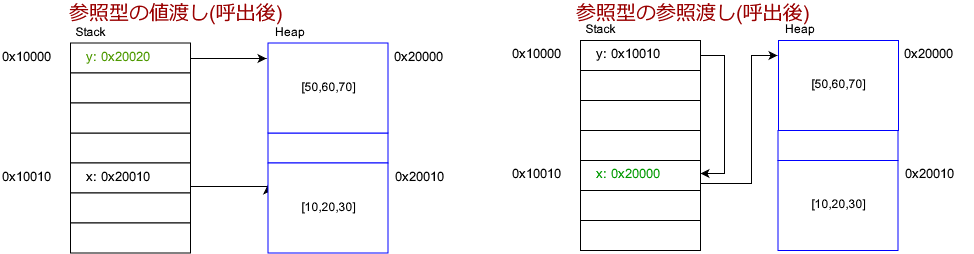
ヒープに新たな配列を確保するのはどちらも同じですが、ref1ではrefSample関数のxには影響が及びません。一方で、ref2ではxの値が書き換わっているのがわかります。
【余談】
クラスの参照渡しはほとんど使うことはありません。この文法が残されているのは、ダブルポインタを扱うWin32APIを自然に叩けるようにするためだと思われます。Win32ではトリプルポインタが出てくることはまずないので、ほとんどの場所で面倒なポインタ構文を使う必要が無くなります。
// C言語
// SHSTDAPI SHGetMalloc(
// IMalloc **ppMalloc
// );
[DllImport("shell32.dll")]
static extern int SHGetMalloc(out IMalloc ppMalloc);
ポインタ型
繰り返しますが、C#のポインタは通常は使いませんが、説明のためにあえてやってるだけです。参照型のポインタは基本的に取れないので値型のポインタについての説明です。
public unsafe void ptrSample()
{
int x = 10;
ptr1( &x );
Console.WriteLine( x ); //=> 20
int *p = &x;
ptr2( ref p );
Console.WriteLine( x ); //=> Invalid(20を出す可能性が高い)
}
//値型へのポインタの値渡し
public unsafe void ptr1( int *y ) {
*y = 20;
}
//値型へのポインタの参照渡し
public unsafe void ptr2( ref int *y ) {
int z = 20;
y = &z; //注意!不適切な代入
}
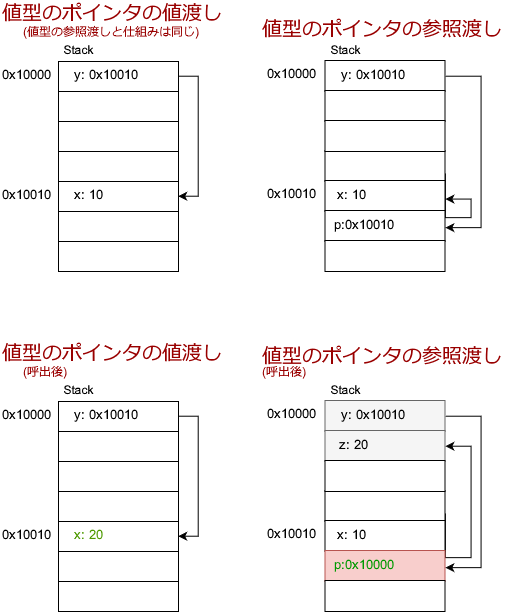
値型のポインタの値渡しは値型の参照渡しとメモリ構造的には完全に同一です。一方で、値型のポインタの値渡しは今回の例では見事に無効なスタック領域を指すようになってしまいました。もちろん、有効な領域を指すポインタにすることも可能ですが、ポインタを使う文脈では素直にダブルポインタを使えば良いので、ポインタを参照渡しするメリットはないと思います。というか、しないで。
[補足]参照とポインタは何が違う?
図を見ると、参照とポインタは何が違うのか、と思うかもしれませんが、機械語レベルではだいたい同じです。一方で、C#の参照は以下のような違いがあります。
- (言うまでもないですが)文法や使える機能が異なる
- 参照はGCが適切にメモリを管理してくれる
- 参照は安全である
- unsafe以外では上のポインタのように無効な領域を指すと言った危険なことは基本起こらない
- ポインタは危険なので
unsafeの指定やコンパイル時に/unsafeを付ける必要があり、実行が制限される可能性がある
C#における参照渡し2019
人によっては、「参照渡しは時代遅れ」思っている方もいるようです。しかし、C#業界では参照渡しはかつてないほどのブームとなっています。
C#のコンパイラがC++製からC#製のRoslynに変わったのですが、それによってパフォーマンス要求が大きくなりました。そこでスタックをうまく使い、遅くなる原因のヒープアロケートを極力避ける方向で文法の拡張が続いており、「安全なポインタ」のように参照渡しがうまく使われている場面があります。その他、スタック領域の配列確保を安全にできるようにしたり、ref戻り値や読み取り専用の参照渡しも登場しています。
JavaやJavaScriptと比べると、プログラマが能動的に最適化を行えるのがC#の面白いところです。一方で、JavaやJavaScriptのJITもかなり早いし、NumPyも丁寧に書かれているので、どの言語が有利!と簡単には言えないのがまた難しいところです。
Span構造体 - C# によるプログラミング入門 | ++C++; // 未確認飛行 C
ref 戻り値と ref ローカル変数 (C# ガイド) | Microsoft Docs
in パラメーター修飾子 - C# リファレンス | Microsoft Docs
まとめ
使い所の難しい参照渡しですが、メモリイメージを完全に理解すればそこまで難しいことはしていません。今後も重要な考え方なので、完全に理解してC#をばりばり書いて行きましょう!
一方で、これはあくまで「C#の参照渡し」のざっくりとした説明です。用語はそれぞれの言語や処理系で異なるので、しっかりと仕様書やドキュメントを確認することが大切です。
(なお、間違いや現在の処理系で異なってる部分があれば教えてください)
【おまけ1】「参照の値渡し」を「参照渡し」と呼ばない方が良い理由
ところで、参照の値渡しを「参照渡し」と呼んでいる方をよく見かけます。そして、それを間違いとする意見もよく見かけます。
まず、「参照渡し(by reference)」が仕様書やドキュメントに用語として使われている言語(C++、.NET系言語、PHPなど)ではふさわしくないでしょう。ちゃんと言語仕様にある用語を使うべきです。
一方で、値渡ししかない言語(JavaScript、Pythonなど)はちゃんと挙動と他の言語での用法を理解していればもう止めてもしょうがない感はあります(私は言いませんがね。)しかし、以下のようなデメリットが生じる可能性があることは留意してください。
言語を跨ぐ際の混乱
C++の影響力はなおも強く、JavaScriptを調べていて気がついたらV8のソースを読んでいたということは稀によくあるかと思います。また、Pythonの拡張ライブラリを書いたりgPRCの発展などで言語の壁が薄くなる展開があれば、言語仕様にない用語は誤った捉えられ方をするかもしれません。
Microsoftやライブラリ用語の影響
参照渡しは.NETやCOMの用語でもあります。.NETによるPythonの実装であるIronPython関連や、JavaScript(JScriptも含む)とWSH絡みでは「JScriptでは参照渡しができないため~」といった説明が現に存在します。近年JavaScript大好きなMicrosoftの展開次第では混乱が生じる場面もあるでしょう。
今後「参照渡し」が追加される可能性
今は参照渡しがない言語に将来「参照渡し」が実装される可能性はないのでしょうか? 例えば、JavaScriptにおいて5年後、10年後にChromeOS絡みやら、WebAssembly絡みの展開を私は全く予測できません。もしどこかに「by reference」という用語が出現したら、混乱や検索の邪魔になることはありえます。
【おまけ2】JIT結果の逆アセンブルを見てみよう!
結局参照よくわからん!という人もいるでしょう。どういう時もとりあえず逆アセンブルを見ておけば安心です(実際はGCの関連などもあるので油断なりませんが)。
https://sharplab.io/ でブラウザから簡単に逆コンパイルを行えます。いい時代になりましたね。
; value1( int y )
C.value1(Int32)
L0000: ret
; value2( ref int y )
C.value2(Int32 ByRef)
L0000: mov dword [rdx], 0x14
L0006: ret
; ref1( int[] y )
; new int[] { 50 }に減らしてあります。
C.ref1(Int32[])
L0000: sub rsp, 0x28
L0004: mov rcx, 0x7ffdb726725a
L000e: mov edx, 0x1
L0013: call 0x7ffdb9a22630
L0018: mov dword [rax+0x10], 0x32
L001f: add rsp, 0x28
L0023: ret
; ref2( ref int[] y )
; new int[] { 50 }に減らしてあります。
C.ref2(Int32[] ByRef)
L0000: push rsi
L0001: sub rsp, 0x20
L0005: mov rsi, rdx
L0008: mov rcx, 0x7ffdb726725a
L0012: mov edx, 0x1
L0017: call 0x7ffdb9a22630
L001c: mov dword [rax+0x10], 0x32
L0023: mov rcx, rsi
L0026: mov rdx, rax
L0029: call 0x7ffdb9a23fc0
L002e: nop
L002f: add rsp, 0x20
L0033: pop rsi
L0034: ret
LinuxとWindowsでは呼び出し規約が異なること、断片的なコードをJITした結果であることに注意してください。Windowsではrcx→rdx→r8→r9の順にレジスタが使われますが、rcxは基本はthisポインタです。
最適化でガッツリコードが消されてますが、value2のコードの扱いとかは見やすいですね!