Seleniumとは
Selenium は Web ブラウザの操作を自動化するためのフレームワークです。
2004 年に ThoughtWorks 社によって Web アプリケーションの UI テストを自動化する目的で開発されました。
https://selenium.dev/history/
元々は Web アプリケーションの UI テストや JavaScript のテストの目的で開発されましたが、テスト以外にもタスクの自動化や Web サイトのクローリングなど様々な用途で利用されています。
この記事では Python で Selenium を介して Chrome を操作するための環境構築と基本的な使い方について説明します。
TL;DR
- 公式の Docker イメージ (https://github.com/SeleniumHQ/docker-selenium) を使うと環境構築が超簡単
- ブラウザをどう操作するかをコードで書いて自動化する
- クローラーの用途でも使える
環境構築
Selenium を使ってブラウザを自動で操作するには以下をインストールする必要があります。
- Web ブラウザ
- Chrome, Firefox, IE, Opera など
- WebDriver
- ブラウザを操作するための API を公開するモジュール
- Selenium
- WebDriver と通信しプログラムからブラウザを操作するライブラリ
ここでは Python で Selenium を使う場合の環境構築について、Docker を使ったやり方とローカル PC に直接環境を作るやり方の2種類をそれぞれ紹介します。
(方法1) Doceker で環境構築
Selenium が公式に公開している Selenium Server の Docker イメージを使うととても簡単にセットアップできます。
https://github.com/SeleniumHQ/docker-selenium
こちらの方法ではこのような構成になり、ブラウザと Remote WebDriver は Docker コンテナ上で動きます。Selenium は別のホストからネットワーク越しに Remote WebDriver に接続しブラウザを操作します。
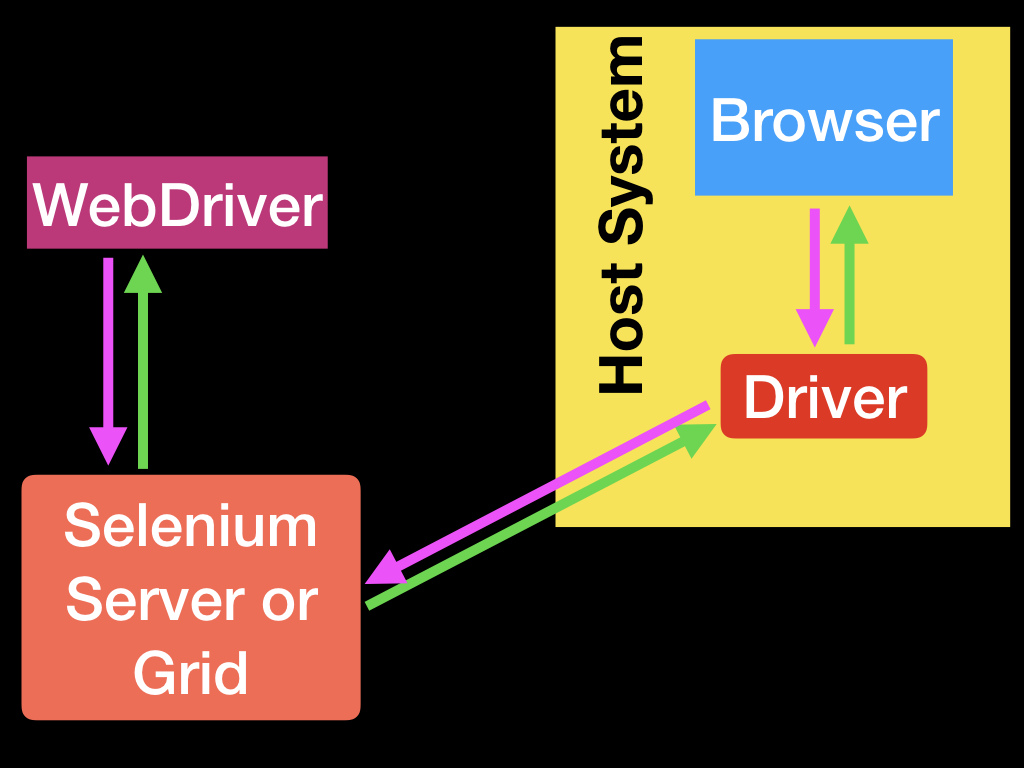
WebDriver はブラウザのバージョンに合ったバージョンを選ばないと動作しないという若干面倒な問題があるのですが、公式の Docker イメージにはブラウザと WebDriver が動作するバージョンの組み合わせでインストール済みなのですぐに使えます。
個人的にはこの方法がセットアップが楽で一番オススメです。
Chrome と WebDriver をインストール
以下のコマンドを実行するだけで Selenium から操作できる Chrome の環境が起動します。
$ docker run -d -p 4444:4444 -v /dev/shm:/dev/shm selenium/standalone-chrome:3.141.59-xenon
Python の Selenium バインディング をインストール
Selenium の Python コードを動かすマシンに Selenium を使うためのライブラリをインストールします。
Python の Selenium バインディングは pip でインストールできます。
$ pip install selenium
動かしてみる
以下のようなコードで Python から Selenium を動かすことができます。
webdriver.Remote を使うところに注意しましょう。
from selenium import webdriver
# Chrome のオプションを設定する
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# Selenium Server に接続する
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
desired_capabilities=options.to_capabilities(),
options=options,
)
# Selenium 経由でブラウザを操作する
driver.get('https://qiita.com')
print(driver.current_url)
# ブラウザを終了する
driver.quit()
(方法2) ローカルに環境構築
次に、Mac のローカル上で Selenium を動かす場合の環境構築方法を書きます。
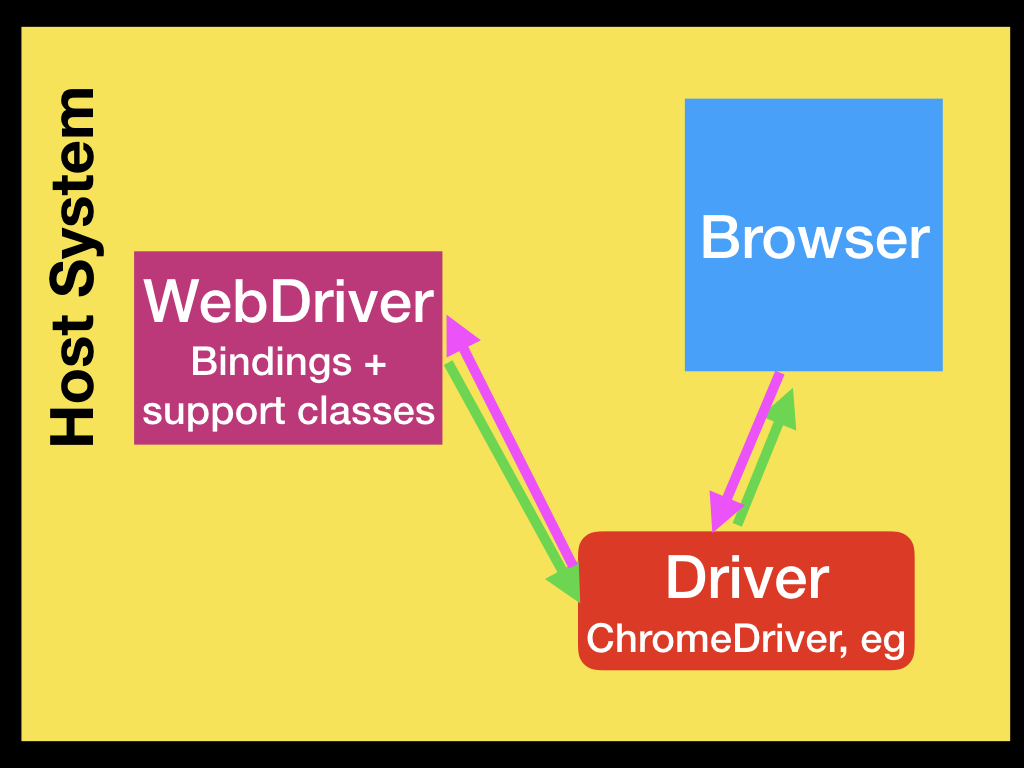
こちらの方法ではこのような構成で、ブラウザと WebDriver が全てローカル上で動いていて、Selenium はローカルの Driver に接続します。
Chrome をインストール
もう既に Chrome が入っている方も多いかもしれませんが普通に Chrome をインストールします。
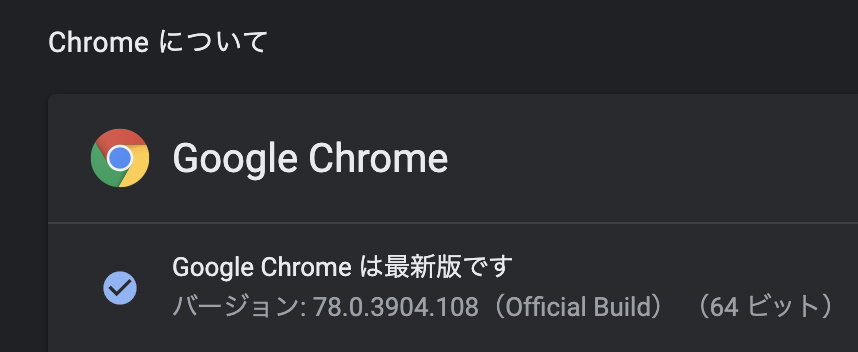
そしてインストールする WebDirver のバージョンを決めるために、インストールされている Chrome のバージョンを確認します。僕の環境では 78.0.3904.108 がインストールされていました。
WebDriver をインストール
Chrome の WebDriver のバイナリをダウンロードします。
Python では chromedriver-binary という、 WebDriver のバイナリのダウンロードとパスの設定をやってくれる便利なライブラリを公開してくれている方がいるのでこれを使います。
Chrome のバージョンと対応した WebDriver をインストールする必要があるので、 pip で以下のようにメジャーバージョンのみ指定して WebDriver をインストールします。
$ pip install chromedriver-binary==78.*
Python の Selenium バインディング をインストール
Python の Selenium バインディングは pip でインストールします。
$ pip install selenium
動かしてみる
ローカル環境では以下のようなコードで Selenium を動かすことができます。
import chromedriver_binary # nopa
from selenium import webdriver
# WebDriver のオプションを設定する
options = webdriver.ChromeOptions()
options.add_argument('--headless')
print('connectiong to remote browser...')
driver = webdriver.Chrome(options=options)
driver.get('https://qiita.com')
print(driver.current_url)
# ブラウザを終了する
driver.quit()
先ほどの Docker での例と比べると WebDriver に Chrome クラスを指定している点が違います。
上記のコードを実行すると PC で Chrome が起動します。
options.add_argument('--headless') の部分をコメントアウトすると、ブラウザの画面が表示され動いている様子を見て確認できます。
基本的な使い方
さて Selenium を使うための環境構築ができるようになったので実際にどのように使うのかを見ていきましょう。
やりたいこと
それでは Selenium で Chrome を動かして以下のような操作をやってみます。
-
Qiita の Chanmoro のプロフィールページにアクセスする
https://qiita.com/Chanmoro -
「最近の記事」に表示されている記事一覧の 2 ページ目に移動する
-
2 ページ目の一番最初に表示されている記事のタイトルを URL を取得して表示する
Python で Selenium を動かす
ここでは冒頭の環境構築で紹介した Docker での Selenium Server を使うことにします。
ローカルの環境であっても WebDrive をセットアップする部分が違うのみで、それ以降の操作については同じコードで動かせます。
まず先にコードの全体をお見せします。
from selenium import webdriver
from selenium.webdriver.common.by import By
# x. Chrome の起動オプションを設定する
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# x. ブラウザの新規ウィンドウを開く
print('connectiong to remote browser...')
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
desired_capabilities=options.to_capabilities(),
options=options,
)
# 1. Qiita の Chanmoro のプロフィールページにアクセスする
driver.get('https://qiita.com/Chanmoro')
print(driver.current_url)
# > https://qiita.com/Chanmoro
# 2. 「最近の記事」に表示されている記事一覧の 2 ページ目に移動する
driver.find_element(By.XPATH, '//a[@rel="next" and text()="2"]').click()
print(driver.current_url)
# > https://qiita.com/Chanmoro?page=2
# 3. 2 ページ目の一番最初に表示されている記事のタイトルを URL を取得する
article_links = driver.find_elements(By.XPATH, '//div[@class="ItemLink__title"]/a')
print(article_links[0].text)
# > Python - 関数を文字列から動的に呼び出す
print(article_links[0].get_attribute('href'))
# > https://qiita.com/Chanmoro/items/9b0105e4c18bb76ed4e9
# x. ブラウザを終了する
driver.quit()
それでは1つづつ順を追って説明していきます。
x. Chrome のオプションを設定する
まずは Chrome を起動する前に、 Chrome の起動オプションを設定します。
オプションのクラスはブラウザ毎に別になっていて Chrome であれば ChromeOptions、 Firefox であれば FirefoxOptions のようにブラウザに対応したクラスが用意されています。
Chrome では headless オプションを付けることによって画面を表示せずにブラウザが起動されます。
基本的には headless モードで動かすことがほとんどだと思いますが、デバッグ中などで画面を操作する様子を目で見て確認したい場合にはこのオプションを指定せずに動かす使い方もできます。
options = webdriver.ChromeOptions()
options.add_argument('--headless')
x. ブラウザの新規ウィンドウを開く
次に Selenium から新規のウィンドウを開きます。
この時ブラウザが起動していなければ起動もされます。
冒頭の環境構築で紹介したように Selenium Server を利用している場合には Remote クラスを使い、ブラウザの種類の指定は desired_capabilities の引数で指定します。
今回の例では options に ChromeOptions オブジェクトが入っているため Chrome を指定することになります。
# NOTE: リモートで Selenium を動かす場合は以下のようにして Remote の WebDriver を指定します
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
desired_capabilities=options.to_capabilities(),
options=options,
)
1. Qiita の Chanmoro のプロフィールページにアクセスする
WebDriver オブジェクトの get() メソッドを呼ぶことで指定した URL にアクセスします。
driver.get('https://qiita.com/Chanmoro')
現在ウィンドウが表示している URL は current_url 、 表示している HTML は page_source でアクセスすることができます
print(driver.current_url)
print(driver.page_source)
2. 「最近の記事」に表示されている記事一覧の 2 ページ目に移動する
プロフィール画面の「最近の記事」の下の方に表示されている 2 ページ目に移動するリンクをクリックしてページを移動します。

Selenium では以下のように find_element で対象の要素を取得し、その要素に対して click() を呼ぶことでクリックをします。
ここでは rel="next" の属性を持っていて 2 の文字列が書かれている a タグを指定してクリックしています。
driver.find_element(By.XPATH, '//a[@rel="next" and text()="2"]').click()
Selenium では XPath 以外にも CSS セレクタや、 ID 指定、 name 属性指定、クラス指定など様々な方法でターゲットとなる要素を指定できます。
個人的には XPath がどんな要素でも強力に一発で仕留められるので一番好きです。
書き方に慣れるまで最初の一瞬少しだけツライですけど。
この例では find_element() に By.XPATH を指定して XPath を書いていますが、find_element_by_xpath() を使って XPath を指定してもやっていることは同じです。
要素を指定するためのメソッドについて詳しくはこちらのドキュメントをご確認ください。
https://selenium-python.readthedocs.io/locating-elements.html
3. 2 ページ目の一番最初に表示されている記事のタイトルを URL を取得する
今度は find_elements() で指定した要素を複数取得します。
クリックの時に使った find_element() は指定した条件にマッチする要素が最初の1つだけ返されるのですが、 find_elements() では複数マッチする場合でも要素の配列が返されます。
プロフィールページでは一覧にある記事タイトルの要素のクラスに ItemLink__title が付与されているのでそこを頼りに記事タイトルの一覧を取得しました。
article_links = driver.find_elements(By.XPATH, '//div[@class="ItemLink__title"]/a')
取得された要素に対して text でそのタグ内に書かれているテキストを取得でき、href などの属性は get_attribute() で取得できます。
print(article_links[0].text)
print(article_links[0].get_attribute('href'))
x. ブラウザを終了する
最後に処理が完了したら quit() を呼んでブラウザを終了します。
driver.quit()
Selenium の処理中にエラーが発生した場合などで quit() を呼ぶのを忘れているとブラウザが起動したままになりメモリの消費がどんどん増えていくようなバグにも繋がるので、 try-catch などでエラーハンドリングをして必ずプログラムの終了時に quit() を呼ぶようにしましょう。
(Tips) Selenium を使ってクローラーを作る
Selenium はクローラーの用途でも使うことができます。
JavaScript による描画の実行やボタンをクリックする操作に Selenium を使い、表示されたページに対して何らかの HTML パーサーを使って要素を取得します。
パース処理は Selenium 自体で用意されている HTML パーサーを使うこともできますが、 BeautifulSoup などライブラリを使った方がパースに便利な機能がついていますしより柔軟に実装できるのでオススメです。
具体的には以下のコードのように driver.page_source で取得した HTML をパースしてデータを取得します。
from bs4 import BeautifulSoup
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
desired_capabilities=options.to_capabilities(),
options=options,
)
driver.get('https://qiita.com/Chanmoro')
# ブラウザに表示されている HTML から BeautifulSoup オブジェクトを作りパースする
soup = BeautifulSoup(driver.page_source, 'html.parser')
articles = soup.select('.ItemLink')
for article in articles:
# プロフィールページに表示されている記事タイトルの一覧を取得
print(article.select_one('.ItemLink__title a').get_text())
driver.quit()
BeautifulSoup の使い方については 「10分で理解する Beautiful Soup」 という素晴らしい記事があるのでこちらも併せてお読みください! (うざい)
https://qiita.com/Chanmoro/items/db51658b073acddea4ac
まとめ
さて、今回の記事では Selenium の環境設定と基本的な使い方についてご紹介しました。
Docker を使って環境構築をするのがすごく簡単ですが、ローカル PC 上で環境を作るのもそれほど難しくないのでどちらの方法でもすぐに試せます。
Selenium は UI テストやブラウザ操作の自動化はもちろんのこと、最後に少し紹介したような JavaScript で描画される SPA のようなサイトをクロールする場合にも使えます。
また UI テストの目的では、複数の種類のブラウザでのテストを同時に動かすことができる Selenium Grid という非常に便利な仕組みがあります。
Selenium Grid は Chrome, Firefox, IE などの複数種類のブラウザや複数バージョンのブラウザをプールしておき、Hub を経由してそれらの複数のブラウザで並行して同じテストを実行することができるというすごい仕組みです。
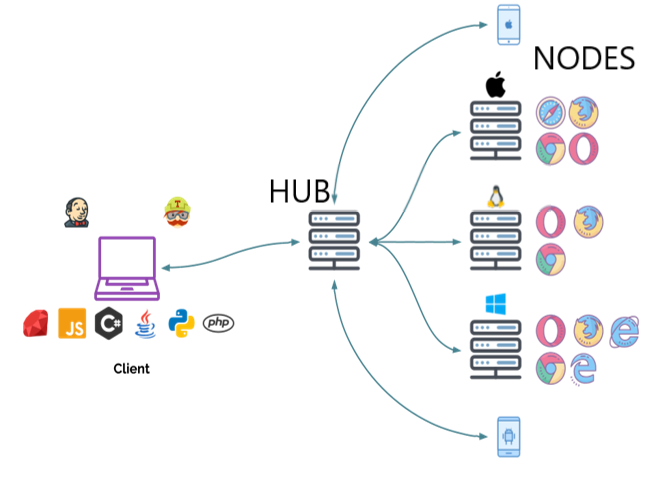
Selenium Grid も docker を使って簡単に環境が作れるようになっているので、詳しくは Selenium Grid のドキュメントや docker-selenium の README をぜひご確認ください。
https://selenium.dev/documentation/en/grid/
https://github.com/SeleniumHQ/docker-selenium
今回この記事を書くにあたり Selenium の歴史 を読んで初めて ThoughtWorks 社のエンジニアが最初に Selenium のコンセプトとコアとなる機能を作ったと知りました。
個人的には ThoughtWorks の人が作ったっていうだけで急激にイケてる感じがしてきます。
また Selenium IDE というブラウザを手動で動かしてその操作をレコーディングし再生できるというこれまた非常に便利なブラウザの拡張機能があり、これは日本人の Shinya Kasatani さん (@shinya) が開発されたそうです。
Selenium は Web アプリケーション開発に革命的な影響を与えているはずですし、こういうソフトウェアを作り OSS として公開し世界中で広く利用されていることは本当にすごいですね。
それでは皆さんも Selenium の使い方を理解して巨人の肩の上に立ち、今日も1日楽しいブラウザオートメーションライフをお過ごしください!