※追記しました
2018/11/10 サンプルコードの言語について、この記事で触れなかったものとその理由について
2018/11/11 諸注意補足
2018/11/12 コードフォーマット、タイポ修正
2018/11/13 ポリモーフィズムのサンプルが弱いとの指摘を頂き追記
はじめに
この記事はオブジェクト指向プログラミング初学者向けの記事です。
記事の内容はオブジェクト指向プログラミングの入り口までを解説しているつもりです。
またオブジェクト指向分析やオブジェクト指向設計については取り扱いません。
オブジェクト指向についてを完全に理解するにはこの記事だけでは足りないと思いますのでその点ご留意願います。
サンプルコードは C# です。
スライドが元ネタになっていて、以下の url がそのスライドです。
もし興味が湧いたらどうぞ。
https://nrslib.com/oop-slide-1/
https://nrslib.com/oop-slide-2/
What is オブジェクト指向?
オブジェクト指向とは何か。
この質問に対しては皆さん一家言をお持ちで、問いかけたらきっと様々な答えが返ってくるでしょう。
私の考えとなってしまって恐縮ですが、この記事におけるオブジェクト指向とは何かをここで定義いたします。
オブジェクト指向は「抽象化」です。
プログラムを理解しやすくために抽象化を行う。その「抽象化」の技法がオブジェクト指向です。
抽象化
そもそも「抽象化」とは何でしょうか。
「抽象化」という言葉自体は知っていても、その意味を問われるとすんなり答えることができない言葉です。
少したとえ話をしましょう。
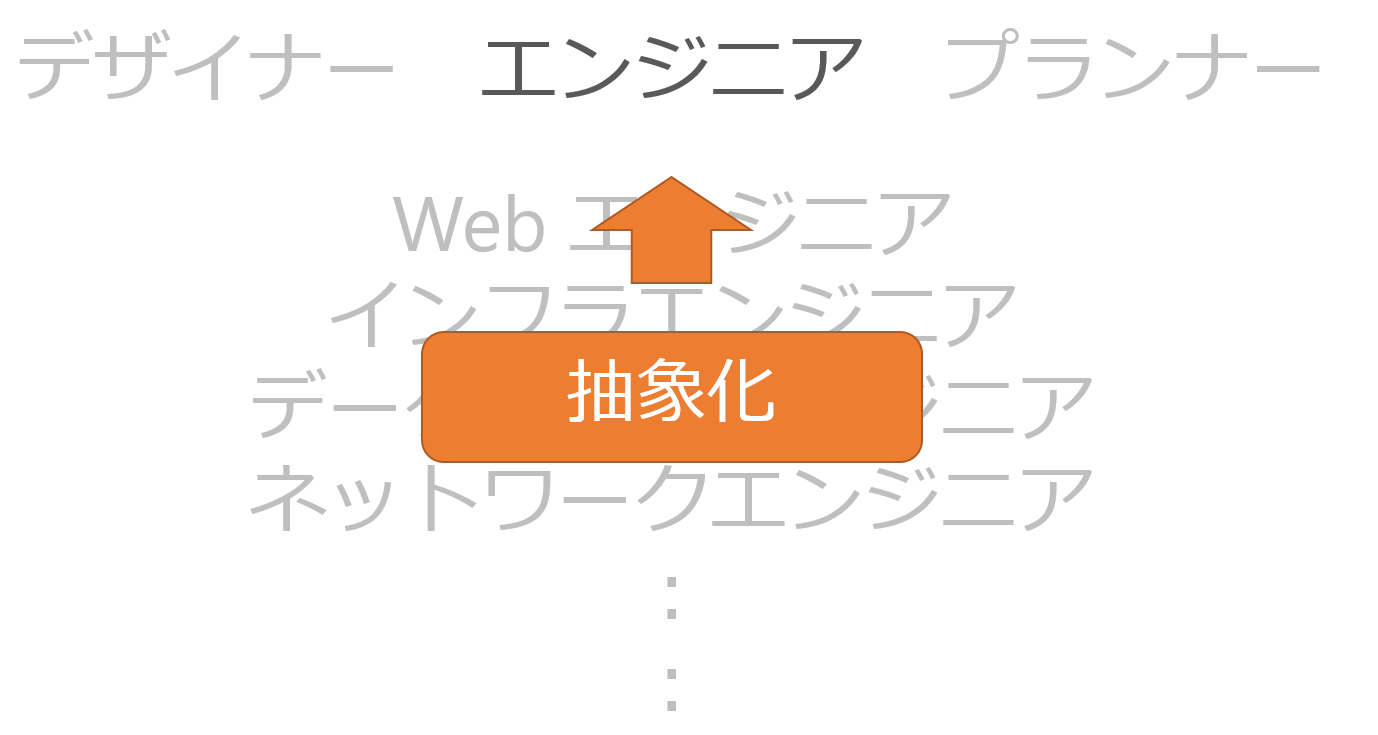
たとえば非 IT 職の方に「あなたの職業は何ですか」と聞かれたら、あなたは何と答えるでしょうか。
たとえば私の場合はまず間違いなく「プログラマです」と答えます。
IT 関係に明るい方が相手であればもう少し詳しい職種を答える可能性はありますが、そうでない場合はイメージしやすい職種としてプログラマと答えます。
これが実は抽象化です。
世の中にはいくつも職業があります。

細分化をしようとすれば、いくらでも細分化できるでしょう。

しかしそんな細かい職種の違いは IT に詳しくない方には伝わらないです。
詳しくない方からしたら、どの職業もエンジニアです。
そんなときに私たちは「抽象化」をして答えるのです。
もう一度質問します。
「抽象化」とは何でしょうか。
ここまでの話を見て、なんとなく想像がついたのではないでしょうか。
「抽象化」とは情報の取捨選択です。理解を助けるために具体的すぎる情報を一旦捨て置き、着目すべき情報を取り出すことです。
Wikipedia の抽象化の項目を参照すると次のように記述されています。
思考における手法のひとつで、対象から注目すべき要素を重点的に抜き出して他は無視する方法である
皆さんの思い描いていた抽象化と合致したでしょうか。
抽象化についてイメージがついたでしょうか。
次の章よりプログラムと抽象化の関係を見ていきましょう。
プログラムと抽象化
変数と抽象化
プログラムにおける抽象化とは何でしょうか。
例えば次のコードを見てください。
※サンプルコードは C# です
var three = 1 + 2;
さて、このthreeは「何」でしょうか。
恐らく「threeはメモリ上に確保された領域で 0000 0000 0000 0000 0000 0000 0000 0011 です」と答える人はいませんね。
大抵の場合は 3 と答えるのではないでしょうか。
次のコードです。
var bottom = 2;
var height = 3;
var area = bottom * height / 2;
area は「何」でしょうか。
「3」と答える方もいらっしゃるでしょうし、「面積」もしくは「三角形の面積」と答える方もいらっしゃるかもしれません。
areaという変数で表現することで具体的な値がなくても理解できるようになったということです。
具体的な値がなくなっても理解できる。つまり変数は抽象化の一種です。
関数と抽象化
ところでさきほどの面積を求める計算ですが、この計算は何を計算しているでしょうか。
var bottom = 2;
var height = 3;
var area = bottom * height / 2;
そうです。三角形の面積の計算をしていますね。
では、次のように記述したらどうでしょうか。
var area = CalculateAreaOfTriangle(2, 3);
こちらも三角形の面積の計算をしているというのが読み取れます。
具体的な計算処理の内容はコード上には全く表れていないですが、理解を阻害していません。
元々のコードでは変数名や処理内容を鑑みて「恐らく」三角形の計算である、と予想できましたが、この新しいコードはそれが情報として抽出されています。
これはつまり抽象化です。
変数と同様に関数も抽象化が行われています。
抽象化の歴史
プログラミング言語の発達は抽象化の歴史です。
機械を扱うための命令は最初は機械のために記述されていました。
しかしそれは余りにも具体的な記述だったので、人には理解しづらいものでした。
人が理解しやすくするために抽象化を施す必要があったのです。
変数も関数もそういった必要に迫られて誕生した抽象化のための技法です。
そして、オブジェクト指向プログラミングも同じように必要とされて誕生した抽象化のための技法です。
変数がデータの抽象化、関数が処理の抽象化だとすると、オブジェクト指向プログラミングでは何を抽象化したかったのでしょうか。
これからそれを紐解いてみましょう。
class
次のプログラムをご覧ください。
void Write(string writeType, string[] data) {
if (writeType == "console") {
Console.WriteLine("Data:");
foreach (var element in data) {
Console.WriteLine("- " + element);
}
} else if (writeType == "file") {
var text = string.Join(",", data);
File.WriteAllText("output.txt", text);
} else {
throw new ArgumentOutOfRangeException(nameof(writeType), writeType, null);
}
}
このコードを見て何を思うでしょうか。
たとえば「コンソールに出力してる」、「ファイルにも出力してるかな」といったことが読み取れるでしょう。
いずれも具体的な処理を読み解いた結果の考えです。
具体的というキーワードが出てきました。これは裏を返すと抽象化されていないということです。
抽象化は理解を助けるものです。
抽象化することで、コードの意図を理解しやすくなる可能性があります。
まずは関数による抽象化をしてみましょう。
void Write(string writeType, string[] data) {
if (writeType == "console") {
WriteConsole(data);
} else if (writeType == "file") {
WriteFile(data);
} else {
throw new ArgumentOutOfRangeException(nameof(writeType), writeType, null);
}
}
void WriteConsole(string[] data) {
Console.WriteLine("Data:");
foreach (var element in data) {
Console.WriteLine("- " + element);
}
}
void WriteFile(string[] data) {
var text = string.Join(",", data);
File.WriteAllText("output.txt", text);
}
WriteConsole という関数とWriteFileという関数を作り、それをWrite関数で呼び出すようにしました。
コードの長さは大して変わらないようですが、Write関数単体で見てみましょう。
void Write(string writeType, string[] data) {
if (writeType == "console") {
WriteConsole(data);
} else if (writeType == "file") {
WriteFile(data);
} else {
throw new ArgumentOutOfRangeException(nameof(writeType), writeType, null);
}
}
関数による抽象化のおかげで処理内容を見ることなく、「もしwriteTypeが "console" だったらコンソールにデータを表示し、"file" だったらファイルに出力する。それ以外は失敗する」ということが読み取れます。
これは最初のコードよりも抽象化されているといえます。
具体的な処理内容を読み解かなくても何を意図しているのかが、分かりやすくなったのではないでしょうか。
しかし、実はこの関数にはまだ「具体的」といえる箇所が存在しています。
それは "console" や "file" です。
"console" や "file" などの文字列は抽象化されていない「具体的」な値を表しています。
"console" と "file" という値は何を指しているのか理解できないこともないのですが、もしも "Console" や "File" といった大文字始まりですと例外になってしまいます。
これらは値、つまりデータです。データといえば変数です。変数で抽象化してみましょう。
const string WriteTypeConsole = "console";
const string WriteTypeFile = "file";
void Write(string writeType, string[] data) {
if (writeType == WriteTypeConsole) {
WriteConsole(data);
} else if (writeType == WriteTypeFile) {
WriteFile(data);
} else {
throw new ArgumentOutOfRangeException(nameof(writeType), writeType, null);
}
}
これによりWrite関数はかなり抽象化されました。
しかし、まだ問題となりうる箇所が存在しています。
この関数のシグネチャ(関数の定義のこと)を見てみましょう。
void Write(string writeType, string[] data);
この関数のシグネチャ「だけ」を見たときにwriteTypeに何の文字列を渡せばよいかわかるでしょうか。
writeType に "console" ないしWriteTypeConsoleなどを渡せばよいと分かるには、関数の処理内容を具体的に知っている必要があります。
「具体的に知っている必要がある」ということはつまり抽象化ができていないということです。
この問題はwriteTypeというデータとその手続きに密接な関係があるのに、データと手続きを分けて考えているために発生しています。
"console"と「コンソールに表示する処理」、"file"と「ファイルに表示する処理」は関係があってしかるべきです。
こういったデータと手続きをまとめるためにクラスが生まれたのです。
では早速クラスに書き換えてデータと手続きをまとめてみましょう。
関数をクラスに書き換える場合は次のような順序で対処していくとよいです。
- 関数名をクラス名にする(名詞になります)
- 引数をフィールドにする
- 関数の処理内容を public メソッドにする
- 処理から呼ばれる関数を private メソッドにする
これらを実施した結果が次の通りです。
class Writer {
public string WriteType;
public string[] Data;
public void Write() {
if (WriteType == "console") {
WriteConsole(Data);
} else if (WriteType == "file") {
WriteFile(Data);
} else {
throw new ArgumentOutOfRangeException(nameof(WriteType), WriteType, null);
}
}
void WriteConsole(string[] data) {
Console.WriteLine("Data:");
foreach (var element in data) {
Console.WriteLine("- " + element);
}
}
void WriteFile(string[] data) {
var text = string.Join(",", data);
File.WriteAllText("output.txt", text);
}
}
このクラスを利用すると次のようになります。
var writer = new Writer();
writer.WriteType = "console";
writer.Data = new[] {"1", "2", "3"};
writer.Write();
このコードは Write というメソッドを呼ぶ前に WriteType と Data を設定する必要があります。これはつまり利用者が実装を具体的に知っているのと同義です。
つまり、あまり先ほどと変わっていません。
なるべくなら Writer を作るときにデータを初期化しておいてほしいものです。
そういった初期化処理を担当するコンストラクタというものがあります。
class Writer {
private string writeType;
private string[] data;
// コンストラクタ
public Writer(string writeType, string[] data) {
this.writeType = writeType;
this.data = data;
}
public void Write() {
if (writeType == "console") {
WriteConsole(data);
} else if (writeType == "file") {
WriteFile(data);
} else {
throw new ArgumentOutOfRangeException(nameof(writeType), writeType, null);
}
}
void WriteConsole(string[] data) {
Console.WriteLine("Data:");
foreach (var element in data) {
Console.WriteLine("- " + element);
}
}
void WriteFile(string[] data) {
var text = string.Join(",", data);
File.WriteAllText("output.txt", text);
}
}
コンストラクタを利用した場合の呼び出し元のコードは次のように変化します。
var writer = new Writer("console", new[] { "1", "2", "3" });
writer.Write();
この変化により、Writeメソッドを呼ぶ際に何も気にする必要がなくなりました。
しかし、当初の "console" や "file" などの文字列で出力方法を指定しないといけないという問題は依然引き継いでしまっています。
またそれ以外の文字列を渡すとエラーとして空文字が返却されてしまいます。
この問題の解決はそもそも "console" や "file" などの文字列を利用しないということで解決します。
class ConsoleWriter {
private string[] data;
public ConsoleWriter(string[] data) {
this.data = data;
}
public void Write() {
Console.WriteLine("Data:");
foreach (var element in data) {
Console.WriteLine("- " + element);
}
}
}
class FileWriter {
private string[] data;
public FileWriter(string[] data) {
this.data = data;
}
public void Write() {
var text = string.Join(",", data);
File.WriteAllText("output.txt", text);
}
}
もはやwriteTypeというフィールドは不要になりました。
例えば ConsoleWriter を利用した場合はこのとおりです。
var writer = new ConsoleWriter(new[] {"1", "2", "3"});
writer.Write();
これらの一連の抽象化の結果、クラスにデータと処理が隠蔽されました。
この隠蔽することが カプセル化 と呼ばれます。
interface
クラスはカプセル化ということで一旦置いておいて次の話題に進みます。
次のコードを眺めてみてください(読み込む必要はないです)。
public class Program {
public void Process(string convertType, string[] data) {
string output;
if (convertType == "csv") {
string csv;
if (data.Length > 0) {
csv = data[0];
} else {
csv = "";
}
for (int i = 1; i < data.Length; i++) {
csv += "," + data[i];
}
output = csv;
} else if (convertType == "tsv") {
string tsv;
if (data.Length > 0) {
tsv = data[0];
} else {
tsv = "";
}
for (int i = 1; i < data.Length; i++) {
tsv += "\t" + data[i];
}
output = tsv;
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
}
このコードは単純ではありますが、若干複雑です。
なぜこのコードが複雑なのでしょうか。
そもそも複雑とは何を指して複雑というのでしょうか。
コードの複雑さを測る指標のひとつとして有名なものに、循環的複雑度と呼ばれるものがあります。
これは循環経路、つまり if 文などの分岐点を基準にしてコードの複雑度を計測する指標です。
つまりこのコードは「条件分岐が多い」ため、複雑であるといえるのです。
では、このコードをシンプルにするにはどうすればよいか。
条件分岐が複雑さに繋がるのであれば、「条件分岐を減らす」ことがそのまま「複雑さを減らす」ことに繋がります。
さっそく条件分岐を減らしたいところですが、単純に if 文を消すと処理が変わってしまうのでそういうわけにもいきません。
そこで抽象化の出番です。
たとえばメソッドを利用して抽象化してみたらどうでしょうか。
public class Program {
public void Process(string convertType, string[] data) {
string output;
if (convertType == "csv") {
output = JoinByComma(data);
} else if (convertType == "tsv") {
output = JoinByTab(data);
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
private string JoinByComma(string[] data) {
string csv;
if (data.Length > 0) {
csv = data[0];
} else {
csv = "";
}
for (int i = 1; i < data.Length; i++) {
csv += "," + data[i];
}
return csv;
}
private string JoinByTab(string[] data) {
string tsv;
if (data.Length > 0) {
tsv = data[0];
} else {
tsv = "";
}
for (int i = 1; i < data.Length; i++) {
tsv += "\t" + data[i];
}
return tsv;
}
}
コードの全体の条件分岐の量は変わりませんが、Program.Processメソッドでは条件分岐が減っています。
次のようにProgram.Processメソッド単体で読んでみても、その意図を読み取ることは難しくないでしょう。
public class Program {
public void Process(string convertType, string[] data) {
string output;
if (convertType == "csv") {
output = JoinByComma(data);
} else if (convertType == "tsv") {
output = JoinByTab(data);
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
/* 省略 */
}
しかし依然として条件分岐は残ってしまっています。
では、今度はクラスで抽象化をするとどうなるでしょうか。
public class CsvConverter {
public string Convert(string[] data) {
string csv;
if (data.Length > 0) {
csv = data[0];
} else {
csv = "";
}
for (int i = 1; i < data.Length; i++) {
csv += "," + data[i];
}
return csv;
}
}
public class TsvConverter {
public string Convert(string[] data) {
string tsv;
if (data.Length > 0) {
tsv = data[0];
} else {
tsv = "";
}
for (int i = 1; i < data.Length; i++) {
tsv += "\t" + data[i];
}
return tsv;
}
}
このCsvConverterクラスとTsvConverterクラスを使ってコードを書き直すと次のコードになります。
public class Program {
public void Process(string convertType, string[] data) {
string output;
if (convertType == "csv") {
var converter = new CsvConverter();
output = converter.Convert(data);
} else if (convertType == "tsv") {
var converter = new TsvConverter();
output = converter.Convert(data);
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
}
このコードはメソッドで抽象化した場合となんら変わらない状況です。
(むしろメソッドで抽象化したときよりもnewする行の分だけ行数が増えています)
ここで注目すべきは以下の部分です。
if (convertType == "csv") {
var converter = new CsvConverter();
output = converter.Convert(data); // ← ここと
} else if (convertType == "tsv") {
var converter = new TsvConverter();
output = converter.Convert(data); // ← ここ
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
条件分岐の中の処理のoutput = converter.Convert(data);というコードが全く同じです。
ということは、もしかしたら次のような処理を書けるのではないでしょうか。
// 疑似コードです 実際はコンパイルエラーです
var converter;
if (convertType == "csv") {
converter = new CsvConverter();
} else if (convertType == "tsv") {
converter = new TsvConverter();
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
output = converter.Convert(data);
更に一歩進めると次のようなコードも書けるのではないでしょうか。
var converter = CreateConverter(format); // CreateConverter は CsvConverter や TsvConverter を作るメソッド
output = converter.Convert(data);
具体的な処理はなくなりましたが、意図は伝わります。
もしこれができたら素晴らしいことですね!
その素晴らしいことを実現するのが interface です。
早速 interface を使ってみましょう。
まずは今回のConverterに合わせた interface を用意します。
interface の内容は今回利用する予定のメソッドを定義します。
// C# の慣習で最初に 'I' をつけます
interface IConverter {
string Convert(string[] data);
}
そしてこの interface を実装します。
public class CsvConverter : IConverter {
public string Convert(string[] data) {
string csv;
if (data.Length > 0) {
csv = data[0];
} else {
csv = "";
}
for (int i = 1; i < data.Length; i++) {
csv += "," + data[i];
}
return csv;
}
}
public class TsvConverter : IConverter {
public string Convert(string[] data) {
string tsv;
if (data.Length > 0) {
tsv = data[0];
} else {
tsv = "";
}
for (int i = 1; i < data.Length; i++) {
tsv += "\t" + data[i];
}
return tsv;
}
}
この interface を利用すると次のコードになります。
public class Program {
public void Process(string convertType, string[] data) {
var converter = CreateConverter(convertType);
string output = converter.Convert(data);
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
private IConverter CreateConverter(string convertType) {
if (convertType == "csv") {
return new CsvConverter();
} else if (convertType == "tsv") {
return new TsvConverter();
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
}
}
このコードではconverterに代入されているオブジェクトによって処理が分岐します。
このように異なるオブジェクトを同じものとして抽象化することをポリモーフィズムといいます。
カプセル化と並んでオブジェクト指向において重要とされる要素のひとつです。
ところで、このプログラムは別解として次のようにメソッドで結果を戻すように記述することもできます。
public class Program {
public void Process(string convertType, string[] data) {
string output = CreateOutput(convertType, data);
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
private string CreateOutput(string convertType, string[] data) {
if (convertType == "csv") {
return JoinByComma(data);
} else if (convertType == "tsv") {
return JoinByTab(data);
} else {
throw new ArgumentOutOfRangeException(nameof(convertType));
}
}
}
Process メソッドを比較したとき、interface を使った場合とメソッドで解決した場合と、そのどちらも行数に差はないです。
で、あればわざわざ interface などというものを用いる必要性もなさそうです。
せっかく interface というものを使っているので、interface ならではの記述をしてみましょう。
interface は次のようなコードを実現します。
public class Program {
public void Process(IConverter converter, string[] data) {
string output = converter.Convert(data);
string message;
if (data.Length > 10) {
message = "Many elements.";
} else {
message = "Few elements.";
}
Console.WriteLine(message);
Console.WriteLine(output);
}
}
文字列の成型処理というものがProcessメソッドの引数として外部から与えられています。
結果としてこのProgramクラスはformatという変数の中身が "csv" や "tsv" であるという知識を持っている必要がなくなりました。またProgramクラス自体が例外を発生させることがなくなりました。
そのときは次のクラスを追加して、引数として渡してあげればよさそうです。
public class PipeJoinConverter : IConverter {
public string Convert(string[] data) {
string text;
if (data.Length > 0) {
text = data[0];
} else {
text = "";
}
for (int i = 1; i < data.Length; i++) {
text += "|" + data[i];
}
return text;
}
}
interface を用いることでProgramクラスを修正することなく拡張ができるのでした。
またもう一つの if 文である、要素の評価をしている部分はどうでしょうか。
現在要素の評価は要素数が 10 を超えるか超えないかで出力をしています。
ここをたとえば次のように interface で評価するようにしてみましょう。
public class Program {
public void Process(IConverter converter, string[] data, IEvaluator evaluator) {
string output = converter.Convert(data);
evaluator.Evaluate(data);
Console.WriteLine(output);
}
}
public interface IEvaluator {
void Evaluate(string[] data);
}
public class NormalEvaluator : IEvaluator {
public void Evaluate(string[] data) {
if (data.Length > 10) {
Console.WriteLine("Many elements.");
} else {
Console.WriteLine("Few elements.");
}
}
}
引数としてNormalEvaluatorが引き渡されることで依然と同じように処理が行われます。
そして評価を行う処理が interface で定義されたことで、次のようにバリエーションをいくらでも増やすことが出来ます。
public class StrictEvaluator : IEvaluator {
public void Evaluate(string[] data) {
if (data.Length > 10) {
Console.WriteLine("Many elements.");
} else if (data.Length > 5) {
Console.WriteLine("So so.");
} else {
Console.WriteLine("Few elements.");
}
}
}
public class IsEvenEvaluator : IEvaluator {
public void Evaluate(string[] data) {
if (data.Length % 2 == 0) {
Console.WriteLine("even");
} else {
Console.WriteLine("odd");
}
}
}
これは新たな処理を増やしたとしてもProgram.Processというメソッドを変更する必要がないということを表しています。
つまり、自由に拡張ができるということですね。
こういった interface を活用し、CsvConverterとTsvConverterやNormalEvaluatorとStrictEvaluator等の異なったオブジェクトを同一のものとしてみなし、同じように扱えるようにすることを ポリモーフィズム といいます。
オブジェクト指向とは何か
以上よりオブジェクト指向は次のように定義づけることができます。
オブジェクト指向は カプセル化 と ポリモーフィズム を利用した 抽象化 の技法です。
というわけで次の章より、カプセル化とポリモーフィズムの解説を行っていきます。
カプセル化
前章でカプセル化についてはデータとその振る舞いを隠蔽することと定義しました。
言葉にしてしまうとたったそれだけなのですが、このカプセル化というのは案外実践をするのが難しかったりします。
そこでカプセル化の理解を深めるべく、まずはなぜカプセル化が必要なのかということと、それを実践をするためのガイドラインをご紹介します。
カプセル化がなぜ必要なのか
カプセル化が必要な理由はカプセル化を「しなかった場合」を確認するとわかりやすいです。
まずは次のクラス定義をご覧ください。
// 定義
public class BusinessLogic {
public void Process();
public void SetLogger(Logger logger);
}
このクラスを利用して次のようなコードを実行します。
var logic = new BusinessLogic();
logic.Process();
しかし、このプログラムは上手く動作せず、エラーにより停止してしまいます。
なぜならBusinessLogicクラスは次のように記述されていたからです。
public class BusinessLogic {
private Logger logger;
public void Process() {
logger.Log("Start"); // ← SetLogger で設定されていない場合 logger が null で落ちてしまう
/* 省略 */
}
public void SetLogger(logger) {
this.logger = logger;
}
}
これでは落ちてしまうのも当然です。
これを防ぐには次のコードに変更する必要があります。
var logic = new BusinessLogic();
var logger = new Logger();
logic.SetLogger(logger);
logic.Process();
さて、このコードはBusinessLogic.Processメソッドを呼ぶ前にBusinessLogic.SetLoggerメソッドを正しく実行する必要があるということを認識したからこそ書けるコードです。
言い換えるならばBusinessLogicクラスを利用するにはBusinessLogicの実装を「具体的に」知っている必要があるということです。
具体的というキーワードが出てきました。
これは裏を返せば、抽象化できていないということです。
メソッドに依存関係があるということはクラスの利用者にはわかりません。
前後関係はクラスの実装者だからわかることです。
クラスの実装の都合を隠蔽しきれないと、先ほどの例の通りランタイムエラーが発生することがあります。
カプセル化のメリットがまさにここです。
実装上の都合を隠すことにより利用者が安心してクラスを利用できるようになるというのが大きなメリットです。
ガイドライン
最初に申し上げた通り、カプセル化は簡単そうに見えて実践するのが意外に難しい代物です。
ひとつひとつ根底にある考え方から解説しても、それをどのように表現すればよいのかが思いつかなかったりします。
そこで今回はガイドラインを紹介して解説しようと思います。
このガイドラインはとにかく念頭に置いておいてほしいものだけを抜粋しました。
これがカプセル化のすべてではないですが、念頭において実践していくことでカプセル化の実践を助けるものです。
ガイドラインは次の六つです。
- 初期化はコンストラクタ
- 自由な型は便利に使わない
- メソッドに前後関係は作らない
- 副作用をわかりやすく
- setter は使わない
- getter は使わない
ひとつずつ解説をしていきます。
1.初期化はコンストラクタ
たとえばInitializeメソッドを作ったとしても見落とされます。
var logic = new BusinessLogic();
logic.Execute(); // Runtime Error !!!
// クラス定義
public class BusinessLogic {
private bool isProduct;
private Logger logger;
public void Initialize(bool isProduct, Logger logger) { // ← 初期化に気づかず呼ばなかった
this.isProduct = isProduct;
this.logger = logger;
}
public void Execute() {
/*
* 処理
*/
}
}
これは当然です。
Initializeを呼ばなくてもExecuteを呼ぶことができてしまうのですから。
初期化が必要な場合は基本的にコンストラクタを利用しましょう。
var logic = new BusinessLogic(); // コンパイルエラーが出るので安心
logic.Execute();
public class BusinessLogic {
private bool isProduct;
private Logger logger;
public BusinessLogic(bool isProduct, Logger logger) {
this.isProduct = isProduct;
this.logger = logger;
}
public void Execute() {
/*
* 処理
*/
}
}
2.自由な型を便利に使わない
次のクラス定義をご覧ください。
public class BusinessLogic {
public BusinessLogic(string mode);
public void Execute();
}
さてこのmodeには何を指定すればよいでしょうか。
何を指定すべきか予想できた方はエスパーです。
きっと皆さんはこのmodeを指定するために、BusinessLogicの実装を確認するでしょう。
public class BusinessLogic {
private readonly string mode;
public BusinessLogic(string mode) {
this.mode = mode;
}
public void Execute() {
switch (mode) {
case "Product":
/* 本番処理 */
case "Test":
/* テスト環境での処理 */
default:
throw new Exception(mode);
}
}
}
正解は"Product"または"Test"だったようです。
このように string などの自由度が高い型を指示子として利用すると、クラスの「具体的な」実装を確認しない限り正しい指示子を指定することができません。
今回のような場合であれば次のように自由度が低い型を指示子として利用するとよいでしょう。
public class BusinessLogic {
public BusinessLogic(Mode mode);
public void Execute();
}
public enum Mode {
Product,
Test
}
3.メソッドに前後関係は作らない
処理順序はときに重要です。処理順序を変更するだけで結果が全く変わってしまうことがあります。
たとえば次のようなクラスを見てみましょう。
public class BusinessLogic {
private Logger logger;
public void Execute() {
logger.Log("Execute on " + DateTime.Now);
}
public void BeforeExecute() {
logger = new Logger();
}
}
BusinessLogic.Execute メソッドとBusinessLogic.BeforeExecuteメソッドには密接な前後関係が存在します。
もしも事前処理のBeforeExecuteを呼び出さず、Executeメソッドを呼び出した場合はプログラムが異常停止してしまいます。
var logic = new BusinessLogic();
logic.Execute(); // <- インスタンス内部で logger がインスタンス化されていないため null で落ちてしまう
たとえ Before と銘打たれていたとしても、それは必ず呼び出さなくてはいけないのか、それとも任意で呼び出すものなのか、はたまた全く関係ない処理なのか、ということは利用者には判断つきません。
サンプルとしてクラスでBeforeExecuteをExecuteの実行前に呼び出す必要があるということは「具体的な」実装を確認して初めてわかることです。
もしも前後関係が存在し、その処理が必ず呼び出してほしい処理であるならば、それは内部で呼び出すべきでしょう。
public class BusinessLogic {
private Logger logger;
public void Execute() {
BeforeExecute();
logger.Log("Execute on " + DateTime.Now);
}
private void BeforeExecute() {
logger = new Logger();
}
}
このクラス定義であれば外部から呼び出すことが出来るメソッドはExecuteメソッドのみです。
もはや迷いようがありません。
4.副作用をわかりやすく
副作用という言葉をご存知でしょうか。
たとえば次のクラスをご覧ください。
public class CommandHandler {
public bool Validate(Command command) {
if (command.Operation == "nop") {
command.Operation = null; // Handle メソッドで何もしないために null に変更
}
if (command.Id < 0) {
return false;
}
return true;
}
public void Handle(Command command) {
if (command.Operation == null) {
return;
} else {
switch (command.Operation) {
case "add":
/* 追加処理 */
break;
case "update":
/* 更新処理 */
break;
case "del":
/* 削除処理 */
break;
}
}
}
}
このクラスのValidateメソッドは副作用のあるメソッドです。
具体的にはcommand.Operation = null;という処理で副作用を引き起こしています。
このような状態に変化を与えることを副作用と呼びます。
副作用の対象はクラスのフィールドの変更などを指し示すこともあれば、ファイルへの出力といったことを指すこともあります。
その対象が何であろうと変化を引き起こすことが副作用です。
さて、この項は「副作用をわかりやすくする」ということでした。
もしも副作用をわかりづらくした場合はどうなるでしょうか。
ちょうどこのCommandHandlerは副作用がわかりづらいクラスになっているので利用してみましょう。
var command = new Command(-1, "nop"); // Id は間違った値, Operation は何も操作しない "nop"
var handler = new CommandHandler();
if (handler.Validate(command)) {
handler.Handle(command);
} else {
Console.WriteLine(command.Operation); // "nop" が表示されそうなのに何も表示されない
}
このコードはもしもバリデーションに失敗したときにそのOperationの内容を表示するということを意図しています。
今回の場合は "nop" というOperationの内容が表示されてほしいところですが、このコードを実行すると何も発生しません。
これは Validate メソッドでCommand.Operationの内容を書き換えてしまっているからです。
public class CommandHandler{
public bool Validate(Command command) {
if (command.Operation == "nop") {
command.Operation = null; // Handle メソッドで何もしないために null に変更
}
/* 以下省略 */
これが副作用の難しさです。
もちろんプログラムを作るうえで副作用というのは避けられません。
副作用が一切ないプログラムは結果もないということですので、およそ役に立つものではないでしょう。
では、どうすればこの副作用とうまくやっていけるでしょうか。
実はこれに対する回答として、次のルールを守ることで比較的安全に副作用のあるメソッドを利用することが出来ます。
- 戻り値のあるメソッドは副作用を起こさない
メソッドは大別すると二種類です。それは戻り値のあるメソッドと戻り値のないメソッドの二つです。
そして、この戻り値のないメソッドというものは確実に副作用を発生させます(もしも、戻り値がないメソッドが副作用を発生しないとしたら、全くの意味がないメソッドとなってしまいます)。
戻り値がないメソッドは副作用を発生させるのですから、戻り値のあるメソッドでは副作用を発生させないと決めることによって、メソッドの定義(戻り値)を見るだけで副作用が起きる起きないかの判別がつくようになるのです。
そのルールに従うと先ほどのCommandHandlerは次のようにValidateは副作用を起こさないようにするべきでしょう。
public class CommandHandler {
public bool Validate(Command command) {
if (command.Id < 0) {
return false;
}
return true;
}
public void Handle(Command command) {
if (command.Operation == "nop" || command.Operation == null) {
return;
} else {
switch (command.Operation) {
case "add":
/* 追加処理 */
break;
case "update":
/* 更新処理 */
break;
case "del":
/* 削除処理 */
break;
}
}
}
}
5.setter は使わない
setter は利用者にクラスの内部実装を強く意識させるものです。
次のクラスのインターフェースをご覧ください。
public class BusinessLogic {
public Logger Logger { get; set; }
public void Execute();
}
この Logger という setter はインターフェースを見ただけでは利用方法がわかりません。
そこでクラスの実装を見てみましょう。
public class BusinessLogic {
public Logger Logger { get; set; }
public void Execute() {
if (Logger != null) {
Logger.Log("Starting");
}
/* 省略 */
}
}
どうやらExecuteメソッドを呼ぶ前に setter を利用することでログを取得できるようです。
このサンプルからわかることは setter を用意するということは、その setter を利用することでクラスにどのような影響があるのかを、利用者に意識させるということです。
これは即ちカプセル化できていないということを意味します。
ではどうすればよいのか。
先ほどのサンプルであればオプショナルとしてLoggerを受け取るようにすればメソッドとの結びつきを示すことができます。
public class BusinessLogic {
public void Execute(Logger logger = null) {
if (Logger != null) {
Logger.Log("Starting");
}
/* 省略 */
}
}
クラスによってコンストラクタで設定させる方がよい場合もあれば setter が妥当な場合もあります。
フレームワークの都合で setter を採用せざるを得ないときもあります。
しかし、setter は第1の選択肢にすべきではありません。
setter を利用したいと感じたときは一度立ち止まって、それが妥当であるかどうかを考慮すべきでしょう。
6.getter は使わない
setter と同様 getter も避けるべきです。
安易な getter によるデータの公開はクラスを脆いものにします。
public class Logic {
private int numElement;
public Logic(List<int> source) {
numElement = source.Count; // コレクションの要素数を cache
Data = source;
}
public List<int> Data { get; }
public int Sum() {
var result = 0;
for (int i = 0; i < numElement; i++) { // cache されたコレクションの要素数を利用
result += Data[i];
}
return result;
}
}
サンプルのクラスにはDataという getter が存在します。これはコンストラクタで受け取ったデータです。
またクラス内での計算処理の高速化のためnumElementというフィールドでデータの要素数をキャッシュしています。
このクラスは次のように操作をするとエラーを起こします。
var source = new List<int> { 1, 2, 3 };
var logic = new Logic(source);
logic.Data.Remove(3); // getter を経由してデータの削除
var result = logic.Sum();
これが getter によるクラスの 破壊 です。
破壊というのはカプセル化のキーワードです。
破壊されないように隠蔽するという見方もあります。
また getter のもう一つの問題として 知識の流出 があります。
これは本来クラスに納めておくべき知識が外部に記述されてしまうことを指します。
具体的に見てみましょう。
public class Team {
public List<Member> Members { get; } = new List<Member>();
}
Team クラスはメンバーを追加することができます。
メンバーは最大50人まで追加できることとして、チームにメンバーを追加するコードを記述してみましょう。
void AddMember(Team team, Member member) {
if (team.Members.Count() >= 50) {
throw new Exception("最大人数を超過します");
}
team.Members.Add(member);
}
さて、このteam.Members.Count() > 50という条件式ですが、ここだけで済めばよいのですが、もしも他の箇所でチームの最大人数が必要になったときはどうなるでしょうか。なんだか至るところに記述することになってしまいそうですね。
実際にいたるところにこのロジックを埋め込んだとして、もしもチームの最大人数を変更することになったらどうなるでしょう・・・?
ぞっとする話だと思います。
本来この「チームは最大50人まで」という知識はクラスに納めておくべき知識です。
Teamクラスは getter を利用せず次のように定義すべきでしょう。
public class Team {
private readonly List<Member> members = new List<Member>();
public void Join(Member member) {
if (members.Count() >= 50) {
throw new Exception("最大人数を超過します");
}
members.Add(member);
}
}
getter の怖さが伝わったでしょうか。
getter は安易に公開すべきものではありません。
setter と同様、第1の選択肢にすべきではありません。
公開することによって発生しうるリスクを考慮する慎重さを持つことをお勧めします。
カプセル化まとめ
カプセル化は何のためにするのか。
隠すことがカプセル化ですが、隠すことそれ自体が目的ではありません。
隠蔽することは手段です。
では目的は何だったのか。
一つ目の目的は知識の集約です。
最後の getter の例を思い出してみてください。
getter を公開していた最初の状態では、条件式がクラスの外側に記述されており、いわゆる知識の流出が発生していました。
getter を利用しないようにすると、知識がクラスの内部に納めることができます。
これは結果として変更箇所をクラスの内部に収めることにつながります。
もしも条件を変更することが必要になったとしても、クラスを利用している側に変更の影響を与えずに変更することができるのです。
二つ目の目的は安全かつ手軽に扱えるようにすることです。
たとえばテレビの電源を付けるということがどういったステップを踏んで実現されるのかを知らなくても、私たちはリモコンで電源を付けることができます。
電話をかけるということがどういったステップを踏んで実現されるのかを知らなくても、私たちは電話をかけることができます。
細心の注意を払いながら、リモコンを操作したり、電話をかけることはありません。
詳細を知らなくても安全に利用できるように隠蔽を行うのです。
カプセル化はそれ自体は簡単なことに思えるのですが、正しく抽象化し、変更に備えたクラスの形を作るのはとても難しいです。
ガイドラインに頼り切らず、それが正しいかどうかを考えながらクラスを形作りましょう。
ポリモーフィズム
さて今度は打って変わってポリモーフィズムについてです。
ポリモーフィズムのメリットは条件分岐を減らすことであるとしていました。
実はこれは少し語弊があります。
条件分岐の数は変わりません。正しくは条件分岐を「メイン処理から」減らすことがポリモーフィズムのメリットです。
その結果としてメイン処理がシンプルになり、人が理解しやすいものになるのです。
とはいえ、闇雲にポリモーフィズムを採用すればよいというわけではありません。
この章ではポリモーフィズムを実践することに焦点を当てて解説をしていきます。
リファクタリング
何かを学ぶときにそのメリットの実感をするには、実践するのが一番です。
ポリモーフィズムを利用していないクラスのリファクタリングをしてみましょう。
次の支払方法を変更するクラスはいくつかの問題を抱えたコードです。
public class BusinessLogic {
private readonly CreditApi creditApi;
private readonly BankApi bankApi;
public BusinessLogic(CreditApi creditApi, BankApi bankApi) {
this.creditApi = creditApi;
this.bankApi = bankApi;
}
public UpdateResult UpdatePayment(UpdatePaymentRequest request) {
switch (request.PaymentType) {
case PaymentType.ConvenienceStore: return UpdateToConvenienceStore(request);
case PaymentType.CreditCard: return UpdateToCredit(request);
case PaymentType.Bank: return UpdateToBank(request);
default: throw new ArgumentOutOfRangeException(typeof(request.PaymentType));
}
}
private UpdateResult UpdateToConvenienceStore(UpdatePaymentRequest request) {
/*
* コンビニ支払い登録処理
*/
return new UpdateResult(true);
}
private UpdateResult UpdateToCredit(UpdatePaymentRequest request) {
if (string.IsNullOrEmpty(request.CreditCardNumber)) throw new Exception();
if (string.IsNullOrEmpty(request.CreditCardName)) throw new Exception();
if (!creaditApi.IsValidCard(request.CreditCardName)) {
return new UpdateResult(false);
}
/* クレジットカード支払い登録処理 */
return new UpdateResult(true);
}
private UpdateResult UpdateToBank(UpdatePaymentRequest request) {
switch (request.BankType) {
case BankType.ABank:
/* 銀行 A での支払い登録 */
break; b
case BankType.BBank:
/* 銀行 B での支払い登録 */
break;
case BankType.CBank:
/* 銀行 C での支払い登録 */
break;
default:
throw new ArgumentOutOfRangeException(typeof(request.BankType));
}
return new UpdateResult(true);
}
}
public class UpdatePaymentRequest {
public long AccountId { get; set; }
public PaymentType PaymentType { get; set; }
public string CreditCardNumber { get; set; }
public string CreditCardName { get; set; }
public BankType BankType { get; set; }
public string BankAccountNumber { get; set; }
}
問題点としてパッと思いつくのは
- 場合によっては利用されないフィールドがある
- UpdatePaymentRequest オブジェクトは慎重に操作しなくてはいけない
- お互いに処理内容が全くことなる処理がメソッドとして同じクラスに同居している
といったところでしょうか。
簡単に問題点を解説します。
場合によっては利用されないフィールドがある
public class BusinessLogic {
private readonly CreditApi creditApi;
private readonly BankApi bankApi;
/* 以下省略 */
このフィールドはクレジット登録をするときはcreditApiが利用されます。
銀行での登録をする場合はbankApiが利用されます。
これは逆に言えば場合によっては利用されないということです。
クラスの凝集度という指標で考えてみてもこれはよくない状態です。
UpdatePaymentRequest オブジェクトは慎重に操作しなくてはいけない
UpdatePaymentRequest は各メソッドで共通で利用されるオブジェクトです。
public class UpdatePaymentRequest{
public long AccountId { get; set; }
public PaymentType PaymentType { get; set; }
public string CreditCardNumber { get; set; }
public string CreditCardName { get; set; }
public BankType BankType { get; set; }
public string BankAccountNumber { get; set; }
}
プロパティ名に Credit や Bank とあるように支払い方法によっては利用されないプロパティが存在します。
(※ C# では get; や set; で記述した getter や setter をプロパティと呼びます)
クレジットカード登録をする場合には Bank と名の付くプロパティを操作しないように慎重にこのオブジェクトを操作する必要があります。
具体的にどのプロパティがそれぞれの処理で利用されるかがわからないという問題点もあります。
お互いに処理内容が全くことなる処理がメソッドとして同じクラスに同居している
このクラスには支払い方法登録の処理が三つ存在しています。
-
UpdateToConvenienceStoreメソッド -
UpdateToCreditメソッド -
UpdateToBankメソッド
この三つのメソッドは支払い方法を登録するという処理という点では共通していますが、処理内容自体はまったく異なるものです。
異なるものはなるべくは別のものとして定義したいところです。
三つのフェーズ
早速ポリモーフィズムを活用するようにリファクタリングをしてみましょう。
ポリモーフィズムを活用する指針として三つのフェーズに分けるとよいです。
具体的には次の三つです。
- 抽象を利用
- 抽象を生成
- 抽象を実装
利用、生成、実装、この三つにわけるようにイメージをして早速取り掛かりましょう。
抽象を実装する
まずは interface を定義します。
public interface IUpdatePaymentCommand {
UpdateResult Update();
}
この interface を実装した各コマンドを用意します。
public class UpdatePaymentToConvinenceStoreCommand : IUpdatePaymentCommand {
private readonly int accountId;
public UpdatePaymentToConvinenceStoreCommand(int accountId) {
this.accountId = accountId;
}
public UpdateResult Update() {
/*
* コンビニ支払い登録処理
*/
return new UpdateResult(true);
}
}
public class UpdatePaymentToCreditCardCommand : IUpdatePaymentCommand {
private readonly ICreditApi api;
private readonly int accountId;
private readonly string creditCardNumber;
private readonly string creditCardName;
public UpdatePaymentToCreditCardCommand(ICreditApi api, int accountId, string creditCardNumber, string creditCardName) {
if (string.IsNullOrEmpty(creditCardNumber)) throw new ArgumentNullException(typeof(creditCardNumber));
if (string.IsNullOrEmpty(creditCardName)) throw new ArgumentNullException(typeof(creditCardName));
this.api = api;
this.accountId = accountId;
this.creditCardNumber = creditCardNumber;
this.creditCardName = creditCardName;
}
public UpdateResult update() {
if (!creaditApi.IsValidCard(request.CreditCardName)) {
return new UpdateResult(false);
}
/* クレジットカード支払い登録処理 */
return new UpdateResult(true);
}
}
public class UpdatePaymentToBankCommand : IUpdatePaymentCommand {
private readonly IBankApi api;
private readonly int accountId;
private readonly BankType bankType;
private readonly strubg bankNumber;
public UpdatePaymentToBankCommand(IBankApi api, int accountId, BankType bankType, string bankNumber) {
this.api = api;
this.accountId = accountId;
this.bankType = bankType;
this.bankNumber = bankNumber;
}
public UpdateResult Update() {
switch (bankType) {
case BankType.ABank:
/* 銀行 A での支払い登録 */
break; b
case BankType.BBank:
/* 銀行 B での支払い登録 */
break;
case BankType.CBank:
/* 銀行 C での支払い登録 */
break;
default:
throw new ArgumentOutOfRangeException(typeof(request.BankType));
}
return new UpdateResult(true);
}
}
これによりお互いに関係のない処理を独立させることができました。
また UpdatePaymentRequest を「慎重に」操作する必要がなくなりました。
抽象を生成する
次に抽象を生成する部分を用意しましょう。
クラスを生成するのにメソッドで生成するパターンとクラスで生成するパターンの二種類があります。
メソッドで生成する場合は次の形です。
private IUpdatePaymentCommand CreateUpdatePaymentCommand(UpdatePaymentRequest request) {
switch (request.PaymentType) {
case PaymentType.ConvenienceStore: return new UpdatePaymentToConvinenceStoreCommand(request.AccountId);
case PaymentType.CreditCard: return new UpdatePaymentToCreditCardCommand(creditApi, request.AccountId, request.CreditCardNumber, request.CreditCardName);
case PaymentType.Bank: return new UpdatePaymentToBankCommand(bankApi, request.AccountId, request.BankType, request.BankNumber);
default: throw new ArgumentOutOfRangeException(typeof(request.PaymentType));
}
}
またメソッドはクラスに変換することが可能です。この生成部分を専用のクラスにすることもできます。
次のサンプルは専用クラスです。
public class UpdatePaymentCommandFactory {
private readonly CreditApi creditApi;
private readonly BankApi bankApi;
public UpdatePaymentCommandFactory(CreditApi creditApi, BankApi bankApi) {
this.creditApi = creditApi;
this.bankApi = bankApi;
}
public IUpdatePaymentCommand CreateUpdatePaymentCommand(UpdatePaymentRequest request) {
switch (request.PaymentType) {
case PaymentType.ConvenienceStore: return new UpdatePaymentToConvinenceStoreCommand(request.AccountId);
case PaymentType.CreditCard: return new UpdatePaymentToCreditCardCommand(creditApi, request.AccountId, request.CreditCardNumber, request.CreditCardName);
case PaymentType.Bank: return new UpdatePaymentToBankCommand(bankApi, request.AccountId, request.BankType, request.BankNumber);
default: throw new ArgumentOutOfRangeException(typeof(request.PaymentType));
}
}
}
この場合はBusinessLogicクラスは次のように変更されます。
public class BusinessLogic {
private readonly UpdatePaymentCommandFactory commandFactory;
public BusinessLogic(UpdatePaymentCommandFactory commandFactory) {
this.commandFactory = commandFactory;
}
}
結果としてcreaditCardApiやbankApiといった具体的なクラスがBusinessLogicクラスから消えました。
抽象を利用する
これまで作成した「生成」と「実装」を組み合わせて、抽象を利用してみましょう。
public class BusinessLogic {
private readonly UpdatePaymentCommandFactory commandFactory;
public BusinessLogic(UpdatePaymentCommandFactory commandFactory) {
this.commandFactory = commandFactory;
}
public UpdateResult UpdatePayment(UpdatePaymentRequest request) {
var command = commandFactory.CreateUpdateCommand(request);
return command.Update();
}
}
最初のコードと比べるとメイン処理から条件分岐が消えました。
それどころかBusinessLogicクラス全体で条件分岐がなくなっています。
このクラス自体はシンプルになり、読むのは難しくないです。
ついで、新たなコマンドを増やす必要が出来たときを考えてみると面白いことがわかります。
たとえば「仮想通貨での決済方法」を追加したときはどうなるでしょうか。
恐らくUpdatePaymentToCryptocurrencyCommandというクラスは追加されますが、この BusinessLogic クラスは変更する必要がありません。
つまり、メインの処理を変更せずにプログラムを拡張することができるのです。
これは開放/閉鎖原則と呼ばれます。
使いどころがないよ!
今回のエクササイズで利用したサンプルは、とあるケースを想定して作っています。
それは次のような MVC フレームワークのコントローラです。
public class PaymentController : Controller {
private readonly UpdatePaymentCommandFactory updateCommandFactory;
public PaymentController(UpdatePaymentCommandFactory updateCommandFactory) {
this.updateCommandFactory = updateCommandFactory;
}
[HttpPost]
public IActionResult UpdatePayment(UpdatePaymentRequestModel model) {
var paymentType = PaymentTypeHelper.Convert(model.PaymentType); // 文字列を受け取ることになるので変換
var bankType = PaymentTypeHelper.Convert(model.BankType); // 同上
// リクエストの DTO との参照を切るため詰め替え
var request = new UpdatePaymentRequest(
model.AccountId,
model.PaymentType,
model.CreditCardNumber,
model.CreditCardName,
model.BankType,
model.BankAccountNumber
);
var command = updateCommandFactory.CreateUpdateCommand(request);
var result = command.Update();
var response = new UpdateResponseModel(result);
return View(response);
}
}
コントローラでこのコードを書くべき、ということを主張したいわけではありません。
これは支払方法更新という処理であってもポリモーフィズムを活用できるという例です。
結果としてコントローラはフロントから受け取るデータを「変換することに集中」し、その処理自体はコマンドを表すオブジェクトに委譲することができました。
今の UpdatePayment メソッドはあまり詳しいことはわかりません。
しかし読み上げてみると「引数からリクエストを作り、コマンドを生成、実行、結果を View に渡す」といったとても簡単なものです。
これこそがシンプルということではないでしょうか。
トップダウンとボトムアップ
ポリモーフィズムは三段階に分かれるとしました。
- 利用
- 生成
- 実装
これまでのエクササイズでは 実装 -> 生成 -> 利用 の順序で実践しています。
これはボトムアップなアプローチです。
しかし、ポリモーフィズムを活用するときはトップダウンで考える方がよりよいです。
なぜボトムアップではなくトップダウンなのか。その理由を知るためにまずはボトムアップの問題点を見てみましょう。
ボトムアップの問題点
ボトムアップとして、まずはビジネスロジックを作成しました。
public class BusinessLogicA {
public void Execute() {
// 処理
}
}
public class BusinessLogicB {
public void Run() {
// 処理
}
}
このロジックをポリモーフィズムを活用してループで回してみましょう。
まずは interface を定義します。
public interface IBusinessLogic {
void Run? Execute? ();
}
ここで早速問題が起きました。
同じように扱いたいBusinessLogicAとBusinessLogicBとでメインの処理のメソッド名が違います。
これを解決するには次のような改修が必要です。
public interface IBusinessLogic {
void Run();
}
public class BusinessLogicA : IBusinessLogic {
public void Run() { // interface 用にメソッド追加
Execute();
}
public void Execute() {
// 処理
}
}
public class BusinessLogicB : IBusinessLogic {
public void Run() {
// 処理
}
}
他にもExecuteメソッドをRunメソッドに変更するという手もあります。
しかしどちらにしてもBusinessLogicAに修正が必要です。
トップダウン
ではトップダウンの場合はどうなるかというと、まずは次のように利用するところを記述してみます。
var logics = new List<IBusinessLogic> {
};
foreach (var logic in logics) {
logic.Run(); // IBusinessLogic には Run メソッドを作ると決める
}
この時点でIBusinessLogicに必要そうなメソッド名が決まります。
interface を定義しましょう。
public interface IBusinessLogic {
void Run();
}
では早速これを実装したクラスを作りましょう。
public class BusinessLogicA : IBusinessLogic {
public void Run() {
// 処理
}
}
public class BusinessLogicB : IBusinessLogic {
public void Run() {
// 処理
}
}
最後に利用します。
var logics = new List<IBusinessLogic> {
new BusinessLogicA(),
new BusinessLogicB()
};
foreach(var logic in logics) {
logic.Run();
}
このように抽象を利用する箇所から作成し、その実装を後回しにすると後から修正する必要がなくなりやすいです。
詳細は先送りできるところまで先送りにしておくのがポリモーフィズムのコツでしょう。
ポリモーフィズムまとめ
プログラムの複雑さは条件分岐に宿ります。
シンプルにするには条件分岐を減らすことが有効な手段です。
その条件分岐を減らす打開手段のひとつとしてポリモーフィズムが活用されます。
ポリモーフィズムを活用すると、条件分岐がメイン処理ではなくオブジェクトの生成部分に移り、メイン処理の見通しがよくなります。
ポリモーフィズムのエクササイズでサンプルにした最初のコードは愚直でした。
それに対して最後のコードはシンプルでした。
これは愚直であることが常にシンプルであるとは限らないということを表しています。
条件分岐が増えてメイン処理が複雑に見えてきたのであれば、ポリモーフィズムを活用することを検討してみましょう。
まとめ
オブジェクト指向とセットで紹介される「現実を表現する」というのは、オブジェクト指向の必要条件ではないです。
むしろオブジェクト指向に留まらず、さまざまな場面で活躍の場があると考えています。
たとえば現実の計算処理は関数で表現されることがあります。
これはオブジェクト指向でなくとも現実を表現することができるということです。
こういった表現方法はモデリングと呼ばれます。
モデリングはカプセル化をするときに活用されるため、セットで紹介されることが多いのだと私は考えています。
今回の記事では、オブジェクト指向の定義はカプセル化とポリモーフィズムによる抽象化の技法であるとしました。
この抽象化を行う目的は理解を助けるためです。
抽象化により具体的な実装が隠蔽されると全体を俯瞰できるようになります。
これにより細かいことを棚上げにしてコードを読み進めることができます。
これがオブジェクト指向のすべて、というわけではありませんが、カプセル化とポリモーフィズムに対する認識の仕方に少し変化が訪れたのではないでしょうか。
カプセル化とポリモーフィズムがもしも難しそうに見えるのであればそれはトレーニングが足りていない可能性があります。
オブジェクト指向のテクニックを使えるところではどんどん使って慣れていきましょう。
また、最後となりましたが、この記事は初学者向けの入門記事です。
オブジェクト指向の導入用としては混乱させるだけで相応しくないと考えた部分については省いています。
たとえばポリモーフィズムについては実は三種類存在します。
- アドホック多相
- パラメータ多相
- 部分型付け
この記事で触れてきたポリモーフィズムはこれらのうち、「部分型付け」だけです。
ポリモーフィズムを完全に理解するには「アドホック多相」と「パラメータ多相」という項目もキャッチアップしなくてはいけないでしょう。
(省略した理由はこの部分の実現については言語によってばらつきが多いため省略をしました)
こういった例のとおり、この記事はオブジェクト指向の導入までしかカバーしきれておりません。
もしかしたら今の段階では「わかった気」になってしまっている可能性もあります。
オブジェクト指向に対して本当の理解を得るには、実践を行ったり、学術的な考察、歴史を学ぶというステップが不可欠だと考えます。
もしもこの記事を読んだことでオブジェクト指向について興味が生まれたようでしたら、この次のステップとしてオブジェクト指向についての他の文献に触れてみることをお勧めします。
きっとさまざまな刺激を受けることになると思います。
文献によっては学術的でとても内容が難しいものがあり、挫折しそうになる可能性はあります。
しかし、もしもこの記事を読んで納得いただけたのならそれが軸となって、理解を助ける武器になるでしょう。
もしもこの記事を読んで納得いただけなかったのであれば、申し訳ないです。ただ、その納得できない理由こそが軸になるのではないかと考えます。
今後の学びの機会において、この記事が皆さまの理解の手助けになるようであれば幸いです。
あとがき
あとがきという名の言い訳または蛇足です。
https://nrslib.com/postscript-oop-iroha/