はじめに
ReduxはSingle Store、immutableなState、副作用のないReducerという3つの原則を掲げたFluxフレームワークです。しかし他のフレームワークと違って提供しているものは最小限で、とてもフルスタックとは言えない薄さです。そのためすべてにおいて定番と言える書き方が定まっているわけでもなく、どうしようか迷ってしまうことも少なくありません。その筆頭とも言えるのが 非同期処理 の扱いです。コミュニティでは今でもさまざまな方向に模索が続いていますが、よく使われているものだとredux-thunk、redux-promiseあたりでしょうか。Reduxに限定しないのであればreact-side-effectというものもあります。こちらはTwitterのモバイルウェブ版で使われていますね。どれを使っても非同期処理が可能になりますが、それはあくまで道具であって、設計の指針までは示してくれません。 問題は非同期処理をどこに書くのか、どのように書くのか、そしてどこから呼び出すべきか、です。 Reduxを使っていると次のような状況に悩んだことはないでしょうか。
- 特定のActionを待って、何か別のActionをdispatchする
- 通信処理の完了を待って、別の通信処理を開始する
- 初期化時にデータを読み込みたい
- 頻繁に発生するActionをバッファしてまとめてdispatchしたい
- 他のフレームワーク、ライブラリとうまく連携したい
React + Reduxのキレイな世界で肩身の狭い思いをするそれらのコードをどうするべきか。どうやって戦っていけばいいのか。本稿では1つの解決方法としてredux-sagaを紹介します。redux-sagaの概要と基本的な考え方についてじっくり説明し、お馴染みのredux-thunkで実装したときとコードを比較してみます。ちょっとだけ入門的なセットアップ方法やハマリポイントについて述べて、後半は実践的なredux-sagaの使い方を紹介します。
ちなみに公式リポジトリには日本語のREADMEも用意しています。とりあえず使ってみたい!という方は先にそちらに目を通してみてください。
redux-saga とは
redux-sagaはReduxで副作用を扱うためのMiddlewareです。 ・・・ちょっとこのままでは理解できませんね。このフレーズ、ライブラリの短い説明文でもあるんですが、実はあまり本質を表現できていません。というわけで自分なりの理解と言葉で説明を試みます。
redux-saga とは(仕切り直し)
redux-sagaは「タスク」という概念をReduxに持ち込むための支援ライブラリです。 ここで言うタスクというのはプロセスのような独立した実行単位で、それぞれが別々に並行して動作します。redux-sagaはこのタスクの実行環境を提供します。それに加えて非同期処理をタスクとして記述するための道具立てである 「作用(Effects)」 と非同期処理を同期的に書き下す手段も提供してくれます。作用というのはタスクを記述するためのコマンド(命令、プリミティブ)のようなもので、例えば次のようなものがあります。
-
select: Stateから必要なデータを取り出す -
put: Actionをdispatchする -
take: Actionを待つ、イベントの発生を待つ -
call: Promiseの完了を待つ -
fork: 別のタスクを開始する -
join: 別のタスクの終了を待つ - ...
これらの処理の中にはタスク内で直接実行できるものもありますが、redux-sagaに依頼することで間接的に実行します。それによって 非同期処理をcoのように同期的に書けるようにしつつ、複数のタスクを同時並行に実行する ことができます。次の図はredux-saga上で実行されるタスクのイメージです。
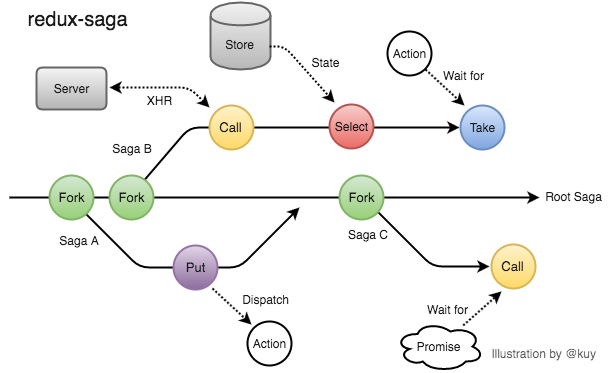
何がうれしいのか
FluxやReduxだけでもややこしいのに、さらにいろいろと新しい概念を持ち込まれて混乱してしまいますね。それでもredux-sagaを使う価値はあると思っています。
- モックのコードをたくさん書きたくない
- 小さなコードにどんどん分割できる
- 再利用可能になる
これは単純な「再利用可能」という言葉以上の意味があります。どういうことかというと再利用可能なContainerコンポーネントを開発する上で不可欠な要素だからです。Middlewareというのは本当にやっかいで気にしなければならないことが山ほどあって、さらに再利用可能なコンポーネントとして導入する際にも、どの位置にMiddlewareを組み込むか考えないといけません。一方でSagaであれば原則的にお互いに独立して動作するので自分の関心のある世界だけでコードを書くことができて、他のSagaに影響を与えることがありません。
抽象的な説明だとなかなか理解が進まないと思うので、redux-thunkで書いたコードと比較しながらredux-sagaによってどのように変わるのか見ていきましょう。
redux-thunk → redux-saga
サンプルとしてFetch APIを使った通信処理を考えてみます。
データを読み込むのは簡単なんですが、Reduxでちゃんとやろうとすると考えるべきことは少なくありません。例えば次のような点です。
- どこに通信処理を書くか
- どこから通信処理を呼び出すか
- 通信処理の状態をどう保持するか
3つ目はどちらのコードでも共通の考え方なので先に説明しておきます。
通信処理が完了するまで「読込中...」のようなメッセージを表示するためには、通信の状態をStoreで保持した上で、通信の開始・成功・失敗の3つのタイミングでActionをdispatchして状態を変化させる必要があります。この実装パターンはReduxのサンプルコードがおそらくオリジナルで、それを切り出したredux-api-middlewareというライブラリもありますが、今回はMiddlewareやredux-api-middlewareを使わずに書いています。通信の状態だけでなく、通信が正常に終了したのか、エラーによって終了したのかも合わせて格納しておくとエラーメッセージの表示に使うことができて便利です。
サンプルコードでは3つのAction Type REQUEST_USER、SUCCESS_USER、FAILURE_USER の文字列定数と、Actionオブジェクトを生成するための3つのAction Creator requestUser、successUser、failureUser は actions.js で定義済みとします。
ではredux-thunkのコードを見てみましょう。
redux-thunk
export function user(id) {
return fetch(`http://localhost:3000/users/${id}`)
.then(res => res.json())
.then(payload => { payload })
.catch(error => { error });
}
export function fetchUser(id) {
return dispatch => {
dispatch(requestUser(id));
API.user(id).then(res => {
const { payload, error } = res;
if (payload && !error) {
dispatch(successUser(payload));
} else {
dispatch(failureUser(error));
}
});
};
}
まずは処理全体の流れを確認してみます。
- (誰かが
fetchUser関数の戻り値をdispatchする) - redux-thunkのMiddlewareがdispatchされた関数を実行する
- 通信処理を開始する前に
REQUEST_USERActionをdispatchする -
API.user関数を呼び出して通信処理を開始する - 完了したら
SUCCESS_USERまたはFAILURE_USERActionをdispatchする
api.js の user 関数はユーザー情報を取得する関数です。Fetch APIはPromiseを返すので適切に処理してやる必要があります。エラーハンドリングの方法は好みで構いませんが、今回は try/catch を使用せずに戻り値で判定するスタイルを採用しています。
actions.js の fetchUser 関数はAction Creatorですが、redux-thunkに実行してもらうためにActionオブジェクトを返さずに関数を返します。redux-thunkはdispatchだけでなくgetStateもパラメータとして渡してくれますが、今回は不要なので省略しています。さきほどの通信処理の実装パターンに従って最初に REQUEST_USER Actionをdispatchして、完了または失敗したら SUCCESS_USER または FAILURE_USER Actionをdispatchします。このようにredux-thunkを使うと非同期処理のコードをAction Creatorに書くことになります。本来のAction CreatorはActionオブジェクトを生成して返すだけなので、生成したActionオブジェクトをdispatchして、さらに処理の前後にいろいろとロジックが書けてしまうのは危険な香りがしますね。導入も使い方も簡単なのでお手軽な反面、右も左も分からない状態で便利だからといって使いまくると後で地獄を見るかもしれません。控えめに使うのであれば問題ありませんが、とてもこれで複雑な通信処理を書きたいとは思えません。思ってはいけません。
それではredux-sagaで書き換えるとどうなるか見てみます。
redux-saga
function* handleRequestUser() {
while (true) {
const action = yield take(REQUEST_USER);
const { payload, error } = yield call(API.user, action.payload);
if (payload && !error) {
yield put(successUser(payload));
} else {
yield put(failureUser(error));
}
}
}
export default function* rootSaga() {
yield fork(handleRequestUser);
}
密度の高いコードになっているので気合を入れて見ていきます。まずは全体の流れから。
- redux-sagaのMiddlewareが
rootSagaタスクを起動する -
fork作用によってhandleRequestUserタスクが起動する -
take作用でREQUEST_USERActionがdispatchされるのを待つ - (誰かが
REQUEST_USERActionをdispatchする) -
call作用でAPI.user関数を呼び出して、通信処理の完了を待つ - (通信処理が完了する)
-
put作用を使ってSUCCESS_USERまたはFAILURE_USERActionをdispatchする - whileループによって3番に戻る
redux-thunkによるコードとの比較のため一連の流れのように書きましたが、実はこの処理には同時並行に走る2つの流れがあります。それがタスクです。sagas.js に定義されている2つの関数はどちらもredux-sagaのタスクです。1つずつ見ていきます。
rootSaga タスクはReduxのStoreが作成されたあと、redux-sagaのMiddlewareが起動するときに1回だけ呼び出されます。そして fork 作用を使ってredux-sagaに別タスクの起動を依頼します。前述の通り、タスク内では実際の処理は行わないため、fork 関数を呼び出して生成されるのはただのオブジェクトです。これはFluxアーキテクチャのActionオブジェクトに近い感じです。そのため次のようにしてオブジェクトの中身を見ることもできます。
console.log(fork(handleRequestUser));
これを実行すると、次のような感じのオブジェクトが生成されます。
{
Symbol<IO>: true,
FORK: {
context: ...,
fn: <func>,
args: [...]
}
}
さて、作用オブジェクトは生成しただけでは何も起きないため、redux-sagaに渡して実行してもらう必要があります。この実現のためにGenerator関数の yield を使って呼び出し側のコードに値を渡しています。「呼び出し側のコード」というのは誰のことでしょうか? それはredux-sagaが提供するタスク実行環境であるMiddlewareです。作用オブジェクトを受け取ったredux-sagaのMiddlewareは、渡された関数を新しいタスクとして起動します。これ以降、redux-sagaは2つのタスクが同時に動いている状態になります。新しく起動した handleRequestUser タスクに話を移す前にもうちょっと rootSaga タスクの「その後」を追います。
fork 作用は指定したタスクの完了を待ちません。そのため yield するとブロックせずにすぐに制御が戻ってきます。しかし rootSaga タスクには handleRequestUser タスクの起動以外にやるべきことがありません。そのため rootSaga タスク内で fork を使って起動したすべてのタスクが終了するまで待ちます。この挙動はredux-saga v0.10.0から導入された新しい実行モデルによるもので、連鎖的なタスクのキャンセルを実現するために必要でした。これは親タスク、子タスク、孫タスクがの3つがあって、親が子をフォークして、子が孫をフォークしたときに親タスクをキャンセルするとちゃんと孫タスクまでキャンセルが伝搬してくれる便利機能です。もし子タスクの完了を意図的に待ちたくないのであれば spawn 作用を使ってタスクを起動してください。
handleRequestUser タスクが起動されるとすぐに REQUEST_USER Actionを待つために take 作用を呼び出します。この「待つ」という挙動が 非同期処理を同期的に書く という特徴的なタスクの記述につながります。redux-sagaのタスクをGenerator関数で書く理由は yield によって処理の流れを一時停止するためです。この仕組みのおかげでシングルスレッドのJavaScriptで複数のタスクを立ち上げて、それぞれで特定のActionを待ったり、通信処理の結果待ちをしても処理が滞ることはありません。
REQUEST_USER Actionがdispatchされると take 作用を yield して一時停止していたコードが再開し、dispatchされたActionオブジェクトが戻り値として返ってきます。そしてようやくAPI呼び出しです。ここで call 作用を使います。これも他の作用と同様にその場で実行しないのは共通していますが、指定した関数がPromiseを返す場合、それがresolveしてから制御を返します。take 作用と似たような挙動ですね。通信処理が完了すると再び handleRequestUser タスクに制御が戻り、結果に応じてActionをdispatchします。Actionのdispatchには put 作用を使います。
これで通信処理自体は完了なのですが、もう1つだけタスクを定義するときによく使うイディオムについて説明しておきます。最初にコードを見たときに「おや?」と気付いたと思うのですが、handleRequestUser タスクは全体がwhile文による無限ループで囲まれています。その結果 put 作用でActionをdispatchしたあと、ループの先頭に戻って再び take 作用で REQUEST_USER Actionを待つことになります。つまりひたすらActionを待って通信処理をするだけのタスクになります。ここ、すごく大事なところです。これくらい極端にやるべきことを絞ってあげるとコードはとても単純でコンパクトになります。当然バグも減りますね。さらに非同期処理に常につきまとうコールバック地獄、深いネスト、突如として出現するPromiseが消えてくれます。
どう変わったか
redux-thunkとredux-sagaのそれぞれのコードについて細かく見ました。ここでちょっと別の観点から考えてみたいと思います。このセクションの冒頭で挙げた「どこに書くか」「どこから呼び出すか」についてです。
redux-thunkはAction Creatorが関数を投げるので必然的にAction Creatorに非同期処理のコードや関連するロジックを詰め込むことになります。一方でredux-sagaは非同期処理を記述する専用の仕組みであるタスクに書きます。その結果、Action Creatorは本来の姿を取り戻して、Actionオブジェクトを生成して返すだけの素直なヤツに戻ります。個人的にこの変化は小さくないと考えています。というのも、redux-thunkはdispatchされた関数をつかまえてひたすら実行するという性質上、Middlewareスタック(タマネギみたいな構造だからシェル?)の一番外側に配置する必要があります。そうでないと他のMiddlewareが関数をつかまされてエラーを吐くかもしれないからです。このような事情から関数がdispatchされたということはredux-thunk以外誰も知らないという事態に陥ります。もしredux-thunkの手前にredux-loggerか何かを置いたとしても得られるものはただの関数です。中身がどうなっているかは実行してみるまでわかりません。最悪ですね。redux-sagaの方はAction Creatorが標準的なActionオブジェクトを生成するだけなのでredux-loggerで表示できます。
さて、さきほどの通信処理はごく単純なものだったので、見慣れない書き方を強制される方が面倒であまり恩恵を受けた、という印象が薄かったかもしれません。というわけで現実のプロジェクトでも起こりそうな機能追加をやってみましょう。複雑になると真価を発揮するのがredux-sagaです。
処理を複雑にしてみる
あまり難しい処理だと理解しにくくなりますし、以前Reduxのmiddlewareを積極的に使っていくという記事で応用例として挙げたAPI呼び出しをチェインさせるをredux-thunkとredux-sagaのそれぞれで書いてみます。記事のサンプルは、ある通信処理が終わったあと、その結果を元にしてさらに通信処理を開始するというものです。今回のサンプルではユーザー情報を取得したあと、ユーザー情報に含まれる地域名を使って同じ地域に住んでいる他のユーザーを検索してサジェストする機能を追加してみます。新しく api.js に追加した searchByLocation 関数はどちらのコードでも使用します。Action TypeとかAction Creatorとかは適当に定義してあると思ってください。
redux-thunk
export function searchByLocation(id) {
return fetch(`http://localhost:3000/users/${id}/following`)
.then(res => res.json())
.then(payload => { payload })
.catch(error => { error });
}
export function fetchUser(id) {
return dispatch => {
// ユーザー情報の読み込み
dispatch(requestUser(id));
API.user(id).then(res => {
const { payload, error } = res;
if (payload && !error) {
dispatch(successUser(payload));
// チェイン: 地域名でユーザーを検索
dispatch(requestSearchByLocation(id));
API.searchByLocation(id).then(res => {
const { payload, error } = res;
if (payload && !error) {
dispatch(successSearchByLocation(payload));
} else {
dispatch(failureSearchByLocation(error));
}
});
} else {
dispatch(failureUser(error));
}
});
};
}
・・・うーむ。やりたいことはわかる。それにたぶん普通に書くとそうなる。だけど・・・みたいな気持ちになりますね。そしてここからさらにチェインさせることになったり、チェインさせるタイミングをやっぱり別のとこにする、という要望に答えていくのもつらそうですね。何よりも気持ち悪いのは fetchUser というAction Creatorを呼び出してなぜかユーザー検索まで実行されてしまうという点です。Middlewareを使って処理を分離していけばこれらの問題点を多少なりとも解消できそうですが、アプリケーション独自のDSLのようなコードが増えまくってそれはそれでつらそうです。
尚、この記事はredux-sagaをえこひいきしています。しかしredux-thunkを徹底的にこき下ろしてやろうという意図はありません。実際私もいまだに使っている部分はあります。やむを得ずredux-thunkを使い続けないといけない方もいると思うので、もし「redux-thunkでもこんな風に書くとつらさが軽減できるよ!」とかありましたらぜひコメントでお知らせ下さい。
ではredux-sagaで書いてみましょう。
redux-saga
// 追加
function* handleRequestSearchByLocation() {
while (true) {
const action = yield take(SUCCESS_USER);
const { payload, error } = yield call(API.searchByLocation, action.payload.location);
if (payload && !error) {
yield put(successSearchByLocation(payload));
} else {
yield put(failureSearchByLocation(error));
}
}
}
// 変更なし!
function* handleRequestUser() {
while (true) {
const action = yield take(REQUEST_USER);
const { payload, error } = yield call(API.user, action.payload);
if (payload && !error) {
yield put(successUser(payload));
} else {
yield put(failureUser(error));
}
}
}
export default function* rootSaga() {
yield fork(handleRequestUser);
yield fork(handleRequestSearchByLocation); // 追加
}
ご覧のように handleRequestUser タスクは変更点がありません。新しく追加された handleRequestSearchByLocation タスクは handleRequestUser タスクとほとんど同じような処理です。rootSaga タスクには handleRequestSearchByLocation タスクを起動するために fork 作用をもう1つ追加しています。ちょっと長いですが、処理の流れを書いておきます。
- redux-sagaのMiddlewareが
rootSagaタスクを起動する -
fork作用によってhandleRequestUserとhandleRequestSearchByLocationタスクが起動する - それぞれのタスクにて
take作用でREQUEST_USERとSUCCESS_USERActionがdispatchされるのを待つ - (誰かが
REQUEST_USERActionをdispatchする) -
call作用でAPI.user関数を呼び出して、通信処理の完了を待つ - (通信処理が完了する)
-
put作用を使ってSUCCESS_USERActionをdispatchする -
handleRequestSearchByLocationタスクが再開して、call作用でAPI.searchByLocation関数を呼び出して、通信処理の完了を待つ - (通信処理が完了する)
-
put作用を使ってSUCCESS_SEARCH_BY_LOCATIONActionをdispatchする - それぞれのタスクにてwhileループの先頭に戻って
takeでActionのdispatchを待つ
それぞれのタスクに着目すると単純なことしかしてないので理解しやすいのではないでしょうか。さらにこのコードを拡張してチェインを増やしたり、チェインさせる順番を入れ替えたり、何をするにしてもタスクは1つのことに集中しているので、他がなにしていようとあまり影響を受けません。この性質を積極的に利用してタスクが膨れ上がる前にガンガン切り分けていくとコードの健全性を保てます。
テストを書いてみる
redux-sagaを積極的に使いたい理由としてテストのしやすさを挙げました。まだ他人に講釈できるほどのノウハウの蓄積はないのですが、雰囲気をつかむ程度に書いてみます。テスト対象は最初の通信処理のコードにします。複雑にする前の方です。まずは単純そうな rootSaga タスクのテストから書いてみます。尚、テストコードは mocha + power-assert です。
export default function* rootSaga() {
yield fork(handleRequestUser);
}
これに対するテストコードは次のようになります。
describe('rootSaga', () => {
it('launches handleRequestUser task', () => {
const saga = rootSaga();
ret = saga.next();
assert.deepEqual(ret.value, fork(handleRequestUser));
ret = saga.next();
assert(ret.done);
});
});
タスクをフォークしているかテストする、と言うと難しそうに聞こえますが、ここでタスクというのはただのGenerator関数で、タスクが返すものはすべてただのオブジェクトである、ということを思い出しましょう。つまりredux-sagaにおけるタスクのテストは単純なオブジェクトの比較でほとんど間に合います。この rootSaga タスクはフォークしているか調べたいので fork 作用でオブジェクトを生成して比較するだけでOKです。このexpectedに指定するオブジェクトもタスクの記述に使われているEffect Creatorで生成して問題ないのも面白いポイントです。 テストするべきはこのタスクが何をしようとしているかであって、その先で何をするかは知ったこっちゃないわけです。
これだけだとテストした気にならないのでもうちょい複雑な handleRequestUser タスクの方のテストも書いてみましょう。
function* handleRequestUser() {
while (true) {
const action = yield take(REQUEST_USER);
const { payload, error } = yield call(API.user, action.payload);
if (payload && !error) {
yield put(successUser(payload));
} else {
yield put(failureUser(error));
}
}
}
通信処理が成功したか失敗したかで分岐します。そのためテストもそれぞれのケースごとに書いてみます。
describe('handleRequestUser', () => {
let saga;
beforeEach(() => {
saga = handleRequestUser();
});
it('receives fetch request and succeeds to get data', () => {
let ret = saga.next();
assert.deepEqual(ret.value, take(REQUEST_USER)); // (A')
ret = saga.next({ payload: 123 }); // (A)
assert.deepEqual(ret.value, call(API.user, 123)); // (B')
ret = saga.next({ payload: 'GOOD' }); // (B)
assert.deepEqual(ret.value, put(successUser('GOOD')));
ret = saga.next();
assert.deepEqual(ret.value, take(REQUEST_USER));
});
it('receives fetch request and fails to get data', () => {
let ret = saga.next();
assert.deepEqual(ret.value, take(REQUEST_USER));
ret = saga.next({ payload: 456 });
assert.deepEqual(ret.value, call(API.user, 456));
ret = saga.next({ error: 'WRONG' });
assert.deepEqual(ret.value, put(failureUser('WRONG')));
ret = saga.next();
assert.deepEqual(ret.value, take(REQUEST_USER));
});
});
これはGenerator関数のテストになるので慣れないうちはややこしいですね。考え方としては next() を呼ぶと最初の yield まで実行されてそのときの右辺値をラップしたものが戻り値として返ってきます。右辺値自体は value プロパティに格納されているのでそれをチェックします。
今、タスクは停止しています。これを再開するにはさらに next() を呼び出します。この next() の引数として渡したものは、タスクが再開したときに yield から返ってくる戻り値になります。つまりコード中の (A) で渡すものが (A') で期待している戻り値、というわけですね。同じように (B) で渡した通信結果のオブジェクトが (B') の call 作用の呼び出し結果になります。
最後に、通信処理が終わったら再度リクエストを受け付ける状態になっているか確認しています。タスクを同期的に書いたことで、テストコードも同期的になっています。
少々駆け足気味でしたが、なぜredux-sagaが用意した実行モデルで提供されたコマンドを使ってタスクを記述するのか理解出来たと思います。すべては予測可能でテストが容易になり、複雑なモックを組み上げる必要性を最小限にするためということです。
セットアップ
タスクの説明でいろいろとすっとばしてしまったので、ちょっとだけredux-sagaの設定についてハマりポイントと共に書いておきます。前提として、基本的には公式ドキュメントを読むのが一番です。今後大幅に変わる可能性は低そうですが、そうなったときに頼れるのはやはり公式ですしね。
redux-sagaを組み込む
サンプルコードのディレクトリを見てもらった方が手っ取り早いかもしれませんが、redux-sagaを使うときは2つのことをします。1つはStoreへのMiddleware組み込み、そしてもう1つはタスクの定義です。以下は典型的なセットアップのコードになります。redux-logger は不要であれば削除してください。
import { createStore, applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import logger from 'redux-logger';
import reducer from './reducers';
import rootSaga from './sagas';
export default function configureStore(initialState) {
const sagaMiddleware = createSagaMiddleware();
const store = createStore(
reducer,
initialState,
applyMiddleware(
sagaMiddleware, logger()
)
);
sagaMiddleware.run(rootSaga);
return store;
};
Storeの初期化タイミング
以前ハマったこととして、意図しないページでredux-sagaが起動して通信処理が始まってしまっていたことがありました。原因は store.js で横着していたからでした。
const sagaMiddleware = createSagaMiddleware();
const store = createStore(
reducer,
applyMiddleware(
sagaMiddleware, logger()
)
);
sagaMiddleware.run(rootSaga);
export default store;
configureStore 関数をエクスポートする代わりに作成したStoreをエクスポートしていますね。そして sagas.js はこんな感じ。
export default function* rootSaga() {
yield fork(loadHogeHoge);
}
初期化時に何かを読み込むタイプのタスクです。
import store from './store.js';
// ...
const el = document.getElementById('container');
if (el) {
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
);
}
もうおわかりと思いますが、以上の構成にするとProviderコンポーネントがマウントされるかどうかに関わらずStoreは初期化されており、Middlewareも初期化されてしまいます。その結果、起動時にリクエストを飛ばすタイプのタスクだと誤爆するというわけです。気を付けましょう(自戒を込めて)。
Middlewareの実行タイミング
v0.10.0 からredux-sagaの起動方法が変わりました。
const store = createStore(
reducer,
applyMiddleware(createSagaMiddleware(rootSaga))
)
こう書いていたのが、
const sagaMiddleware = createSagaMiddleware();
const store = createStore(
reducer,
initialState,
applyMiddleware(sagaMiddleware)
);
sagaMiddleware.run(rootSaga);
こうなります。初期実行タスクをMiddlewareの作成時ではなく、Storeの初期化が完了したあとに run メソッドを呼び出すことで起動します。
デバッグ
1つ1つのタスクは独立して実行されるので、やることを絞って単純に保てばデバッグツールが必要なほど複雑になることは少ないのですが、一応 redux-saga にはモニタリングツールを組み込むためのインターフェイスが用意されています。effectTriggered, effectResolved, effectRejected, effectCancelled の4つのプロパティを持つオブジェクトを createSagaMiddleware 関数のオプションとして渡します。
import sagaMonitor from './saga-monitor';
export default function configureStore(initialState) {
const sagaMiddleware = createSagaMiddleware({ sagaMonitor });
const store = createStore(...
モニターの実装はとりあえずredux-sagaのexamples/sagaMonitorを使ってみてください。尚、このモニターはデフォルトでは何も表示しないので、コード中の VERBOSE という変数を true にすると騒がしくなります。ただ、redux-logger のように常にログが垂れ流されるという使い方ではなくて、必要なときにブラウザの開発者ツールから window.$$LogSagas 関数を呼び出してタスクツリーを眺めるのがメインです。実行してみたときの様子は以下です。が、あまりかっこよくないのでD3.jsで可視化するツールを作るつもりです。

このあとのAPI呼び出しのスロットリングで紹介するサンプルにはモニターが組み込んであるのでデモから試せます。
実践 redux-saga
redux-sagaには豊富なサンプルが用意されています。なにか困ったらヒントがないか見てみるといいです。・・・が、これで終わらせてしまうのはあんまりなので別の利用例を紹介します。特に先日リリースされた 0.10.0 の新機能である eventChannel を使ったサンプルはあまり出回ってないので参考になるかもしれません。
オートコンプリート
テキストフィールドでオートコンプリートを実装するとき、単純にやるならdispatchされたActionを take で受け取って call でリクエストを発行して結果を put すればよさそうです。ただ、これは一般的な通信処理なので、素直に実装すると入力のたびにリクエストが投げられてしまってあまりよろしくありません。このサンプルでは初期のイケてないオートコンプリートからイケてるオートコンプリートに改良していく過程を書いてみます。
デモ: Autocomplete
サンプルコード: kuy/redux-saga-examples > autocomplete
初期実装
function* handleRequestSuggests() {
while (true) {
const { payload } = yield take(REQUEST_SUGGEST);
const { data, error } = yield call(API.suggest, payload);
if (data && !error) {
yield put(successSuggest({ data }));
} else {
yield put(failureSuggest({ error }));
}
}
}
export default function* rootSaga() {
yield fork(handleRequestSuggests);
}
通信処理のコードそのままですね。ちなみに実はこのコード、大きな問題を抱えています。なんと、通信処理の完了待ちをしている間にdispatchされたActionを取りこぼします。サンプルでは通信処理部分をダミーにして setTimeout を使って時間がかかっているように見せかけているのでその部分の時間を3秒とかに変更してみるとはっきりすると思います。
取りこぼし対策
というわけでまずはイケてるオートコンプリートにする前にバグを取りましょう。問題は call で API.suggest の結果を待つところです。これの呼び出しを待たずに take に戻れれば取りこぼしはなくなります。そうすると fork で新しくタスクを起動するのがよさそうですね。
function* runRequestSuggest(text) {
const { data, error } = yield call(API.suggest, text);
if (data && !error) {
yield put(successSuggest({ data }));
} else {
yield put(failureSuggest({ error }));
}
}
function* handleRequestSuggest() {
while (true) {
const { payload } = yield take(REQUEST_SUGGEST);
yield fork(runRequestSuggest, payload);
}
}
export default function* rootSaga() {
yield fork(handleRequestSuggest);
}
こんな感じになります。これまでは handleRequestSuggest タスクで通信処理までハンドリングしていましたが、 call 以降の部分を別タスクに分けました。たとえ今回みたいな問題が起きていなかったとしても、Actionを監視するタスクと通信処理をするタスクを分けるというのはよさそうです。これでガンガンリクエストが飛びますね!よかった!
別の解決方法
さて、バグは直りましたがちょっと勉強のために寄り道します。redux-sagaでタスクを書いていると上記のようなパターンが頻出するため takeEvery が用意されています。これを使って書き換えてみましょう。
import { call, put, fork, takeEvery } from 'redux-saga/effects';
function* runRequestSuggest(action) {
const { data, error } = yield call(API.suggest, action.payload);
if (data && !error) {
yield put(successSuggest({ data }));
} else {
yield put(failureSuggest({ error }));
}
}
function* handleRequestSuggest() {
yield takeEvery(REQUEST_SUGGEST, runRequestSuggest);
}
export default function* rootSaga() {
yield fork(handleRequestSuggest);
}
takeEvery は指定したActionのdispatchを待って、そのActionを引数としてタスクを起動します。以前はヘルパー関数として提供されていましたが、0.14.0 から正式な作用になりました。なお、ヘルパー版の takeEvery は廃止予定となっているので移行をおすすめします。また、作用としての takeEvery と ヘルパーの takeEvery は異なるものです。したがって、作用としての takeEvery を yield* で使用することはできません。
イケてる実装
バグも取れて、これで改善の準備が整いました。どういう動作が望ましいのか整理するためにシナリオを書いてみます。
- 1文字入力する
- すぐにリクエストは投げられない
- さらに何文字か入力する
- まだリクエストは投げられない
- 何も入力がない状態が一定時間続くとリクエストが投げられる
基本的には一定時間待ってからリクエストを開始する遅延実行タスクを定義して、入力があるたびにそれを起動することになります。ただし、入力があったときにすでに遅延実行タスクを起動しているときは、まずそれをキャンセルしてから新しいタスクを起動する必要があります。よって遅延実行タスクは最大でも1つしか並行実行されません。それではコードを見てみます。
import { delay } from 'redux-saga';
import { call, put, fork, take } from 'redux-saga/effects';
function* runRequestSuggest(text) {
const { data, error } = yield call(API.suggest, text);
if (data && !error) {
yield put(successSuggest({ data }));
} else {
yield put(failureSuggest({ error }));
}
}
function forkLater(task, ...args) {
return fork(function* () {
yield call(delay, 1000);
yield fork(task, ...args);
});
}
function* handleRequestSuggest() {
let task;
while (true) {
const { payload } = yield take(REQUEST_SUGGEST);
if (task && task.isRunning()) {
task.cancel();
}
task = yield forkLater(runRequestSuggest, payload);
}
}
export default function* rootSaga() {
yield fork(handleRequestSuggest);
}
ポイントは2つあります。1つ目のポイントは渡されたタスクを遅延実行する forkLater 関数は fork 作用を返す関数です。call 作用で delay 関数を呼び出して一定時間待ち、delay 関数が返すPromiseがresolveされたら制御が戻ってくるのでタスクを fork します。ちなみに delay 関数は redux-saga モジュールからの読み込みです。2つ目のポイントは handleRequestSuggest タスクで実行中の遅延実行タスクがあった場合はそれをキャンセルしてから起動する部分です。fork 作用を yield したときの戻り値は Taskインターフェイスを実装したオブジェクトで、起動したタスクの状態を取得したりキャンセルしたり、いろいろできます。
この実装で望みの動作は実現できるんですが、handleRequestSuggest タスクの「Actionを受け取ってリクエストを開始する」という役割がパッと見て伝わりにくくなっています。できるだけ元のタスクのようにやりたいことの意図が伝わるようなコードだといいですね。
function* handleRequestSuggest() {
while (true) {
const { payload } = yield take(REQUEST_SUGGEST);
yield fork(runRequestSuggest, payload);
}
}
オートコンプリートの機能的にはイケてるので、コードの方もイケてる実装にしてみましょう。
さらにイケてる実装
方針としては handleRequestSuggest タスクに散らばってるキャンセル処理の部分を分離します。これは1つのタスクでやることを減らして役割を明確にするという意味で積極的にやっていきたい改善です。
function* runRequestSuggest(text) {
const { data, error } = yield call(API.suggest, text);
if (data && !error) {
yield put(successSuggest({ data }));
} else {
yield put(failureSuggest({ error }));
}
}
function createLazily(msec = 1000) {
let ongoing;
return function* (task, ...args) {
if (ongoing && ongoing.isRunning()) {
ongoing.cancel();
}
ongoing = yield fork(function* () {
yield call(delay, msec);
yield fork(task, ...args);
});
}
}
function* handleRequestSuggest() {
const lazily = createLazily();
while (true) {
const { payload } = yield take(REQUEST_SUGGEST);
yield fork(lazily, runRequestSuggest, payload);
}
}
export default function* rootSaga() {
yield fork(handleRequestSuggest);
}
handleRequestSuggest タスクがとてもすっきりしました。fork(runRequestSuggest, payload) だった部分が fork(lazily, runRequestSuggest, payload) に変わるだけなので変化も少ないです。しかも英語っぽく「fork lazily」と読めるので意図も伝わりやすいかもしれません。
魔法のように遅延実行してくれる lazily タスクですがこれは createLazily 関数で生成しています。実行中のタスクを保持するためにクロージャにする必要がありました。やっていることは1つ前の実装と同じです。
これで機能も実装もイケてるものになりました!
研究課題
- 遅延実行が開始されるまで何も表示されない問題を解決する
-
takeLatestヘルパー関数を使って書き換える
API呼び出しのスロットリング
デモ: Throttle
サンプルコード: kuy/redux-saga-examples > throttle
一覧ページなどでたくさんのコンテンツを一気に読み込んで、さらに個々のコンテンツごとにリクエストを開始すると、コンテンツの数だけリクエストが同時に飛んでひどいことになりますね。サーバー負荷的に問題はなかったとしても、DoS攻撃とみなされてリクエストがブロックされる、ということもありえます。また通信処理に限らず、大量発生するActionに付随するタスクを指定した同時実行数以上は起動せずに待たせておき、完了したら順番にタスクを起動するキューが欲しくなることがあります。このサンプルではこういったタスク起動数のスロットリングをredux-sagaで実装しています。
const newId = (() => {
let n = 0;
return () => n++;
})();
function something() {
return new Promise(resolve => {
const duration = 1000 + Math.floor(Math.random() * 1500);
setTimeout(() => {
resolve({ data: duration });
}, duration);
});
}
function* runSomething(text) {
const { data, error } = yield call(something);
if (data && !error) {
yield put(successSomething({ data }));
} else {
yield put(failureSomething({ error }));
}
}
function* withThrottle(job, ...args) {
const id = newId();
yield put(newJob({ id, status: 'pending', job, args }));
}
function* handleThrottle() {
while (true) {
yield take([NEW_JOB, RUN_JOB, SUCCESS_JOB, FAILURE_JOB, INCREMENT_LIMIT]);
while (true) {
const jobs = yield select(throttleSelector.pending);
if (jobs.length === 0) {
break; // No pending jobs
}
const limit = yield select(throttleSelector.limit);
const num = yield select(throttleSelector.numOfRunning);
if (limit <= num) {
break; // No rooms to run job
}
const job = jobs[0];
const task = yield fork(function* () {
yield call(job.job, ...job.args);
yield put(successJob({ id: job.id }));
});
yield put(runJob({ id: job.id, task }));
}
}
}
function* handleRequestSomething() {
while (true) {
yield take(REQUEST_SOMETHING);
yield fork(withThrottle, runSomething);
}
}
export default function* rootSaga() {
yield fork(handleRequestSomething);
yield fork(handleThrottle);
}
オートコンプリートのサンプルは同時実行数は1で、かつ新しいタスクが来たら処理中のタスクをキャンセルしてから起動するという挙動でした。すでにタスクが起動中かどうかを判定するために状態を持つ必要があり、それをクロージャ内に保持するというアプローチです。スロットリングでも実行中のタスクを把握する必要があるため何かしらの状態を持つ必要があるという点で共通しています。せっかくなのでこのサンプルでは別のアプローチをとり、状態をタスク内部に持たず、代わりにStoreに格納します。それによってタスクの実行状況がビュー側にリアルタイムに表示できます。
上には sagas.js のコードしか示していませんが、今回は状態をStoreに持たせているので reducers.js の方も全体を理解する上では大事なので目を通してみてください。
2つのタスク
実装は大きくわけて2つのタスク、handleRequestSomething と handleThrottle に分かれます。前者は REQUEST_SOMETHING Actionのdispatchを監視して実行すべきタスクをひたすら投げます。後者はちょっと複雑です。handleRequestSomething タスクから実行依頼されたタスクをいったんキューに入れて、同時実行数を調整しながら処理していきます。スロットリングなしの実行 fork(runSomething) とスロットリングありの実行 fork(withThrottle, runSomething) ではコードの違いはわずかになるよう実装しました。
2重のwhileループ
handleThrottle タスクを見るとちょっと見慣れない2重のwhileループがあります。1つ目のループはおなじみのパターンなので大丈夫ですね。2つ目のループは実行可能なタスク数に空きがある限りジョブの実行を開始するためのものです。コードのわかりやすさを優先してwhileループにしていますが、実行可能なジョブ数と待ち状態のジョブを用意して一気に実行しても大丈夫です。
研究課題
- 複数の実行キュー
- 優先順位
認証フロー(セッション維持)
redux-sagaで認証処理をどう扱うかについて考えてみます。
実現したいことは、ユーザーがログインして、認証して、成功したら例えば画面遷移をする、失敗したらその旨を表示する、ログアウトしたらまた待ち受け状態に戻る、というような認証のライフサイクル全体です。こういった処理をサーバーサイドで実装すると、Cookieのようなトークンを持たせて飛んできたリクエストがどのユーザーによるものなのかを識別する必要がありますね。つまり処理自体はリクエスト単位になっていてぶつ切れになります。それをredux-sagaの(まぁ1人しかいないから識別する意味なんてないんだけど)タスクが一時停止可能であるという特徴を活かして、認証のライフサイクル全体を1つのタスクが張り付いて管理するように実装してみます。つまりセッションの維持にタスクを使うイメージです。
サンプルは雰囲気を掴んでもらうためのコードになります。もともとGistに書いたものです。ログインが成功すると react-router-redux を使ってダッシュボードページに移動します。
import { push } from 'react-router-redux';
function* authSaga() {
while (true) {
// ログインするまでずっと待つ
const { user, pass } = yield take(REQUEST_LOGIN);
// 認証処理の呼び出し(ここではtry-catchを使わず戻り値にエラー情報が含まれるスタイル)
const { token, error } = yield call(authorize, user, pass);
if (!token && error) {
yield put({ type: FAILURE_LOGIN, payload: error });
continue; // 認証に失敗したらリトライに備えて最初に戻る
}
// ログイン成功の処理(トークンの保存など)
yield put({ type: SUCCESS_LOGIN, payload: token });
// ログアウトするまでずっと待つ
yield take(REQUEST_LOGOUT);
// ログアウト処理(トークンのクリアなど)
yield call(SUCCESS_LOGOUT);
}
}
function* pageSaga() {
while (true) {
// ログイン成功するまでずっと待つ
yield take(SUCCESS_LOGIN);
// ダッシュボードページに移動する
yield put(push('/dashboard'));
}
}
2つのタスク
やるべきことは認証処理のライフサイクルの面倒を見ることと、ログイン成功時にページ遷移をすることの2つです。これらはもちろん1つのタスクとして実装できますが、redux-saga's way(というのがあるのかわかりませんが)に従ってきっちり役割ごとにタスクを分けて、それぞれ authSaga と pageSaga として定義しています。
ここまでの2つのサンプルでは必要に迫られてタスク内部または外部に状態を持っていました。このサンプルでは認証処理のライフサイクルがどこまで進んだかというのを状態としてとらえて、それを積極的に活用している例になります。1つの処理に1つのタスクがずっと張り付いていられるのはredux-sagaが提供するタスク実行環境のおかげです。それによってコードがとても直感的になります。
研究課題
- 複数セッションの維持
Socket.IO
ここからちょっと変わり種の紹介していきます。まずはSocket.IOとの連携です。
サンプルコード: kuy/redux-saga-chat-examples
以下、抜粋です。
function subscribe(socket) {
return eventChannel(emit => {
socket.on('users.login', ({ username }) => {
emit(addUser({ username }));
});
socket.on('users.logout', ({ username }) => {
emit(removeUser({ username }));
});
socket.on('messages.new', ({ message }) => {
emit(newMessage({ message }));
});
socket.on('disconnect', e => {
// TODO: handle
});
return () => {};
});
}
function* read(socket) {
const channel = yield call(subscribe, socket);
while (true) {
const action = yield take(channel);
yield put(action);
}
}
function* write(socket) {
while (true) {
const { payload } = yield take(`${sendMessage}`);
socket.emit('message', payload);
}
}
function* handleIO(socket) {
yield fork(read, socket);
yield fork(write, socket);
}
function* flow() {
while (true) {
let { payload } = yield take(`${login}`);
const socket = yield call(connect);
socket.emit('login', { username: payload.username });
const task = yield fork(handleIO, socket);
let action = yield take(`${logout}`);
yield cancel(task);
socket.emit('logout');
}
}
export default function* rootSaga() {
yield fork(flow);
}
Socket.IOからのメッセージの受信にeventChannelを使っています。受け取ったSocket.IOのイベントごとにReduxのActionにマッピングしてあげて put でdispatchしています。さらにタスクの連鎖的なキャンセルも使っています。
このサンプルはとりあず動かしてみた、というレベルです。Read/Writeの部分や、複数チャンネル対応、いちいちマッピングが面倒なのでイベント名をそのままAction Typesとして使うとか、Socket.IOの通信状況をモニタリングしたり、どうやって扱うべきなのかまだまだ悩んでいます。いずれそれらをライブラリという形で昇華できたらいいなぁと思ってます。
Firebase (Authentication + Realtime Database)
デモ: Miniblog
サンプルコード: kuy/redux-saga-examples > microblog
最近大幅アップデートがあったFirebaseを使って試しにredux-sagaで連携させてみたサンプルがこちらになります。題材はTwitterライクなミニブログサービスですが、実装が足りなすぎてただのチャットアプリみたいになってますね・・・。ブラウザのシークレットモードとかで複数開いて別々の名前でログインして投稿するとリアルタイムにタイムラインが更新されます。
これらのサンプルはサンプル以上の意味はありません。どうかredux-sagaでFirebaseとかSocket.IOを使うべきだ、と捉えないで下さい。なぜかというとredux-sagaは機能的にはMiddlewareのサブセットなので、redux-sagaでできることはMiddlewareでも可能です。さらにredux-sagaで作ってしまうと、プロジェクトに導入するときにredux-sagaが必須になります。Middlewareで可能なものをredux-sagaで作って、導入のハードルを上げる意味はありません。これらの機能は素直にMiddlewareかStore Enhancerレベルで実装してあげるのがいいのではないでしょうか。
PubNub
redux-saga-chat-exampleというredux-sagaとSocket.IOを組み合わせたチャットアプリを作ったら、何故かPubNubと組み合わせるにはどうすればいいの?という質問が来たのでサンプルコードを書きました。
銀の弾丸ではない
redux-sagaの使い方をいろいろな角度から見てきました。なんでもできそうに思えますが、redux-sagaにも制約はあります。すべてのMiddlewareの処理をそのまま移植できるわけではありません。例えばMiddlewareのようにActionを間引くことはできません。なので今回のサンプルにはReduxのmiddlewareを積極的に使っていくで紹介したActionをDispatchする前にブラウザの確認ダイアログを表示するをそのまま移植できませんでした。同じことをやるにはまずは別のActionをdispatchしてもらって、確認ダイアログでYesだったら本物のActionをdispatchするという感じに変更が必要になってしまいます。これだと本末転倒なので素直にMiddlewareを使った方がいいパターンです。ちなみにこの制約はRedux Middleware in Depthという記事で解説したMiddlewareを実行するタイミングに起因するものです。redux-sagaの場合、常にReducerの処理が終わった後にSagaが実行されるため、現状ではどうやっても不可能というわけです。需要があるのかわかりませんが、redux-sagaにissueを立ててみようかなと思っています。
まとめ
redux-sagaを使うことでredux-thunkやMiddlewareよりも構造化されたコードで非同期処理をタスクという実行単位で記述することができます。さらにモックを使わなければならないテストを減らして、テストしたいロジックに集中できます。また、再利用可能なコンポーネントの開発においても必要な非同期処理をredux-sagaのタスクとして提供することで、Middlewareを使った場合に起こる実行順序の問題を回避できて安全です。それでもすべてのMiddlewareをredux-sagaで置き換えることはできないので注意が必要です。