最近メモリを大量に使うJavaのプロセスに関する仕事があり、GCの知識が必要になったので調べたことをまとめておきます。調べたら色々出てくる時代ですが考えを整理するために書きました。間違った認識をしている可能性はあるのでそこはご指摘いただけると幸いです。
注: この記事は最新のGC事情を整理するものではなく、古典的?な手法について書いてます。
JVM
まずはざっくりJavaの基本的な仕組みから。
JavaのプロセスはJVMと呼ばれる仮想マシンの上で動作します。この仕組みは様々なOSで動作し、環境の差異を気にする事なくコンパイルされたJavaのコード(クラスファイル)を様々な環境で実行可能にしてくれます。

JVMにはいくつ種類がありますが、本記事はOpen JDKで用いられるHotSpot VMの場合を想定しています。(他のJVMとの違いはわからない)
ヒープ領域
Javaのプロセスを開始する際にメモリの割り当てが行われます。主に使われる領域はヒープ領域と呼ばれていて、処理を実行する過程で動的に変化するデータは基本的にここに割り当てられます。長時間同一プロセスで稼働するアプリケーションにおいてはこのヒープ領域におけるメモリ利用を最適化することが重要です。
割当てるサイズを指定する際は、具体的にはオプションで
-Xms20m -Xmx100m
と指定すると
ヒープ領域に割り当てるメモリの初期サイズ: 20MB
ヒープ領域に割り当てるメモリの最大サイズ: 100MB
という設定になります。
不要なメモリ領域
メモリの使用状況を意識する事なくアプリケーションを作っていたら、使用されなくなったゴミデータ(ガベージ)は生まれてしまいます。
この記事の中でガベージが生じる例を分かりやすく解説されていたので紹介します。
https://www.oracle.com/webfolder/technetwork/jp/javamagazine/Java-MA16-GC.pdf
例えば下記のようなクラスがあったとします
class TreeNode {
public TreeNode left, right;
public int data;
TreeNode(TreeNode l, TreeNode r, int d) {
left = l; right = r; data = d;
}
public void setLeft(TreeNode l) { left = l;}
public void setRight(TreeNode r) {right = r;}
}
下記の処理によってTreeNodeを作成します。
TreeNode left = new TreeNode(null, null, 13);
TreeNode right = new TreeNode(null, null, 19);
TreeNode root = new TreeNode(left, right, 17);
これによってrootノードがleftノードとrightノードを参照していることになります。

ここでrightノードを入れ替える処理を追加したとします。
root.setRight(new TreeNode(null, null, 21));
すると元々rightノードに入っていた19番ノードは誰からも参照されなくなり、下図のような状態になります。

この状態だとdata=19のTreeNodeのインスタンスは誰からも参照されないオブジェクトとなるため、ガベージとなりました。
使われないデータが生じ続けると無駄なメモリが溜まり続けていずれ容量の限界がきます。それを未然に防ぐためにヒープ領域の無駄なメモリを自動的に解放する仕組みとしてGC(ガベージコレクション)が必要になります。
GCとヒープ領域の役割
GCは先に述べた通り、不要になったメモリを解放するための仕組みです。
メモリ内のデータを精査し、参照があれば有効なデータとして残し、参照が無ければ不要だと判断して解放します。しかし、単純に全てのメモリ空間を精査していると効率が悪いため、データの存在期間によって内部的に分けて管理されています。
若いデータはYoung Generation、古いデータはOld Generation、事前に変化が起きにくいことが分かっているデータをPermanent Generationと呼びます。
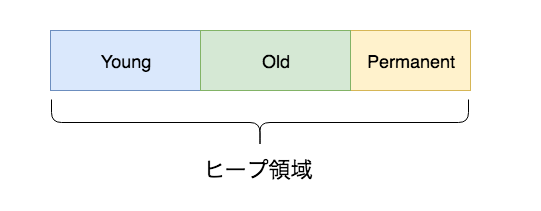
基本的にメモリへの割り当ては頻繁に発生するものの、ほとんどは長生きしないという考えから、できて間もないデータ(Young Generation)と長期的に参照されるデータ(Old Generation)とを分けています。
これにより、Young Generationに含まれるデータだけをGCの対象とすることで効率的にチェックすることができます。
また、Permanent Generationと呼ばれる領域も存在し、ここにはロードされたクラスの情報など変わらないことがある程度保証されているものが格納されます。
参考: Open JDKのドキュメント
GCのサイクル
GCのアルゴリズムは複数あります。
- Serial GC
- Pararel GC
- CMS
- G1
などなどがある(らしい)。
今回はSerial GCやParallel GCで用いられる方法について説明します。
ヒープ領域のYoung領域は下図のようにEdenとSurvivorに分かれており、それぞれの領域を上手く使ってGCが行われます。
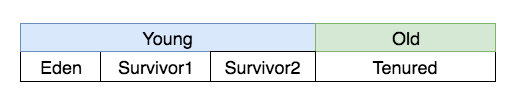
それぞれの領域はざっくり下記の役割を持っています。
-
Eden
最初に割り当てられるメモリ領域 -
Survivor1, Survivor2
GC後に解放されず、かつOldには行かないデータ(便宜的に2種類あるものに1と2をつけてるだけです) -
Tenured
Oldのこと。指定回数GCを経験して生き残ったデータOldに移行される
マイナーGC
Young世代だけを対象としたGCのことをマイナーGCと言います。下記の特徴があります。
- 処理時間が短い
- Edenがいっぱいになったら発生
- 特定回数GC対象になるとOldに移動(昇格)する
- GCの間プロセスの処理は停止(Stop the world)
言葉で説明しづらいので、図で説明します。
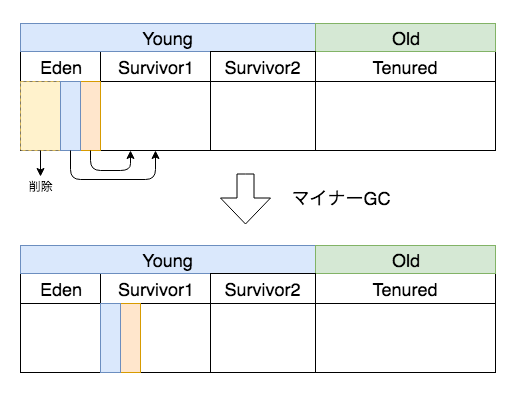
新規にメモリが割り当てられてEdenがいっぱいになると、マイナーGCが発生します。
参照がないデータは削除されますが、有効なデータはSurvivor領域にコピーされます。また、Eden領域は全て空になります。
さらにこの状態でまたEdenがいっぱいになったら再度マイナーGCが発生して下図のようになります。
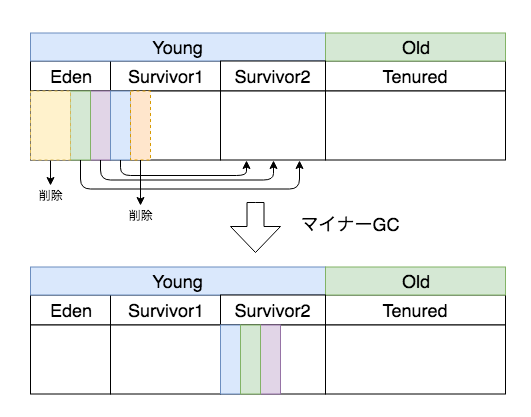
今回は GC後に全てSurvivor2に入りました。Survivor領域はどちらか空いてる方にデータをコピーされて、1と2を行き来することになります。
また、Edenと同様にSuvivor領域からも参照されないデータは削除されます。
次にOldへの昇格です。GCが発生するたびにYoungのデータはその回数が記録され、一定回数を超えたらOldに移動します。
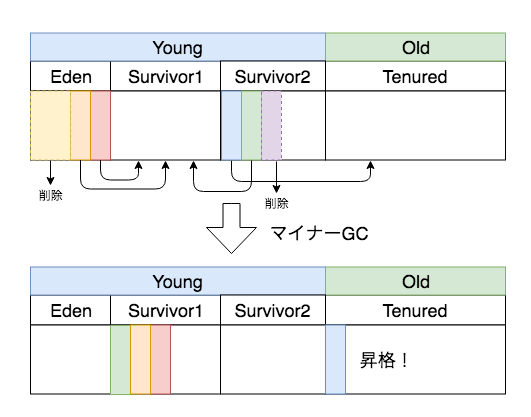
この様に何度もGCを繰り返すことで、YoungからOldへの移動が発生します。この回数はオプションで指定することができるため、Oldへ行く頻度を制御することができます。
-XX:MaxTenuringThreshold=N
FullGC
YoungからOldにデータが移る仕組みはわかりましたが、これだけだとOldの容量が常に増え続けることになり、どこかで容量の限界がきます。そこでFullGCの出番です。Oldに割り当てが失敗したタイミングでFullGCが発生し、OldとYoungを両方含めてメモリを掃除します。
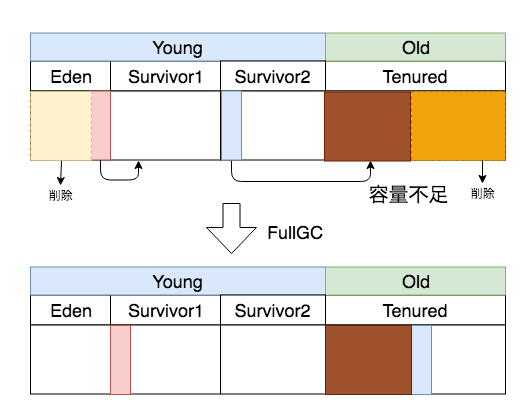
これによりOld領域で不要となった空間が解放され、Survivor領域にいたデータをコピーすることができます。
マイナーGCと同様にFullGC中もアプリケーションは停止してしまいます。しかもOldが入ってる分停止時間も長いため、メモリは極力Young領域で解放される使い方をして発生を抑えることが大事になりそうです。
まとめると
- Eden領域がいっぱいになるとマイナーGCが発生
- マイナーGCによってYoung領域を解放し、条件を満たせばOldに昇格
- Old領域がいっぱいになるとFullGCが発生
- FullGCでOld領域を解放し昇格できるスペースを確保
というサイクルであることがわかりました。
最後に
JavaにおけるGCの基本的な仕組みを整理してみました。
JVMの種類が色々あったり、記事によって言ってることが微妙に違ったりと混乱しましたがOracleとOpen JDKのソースを元にまとめたつもりです。
今ではデフォルトで選択されるGCのアルゴリズムがG1GCだったりするので、次はそれについてまとめてみようと思います。まずは基礎となっているメモリの解放メカニズムを紹介したのでした。
参考
Open JDK Document
Oracle Document
JAVAMAGAZINE / Open JDKと新しいガベージコレクター
JVMのGCアルゴリズムとチューニング