はじめに
GoのGC(Garbage Collection)を調べる中で学んだことをなるべく分かりやすく簡潔にまとめたものです。
GCのアルゴリズムやメモリ割り当てについてまとめています。
記事内で使われている「オブジェクト」という用語はGoにおいては適切でないかもしれませんが、説明のしやすさから使用しています。
概要を把握しやすいように単純化しているため細部は正確でない部分があります。
GC基本
用語集
前提となる用語です。
ルート
ルートとは、オブジェクトが到達可能か(生存しているか)を判定するための始点です。
プログラミング言語にもよりますが、基本的にメモリのスタック領域がルートになります。
フラグメンテーション
フラグメンテーションとは、使用可能なメモリが断片化し途切れ途切れになっている状態です。
フラグメンテーションになってしまうと、総量的にはメモリが空いていてもアプリケーションが必要としているメモリの大きさの区画がなく、最悪、アプリケーションが停止してしまう可能性があります。
コンパクション
コンパクションとは、フラグメンテーションを解消する機能です。
ヒープ領域での生存オブジェクトの隙間をなくして、詰めます。
STW(Stop The World)
STWとは、GCによりアプリケーションが動作停止になる現象です。
GCとは
GCとは不要になったメモリを解放する機能です。
アプリケーションは常にサーバやPCのメモリを確保しつつ何かしらの処理を行なっています。
GCは確保したメモリのうち、不要なメモリを解放します。
不要かどうかの判定は、メモリを使用しているオブジェクトが何かしら(ルート集合あるいは他のオブジェクト)から参照されているかどうかで行っています。
解放しないとメモリリーク(占有され続けてしまう状況)になってしまいます。メモリリークが積み重なると、メモリが枯渇し、アプリケーションのパフォーマンス低下や停止が発生してしまいます。
C言語などではmalloc関数とfree関数を使ってプログラマがメモリ管理する必要がありましたが、GCの登場により自動的にメモリ管理が行われるようになりました。
GCには様々なアルゴリズムが存在し、プログラミング言語ごとに採用しているアルゴリズムの種類が異なります。
GoのGCアルゴリズム
Go1.5以降で採用されているコンカレントマーク&スイープアルゴリズムと前提となるアルゴリズムについて説明します。
mark&sweep
最も基本的なGCのアルゴリズムです。
Go1.2までは純粋なmark&sweepを採用していました。
- markフェーズ(ルートから参照されているオブジェクトをマークする。)
- sweepフェーズ(ヒープ領域でマークが付いていないオブジェクトを破棄してマークを消す。)
- markフェーズとsweepフェーズを繰り返す。
オブジェクトのヘッダにフラグを付けてマークする方法もありますが、Goでは別の領域(bitmap)でマーク情報を管理します。bitmapで管理した方が高速です。
シンプルでわかりやすい仕組みである反面、いくつか問題があります。
- STWが発生
- markフェーズ中にアプリケーションが動作しているとオブジェクトの参照関係が変動してしまうから。STWしないと参照されているにもかかわらずマークされずにスイープされてしまう。
- STWが長い
- ヒープ領域全てをマーク探索するため
- sweepフェーズ後にフラグメンテーションが発生
incremental tri-color marking
incremental tri-color markingとは、mark&sweepをtri-color markingによりincremental(交互に)実現するアルゴリズムです。
mark&seepで問題だったSTW関連の問題を軽減します。
incremental GC
incremental GCとは、GCとアプリケーションの動作を交互に行う方法です。
tri-color marking
tri-color markingとは、オブジェクトを白色(未探索)と灰色(探索中)と黒色(探索済み)の3色でmark&sweepする方法です。
root scan phase➡︎アプリケーション➡︎mark phase➡︎アプリケーション・・・➡︎sweep phase➡︎アプリケーション➡︎sweep phase・・・ という流れになります。
開始前
初期値は全て白色です。
root scan phase
ルートおよびルートから直接参照できるオブジェクトを灰色にします。
GCの初めに一度だけ実行されます。
mark phase
灰色のオブジェクトの子を灰色にします。
全ての子ブジェクトを灰色にしたら、灰色のオブジェクトを全て黒色にします。
アプリケーションとmark phaseはincrementalです。
全てのオブジェクトを一気にマークするのではなく、一定数のオブジェクトをマークしたらアプリケーションスレッドに動作を戻します。
sweep phase
白色のオブジェクトを破棄し、黒色のオブジェクトを白色にして終了します。
アプリケーションとsweep phaseはincrementalです。
ライトバリア
GCとアプリケーションが交互に動作することで、マーク漏れの可能性が発生するケースがあります。
マーク漏れとはどういうことでしょうか?
例えば、オブジェクトA(灰色)からオブジェクトB(白色)が参照されていたとします。本来はオブジェクトBも灰色に塗り替えたいところですが、アプリケーションスレッドに処理を譲渡することになったとします。
アプリケーションによりオブジェクトC(黒色)からオブジェクトBへの参照が追加され、オブジェクトAからの参照が削除され、マークフェーズが再開した場合、オブジェクトCは既に探索済みのため、オブジェクトBはマークされることなくマークフェーズが終了します。
これがマーク漏れです。
マーク漏れになると、本当は参照されているのに、sweep phaseで破棄されてしまいます。
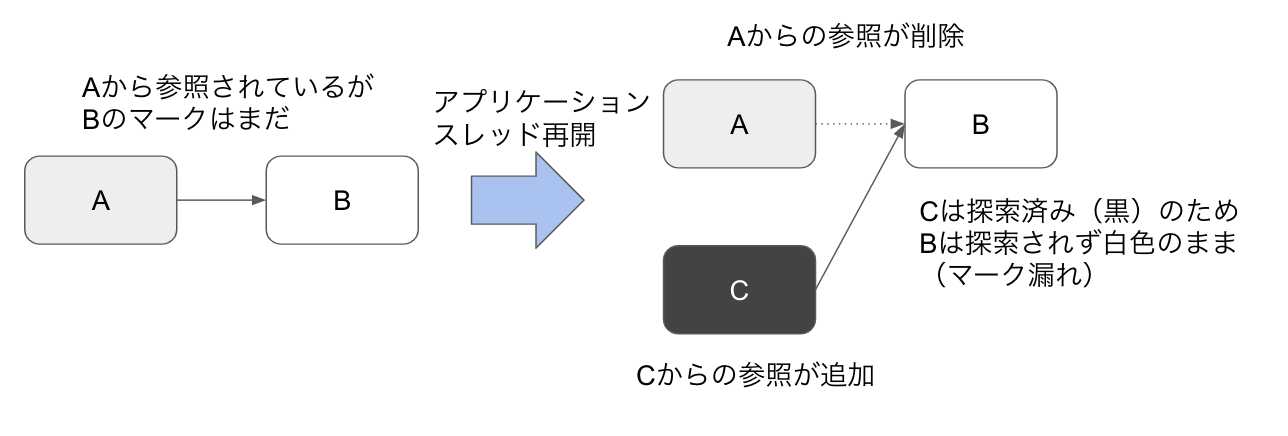
マーク漏れが発生する状況を汎用的に書くと以下の2つを同時に満たすケースです。
- 黒色オブジェクトからある白色オブジェクトへの参照が貼られる
- 全ての灰色オブジェクトから該当の白色オブジェクトへの参照が削除される
これを防ぐために、「新たに参照されるオブジェクトが白色であれば灰色にすぐ変える」ようにすればマーク漏れを防げます。
これがtri-color markingにおけるライトバリアです。
他にもやり方があるようです。
ただし、ライトバリアのオーバーヘッドにより、スループットが低下します。
concurrent mark&sweep(CMS)
Goが1.5以降から採用しているアルゴリズムです。
CMSは、tri-color markingをアプリケーションとincrementalではなくconcurrent(並列)に実行する方法です。
concurrentを実現するためにGC用のgoroutineが走ります。
全てがconcurrentではなく、アプリケーションを停止する(STW)フェーズもあります。
コンパクションは行いません。
-
Initial Mark
ルートのオブジェクトを全て灰色にマークします。
STWが発生します。
ただし、ルートオブジェクトは少ないためすぐに終了します。 -
Concurrent Mark
GC用goroutineでライトバリアしながらヒープ領域をtri-color markingでマークします。
アプリケーションスレッドとconcurrentです。 -
Mark Termination
アプリケーションスレッドがどんどん新しいオブジェクトを生成したり参照したりすると、マークが終わらない可能性があります。
そこで、マークを収束させるために新しく生成されたオブジェクトを全て黒色にします。
STWが発生します。 -
Concurrent Sweep
ヒープ領域をスイープします。
アプリケーションスレッドとconcurrentです。 -
Sweep Termination
再度Initial Markを開始したい場合にSweepが動いていたら、Sweepを停止します。
STWが発生します。
incrementalに比べてconcurrentな部分がある分、STWが減ります。
ただし、依然としてライトバリアによるスループット低下の問題は残ります。
Goのメモリ割り当て
メモリ割り当ての仕組み
Goでは変数や関数をメモリに割り当てる際に、コンパイラがスタック領域かヒープ領域への割り当てを決定します。
スタック領域への割り当てと解放は軽い処理ですが、ヒープ領域への割り当てと解放は重い処理です。
スタック領域はそれぞれCPUへの命令のみで可能なのに対して、ヒープ領域はmalloc関数(割り当て)とGC(解放)を定期的に実行する必要があるからです。
したがって、コンパイラはまずはスタック領域への割り当てが可能かを検討し、無理であればヒープ領域への割り当てを実施します。
エスケープ解析
エスケープ解析とは
エスケープ解析とは、ポインタのスコープを特定するための手法です。Goではスタック領域とヒープ領域のどちらに割り当てをするかを決定する際に利用されます。
「寿命が特定のスコープに限定できる」(例えば、変数が関数内だけ使われる)ときかつ「コンパイル時にメモリサイズが確定できる」場合はスタック領域への割り当てを実施し、無理であればヒープ領域へエスケープします。
スタック領域へなるべく割り当てられるようにできること
- ポインタを避ける
- ポインタ型はヒープ領域へ割り当てられます
- そもそもポインタは色々重い処理を伴います
- time.Timeを避ける
- time.Timeはタイムゾーン情報をポインタで持っています
- unix timeであれば整数型です
- スライスと文字列を避ける
- スライスと文字列は可変長のためメモリサイズを確定できないことからヒープ領域へ割り当てられます
- 配列であれば寿命が確定されればスタック領域へ割り当てられます
「避ける」と書きましたが、現実的には避けることが難しいケースがほとんどだと思いますので、ここら辺はあまり神経質になりすぎないほうがいいかもしれません。
エスケープ解析の結果を確認する
-gcflags '-m'で、プログラム中のメモリのヒープ割り当て(エスケープ解析の結果)を確認できます。
-mを増やすとより詳細に確認できます。
サンプルコードはこちらです。
package main
import "fmt"
func main() {
a := "hello"
fmt.Println(a)
}
変数aがヒープ領域に割り当てらるよと伝えてくれています。
$ go build -gcflags '-m' sample.go
# command-line-arguments
./sample.go:7:13: a escapes to heap
./sample.go:7:13: main ... argument does not escape
-mを増やすと出力行が明らかに増えました。
サンプルコードが薄いのであまり意味なさそうですね。
$ go build -gcflags '-m -m' sample.go
# command-line-arguments
./sample.go:5:6: cannot inline main: function too complex: cost 89 exceeds budget 80
./sample.go:7:13: a escapes to heap
./sample.go:7:13: from ... argument (arg to ...) at ./sample.go:7:13
./sample.go:7:13: from *(... argument) (indirection) at ./sample.go:7:13
./sample.go:7:13: from ... argument (passed to call[argument content escapes]) at ./sample.go:7:13
./sample.go:7:13: main ... argument does not escape
もう少しだけ難しいサンプルコード(インターフェースやら構造体やら委譲やら)を使ってみます。
package main
import "fmt"
type SampleInterfaceA interface {
Hoge() string
}
type SampleStructA struct {
}
func (a *SampleStructA) Hoge() string {
return "hoge"
}
type SampleStructB struct {
SampleInterfaceA
}
func (b *SampleStructB) Hoge() string {
return "hoge!!!"
}
func main() {
a := SampleStructA{}
fmt.Println(a.Hoge())
b := SampleStructB{}
fmt.Println(b.Hoge())
}
$ go build -gcflags '-m' main.go
# command-line-arguments
./main.go:12:6: can inline (*SampleStructA).Hoge
./main.go:20:6: can inline (*SampleStructB).Hoge
./main.go:26:20: inlining call to (*SampleStructA).Hoge
./main.go:28:20: inlining call to (*SampleStructB).Hoge
./main.go:12:7: (*SampleStructA).Hoge a does not escape
./main.go:20:7: (*SampleStructB).Hoge b does not escape
./main.go:26:20: a.Hoge() escapes to heap
./main.go:28:20: b.Hoge() escapes to heap
./main.go:26:15: main a does not escape
./main.go:26:13: main ... argument does not escape
./main.go:28:15: main b does not escape
./main.go:28:13: main ... argument does not escape
<autogenerated>:1: leaking param: .this
$ go build -gcflags '-m -m' main.go
# command-line-arguments
./main.go:12:6: can inline (*SampleStructA).Hoge as: method(*SampleStructA) func() string { return "hoge" }
./main.go:20:6: can inline (*SampleStructB).Hoge as: method(*SampleStructB) func() string { return "hoge!!!" }
./main.go:24:6: cannot inline main: function too complex: cost 188 exceeds budget 80
./main.go:26:20: inlining call to (*SampleStructA).Hoge method(*SampleStructA) func() string { return "hoge" }
./main.go:28:20: inlining call to (*SampleStructB).Hoge method(*SampleStructB) func() string { return "hoge!!!" }
./main.go:12:7: (*SampleStructA).Hoge a does not escape
./main.go:20:7: (*SampleStructB).Hoge b does not escape
./main.go:26:20: a.Hoge() escapes to heap
./main.go:26:20: from ... argument (arg to ...) at ./main.go:26:13
./main.go:26:20: from *(... argument) (indirection) at ./main.go:26:13
./main.go:26:20: from ... argument (passed to call[argument content escapes]) at ./main.go:26:13
./main.go:28:20: b.Hoge() escapes to heap
./main.go:28:20: from ... argument (arg to ...) at ./main.go:28:13
./main.go:28:20: from *(... argument) (indirection) at ./main.go:28:13
./main.go:28:20: from ... argument (passed to call[argument content escapes]) at ./main.go:28:13
./main.go:26:15: main a does not escape
./main.go:26:13: main ... argument does not escape
./main.go:28:15: main b does not escape
./main.go:28:13: main ... argument does not escape
<autogenerated>:1: leaking param: .this
<autogenerated>:1: from .this.Hoge() (receiver in indirect call) at <autogenerated>:1
GCのチューニング
Javaではたくさんのパラメータがあるみたいですが、GoではGOGCのみです。
GOGC
GOGCはGCの頻度をチューニングする環境変数パラメータです。
デフォルト値は100です。
値を大きくすると頻度は落ち、小さくすると頻度は上がります。
GOGCをoffにするとGCが発生しません。
(おまけ)その他GCアルゴリズム
GoのGCに直接的な関係はないですが、調べていく中で出てきたその他の基本的なGCもあわせてまとめておきます。
コピーGC
コピーGCは、ヒープ領域内に用意した2つの領域(From領域とTo領域)間でオブジェクトのコピーを行う手法です。
大まかな処理の流れは以下です。
- From領域を使用します。
- From領域がいっぱいになったら、From領域内で生きている(何かしらから参照されている)もののみをTo領域へコピーします。
- To領域でコンパクションを実行します。
- コピー元であるFrom領域を空にします。
- スタック領域からの参照をTo領域へ付け替えます。
- From領域とTo領域を入れ替えます。
- 1-6を繰り返します。
比較的シンプルなうえコンパクションもできるのですが、アプリケーションがヒープ領域の半分(From領域)しか使えないというデメリットがあります。
世代別GC

世代別GCは、「新しいオブジェクト」とヒープ領域に長く残っている「古いオブジェクト」をそれぞれ分類して管理する方法です。
新しく生成されたオブジェクトは短期間だけ必要であり、GCされても長く残り続きているオブジェクトはこれからも長く必要だという仮説からこの手法が確立されました。
ヒープ領域はyoung(new)領域とold領域に分割されます。
young領域はさらにeden領域とfrom(survivor 0)領域とto(survivor 1)領域に分割されます。
young領域には新しく作られたオブジェクトあるいは年齢が低いオブジェクトを割り当てます。
old領域には年齢が高いオブジェクトを割り当てます。
オブジェクトがGCされて生き残った回数を年齢として扱います。
young領域とold領域をそれぞれ年齢で世代別に管理することから、世代別GCと呼ばれています。
基本的にyoung領域だけがGCされるため、対象オブジェクトが少なくなり、高速にGCすることができます。
マイナーGC
新しく生成されたオブジェクトはeden領域に配置されます。
eden領域がいっぱいになると、コピーGCが発生し、生き残ったオブジェクトはto領域へコピーされます。
コピーが完了するとfrom領域とto領域が入れ替わります。
次に、再びeden領域がいっぱいになると、さきほどと同様にto領域へのコピーが実施されますが、同時にfrom領域でもコピーGCが発生し、to領域へのコピーが発生します。
コピーが完了したらfrom領域とto領域を入れ替えます。
したがって、GCが完了した直後はeden領域とfrom領域は必ず空の状態になります。
あとはこれの繰り返しとなります。
このGCが一回実施される毎にオブジェクトは1つ年齢をとります。
一定の回数GCされても生き残ったオブジェクト(年齢オーバー)はold領域へ移動します。
これをマイナーGCと言います。
ライトバリア(Write Barrier)
マイナーGCにおけるコピーGCで、ルートから参照されているかの判定だけでは、例えばold領域から参照されているオブジェクトも破棄してしまうことになります。
とはいえ、old領域もGC対象にしては、結局全ての領域をガベージコレクタが探索することになってしまい、世代別にした意味がなくなってしまいます。
そこで、old領域からnew領域への参照関係を別途管理する処理が必要です。
これが世代別GCのライトバリアです。
ただし、このライトバリアはそれなりに重いオーバーヘッド処理になります。
メジャーGC
old領域がいっぱいになるとGCが発生します。
この時は、マーク&スイープとコンパクションを実行します。
これをメジャーGCと言います。
old領域のGCは重い処理になるため、基本的にold領域がGCされる機会はなるべく発生させないようにします。
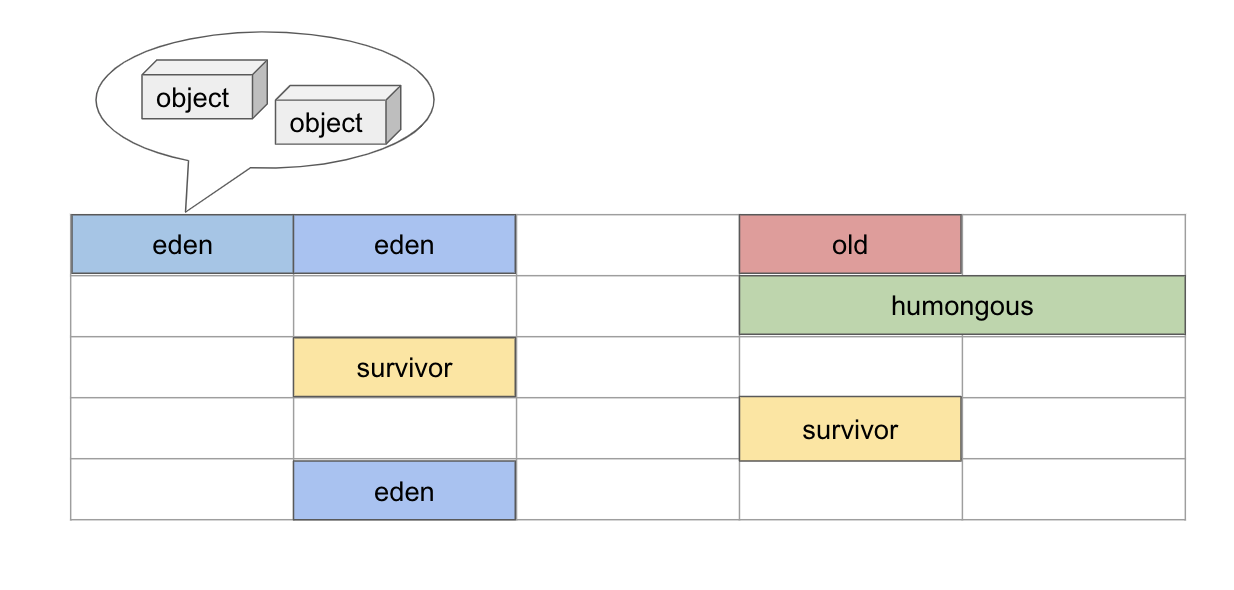
G1GC(Garbage First GC)
G1GCは、ヒープ領域をregionと呼ばれる均等に分割した領域を使って世代別GCを行うGCです。
1つのregionのサイズは数MB単位(1MB〜32MB)にチューニング可能です。
世代別GCでは、ヒープ領域を世代ごとに分割してGCの範囲を限定することで効率化を図っていました。
しかしながら、そもそものヒープ領域が大きくなると、結局は非効率でした。
そこで、ヒープ領域をregionでより詳細に分割して管理するようにします。
したがって、ヒープ領域が大きい(4GB以上)場合にG1GCは有効とされています。
世代別GCと同じように世代別でregionを分類します。
ヒープ領域はyoung領域とold領域に分類され、さらにyoung領域はeden領域とsurvivor領域に分類されます。各領域にオブジェクトが複数格納されます。
1つのRegionのサイズに収まりきらないような大きなオブジェクトはHumongous Objectとして扱われ、専用のregionに割り当てられます。
GCの大まかな流れは以下の3ステップです。
- young GC
- marking
- mixed GC
young GC
eden領域が多くなると、eden領域とsurvivor領域を対象にコピーGCが発生します。
コピー元がeden領域の場合、新しいsurvivor領域へコピーGCします。
コピー元がsurvivor領域の場合、閾値の年齢に達していたら新しいold領域へコピーGCします。そうでなければ、新しいsurvivor領域へコピーGCします。
いずれもコピー元の領域は解放します。
新しいコピー先の領域は共用するため、eden領域およびsurvivor領域は減り、空のregionが増えることになります。
young GCにより、eden領域とsurvivor領域で参照されていなかったオブジェクトは破棄され、参照されているオブジェクトのみが新しく割り当てられた領域へコピーされて残ります。
marking cycle
複数のyoung GCを繰り返した後、ヒープ領域の使用率が閾値を超すとmarking cycleが始まります。
marking cycleでは各regionの生成オブジェクト情報を取得します。
ルート領域から参照可能なものをtri-color markingでマークします。この時、アプリケーションスレッドとconcurrentです。
いったんマークが完了したら、漏れを防ぐためにアプリケーションスレッドを停止(STW)して、再度マークします。
mixed GC
mariking cycleで得た情報をもとにGCします。
対象は全てのeden領域およびsurvivor領域とマークされた生存オブジェクトの割合が閾値を下回るold領域のregion(つまりガベージが多いold領域のregion)です。
old領域が含まれるのがyoung GCとの違いです。
ガベージが多いものを優先的にGCするため、「Garbage First」と呼ばれます。ガベージが多いかどうかはmariking cycleにより判明しています。
GCの内容はyoung GCとほとんど同じです。
ただし、old領域の場合は新たなold領域を用意しそこにコピーGCし、コピー元のold領域は解放します。
old領域の不要オブジェクトがヒープ全体の閾値以下になるまで、mixed GCを繰り返します。