みなさん、こんにちは!!
こちらは「ABEJAアドベントカレンダー2020」の10日目の記事です。
2日目に続き2回目の登場ですが、また仕事関係ない話です。
11月中旬:遠方に引っ越すことが決まった
ここから、このプロジェクトは始まりました。
年内目標での引越しです。
なかなかの短期プロジェクトです。
※ちなみに転勤や転職ではなく家庭の事情です。ABEJAではフルリモートで働き続けます。
早急に物件を探さねければ
引越し目標まで1ヶ月半、時間がありません。
そして引越し先は実家のある名古屋とまでは決まっているのですが、あまり土地勘がありません。
そのため、どのあたりに住むのがいいのか?それもあまり分かりません。
まずは、賃貸検索サイトで探します。
。。。どの物件も今(横浜)よりは安いです。お得そうです。
でもどれが良いかなかなか絞り込めません。気軽に内覧行ける距離でもありません。
機械学習使えばいいんじゃね?
「お前はデータサイエンティストだろ?こんな時こそ役に立たないのか?」 そんな声がどこからか聞こえてきました。
しかも不動産のデータは私の好きなKaggleなどのデータ分析コンペでもよく取り上げられるものであり、機械学習との相性が良いデータとも言えます。
これまでの仕事やKaggleでの経験を、私生活に役立てるときが来たようです。
本編(優良物件探しAIの開発)スタート
方針
お得な物件(条件が良い割に安い)を機械学習により抽出します。
具体的には、家賃以外の物件の情報から家賃を予測します。
そして予測した価格と実際の家賃を比較して、
- 実際の価格の方が高い→損な物件
- 実際の価格の方が安い→お得な物件
と考えます。
目標
- 機械学習により抽出した物件が最終的に選ばれること
- 爆速に構築する
ちなみにネタのために機械学習で選ばれた物件を優遇して決めるようなことはしません。
妻と共に最も納得できる物件にします。
そして、引越しまで1ヶ月ちょっとしか残されていないので、モデルができてから物件を探そうと悠長なことを言ってられません。
私が機械学習モデルを作っている間にも、妻がいい物件を見つけてしまうかもしれません。
なので、爆速に構築することが求められます。
STEP1: データの収集
賃貸検索サイトからスクレイピングをしました。
無駄にデータ数を増やしたくない&サーバに負荷をかけたくないこともあり、引越し先の地域に物件にしぼりました。
ちなみに取得した情報は、
- 物件名
- 住所
- 家賃
- 敷金・礼金
- 面積
- 築年数
- 間取り
- 最寄駅情報(何駅徒歩何分)
- 駐車場
- 部屋の方角
- 構造(木造、鉄筋コンクリート等)
- 設備(独立洗面台、浴室乾燥機、3口コンロ、、、等)
あたりです。
本題ではないので詳細は省きますが、取得したい情報ごとにxpathを指定し、Scrapyによりデータは収集しています。
xpath_params = [
# 名前
{
"name": "title",
"xpath": "//h1[@class='section_h1-header-title']/text()",
"func": "get"
},
# 家賃
{
"name": "price",
"xpath": "//span[@class='property_view_note-emphasis']/text()",
"func": "get"
},
# 専有面積
{
"name": "area",
"xpath": "//table[@class='property_view_table']/tr/th[text()='専有面積']/following-sibling::td[1]/text()",
"func": "get"
},
....
]
STEP2: モデルの構築
STEP1で取得した物件情報を元に機械学習モデルを作成します。
データの分割
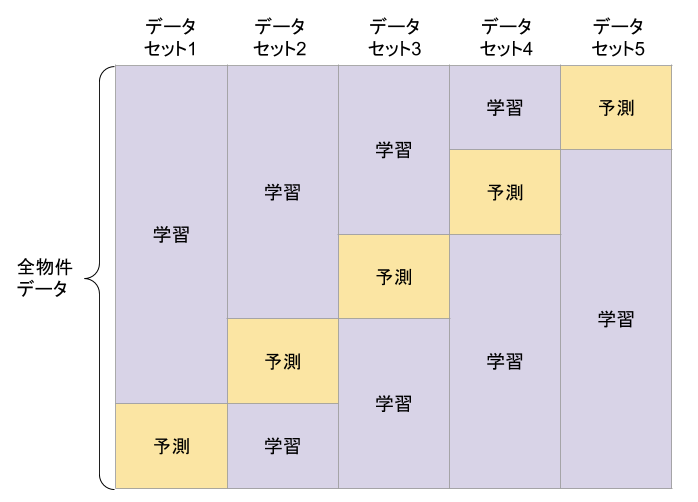
全てのデータに対して、お得度合い(実際の家賃と予測家賃の差)を確認するために、CrossValidationにおけるOut of Fold(OOF)を活用します。
今回は5分割でCrossValidationを行います。
下の図のとおり、全物件データを5回分割を行い、それぞれの学習データでモデルの学習を行い、予測対象のデータに対して価格の予測を行った結果を保存します。
これにより、全データの予測結果が手に入ります。
前処理・特徴量
機械学習モデルを作ったとしても精度が悪いと、お得物件かそうでないかがランダムで決まることになってしまいます。
それでは全く役に立たないので、それなりの精度は必要です。
そして精度に最も影響しうるのが、この部分と言っても過言ではないので、短時間で真面目にやります。
前処理
スクレイピングでとってきたデータなこともあり、主に以下のような処理を行いました。
- 予測対象である家賃が欠損 or 明らかに外れ値であるものデータを消去
- 幸い地方で言うほど高価格の物件はなかったので、すぐ取り除ける程度の量でした
- 重複物件の削除
- 物件の名前が違っても中身が一緒の物件がところどころにありました
- 「家賃」「敷地面積」「築年数」「住所」が全て同じ物件は重複しているものとして1つに絞りました
- 築年数や駐車場、敷金・礼金などから数値を抽出
- 「築10年」→「10」
- 「新築」→「0」
- 「築99年以上」→「99」
- 「駐車場無料」→「0」
特徴量作成
自身のKagglerとしての経験と勘から、特に精度が上がりそうなところとして、下記の特徴を作成しました。
- 数値データをそのまま
- 築年数、面積、各種設備のOne-Hot-Encoding
- カテゴリデータに対してのTargetEncoding
- 間取り、構造、最寄駅、部屋の方角
- 最寄り駅まで歩く時間 / 最寄りバス停まで歩く時間
- カテゴリデータでGroupByした時の連続値データの統計量
- 例:間取りあたりの面積の最小値・最大値・平均・分散
- カテゴリデータでGroupByした連続値の平均との差分
- 例:最寄り駅あたりの面積の平均と、対象物件の面積の差分・比率
また、特徴量から敷金や礼金は除きました。
敷金や礼金は家賃の1ヶ月分に設定されている物件が多く、家賃を予測する際にはLeakage1になってしまうためです。
モデル
モデルは使い慣れていて、精度・速度ともに優れているという理由でLightGBMを使いました。
回帰問題として、ObjectiveはRMSEで学習させました。
価格差が大きく自身が住む家がそこまで高くない場合は、RMSEよりも目的変数の対数で最適化するRMSLEを使ったほうが良いことも多いですが、今回は地域的にそこまで高い物件はない&一部は例外的に除いたことから、RMSEを用いました。
(東京都でやる場合はRMSEとしたほうがいいかもしれません)
学習結果
RMSEで最適化しましたが、どの程度の精度が出ているか直感的に理解するために、ここではMAE(MeanAbsoluteError)を載せています。
単位は万円なので、平均して家賃、約5000円の誤差という結果です。まぁまぁではないでしょうか!!
| 指標 | 精度 |
|---|---|
| MAE | 0.51167 |
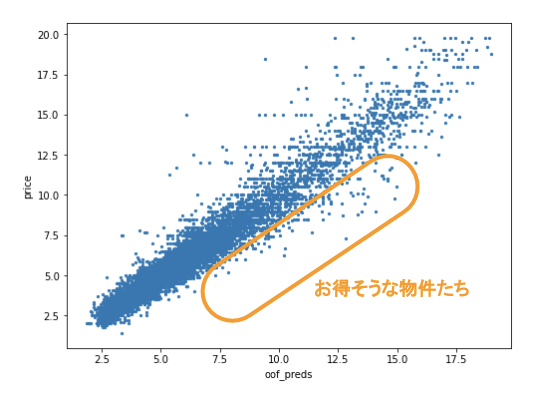
次に予測価格と実際の家賃との関係を見てみましょう。縦軸が実際の家賃、横軸が予測した価格です。
これを見ても、額が大きいほどブレはありますが、概ね予測できていることがわかるかと思います。
そしてお得な物件は予測価格よりも実際の家賃のほうが安い、すなわち右下らへんの点の物件になります。
Feature Importance
FeatureImportanceとは、どんな特徴が学習に寄与したのかを表すものです。
決定木をベースとしたモデルではこういった特長の貢献度がすぐに見れるのも魅力の一つです。
TOP10を見てみましょう。
| feature | gain | |
|---|---|---|
| 0 | 面積 | 285592 |
| 1 | diff_near_subway_station_agg_area_mean(最寄駅毎の平均面積との差) | 72212 |
| 2 | diff_structure_agg_area_mean(構造毎の平均面積との差) | 63294 |
| 3 | 洗面所独立 | 31446 |
| 4 | diff_structure_agg_build_age_mean(構造毎の平均築年数との差分) | 30752 |
| 5 | diff_direct_agg_area_mean(部屋の方角毎の平均面積との差分) | 15244 |
| 6 | rel_near_subway_station_agg_area_mean(最寄駅毎の平均面積との比率) | 14853 |
| 7 | rel_structure_agg_build_age_mean(構造毎の平均築年数との比率) | 14532 |
| 8 | 浴室乾燥機 | 12920 |
| 9 | rel_near_subway_station_agg_build_age_mean(最寄駅毎の平均築年数との比率) | 11597 |
| 10 | システムキッチン | 11259 |
これをみると「面積」「築年数」が大きく影響していて、特に「最寄駅」や「構造」毎での比較が効いているというのがわかります。またそれ以外に「洗面所独立」「浴室乾燥機」「システムキッチン」が上位に来ているのも面白いですね。
たしかにこれらの条件めちゃくちゃ大事ですよね。つまり納得感がある結果であり、ある程度学習がうまくいってそうなことが、ここからもわかりそうです。
お得物件を抽出する
今回一番大事なのは精度ではありません。**「本当にお得な物件が抽出できるか?」**です。
ということで、実際に予測した値 - 実際の家賃が大きくなる物件をリストアップします。
ただし、この時お得だからなんでもいいか?と言われるとそうではありません。
例えば、いくらお得だからって家賃が100万円の物件には私では住めません。。自分の求める条件の範囲内でお得な物件である必要があります。
そこで条件を指定した上で、上位からリストアップします。
(条件の設定をpandasで自由に簡単にできてしまうのも良いですね)
こんな感じで表示します。
(URLと物件名は架空です)
Top 1: マンションABEJA
https://hogehoge.jp?id=1001
Top 2: メゾン アドベントカレンダー
https://hogehoge.jp?id=12301
Top 3: カーサQiita
https://hogehoge.jp?id=6001
・・・・
あとは上から人間が物件を見ていくだけです。簡単ですね!!!
ほんとにお得な物件が抽出できたのか?
実際にTOP10をチェックした時の話です。
「あれ?聞いたことある物件な気がする...??」
まず上位を見たときの最初の感想がこれでした。
なんでだろうと思い、考えます。そしてわかりました。
何とそれは妻が良さげな物件としてリストアップしていたものでした。
しかも上位5件のうち3件がそれに該当しました。
これはお得な物件を抽出できているといえそうです。
妻がいればAIいらないんじゃないか?
ここでふとした疑問が頭をよぎります。
「妻のオススメ物件と同じものが出てくるだけであれば、このAIいらないんじゃないか?」
たしかに妻が良いと思った物件とほぼ同じであれば、わざわざ機械学習をして...って要らないのかもしれません。
いや、しかし、無駄なわけはない....作って良かった理由を探します。
物件が更新された時の再チェックが簡単
新しい物件が掲載されたのを、検索サイトで調べるとき、前に見た物件も条件にひっかかることがあります。
そして、どれが更新されたのか分かりません。それに比べ、今回のモデルではスクレイピングからやり直せば、新しいデータでのお得物件を出すことが簡単にできます。
いやしかし、検索サイトで新着順にすれば良いだけかもしれません......
手間が省ける
一度作ってしまえば自動で良い物件がないかいつでも見れます。
人件費削減ってやつですね。これは良いです。
家庭の自由時間が増えます、大事ですね。
抜け漏れなくお得物件が抽出できる
上で5件のうち3件は妻が推していた物件と書きました。
逆に言うと残り2件は妻の推しに入っていない物件です。これがお得な物件であれば、抜け漏れていた良い物件を見つけれたということになります。
妻に実際聞いてみると、1件はたしかに良さそう、もう1件は他の条件が微妙とのことでした。
少なからず良い物件を見つけるのに役立ちそうです。
お得と判定されたけど微妙だった物件
お得な物件一覧の中にはお得とは言えない微妙な物件もいくつか存在しました。
それらの特徴としては、特徴量に使った物件情報には含まれていないものでした。
実際にあったものとしては、
- 家の中に階段が2つあり、3階建である
- 小さな子供がいる我が家では怖くて、かなりの減点ポイントでした
- 定期借家だった
- 定期借家の情報は事前に取れましたが、時々書かれている場所が違って、取れていないものがありました
- 壁紙が絶妙にダサい
等のものでした。
これらを見てみると、スクレイピングで得た物件の情報からは分からないものばかりでした。
間取りや室内の画像データとかを使えば多少分かるようになるかもしれませんが、特徴量として入れた情報しか加味できない。当たり前ではありますが、これは機械学習モデルの弱点といえそうです。
もう一つの弱点
途中で、別の物件サイトにしか載っていない物件が候補にあがりました。
そのサイトでもう一回xpathを調べてスクレイピングをしないと、見つけれません。
急いでxpathを調べているうちに、そちらのサイトの物件は微妙だということがわかり、幸い作業が増えることはありませんでした。
しかし今回のモデルの性質上、サイトが変わるたびにスクレイピングから前処理まで大きく変わってしまうので、作業が発生してしまいます。
人間であれば自由にサイトを跨いで検索できるのに対して、この部分はAIの弱点だと感じました。
最終的に機械学習モデルにより見つけた物件に決めたのか?
残念ながら、モデルが見つけた物件にはなりませんでした。
理由としては、最終的に決めた物件は「実家に徒歩でいける」という点が大きかったのと、「公園が近い」「近くに幼稚園がある」といった当初取得した物件情報以外のところでのメリットがあったからです。
この辺りも最初から考慮に入れた上でモデルを作っていたら、機械学習が見つけた物件に住んでいたのかもしれません。
そして、これは機械学習そのものというより、要件を決めた私側に原因がありそうです。(ごめんねLightGBM)
最後に
目標は達成できませんでしたが、何はともあれ満足いく物件を見つけれたので良かったです。
私はダメでしたが、機械学習で物件を決めるというのは現実的に可能そうというのも分かりました。
この記事を読んだ誰かがリベンジしてくれると願っています。
話は変わりますが、今回会社には家庭の事情を考慮いただき、遠方在住でのフルリモートを認めていただきました。
しかも私が相談してからすぐに意思決定をいただき、おかげで物件探しをはじめとした引越しの用意をすぐに始めることができました。
柔軟かつスピード感ある対応をしていただいた会社には感謝しかありません。
こんな優しい会社ABEJAでは一緒に仕事をする仲間を募集しています!!
興味がある方がいましたら、カジュアル面談からでも、気軽にご連絡ください!!
(私も新しい家からオンラインで話せるのを楽しみにしてます)
【募集職種一覧はこちら!】
-
目的変数の情報が説明変数にも混ざってカンニングのような状態で教師あり学習を行うこと ↩