「それってあなたの感想ですよね」
.....
けど、これじゃ勝てないよね、現場はそんな単純じゃないですよね
そんなあなたのデザインにひと摘みのエビデンスを添える手法をいくつかお伝えします。
そうです、ユーザーテストです。
.....まだ閉じないで...まだ諦めないでほしい。
いつものじゃなくて定量的に測るユーザーテストです。
タイトルのような主観的な感想を、客観的な数値で倒すことができるのです。
ここではプロダクトのデザイン(見た目やUI設計)をどう定量的にテストしていこうかというお話をします。
はじめに定量的なユーザーテストをすることで見える世界をお伝えするので、その後はこういう場面ではこう倒すといったような How to を列挙しようと思います。
エンジニアの皆々様はテストを書きますよね。
デザインのテストは疎かにしてませんか?
ユーザーテストをすることで実現できること
たとえば YouTube のデザイン。
 これは世界屈指の YouTube 開発チームが寄ってたかって考え抜いて、現在のデザインがあるはずです。
このように考え抜かれたデザインは、ありがたいことに誰でも使えるようにライブラリ化されて公開されることもあります。
これは世界屈指の YouTube 開発チームが寄ってたかって考え抜いて、現在のデザインがあるはずです。
このように考え抜かれたデザインは、ありがたいことに誰でも使えるようにライブラリ化されて公開されることもあります。
たとえば Material Design。

Material Design を使えば、天才たちが何時間もかけて作り出したノウハウをものの数秒で使いこなすことができるようになります。
ユーザーテストをする工程もパスして良いものが作れるということです。
ここで満足しても良いのですが、人が作ったものを使うだけじゃなくて、生み出したいと思う人はもっと学ぶ必要があります。
ユーザーテストを行うということは時間をかけてノウハウを作り出すということです。
これが大事な作業だと思える方はユーザーテストを会得して、良いものを作成していきましょう
定量的ユーザーテストで調べられること
こんなことが定量的(一部定性的)にわかるようになります
- ユーザービリティ
- 使いづらさ
- 分かりづらさ
- 間違いの多さ
- 見た目
- デザイン・色
- UIの配置
- ユーザーの感情・印象
ユーザービリティってUX?、UIを見たユーザーの印象テスト?
いろんな言葉でごちゃごちゃしていることと思います。
ここで一つUXとユーザービリティについて整理してみましょう
UXとユーザービリティ
このあたりで出てくる単語の中でも、UXは最上位の概念です。

また、UXはシーンによって呼び名を変えることがあります。
帽子を買おうとしてる人が Amazon で帽子を買ったとして、届くまでにどんな体験があるでしょうか
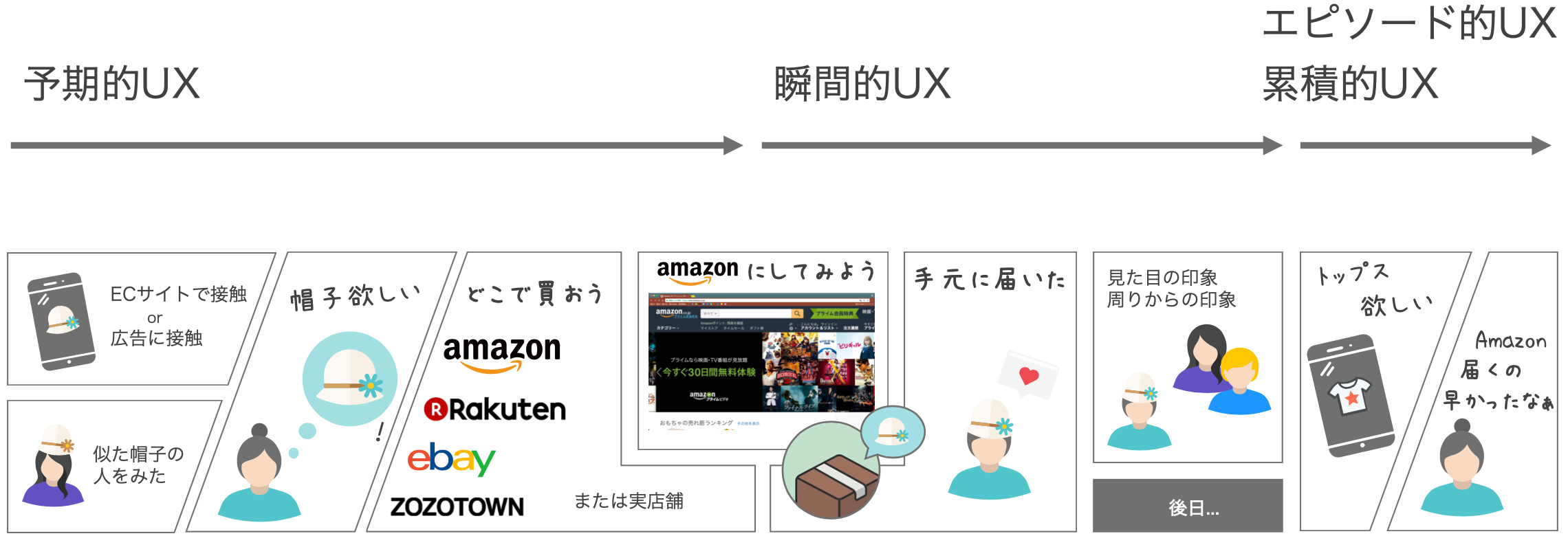
このシーンの中でUIが出てくるのは Amazon で商品を選んでるところだけです。
それ以外はプロダクトデザイナー/オーナーが設計する部分であって、この記事のテスト対象ではありません。
そんな瞬間的な部分にどうしてテストが必要なのか
プロダクトのUXという巨大なフローをUIごときがぶった切ってはダメだからです。
帽子を探したいときのページネーション、カートに入れるボタンの位置、支払いの入力フォーム、どれをとっても使いづらく・分かりづらく・間違いが起きてはダメなのです。
返せば、ユーザービリティ/ユーザー印象がわるいとあなたの持ってる素敵なアイデアはそこでしんでしまいます。
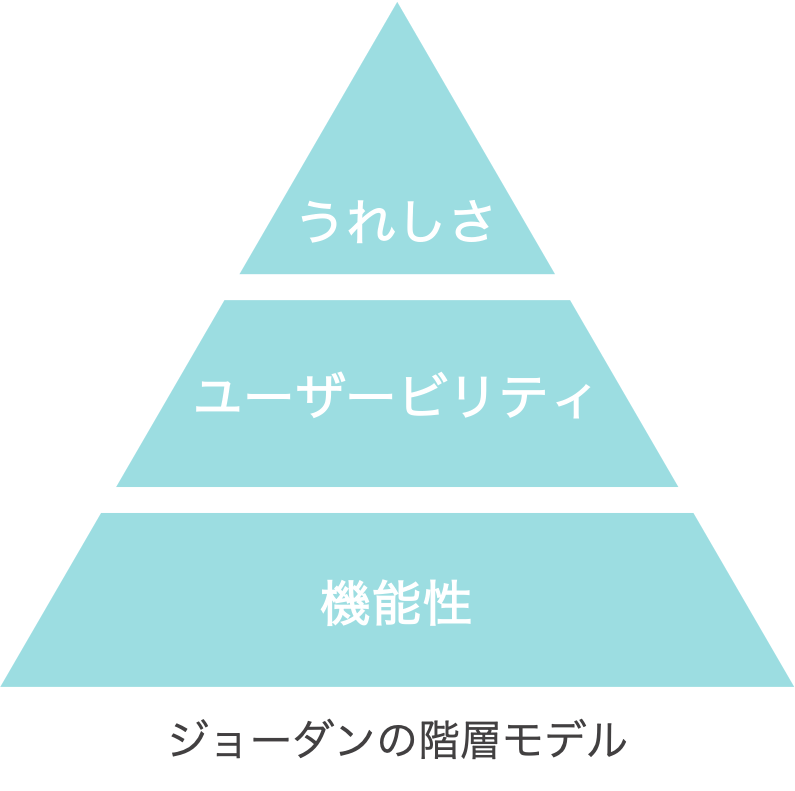
ジョーダンの階層モデルでも "うれしさ" という概念はユーザービリティの上に乗るものとして君臨しています。
このへんの定義に興味があれば↓の本を読んでみると良いでしょう
UX原論 ユーザビリティからUXへ
www.amazon.co.jp/dp/B087JQC9QW
定量的ユーザーテストをはじめよう
やる意義は伝わったでしょうか
ここから下はケースバイケースに合わせて、テストする手法を列挙していきます。
長くなるので、ここで一旦ひとやすみ。
LGTM ボタンを押して、シェアをして、仲間を増やしましょう(切実)
(正直ここまで読んでくれたら十分です、必要と感じたときに後半を見て使ってみましょう)
ユーザーテストの準備に本腰を入れないで
ユーザーテストは5人で十分
もしかしたらたまに聞いたことがあるかもしれません。
まずは5人だけ集めましょう、なんなら身近で結構です。
Why You Only Need to Test with 5 Users
https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/
この Nielsen Norman Group の記事では5人で十分な理由として問題発見割合を提示しています。
- ユーザー1名が発見できる問題の割合 L は 31% と言われている
- n 人のユーザーが発見できる問題の割合 N は 以下の式になる
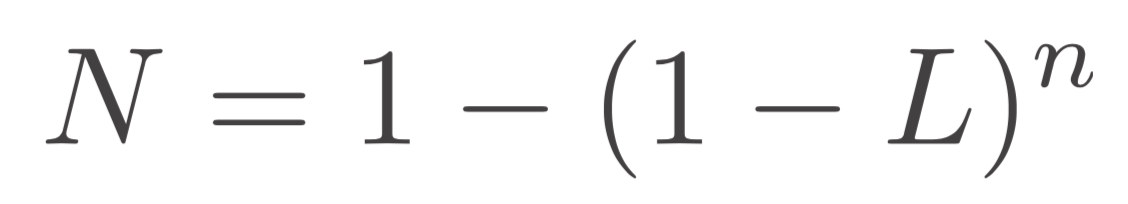
L は 0.31 で定数なので、この式を N vs n としてグラフにすると以下のようなグラフになる
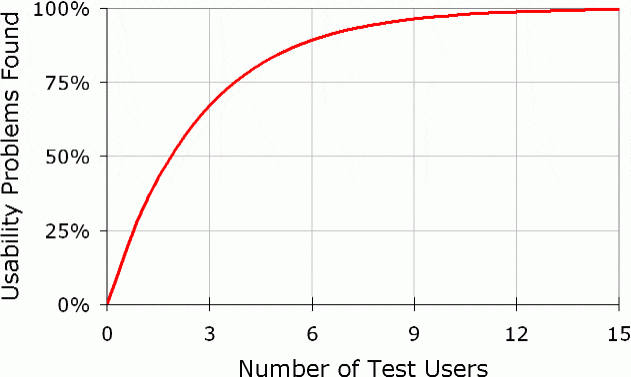
5人のユーザーでテストした場合(n = 5)、N は 0.84 になります。
ここから言えることは、8割の問題を5人のユーザーで発見することができるし、さらに人数を増やしても、問題発見の割合は飛躍的に増えることはないということです。
仮に10人のユーザーがいた場合、先に5人でテストを行って、見つかった問題を修正した後にまた別の5人でテストを行ったほうが問題発見の効率が良いのです。
ユーザーテストをやるタイミング
形成的アプローチと総括的アプローチというものがあります。
-
形成的アプローチは Unit テスト -
総括的アプローチは E2E テストのようなイメージです
形成的アプローチ
小さなUIパーツの性能を評価したり、フロントエンドなら1つのコンポーネント単位で評価します。

総括的アプローチ
システムが完成したり、ゲームだったら1ステージ完成したあたりで通しのテストをします。
すでに完成されてる他人のデザインと比較したい場合もこっちです。

〇〇を調べるには□□と言う感じで紹介します。
それぞれやり方を見ていきましょう。
定量的ユーザーテストの計測の仕方
定量的ユーザーテストで行うことのメインは比較です。
デザインA、デザインB、デザインC… とあったとき、その中でどれが一番良いデザインかを決めるために行います。
自分を疑え!と言っておいてなんですが、一旦は自分が信じるデザインでプロトタイプを作成する必要があります。
その後は、どれが正しいか定量的に評価します。
世の中にすでにあるデザインと比較して、良し悪しを比べても良いです。
また、以下から出てくるタスクという言葉は、ユーザーテストの1つのタスクのことを指します。
たとえば、「会員登録してください」とか、「購入画面で商品をキャンセルしてください」といったものが該当します。
1. ユーザービリティを計測する
計測のときはスマホのカメラや作業しているPCやスマホ画面の録画をすると、後々の計測に役立ちます。
1−1. 使いづらさ・分かりづらさを計測する
これはカウントするだけ、とても簡単です。
- タスク時間:タスクにかかった時間を計測
- 効率:タスクとは関係ない操作・処理がどれくらいあったか
この2つをカウント・計測します。
もちろんその他に使いづらさの指標になりそうなデータがあれば追加します。
カウントするだけで使いづらい/分かりづらいがわかるの?と感じるかと思います。
最終的に出てくるアウトプットは下の図のようなデータとなります。
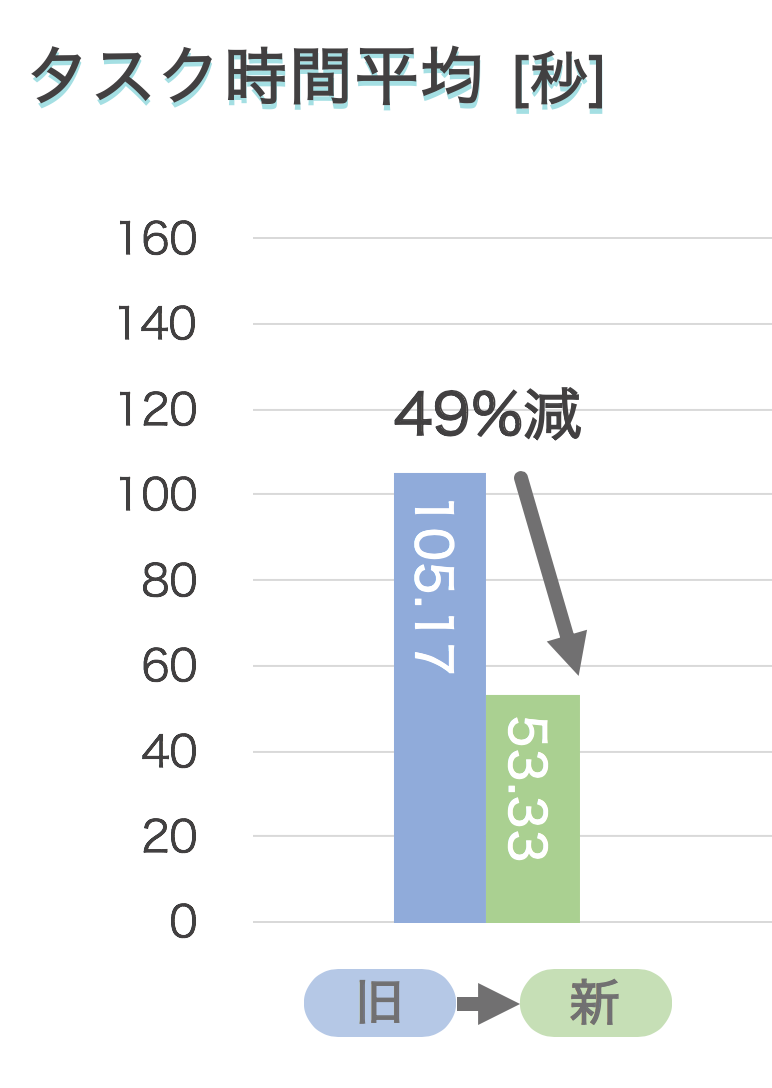
ここでの例は旧デザインから新デザインに変更しました、といったシチュエーションです。
このとき、新規ユーザー登録までにかかる時間を 49% 減らすことができました。
と言ったようなデータの見える化ができます。
至って単純ですが、「今のシステムは使いづらかったですか?」→ Yes / No というような評価よりはるかに情報量が多く、説得力も増します。
効率でも同じように、タスクをクリアする前のタップ数(クリック数)が xx% 減りました。
など言えるようになります。
どうですか? タイトルのような人をだんだん倒せそうな気がしてきませんか?
1−2. 間違いの多さを計測する
-
エラー:タスクを行うにあたって間違えた数がどれくらいあったか -
迷い度:タスクを行うにあたってどのくらい迷う要因があったか
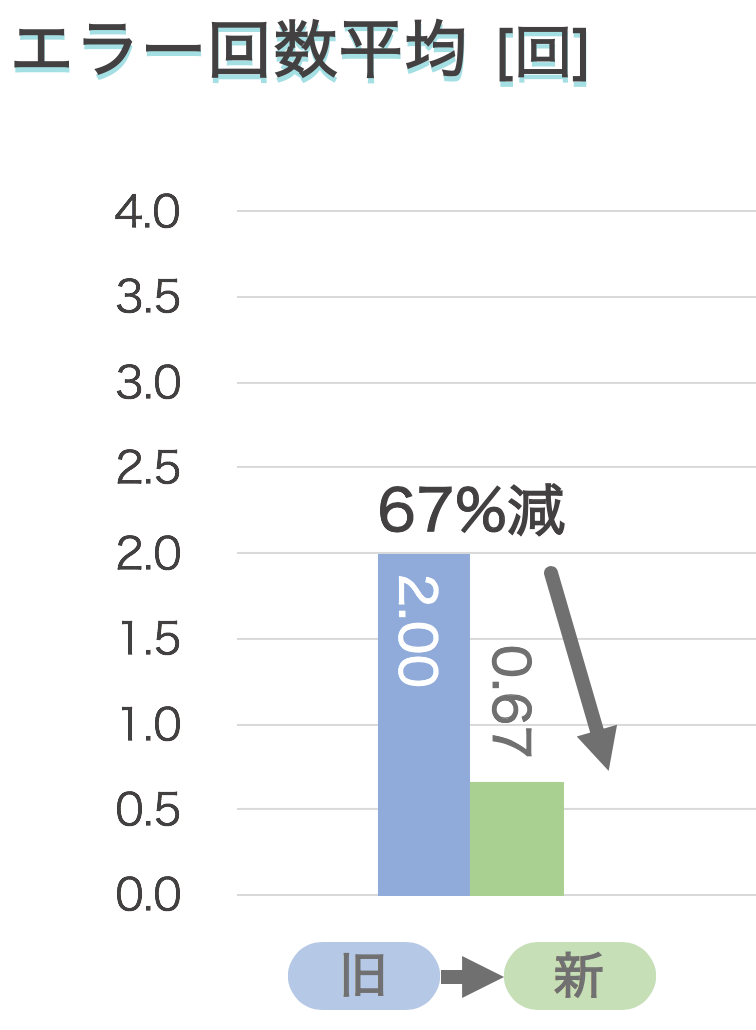
エラーは 1−1 と同じ要領でカウントしてグラフ化するだけです。
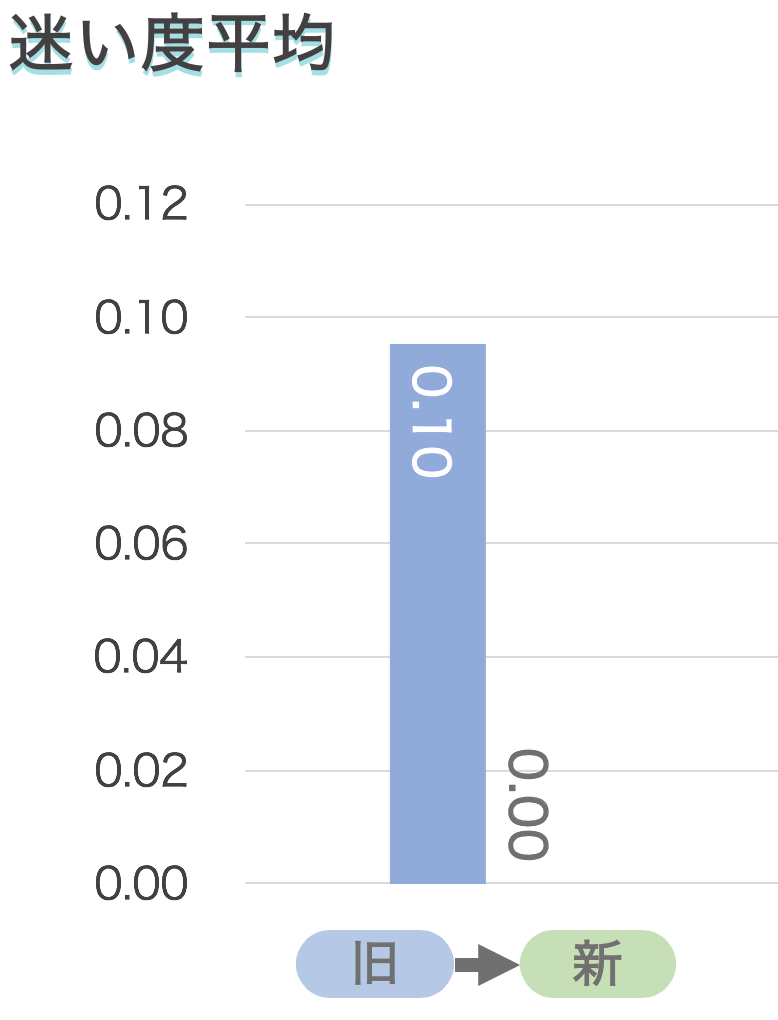
そして、迷い度は目的の画面に行くまでどのような軌跡をたどったかにて求めます。
以下のようにして求めます。
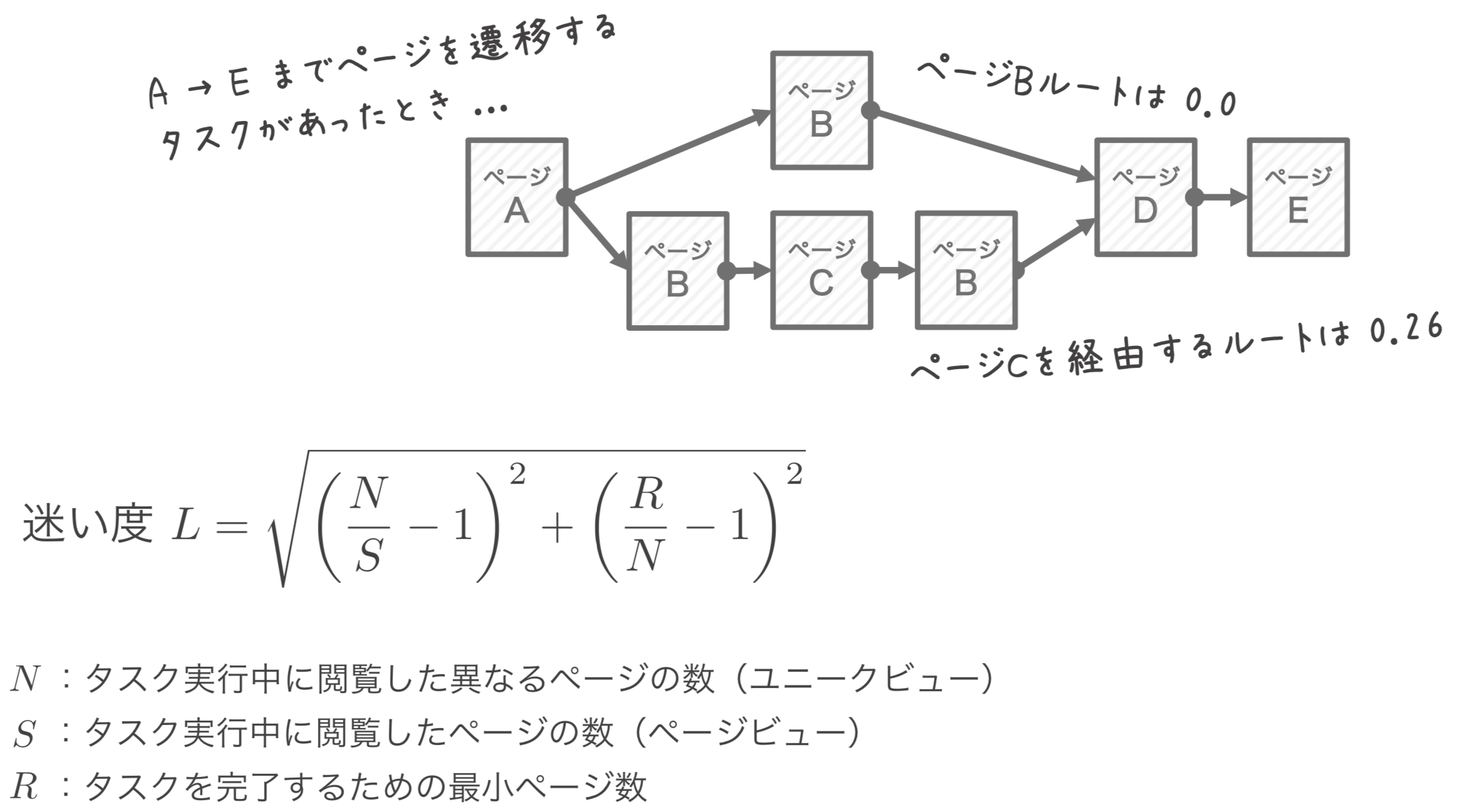
ページ遷移を題材にしてはいますが、
これがゲームならボス部屋に付くまでの最短経路とユーザの行動数で求めたり、様々な応用を利かせることができます。
データの表示方法もグラフを用いて、 xx% 減りましたと見せると良いです。
2. 見た目を調べる
2−1. デザイン・色
アイトラッカー
アイトラッカーを使うと、ユーザーの目線がどう変わったか調べることができます。
デザインや色を変えたときの評価に使うことが出きます。
ヒートーマップを作ってUIのどこが見られてない、じゃまになってるというデータも見れます。
UI配置がなんらかのエラーの要因となっている場合、ユーザービリティのエラー指標を計測することでも見えてくるものがあります。
タスク達成のために押す必要のあるボタンをユーザーが押さなかったとき、
それは**「気づいてなかった」から押さなかったのか、見た上で「必要に感じなかった」**から押さなかったのかは非常に重要な違いです。
アイトラッカーでは見たかどうかを可視化できるので、この切り分けをすることができます。
アイトラッカーのデータを定量的な評価にするためには多くのデータ加工が必要です。
たとえば
- 画面全体のうち何割を見ているか
- 特定のUIに視線が入ったか
など。
安価なアイトラッカーも多くあります。
自分は以下の商品を使っています。
SteelSeries Sentry Gaming Eye Tracker 視線測定機 69041
https://www.amazon.co.jp/SteelSeries-Sentry-Gaming-Tracker-69041/dp/B00SB8YKVI
ユーザーテスト中は視線マーカーを出さず、録画している映像にだけ残るようにできます。
また、実際の座標はライセンス登録(数万〜数十万)などをしないと取得できないメーカーもあります。
顕著性マップ
ヒトはUIや画面を見るとき必ずと言っていいほど目を使用します。
顕著性マップでは、人間の目を数理的にシュミレーションして目に付きやすいところなどを発見できます。
画像中の明るい部分がよく目につくところという意味になります。
顕著性マップを詳しく知りたい方はこちら
画像処理 (3) 顕著性マップ
http://fussy.web.fc2.com/algo/image3_saliency_map.htm
顕著性マップの推定手法
https://www.slideshare.net/takao-y/20150619-49592895
顕著性マップはいくつかのアルゴリズムもあります
プログラムコード自体は長くなってしまうので、上記URLや下記 URL を参考にしてみてください。
OpenCVで顕著性(Saliency)を求めてみる
http://irohalog.hatenablog.com/entry/2016/12/23/000000
Python の DeepGaze というライブラリでも顕著性マップが実装できます。
2−2. UI配置
カードソートを使うと、グルーピングの妥当性を検証することができます。
グルーピングとはメニューやタブなどに含まれるコンテンツのグループのことです。
カードソートでは各々のコンテンツをカード状にして並べ替えれるように用意します。
これを何人かにグルーピングを行ってもらいます。
写真などを撮っておくと後々使いやすいです

カードソートのやり方
 複数人分のデータが集まったら以下のルールで集計します。
複数人分のデータが集まったら以下のルールで集計します。
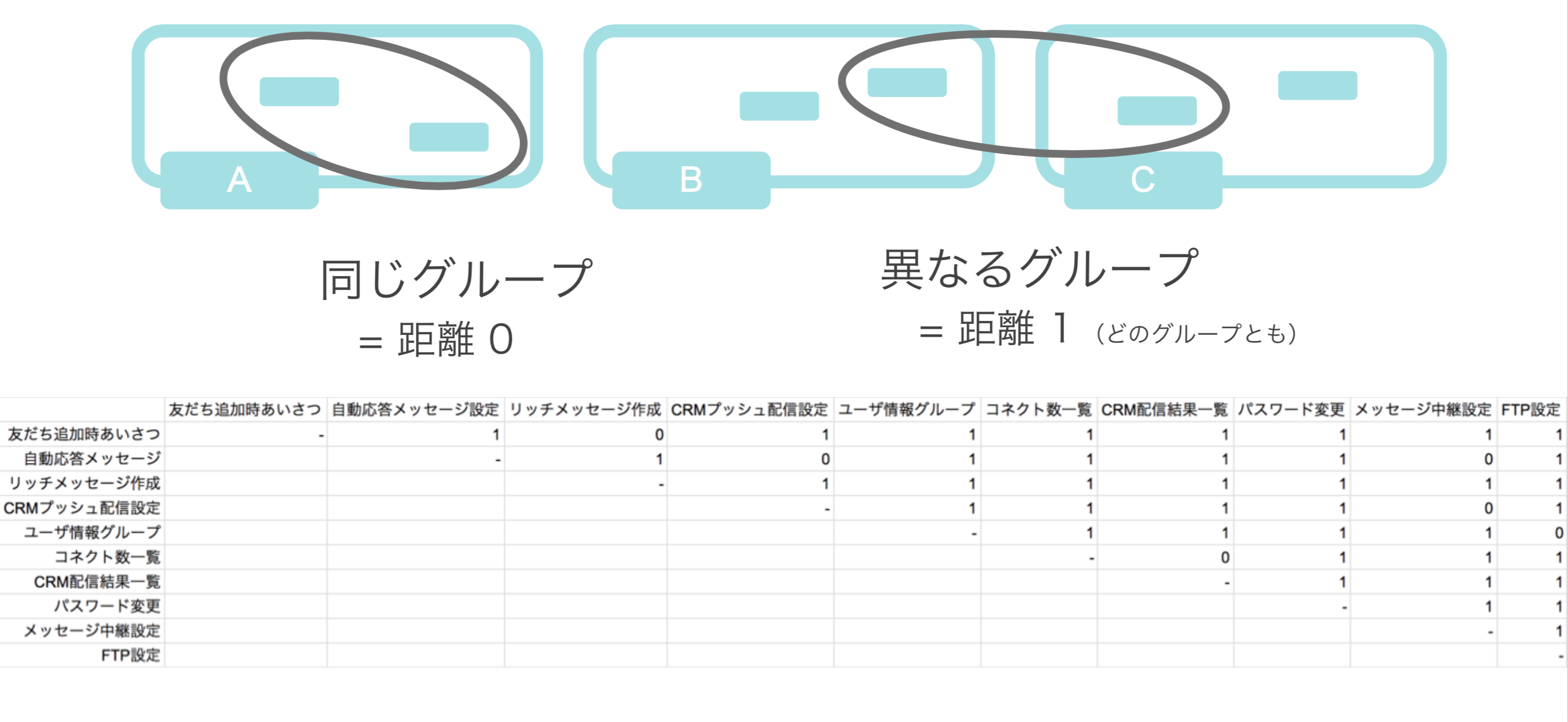 これは面白いことに、距離の公理を満たします。
ややこしいこと言うなって思うかもしれませんが、つまり、多くの統計手法を用いることができるようになったのです。
これは面白いことに、距離の公理を満たします。
ややこしいこと言うなって思うかもしれませんが、つまり、多くの統計手法を用いることができるようになったのです。
たとえば、
多次元尺度構成法
これは各々の位置関係をグラフ上にプロットして、位置関係を明確にすることで近い関係/遠い関係を見える化することができる手法です。
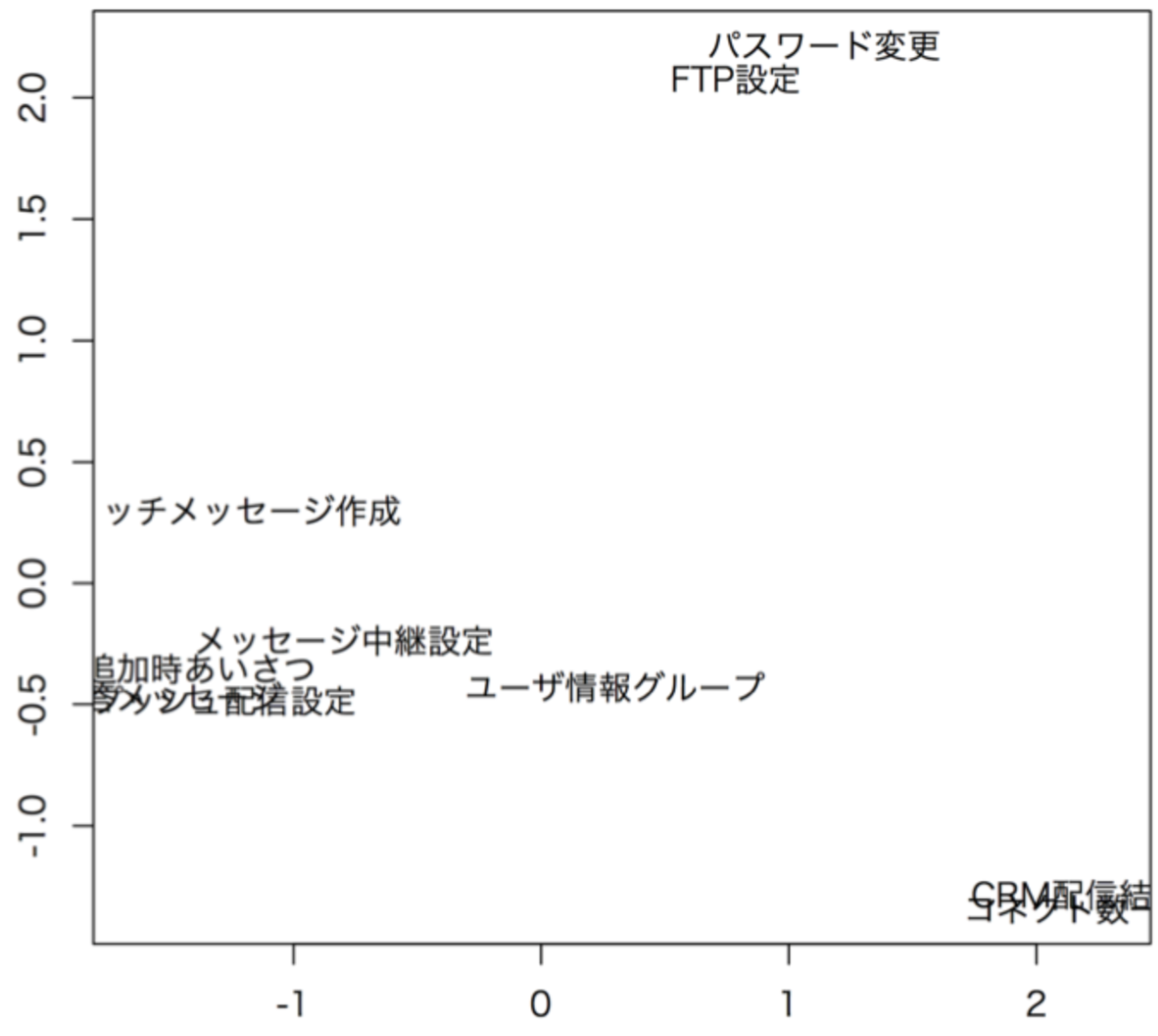
縦横の軸はあまり意味がある数値ではありません。
あくまでもプロットされたものの位置関係が重要です。
多次元尺度構成法について詳しく知りたい方は下記のリンクを。
使えればいいやと言う方は以下のソースコードを参照ください。
フリーソフトによるデータ解析・マイニング 第27回
https://www1.doshisha.ac.jp/~mjin/R/Chap_27/27.html
R (https://www.r-project.org/) という統計ソフトを用いることで、簡単に多次元尺度構成法を使うことができます。
まず、集計したカードソートの結果をCSVファイルにします。
ここで注意すべきはCSVファイルは対称行列でなければいけません。
(対称行列というものの例、データが対象的なのです)
つまり片側だけだったデータを同じように反対側にもコピーして対象なデータにします。
これでCSVファイルを保存しましょう。
Rでのソースコードは以下の通りになります。
data = read.csv(file="matrix.csv", sep=",")
cmd = cmdscale(data)
plot(cmd)
text(cmd, colnames(data))
上記が最小の記述コードですが、これだと日本語などが文字化けしたり、読み込めなかったりします。
Mac の R で日本語が表示できるようにするには以下のようにコードをアレンジします。
# 日本語いけるようにしたコード Mac版 R 用
data = read.csv(file="matrix.csv", sep=",", fileEncoding="CP932")
cmd = cmdscale(data)
par(family = "HiraKakuProN-W3")
plot(cmd)
text(cmd, colnames(data))
クラスターデンドログラム
多次元尺度構成法と似ていますが、こちらは樹形図(デンドログラム)を用いて関係の近い順に図のようなグラフを作成します。
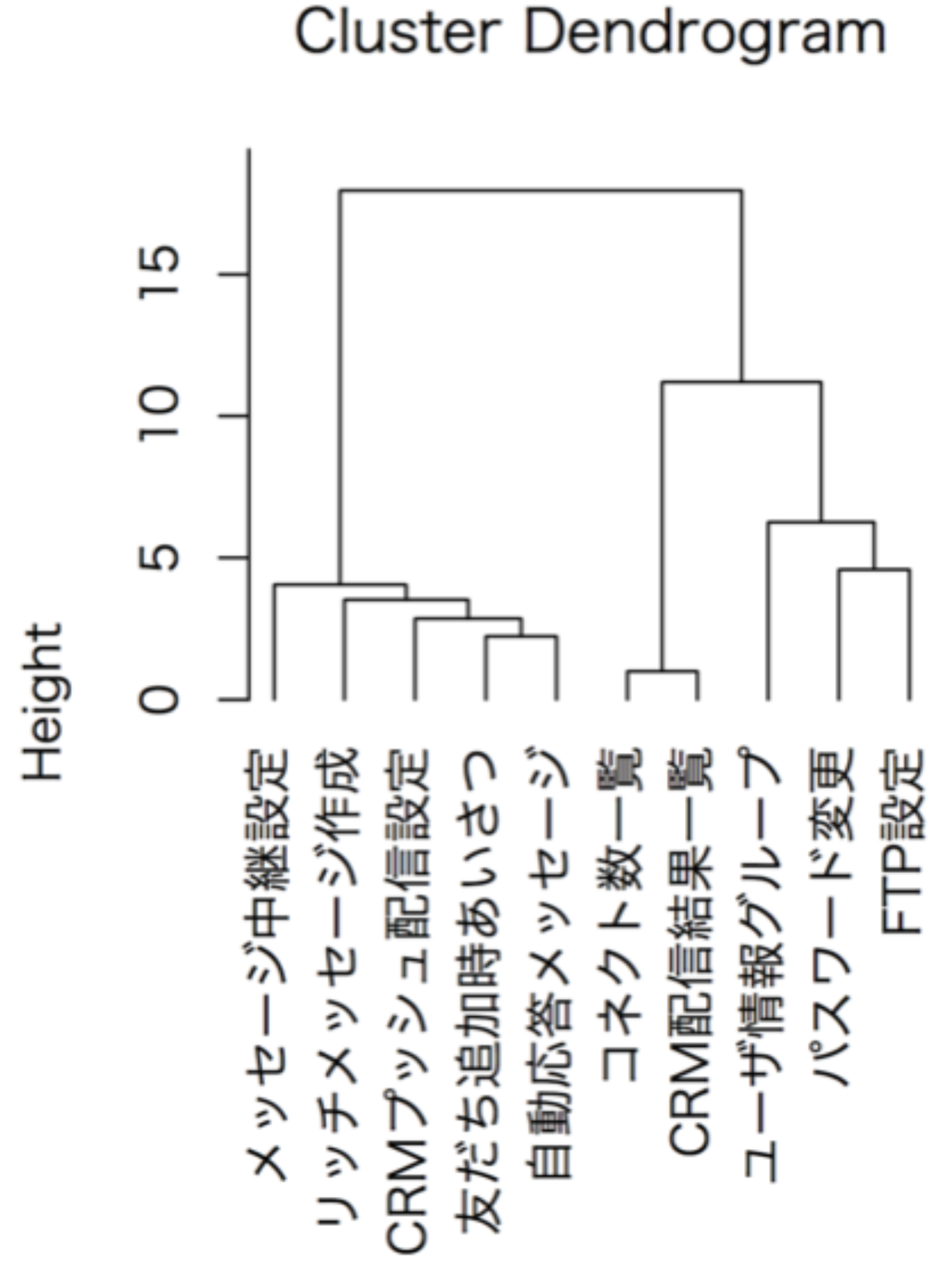
クラスタリングするためには適当な位置で Height のしきい値を決めて区切ります。
5の場所で切ってグループにしてもいですし、10でも大丈夫です。
自分でグループの粒度を決めることができます。
この手法だと入れ子メニューなども一発で構築できます。
クラスターデンドログラムについて詳しく知りたい方は下記のリンクを。
使えればいいやと言う方は以下のソースコードを参照ください。
クラスター分析の手法②(階層クラスター分析)
https://www.albert2005.co.jp/knowledge/data_mining/cluster/hierarchical_clustering
多次元尺度構成法(上述)のときのようにカードソートの結果を対称行列にしてCSVファイルにします。
Rでのソースコードは以下の通りになります。
data = read.csv(file="matrix.csv", sep=",")
hc = hclust(dist(data), method="ward.D2")
plot(hc, hang=-1, colnames(data[0, ]))
こちらもそのままだと日本語が使えないので、以下のようにアレンジすると日本語が使えるようになります。
(Windows の方はそのまま使えないかもしれません)
# 日本語いけるようにしたコード Mac版 R 用
data = read.csv(file="matrix.csv", sep=",", fileEncoding="CP932")
hc = hclust(dist(data), method="ward.D2")
par(family = "HiraKakuProN-W3")
plot(hc, hang=-1, colnames(data[0, ]))
カードソート、面白くないですか?
いくつかの機能があって、並べ替えただけなのにこんな高度な分析ができるようになるんです。
あなどれないです。
3. ユーザーの感情・印象を調べる
3−1. 調査票を使ったテスト結果の比較
システムユーザビリティスケール(SUS)
システムの印象を確認するための調査票になります。

この調査票はすでに決まった問に関して答えてもらうことになります。
そのため、SUSを使った他のプロダクトとも比較することができます。
奇数の番号はポジティブな質問、偶数の番号はネガティブな質問が並んでいます。
- 全く同意できないを1点
- 非常に同意できるを5点
としたとき、
ポジティブな質問は 点数 – 1 点 、ネガティブな質問は 5 – 点数 と変換して全部足し、最後に x 2.5 をします。
SUS(システムユーザビリティスケール)
https://www13.atwiki.jp/unoy/pages/27.html
そうすると、0点 ~ 100点の間に収まります。
スコアが高いほど、ユーザーの印象は良いということが言えるテストになっています。
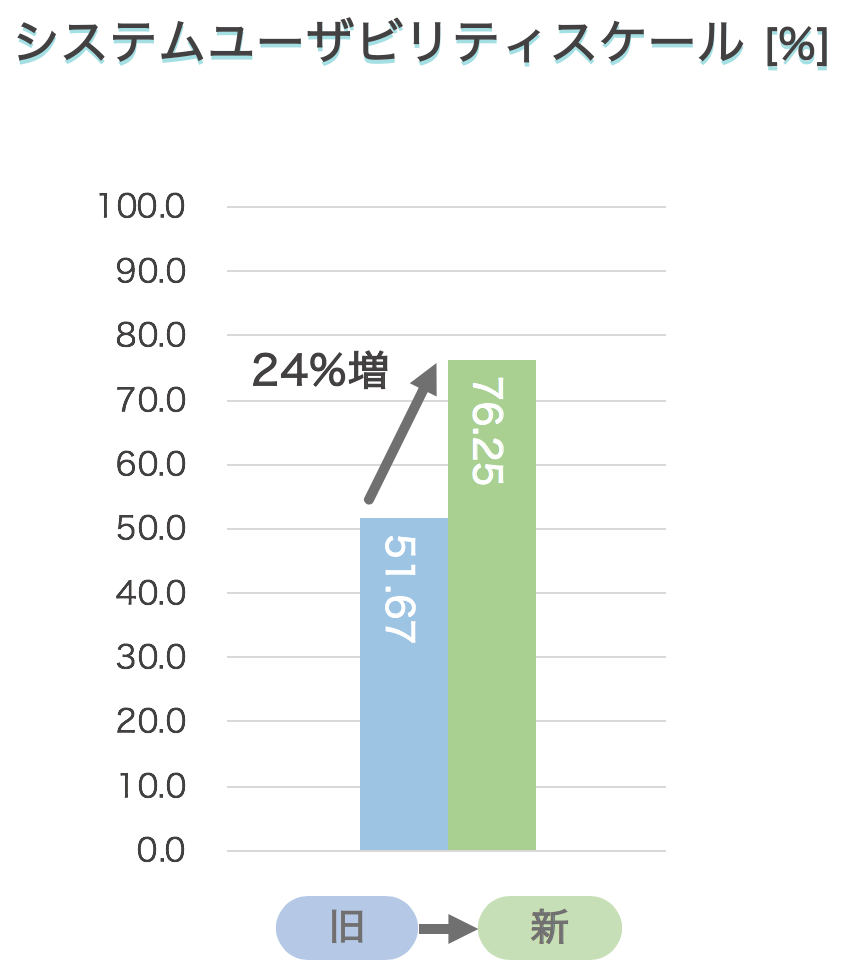
2つのデザインを比較してどっちが良いかを求めることができます。
3−2. 発話しなくてもユーザーの感情を引き出す
ユーザーテストではプロトコル解析という思ったことを声に出し続けるやり方があります。
これは一見簡単そうに見えますが、ユーザーによってアウトプットがまちまちになり、比較しづらいです。
そしてそれは定量的に測ることとは程遠くなってしまいます。
そこで活躍するのが製品リアクションカード
製品リアクションカード
思考発話法(think aloud)を使っても、ユーザーの心の内を話してくれないことは多々あります。
それも発話することに一生懸命で言いたいことを忘れてしまったり。
製品リアクションカードでは、印象を形容する単語が散らばっています。
評価するプロダクトの印象を捉えているカードを選択することで、頭にはなかったけど思っていたことを引き出すことができます。
そして何より、あらゆるユーザーが同じ集合から単語をピックアップするのでカウントし定量的に測る事ができます。
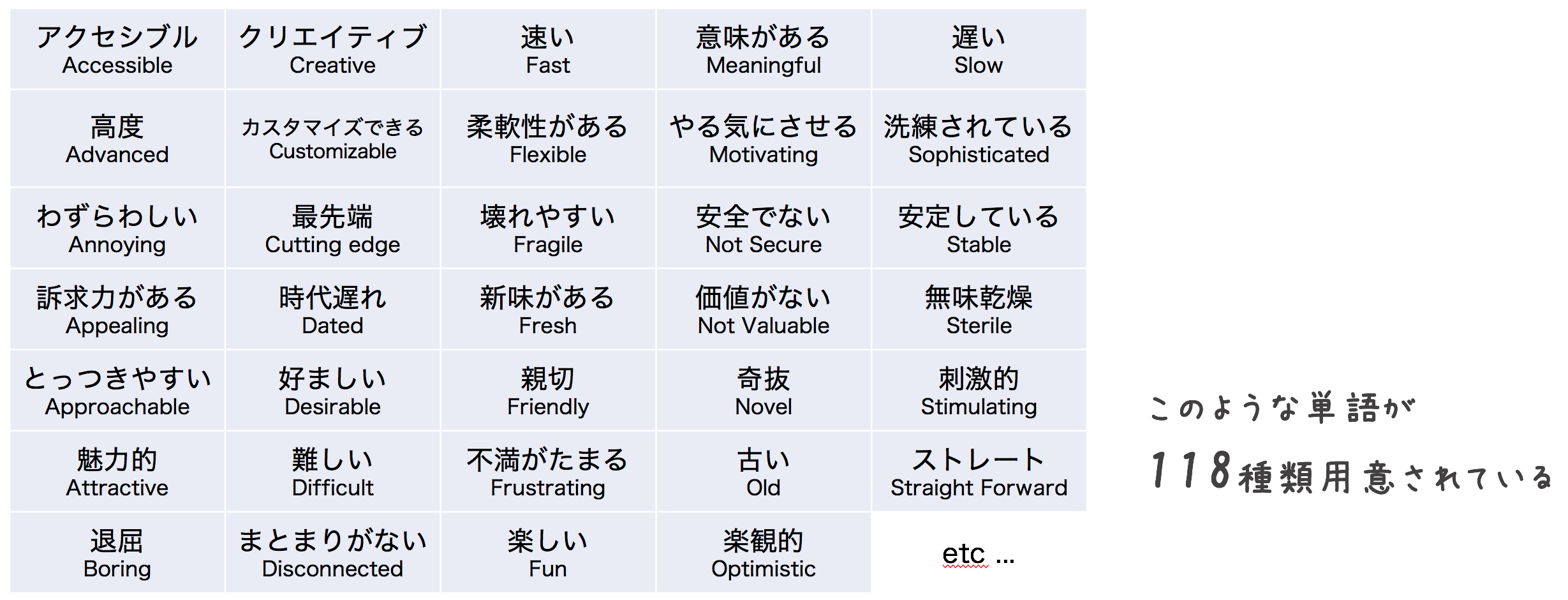
Capturing user feedback with Microsoft’s product reaction cards
http://www.uxforthemasses.com/product-reaction-cards/
ポジティブなワード/ネガティブなワードがそれぞれあるので、各々の割合を表示すると印象を見える化することができます。
ですが一番パッと見で変化がわかるのはワードクラウドでしょう。

ワードクラウド中の文字の大きさは、複数のユーザーに多く選ばれていた文字になります。
このように見える化することで、「改善して良くなりました!」だけじゃなくて「〇〇という印象が消え、△△という印象が増える結果となりました」なんて言えるようになります。
4. データの読み方
この記事では数字が多く出てきました。
数字にするとわかりやすいですが、読み誤るということが起きがちです。
注意すべきポイントを見てみましょう。
4-1 平均値の扱い
定量的な評価をすると、平均値などと言ったデータを多く扱うことになると思います。
ですが、平均値はあくまでも目安として信じてください。
平均値だけを見て、◯◯が一番いい!と決めることは危険です
たとえば
- デザインのA/Bテストを行ったとき
| スコア1 | スコア2 | スコア3 | スコア4 | スコア5 | スコア6 | 平均値 | |
|---|---|---|---|---|---|---|---|
| デザインA | 85.0 | 80.0 | 77.5 | 70.0 | 45.0 | 90.0 | 74.6 |
| デザインB | 70.0 | 80.0 | 62.5 | 45.0 | 55.0 | 77.5 | 65.0 |
デザインAのスコアの平均値は74.6、デザインBのスコアの平均値は65.0。
平均値だけ見るとデザインAのほうがスコアが高いということになりますが、この判断は危険です。
危険というのは、誤ったデータの読み方をしている可能性があるということです。
疑うべきポイントは以下の点になります
- 複数回 同じA/Bテストをしても、毎回デザインAのスコアが高いでしょうか?
- それぞれのスコアは何らかの勘違い/不正によってもたらされたスコアが含まれてないでしょうか?
これらの疑いを解消するためには次項の 検定 と呼ばれる手法を用いる必要があります。
4-2 検定
ここでは t検定 と呼ばれる手法のみを解説します。
例を使ってざっくりとした解説のみします、詳しく知りたいかたは以下のURLを参考にしてください。
t検定
2つの分布間の平均値が有意に異なるかを調べるための検定手法です。
スチューデントのt検定とも呼ばれます。
噛み砕いて説明すると、

2つの組でテストをやってどっちの組が優秀だったかを調べるとき、
2つの分布間の平均値 とは図で言うところのA組と平均点とB組の平均点のことを指します。
また、有意に異なるか とは明らかに違っているかということを意味します。

2つの組は平均点が違い、A組のほうが高いスコアを出していたとします。
ですが、B組の上位には劣っている学生もA組にはいるわけです。
それを加味しても本当にA組のほうが優秀だったのかということを調べたいわけです。
2つの分布間の平均値が有意に異なるかを調べる という意味はこの例でいうと
「A組とB組の平均点は、A組のほうが高いけど、それって本当に明らかにA組のほうが高い?」という意味になります。
t検定を使うとこれが明確にわかります。
Rで簡単にできます。
先程の例で検定をしてみましょう。
A = c(85.0, 80.0, 77.5, 70.0, 45.0, 90.0)
B = c(70.0, 80.0, 62.5, 45.0, 55.0, 77.5)
t.test(A, B, var.equal=F)
正確な議論をすると、ここではウェルチのt検定を行っています(var.equal=Fの部分で設定)
検定をするとき、2つのデータ列に対応のあり・なしを意識する必要があります。
ウェルチのt検定ではどちらの場合でも使用可能なので、こちらを紹介しています。
出力↓
> t.test(A, B, var.equal=F)
Welch Two Sample t-test
data: A and B
t = 1.121, df = 9.7265, p-value = 0.2892
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-9.538524 28.705191
sample estimates:
mean of x mean of y
74.58333 65.00000
この結果では p-value = 0.2892 というを見てみましょう。
t検定はデザインAとデザインBに違いがないということを仮定した上で、それを否定する検定方法です
このP値が意味することは 28.92% の確率でデザインAとデザインBは違いがないと言うことです。
大抵の場合 5% または 1% 以下の結果をもって否定とするため、28.92% では否定できない(同じである可能性がある)という結果になります。
デザインAとの平均点は 74.6、デザインBの平均点は 65.0 でデザインAのほうが優れてると見られがちですが、検定の結果この2つのデザインに差はないということが分かりました。
このように、平均値1つとってもデータの誤読が起きる恐れがあります。
だからといって定量的なユーザーテストはむずかしい!と嫌厭されると残念なので、ここは少し頑張って知識を手に入れましょう。
しっかり理解しなくてもツールとしてなら使えるのですから。
まとめ
きっとここまで目を通した人はいないかと思います。
すぐ上にも書いてあるとおり、難しい...、めんどくさい... と感じることはあるかと思いますが、ツールとして使うのなら理解は後からでも追いつきます。
この記事で伝えたかったことはほんの1つだけ。
"エビデンスのあるデザインは強い" です。
デザインにはだいたいルールと規則があります。
ここでは数値を使って明確にしましたが、優秀なデザイナーは数値を使わなくとも感覚でこのような計算を無意識にやっているから優秀とされていたりします。
優秀な感覚を会得するまでは、数値に頼ってテストしてみてはいかがでしょう。