この記事はNTTテクノクロスアドベントカレンダー2021 25日目の記事です。
はじめに
こんにちは。NTTテクノクロスの山下です。
2021/12/08にElasticsearch 7.16.0がリリースされ、Experimentalな新機能としてCategorize Text Aggregationが追加されました。
アプリログのような定型的な文字が出力されるドキュメントに対して、似たようなパターンのドキュメント(行)がどれぐらいあるか?を集計してくれる機能のようです。1
この機能を事前に実行しておけば、障害時などに大量に同じ内容のログが出力されるケースなどに対応する際に、ログ傾向を把握した上で詳細なログを確認できそうです。
というわけで、この記事ではCategorize Text Aggregationを実際に使ってみて、どんな感じの機能なのかまとめてみます。
なお、一応ドキュメントと見比べてはいますが、試した中から把握したことをまとめているため、必ずしも正しい内容とは限りません。間違いを見つけたら編集リクエストお願いします🙇♂️🙇♂️🙇♂️
Elasticsearchとは
Elasticsearchはスキーマレスなデータベースを持った高速な全文検索エンジンです。世界のデータベースランキングであるDB-Engines Rankingで常に10位以内をキープしているなど、全文検索用途ではデファクトスタンダードになっている人気プロダクトです。
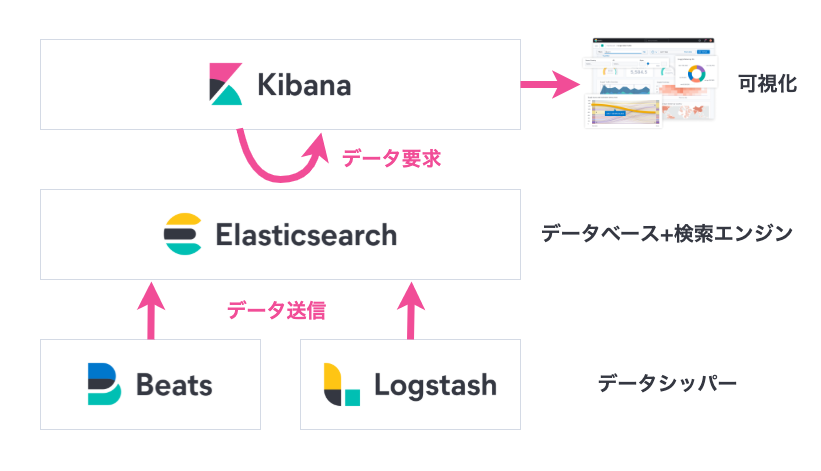
ちなみに、ElasticsearchはElastic Stackと呼ばれるプラットフォームの1プロダクトでもあり、今回も関連プロダクトであるKibanaを使ってElasticsearchへのデータの投入やAPIリクエストを試していきます。
Categorize Text Aggregationを実際に試してみる
Elastic Stackの起動
deviantony / docker-elkを使ってElastic Stackの環境を構築します。Docker実行環境さえあれば特定バージョンの環境構築ができるので、Elastic Stackで何か試すときには定番ですね。
- 動作確認時の各種ツール・ミドルウェアのバージョン
- Git
- 2.33.0
- Docker
- 20.10.8
- docker-compose
- 1.29.2
- Elastic Stack
- 7.16.2
- Git
git clone https://github.com/deviantony/docker-elk.git
cd docker-elk
git checkout 691ffd8764fe22bc363836219b3ee2e089c2c12e
docker-compose up -d
これでElasticsearch + Kibanaの環境が起動しました。
データの投入
まず、カテゴライズしたい対象のログファイルをダウンロードしましょう。
今回はlogpai / loghubで公開されているApacheのアクセスログを使用することにします。
以下のURLから直接ダウンロードできます。
続いて、ダウンロードしたApacheアクセスログをKibana経由でElasticsearchに投入していきましょう。
Kibanaの対応ブラウザ(Google Chrome / Firefox / Safari / Chromium Edge)で http://localhost:5601 を開きます。
以下の情報を入力しLog inをクリックします。
- Username
- elastic
- Password
- changeme
画面上部の初期通知に記載されているとおり、業務上使用する場合は、使用情報をElasticに送信したくないケースもあるでしょう。その場合は、disable usage data here.をクリックして、テレメトリーデータの送信をしないように設定しておくのが良いです。しかし、今回は本筋ではないため説明を割愛します。画面上部の通知にあるDismissをクリックします。
左上のハンバーガーボタンをクリックします。
Analytics => Machine Learningをクリックします。
上部のタブからData Visualizerをクリックします。
Select fileをクリックします。
Select or drag and drop a fileをクリックし、ダウンロードしたApache_2k.logを選択しましょう。ドラッグ&ドロップで運んでも構いません。
すると、ログファイルの内容をKibanaが解析し、Elasticsearchに取り込める形式に変換してくれます。
画面左下のImportをクリックします。
Index名としてapache-2kと入力し、Importをクリックします。
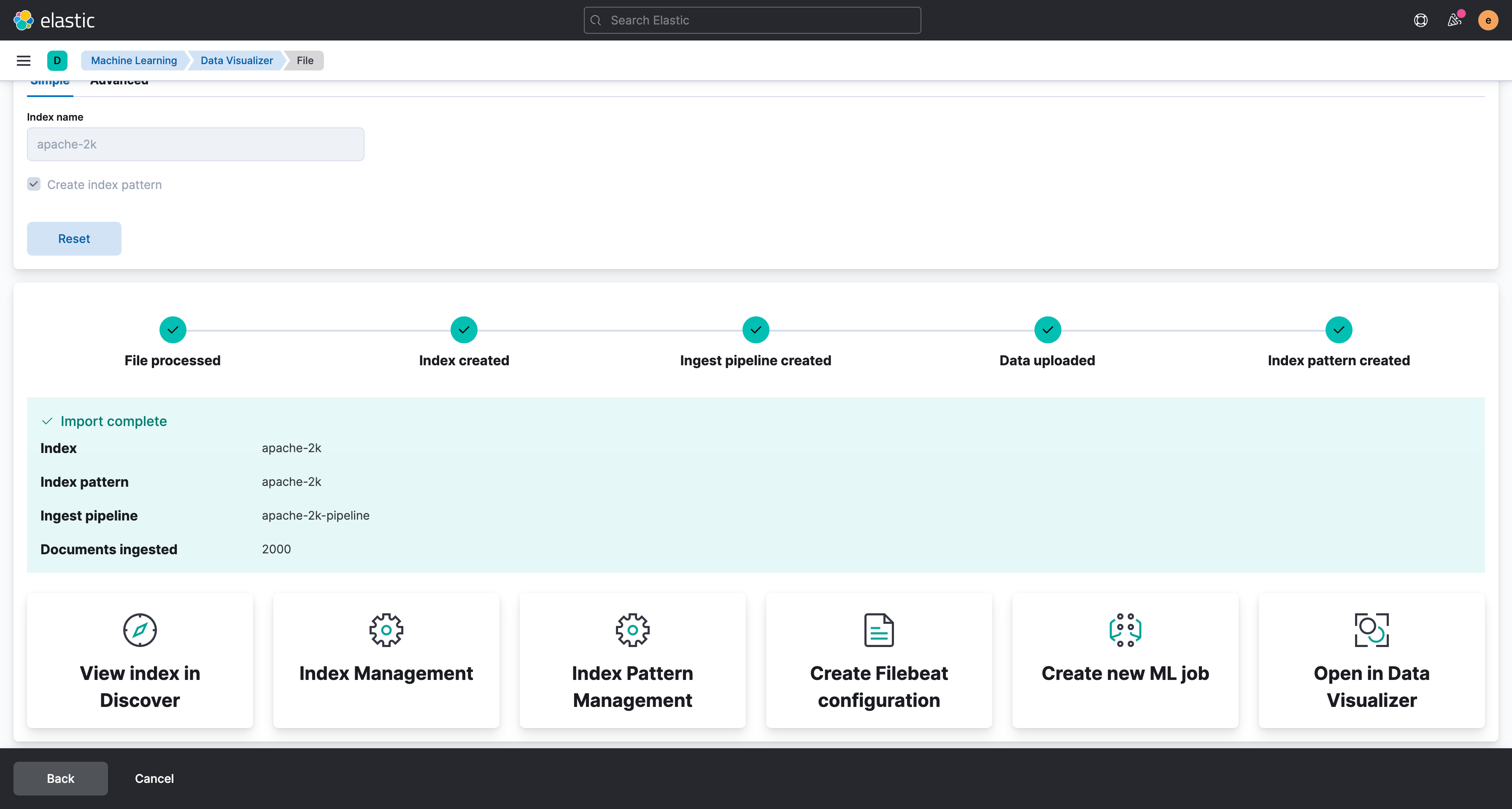
ファイルの取り込み処理が実行されます。プログレスバーが完了まで進んだら画面左下のView index in Discoverをクリックします。
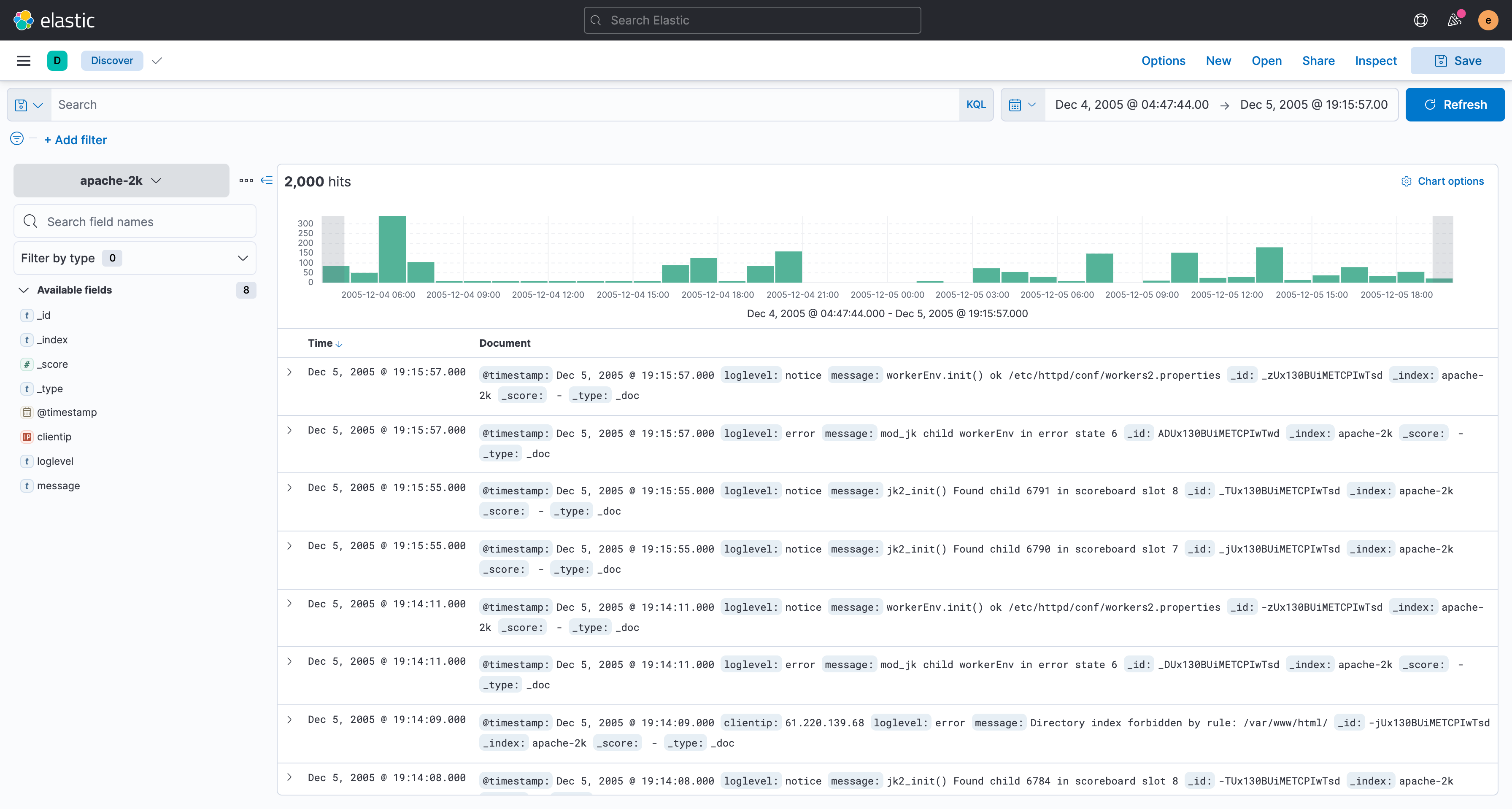
各行のログ内容が表示されました。
この画面はKibanaの機能の中でもDiscoverと呼ばれる画面で、
この画面の時点でこのログについて以下のことが分かります。
- 右上の日付期間から、2005年12月4日04:47:44.00から2005年12月5日19:15:57.00までのログが含まれていることが分かる
- 画面左上のヒット件数から、2000行あることが分かる
- 画面中央上部の件数の時系列ヒストグラムから、全くログ出力がない期間といくつかのスパイクが見られ、流量が一定ではないことが分かる
今回メインとなる確認ではないですが、こういったことが一目でわかるのがElasticsearch + Kibanaの良いところですね。
何はともあれ、これでElasticsearchにログを取り込むことができました。
シンプルなCategorize Text Aggregationを試してみる
次はいよいよ新機能を試してみましょう。
ElasticsearchのAPIを叩くのはKibanaのDev ToolsにあるConsole画面から試すのがおすすめです。
左上のハンバーガーボタンをクリックします。
Management => Dev Toolsをクリックします。
これがConsole画面です。
左側にElasticsearch APIのエンドポイントや送信するボディを記述し、Ctrl(Cmd) + Enterするか、再生ボタンをクリックすると、APIが実行され、レスポンスが画面右側に表示されます。
以降、この画面で実行するための形式でリクエストを書いて試していきます。
まずは最も基本的な使い方を試していきます。ログのメッセージ部分が入っているmessageフィールドに対して、単純なCategorize Text Aggregationを試してみます。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message"
}
}
}
}
他のデータについて試すときには、インデックス名(apache-2k)とフィールド名(message)の指定に注意してください。それ以外は基本的にこの使い方のままで実行できるはずです。
実行後のレスポンスは以下の通りになりました。
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "jk2_init Found child in scoreboard slot"
},
{
"doc_count" : 569,
"key" : "workerEnv.init ok /etc/httpd/conf/workers2.properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerEnv in error state"
},
{
"doc_count" : 32,
"key" : "Directory index forbidden by rule /var/www/html/"
},
{
"doc_count" : 12,
"key" : "jk2_init Can t find child in scoreboard"
},
{
"doc_count" : 12,
"key" : "mod_jk child init"
}
]
}
}
}
aggregations.categories.bucketsの中に配列形式で、複数のドキュメントに登場した文字列パターン(key)と登場したドキュメント件数(doc_count)が返却されます。
今回はシンプルなログファイルということもあって、2000件のドキュメントが6種類のカテゴリに分類されました。全てのdoc_countを合計すると、ログ件数の2000と一致するので、全てのドキュメントがどれかのカテゴリに分類されているようです。2
最も多いカテゴリはjk2_init Found child in scoreboard slotという文字列で、836件あるようです。実際にログの最初の10行を抜粋してみましょう。
[Sun Dec 04 04:47:44 2005] [notice] workerEnv.init() ok /etc/httpd/conf/workers2.properties
[Sun Dec 04 04:47:44 2005] [error] mod_jk child workerEnv in error state 6
[Sun Dec 04 04:51:08 2005] [notice] jk2_init() Found child 6725 in scoreboard slot 10
[Sun Dec 04 04:51:09 2005] [notice] jk2_init() Found child 6726 in scoreboard slot 8
[Sun Dec 04 04:51:09 2005] [notice] jk2_init() Found child 6728 in scoreboard slot 6
[Sun Dec 04 04:51:14 2005] [notice] workerEnv.init() ok /etc/httpd/conf/workers2.properties
[Sun Dec 04 04:51:14 2005] [notice] workerEnv.init() ok /etc/httpd/conf/workers2.properties
[Sun Dec 04 04:51:14 2005] [notice] workerEnv.init() ok /etc/httpd/conf/workers2.properties
[Sun Dec 04 04:51:18 2005] [error] mod_jk child workerEnv in error state 6
[Sun Dec 04 04:51:18 2005] [error] mod_jk child workerEnv in error state 6
3行目〜5行目までが該当の文字列パターンが登場するログです。
カテゴリ集計後の文字列と比較すると、集計後の文字列(key)には共通部分のみが抽出されており、行ごとに異なる文字列は除去されています。共通部分のみに着目してログの種類別件数を確認できるのは便利ですね!
基本的なパラメータ
先ほど使用したfield以外のパラメータについても確認しておきましょう。まずは挙動を簡単に理解できるパラメータを試してみます。
その他の応用的なパラメータに関しては本編に記載するとボリューミーだったので、Appendixに試した結果をまとめました。興味があれば読んでみてください。
categorization_filters
カテゴライズする際に指定した単語を除去してカテゴライズできます。正規表現も使用できます。
なお、後ほど紹介するcategorization_analyzerとは共用できません。3
リクエストとレスポンス
mod_jk child workerEnv in error stateとmod_jk child initからchild以外の単語を除去してカテゴライズする例です。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_filters": ["\\w+\\_\\w+", "workerEnv", "in", "error", "state", "it"]
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "Found child scoreboard slot"
},
{
"doc_count" : 569,
"key" : "/etc/httpd/conf/workers2.properties"
},
{
"doc_count" : 551,
"key" : "child"
},
{
"doc_count" : 32,
"key" : "Directory dex forbidden by rule /var/www/html/"
},
{
"doc_count" : 12,
"key" : "Can t child scoreboard"
}
]
}
}
}
size
レスポンスとして返ってくるカテゴリ数の上限を指定できます。
オーダー順を指定しなければ、件数が多い方順に上位N件が返却されます。
デフォルトの値は10です。
リクエストとレスポンス
件数上位のカテゴリ2件のみを返却する例です。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"size" : 2
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "jk2_init Found child in scoreboard slot"
},
{
"doc_count" : 569,
"key" : "workerEnv.init ok /etc/httpd/conf/workers2.properties"
}
]
}
}
}
min_doc_count
カテゴリとして集計する際に何件以上あるkeyについてのみ集計するか指定できます。
指定した数より小さい件数のカテゴリは結果が返却されません。
リクエストとレスポンス
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"min_doc_count" : 100
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "jk2_init Found child in scoreboard slot"
},
{
"doc_count" : 569,
"key" : "workerEnv.init ok /etc/httpd/conf/workers2.properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerEnv in error state"
}
]
}
}
}
おわりに
Categorize Text Aggregation、一瞬で生ログの傾向を把握できて便利そうです。まだKibanaのVisualizeでこのAggregationに対応したものはないと思いますが、自由にElasticsearchへのクエリが書けるVega Visualizationと組み合わせれば何とか可視化にも使えそうです。
ただし、公式ドキュメントによれば、このCategorize Text Aggregationは大量のドキュメントに対して実行すると膨大な時間とメモリを使用するため、Async searchにしたり、Sampler aggregationやDiversified sampler aggregationすることが推奨されています。
これでNTTテクノクロスAdvent Calendar 2021は終わりとなります。
たまたまこの記事にアクセスされた方はぜひカレンダーの記事一覧に飛んで他にも興味ある記事がないかどうか確認してみてください!
Appendix
応用的なパラメータ
以下のパラメータについては、本格的にaggregationの設定をカスタマイズしていく際には重要なパラメータになりそうなのですが、本編の内容にするには重めの内容だったので、Appendixとしてまとめておきます。
categorization_analyzer
このパラメータに関してはElasticsearchのanalyzerなどについての知識が必要となるため、analyzerを知らない方は読み飛ばすことを推奨します。
aggregationを実行する前に適用するanalyzerを指定できます。
指定しない場合はCategorize Text Aggregationが持っているデフォルトのanalyzerが使われるようです。
リクエストとレスポンス
Standard Analyzerを使用する例です。
なお、この後のパラメータ紹介はこれを設定した前提で説明していきます。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard"
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 781,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 12,
"key" : "jk2_init can't find child * in scoreboard"
},
{
"doc_count" : 12,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6733 in scoreboard slot *"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6740 in scoreboard slot 7"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6750 in scoreboard slot *"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6751 in scoreboard slot *"
}
]
}
}
}
*が登場している意味については後述します。
Categorize Text Aggregationが使うデフォルトのanalyzerについて
デフォルトのanalyzerについては自信はないものの、以下のようなGET _ml/infoで取得できるcategorization_analyzerを使っていそうです。試しに適用してみたところ、同じ結果が得られました。
{
"char_filter" : [
"first_line_with_letters"
],
"tokenizer" : "ml_standard",
"filter" : [
{
"type" : "stop",
"stopwords" : [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday",
"Mon",
"Tue",
"Wed",
"Thu",
"Fri",
"Sat",
"Sun",
"January",
"February",
"March",
"April",
"May",
"June",
"July",
"August",
"September",
"October",
"November",
"December",
"Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec",
"GMT",
"UTC"
]
}
]
}
Token FilterについてはシンプルなStop token filterですね。曜日に該当する単語を除去しています。
Character Filterのfirst_line_with_lettersと、Tokenizerのml_standardについてはドキュメントに挙動が記載されていませんが、ソースコードのJavaDocを読めば挙動が理解できそうです。リンクを貼っておきます。
max_matched_tokens
指定した位置以降のトークンで異なるパターンのトークンがある場合、カテゴリとしてマージするかを指定できます。
これだけだと意味不明なので、いくつかパターンが異なる実例を見ていきます。
8トークン目以降のトークンをマージするリクエストとレスポンス
similarity_thresholdはデフォルトの50、max_unique_tokensもデフォルトの50とします。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 50,
"max_matched_tokens": 8,
"max_matched_tokens": 50
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 617,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 369,
"key" : "mod_jk child workerenv in error state 6"
},
{
"doc_count" : 101,
"key" : "mod_jk child workerenv in error state 7"
},
{
"doc_count" : 44,
"key" : "mod_jk child workerenv in error state 8"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 20,
"key" : "mod_jk child workerenv in error state 9"
},
{
"doc_count" : 11,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 5,
"key" : "mod_jk child workerenv in error state 10"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6733 in scoreboard slot *"
}
]
}
}
}
mod_jk child workerenv in error state [number]という文字列について、それぞれの6~10までの数字別の内容がカテゴリとして返却されます。[number]は半角スペースで区切られた7トークン目の文字列となるため、8トークン目以降をマージする設定のこの時点ではカテゴリとしてマージされていません。
また、jk2_init found child [number] in scoreboard slot *という文字列についても、[number]に相当する箇所は4トークン目となるため、カテゴリとしてマージされていません。
7トークン目以降のトークンをマージするリクエストとレスポンス
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 50,
"max_matched_tokens": 7
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 634,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 11,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6733 in scoreboard slot *"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6741 in scoreboard slot *"
},
{
"doc_count" : 1,
"key" : "jk2_init can't find child 2085 in scoreboard"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 8744 in scoreboard slot 8"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 8766 in scoreboard slot 12"
}
]
}
}
}
mod_jk child workerenv in error state [number]という文字列について、それぞれの6~10までの数字別の内容がマージされたmod_jk child workerenv in error state *というカテゴリにマージされました。パラメータで指定した7トークン目以降の異なるパターンがマージされた形です。
4トークン目以降のトークンをマージするリクエストとレスポンス
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 50,
"max_matched_tokens": 4,
"max_unique_tokens": 50
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 12,
"key" : "jk2_init can't find child * in scoreboard"
},
{
"doc_count" : 12,
"key" : "mod_jk child init 1 2"
}
]
}
}
}
jk2_init found child [number] in scoreboard slot *というメッセージについて、マージされたk2_init found child * in scoreboard slot *というカテゴリが返却されています。[number]に相当する箇所は4トークン目であるため、今回の指定である4トークン目以降での異なるパターンがマージされました。
similarity_threshold
トークン全体で見た時の何%以上のトークンが一致した時に*としてカテゴリにマージして表示するか設定できるパラメータです。
デフォルトの値は50です。
100%トークンが一致した文字列をカテゴライズするリクエストとレスポンス
トークンが完全一致した文字列のみをカテゴライズする例です。似たような文字列でもマージされません。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 100,
"max_matched_tokens": 5,
"max_unique_tokens": 50
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 369,
"key" : "mod_jk child workerenv in error state 6"
},
{
"doc_count" : 101,
"key" : "mod_jk child workerenv in error state 7"
},
{
"doc_count" : 44,
"key" : "mod_jk child workerenv in error state 8"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 20,
"key" : "mod_jk child workerenv in error state 9"
},
{
"doc_count" : 11,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 5,
"key" : "mod_jk child workerenv in error state 10"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 1338 in scoreboard slot 7"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 312 in scoreboard slot 10"
}
]
}
}
}
ここの結果の中で、mod_jk child workerenv in error state [number]というkeyについて考えてみます。
似たようなkeyを眺めると、mod_jk、child、workerenv、in、error、stateの6つは共通したトークンで、[number]だけが異なっています。異なるトークンの割合は6 / 7 = 85.7(%)です。この値の前後を設定することで挙動を確認してみましょう。
86%以上トークンが一致した文字列をカテゴライズするリクエストとレスポンス
86%以上トークンが一致した文字列のみをカテゴライズする例です。85.7%は含まれないため、mod_jk child workerenv in error state [number]はマージされません。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 86,
"max_matched_tokens": 7,
"max_unique_tokens": 50
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 590,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 369,
"key" : "mod_jk child workerenv in error state 6"
},
{
"doc_count" : 101,
"key" : "mod_jk child workerenv in error state 7"
},
{
"doc_count" : 44,
"key" : "mod_jk child workerenv in error state 8"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 20,
"key" : "mod_jk child workerenv in error state 9"
},
{
"doc_count" : 11,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 5,
"key" : "mod_jk child workerenv in error state 10"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6741 in scoreboard slot *"
}
]
}
}
}
85%以上トークンが一致した文字列をカテゴライズするリクエストとレスポンス
85%以上トークンが一致した文字列のみをカテゴライズする例です。85.7%が含まれるため、mod_jk child workerenv in error state [number]もマージされます。
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 85,
"max_matched_tokens": 7,
"max_unique_tokens": 50
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 627,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 11,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6733 in scoreboard slot *"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6741 in scoreboard slot *"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 32390 in scoreboard slot 8"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 32445 in scoreboard slot 10"
},
{
"doc_count" : 1,
"key" : "jk2_init found child 8766 in scoreboard slot 12"
}
]
}
}
}
max_unique_tokens
max_matched_tokensで指定した位置のトークンより前のトークンについて複数候補あるトークンを何種類keyとして許容するかを指定できます。トークンは指定した種類に収まるように*にマージされます。
1種類(*のみ)しか許容しない場合のリクエストとレスポンス
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 50,
"max_matched_tokens": 5,
"max_unique_tokens": 1
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 836,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 12,
"key" : "jk2_init can't find child * in scoreboard"
},
{
"doc_count" : 12,
"key" : "mod_jk child init 1 2"
}
]
}
}
}
jk2_init found child * in scoreboard slot *として、childの後のトークンがマージされています。
これは、max_matched_tokensで指定した5番目のトークンより前の4番目のトークンです。今回はmax_unique_tokensで、1種類しか許容しないように設定したので、全てのトークンが*にマージされました。
2種類(*ともう1つのトークン)許容する場合のリクエストとレスポンス
POST apache-2k/_search?filter_path=aggregations
{
"aggs": {
"categories": {
"categorize_text": {
"field": "message",
"categorization_analyzer": "standard",
"similarity_threshold": 50,
"max_matched_tokens": 5,
"max_unique_tokens": 2
}
}
}
}
{
"aggregations" : {
"categories" : {
"buckets" : [
{
"doc_count" : 834,
"key" : "jk2_init found child * in scoreboard slot *"
},
{
"doc_count" : 569,
"key" : "workerenv.init ok etc httpd conf workers2 properties"
},
{
"doc_count" : 539,
"key" : "mod_jk child workerenv in error state *"
},
{
"doc_count" : 32,
"key" : "directory index forbidden by rule var www html"
},
{
"doc_count" : 12,
"key" : "jk2_init can't find child * in scoreboard"
},
{
"doc_count" : 12,
"key" : "mod_jk child init 1 2"
},
{
"doc_count" : 2,
"key" : "jk2_init found child 6741 in scoreboard slot *"
}
]
}
}
}
jk2_init found child * in scoreboard slot *として、childの後のトークンがマージされていますが、jk2_init found child 6741 in scoreboard slot *という似たkeyのカテゴリも存在しています。
今回はmax_unique_tokensで、2種類許容するように設定したので、この2つの似たkeyが許容されました。
その他のパラメータ
その他、インデックスを複数シャードに分割している際に使えるパラメータとしてshard_sizeやshard_min_doc_countなどもあります。
今回はデフォルトのプライマリシャード数1で試していたので紹介するのみに留めます。