どんな内容?
前回、この記事にて、記事推薦モデルをBERT+AllenNLPを用いて作成しました。
今回、この記事では、faissとFastAPIを更に用いることで、任意の日本語検索クエリに対して、記事を推薦するモデルを作っていきます。
今回のコードは以下にすべて用意しています。
構成について
非常にシンプルな構成になっています。
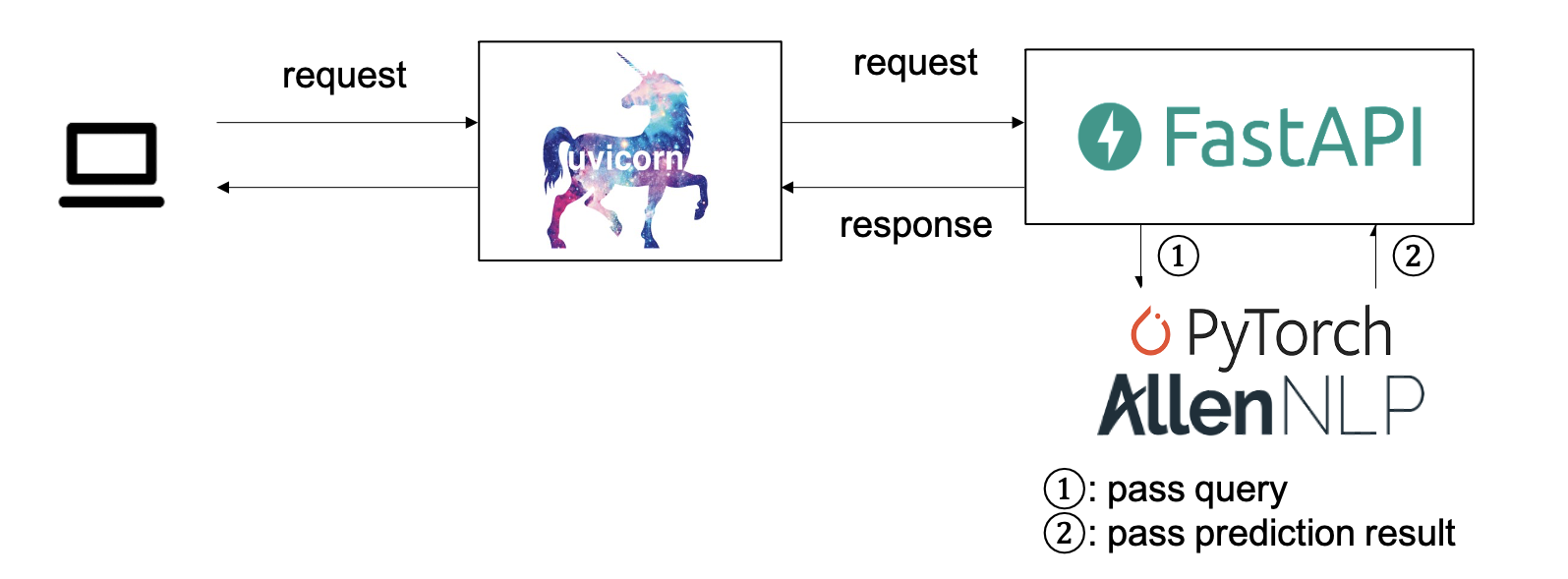
今回は、検索クエリ(例えば”iPhone 最新”等)をリクエストボディとして受け取り、それをFastAPI経由で予測モデルに渡すようにします。予測結果がjsonとして返ってきます。
実装について
前回の記事で、学習モデルを用いて、任意の文字列(タイトル、検索クエリ)に対して埋め込みを吐き出す部分の実装を行いました。
今回は、この実装と、近似近傍探索ライブラリfaissを用いることで、
①[準備]探索対象となる全記事の埋め込み変換
②記事埋め込みのfaissへの格納
③実際の検索
この順に実装していきたいと思います。
faissとは?
近似近傍探索ライブラリの一種です。C++ベースの実装ではあるものの、pythonのインターフェースも用意しており、pythonからも大変使いやすくなっています。
近似近傍探索ライブラリには、annoyなどもあるようです。
[準備]探索対象となる全記事の埋め込み変換
前回用意したデータセットのイテレータを用いて、train及びdevデータの各記事タイトルを埋め込みへと変換します。
emb_dumper.py
import pickle
from allennlp.data import (
DataLoader,
DatasetReader,
Instance,
Vocabulary,
TextFieldTensors,
)
from allennlp.predictors import Predictor
from allennlp.common.util import JsonDict
from tqdm import tqdm
import os
class EmbeddingEncoder(Predictor):
def predict(self, sentence: str) -> JsonDict:
# This method is implemented in the base class.
return self.predict_json({"context": sentence})
def _json_to_instance(self, json_dict: JsonDict) -> Instance:
context = json_dict["context"]
return self._dataset_reader.text_to_instance(mention_uniq_id=None,
data={'title': context})
class ArticleKB:
def __init__(self, model, dsr, config):
self.predictor = EmbeddingEncoder(model, dsr)
self.dsr = dsr
self.train_mention_ids, self.dev_mention_ids, self.mention_id2data = \
dsr.train_mention_ids, dsr.dev_mention_ids, dsr.mention_id2data
self.config = config
self._dump_dir_maker()
if not os.path.exists(self.config.dump_emb_dir+'kbemb.pkl'):
mention_idx2emb = self._article_emb_iterator_from_train_and_dev_dataset()
with open(self.config.dump_emb_dir+'kbemb.pkl', 'wb') as f:
pickle.dump(mention_idx2emb, f)
self.mention_idx2emb = mention_idx2emb
else:
with open(self.config.dump_emb_dir+'kbemb.pkl', 'rb') as g:
self.mention_idx2emb = pickle.load(g)
def _article_emb_iterator_from_train_and_dev_dataset(self):
print('=== emb making from train and dev')
mention_id2emb = {}
for mention_id in tqdm(self.train_mention_ids + self.dev_mention_ids):
its_article_title_emb = self.predictor.predict(
self.mention_id2data[mention_id]['title']
)['encoded_embeddings']
mention_id2emb.update({mention_id: its_article_title_emb})
return mention_id2emb
def _dump_dir_maker(self):
if not os.path.exists(self.config.dump_emb_dir):
os.mkdir(self.config.dump_emb_dir)
Predictor クラスを継承することで、今回実装したモデルのforwardメソッドの返り値を受け取ることが可能になります。
今回実装したモデルのforward部分では
def forward(self, context,
mention_uniq_id: torch.Tensor = None,
label: torch.Tensor = None):
emb = self.mention_encoder(context)
scores = self.linear_for_classify(emb)
probs = softmax(scores, dim=1)
output = {}
if label is not None:
loss = self.loss(scores, label)
self.accuracy(probs, label)
output['loss'] = loss
output['logits'] = scores
output['probs'] = probs
output['mention_uniq_id'] = mention_uniq_id
output['encoded_embeddings'] = emb
return output
としており、ラベルが存在しないテキストを引数として受け取った場合でもencoded_embeddingsに埋め込みが格納されます。
記事埋め込みのfaissへの格納
上記のようにして各記事の埋め込みを用意した後、faissへの格納を行います。と言っても、行列に変換してfaissに渡してあげるだけで可能です。
ただし、faissへ格納する行列のインデックスと、実際の記事のインデックスとを混合しないように注意して実装します。
import faiss
import numpy as np
class ArticleTitleIndexerWithFaiss:
def __init__(self, config, mention_idx2emb, dsr, kbemb_dim=768):
self.config = config
self.kbemb_dim = kbemb_dim
self.article_num = len(mention_idx2emb)
self.mention_idx2emb = mention_idx2emb
self.dsr = dsr
self.search_method_for_faiss = self.config.search_method_for_faiss
self._indexed_faiss_loader()
self.KBmatrix, self.kb_idx2mention_idx = self._KBmatrixloader()
self._indexed_faiss_KBemb_adder(KBmatrix=self.KBmatrix)
def _KBmatrixloader(self):
KBemb = np.random.randn(self.article_num, self.kbemb_dim).astype('float32')
kb_idx2mention_idx = {}
for idx, (mention_idx, emb) in enumerate(self.mention_idx2emb.items()):
KBemb[idx] = emb
kb_idx2mention_idx.update({idx: mention_idx})
return KBemb, kb_idx2mention_idx
def _indexed_faiss_loader(self):
if self.search_method_for_faiss == 'indexflatl2': # L2
self.indexed_faiss = faiss.IndexFlatL2(self.kbemb_dim)
elif self.search_method_for_faiss == 'indexflatip': #
self.indexed_faiss = faiss.IndexFlatIP(self.kbemb_dim)
elif self.search_method_for_faiss == 'cossim': # innerdot * Beforehand-Normalization must be done.
self.indexed_faiss = faiss.IndexFlatIP(self.kbemb_dim)
def _indexed_faiss_KBemb_adder(self, KBmatrix):
if self.search_method_for_faiss == 'cossim':
KBemb_normalized_for_cossimonly = np.random.randn(self.article_num, self.kbemb_dim).astype('float32')
for idx, emb in enumerate(KBmatrix):
if np.linalg.norm(emb, ord=2, axis=0) != 0:
KBemb_normalized_for_cossimonly[idx] = emb / np.linalg.norm(emb, ord=2, axis=0)
self.indexed_faiss.add(KBemb_normalized_for_cossimonly)
else:
self.indexed_faiss.add(KBmatrix)
def _indexed_faiss_returner(self):
return self.indexed_faiss
def search_with_emb(self, emb):
_, faiss_search_candidate_result_kb_idxs = self.indexed_faiss.search(
np.array([emb]).astype('float32'),
self.config.how_many_top_hits_preserved)
top_titles = []
for kb_idx in faiss_search_candidate_result_kb_idxs[0]:
mention_idx = self.kb_idx2mention_idx[kb_idx]
candidate_title = self.dsr.mention_id2data[mention_idx]['title']
top_titles.append(candidate_title)
return top_titles
一つ前のセクションで作成した、mention_idx2emb を、_indexed_faiss_KBemb_adderメソッドを用いて格納しています。
今回は探索手法としてL2距離をデフォルトでは用いています。コサイン距離での探索を行う場合は、格納時にノルムの正規化が必要となるので注意しましょう。
実際の検索
main.py に予測のサンプルを追記してあります。
# load kb
article_kb_class = ArticleTitleIndexerWithFaiss(
config=config, mention_idx2emb=mention_idx2emb, dsr=dsr, kbemb_dim=768
)
top_titles = article_kb_class.search_with_emb(
emb=emb_dumper.predictor.predict('iPhoneとパソコン')['encoded_embeddings'])
予測部分では、再びPredictor.predictメソッドを再利用しています。
"iPhoneとパソコン"の推薦記事検索結果は、トップ順に以下のようになりました。似たワードが出ていることから、うまく推薦できているように見えますね。
[
'Android版の「LINE」に、新プラットフォーム「LINE Channel」提供サービスとして「LINE占い」を先行公開!仮想通貨「LINEコイン」も導入【Androidアプリ】',
'ウィルコム、世界的な色彩規格のリーディングカンパニーであるPANTONE社とのコラボPHS「PANTONE WX01SH」を発表!',
'Microsoft、Windows Phone 7.x搭載端末向けの最新「Windows Phone 7.8」を発表!Windows Phone 8の機能を先取り',
'ウィルコム初の「PANTONE」ブランドのPHS音声端末「PANTONE PHS WX01SH」を写真で紹介【レポート】',
'Google、iOS向けWebブラウザー「Chrome」とクラウドストレージ「Google Drive」の専用アプリを提供開始!Android向け「Chrome」も正式版に'
]
FastAPIを用いたAPI化
更に、このモデルを用いて、レコメンドエンジンをAPI化することを考えます。
冒頭の構成図をもう一度再掲します。
uvicorn, FastAPI経由で検索クエリをモデルに渡し、推薦記事のタイトルがjsonで返ってくるAPIを作製します。
FastAPI上での予測モデル呼び出し
import uvicorn
from fastapi import FastAPI, Query, Path, Body
from pydantic import BaseModel, Field
from main import main
app = FastAPI()
article_kb_class, emb_dumper = main()
class Article(BaseModel):
title: str
@app.get("/hello")
def hello():
return {"Hello": "World!"}
@app.post("/request/")
async def predict_nearest_title(article: Article):
top_titles = article_kb_class.search_with_emb(
emb=emb_dumper.predictor.predict(article.title)['encoded_embeddings'])
return top_titles
リクエストボディはBaseModelを継承することで定義が出来ます。
今回は/requestへ検索クエリをリクエストボディとして渡し、予測結果が返ってくるのを実際に見てみます。
uvicornによるFastAPIの起動
# 実験が一回でも終了していれば、1行目は省略可能
$ python3 main.py -num_epochs 10
$ uvicorn api:app --reload --host 0.0.0.0 --port 8000
FastAPIは各メソッドを自動でドキュメント化してくれるので、今回は実際に/docs/を見てみましょう。
docsの確認
起動しているサーバ下でlocalhost:8000/docs を見てみましょう。
(ローカルでない他のサーバで起動している場合、適宜事前にポートフォワーディングしておきましょう。)
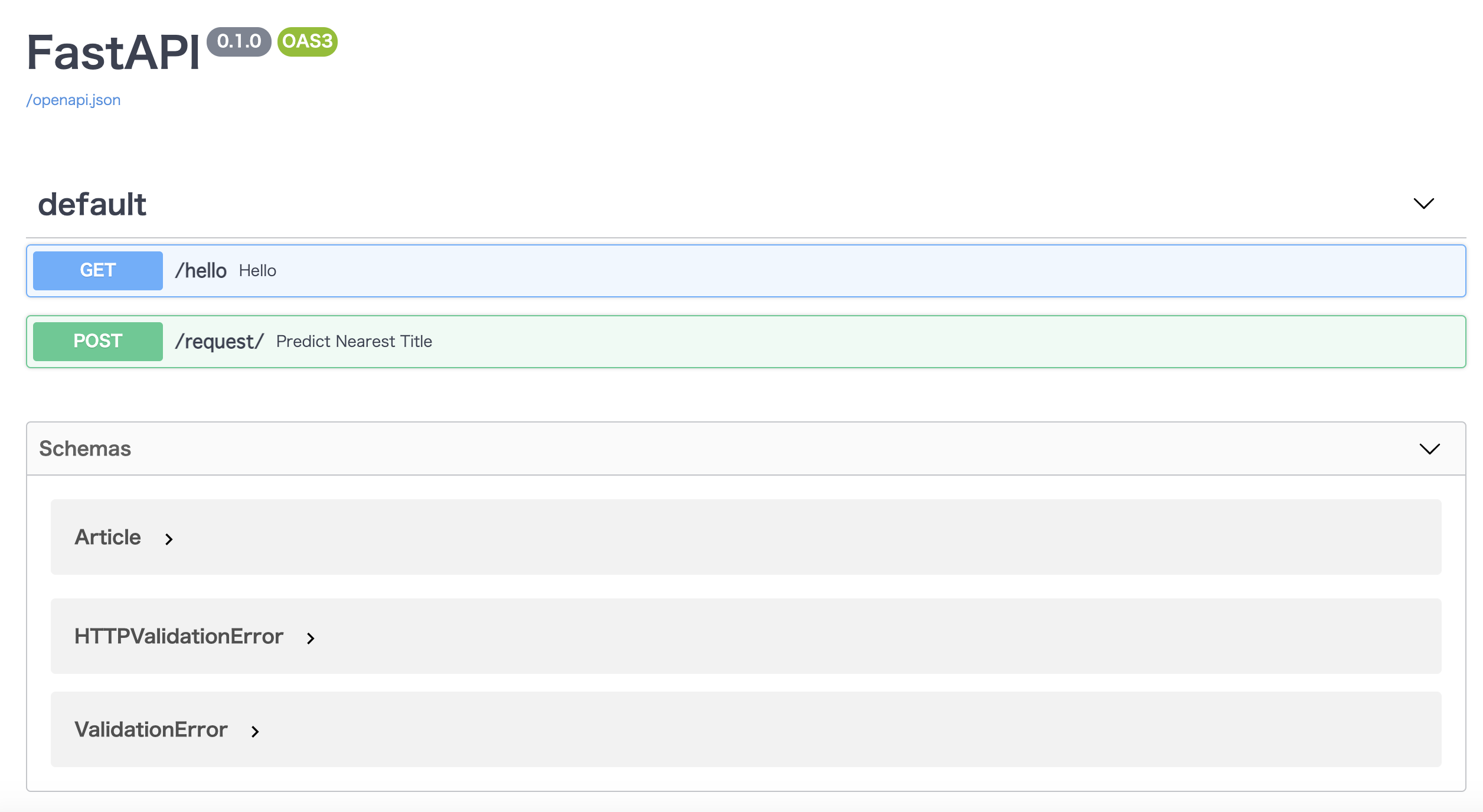
実際にrequestメソッドがPOSTメソッドとして定義されていることが確認できます。
docsインターフェース経由での予測確認
実際にここでも予測とその結果を見てみましょう。先程Articleクラスで渡すtitleを定義しました。ここでもそのように渡してみましょう。

Executeを押して、結果を見てみましょう。

"食べ"に関連するワードを含む記事が推薦されていることが確認できます。キン肉マンの"肉"も反応しているのは、予測モデルの改良が必要そうですね。
"Mac iPhone" でもクエリを与えてみます。
[
"ウィルコム初の「PANTONE」ブランドのPHS音声端末「PANTONE PHS WX01SH」を写真で紹介【レポート】",
"Google、iOS向けWebブラウザー「Chrome」とクラウドストレージ「Google Drive」の専用アプリを提供開始!Android向け「Chrome」も正式版に",
"渋谷駅の駅ビルで通り魔",
"今日の運勢は?タロットで占おう!「タロットby Hangame」【Androidアプリ】",
"5000以上のタイトルが見放題!使ってわかった楽しすぎる「dマーケット VIDEOストア Powered by BeeTV」の秘密に迫る"
]
テクノロジー関連の記事が出ていますね。
まとめ
BERTを用いて記事推薦モデルを2記事に渡って作りました。実際には予測のパフォーマンスを高速化するために、検索クエリの事前バッチ処理のスケジュール化なども考えられます。
コードは
にあります。よければクローンして遊んでみて下さい。