はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 22日目にあたる記事になります。
今回はAIを使用したAWSサービスを対象とした記事が良いということでしたのでサービスの説明を読んでいて面白そうだったAmazonTranscribeというサービスを使ってみました。
AmazonTranscribeとは
AmazonTrandcribeとは自動音声認識と呼ばれる深層学習のプロセスを使用して音声をテキストへ変換してくれるサービスです。
今回はReal-time transcriptionというリアルタイムでのテキストへの文字起こし機能とTranscription jobsという録音データからのテキストへの文字起こし機能を使ってみたいと思います。
Real-time transcription
まずはReal-time transcriptionを使用してみます。
AWSコンソールからAmazon Transcribeを選択。
機能の一覧からReal-time transcriptionを選択すると以下のような画面へ遷移します。
次にLanguageでJapanese,JP(ja-JP)を選択し右上のStart streamingを選択します。
後はマイクに喋りかけるだけです。
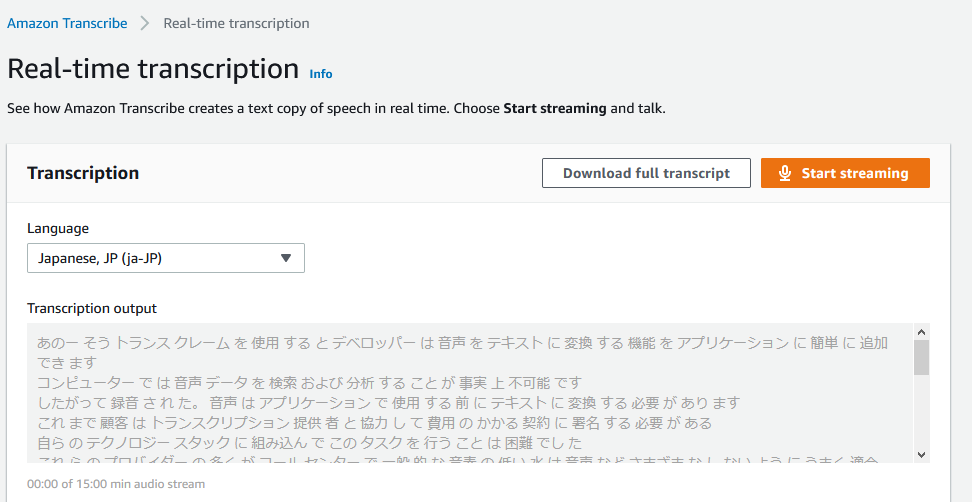
すると喋りかけた内容がコンソール画面上に表示されます。
今回はAWS公式ののAmazonTranscribe紹介文を文字起こしできるか試しています。
一通り文字起こししてみたい内容を喋り終わったらstop streamingを選択することで終了します。
自分が喋った内容はjson形式のファイルとしてダウンロードすることができます。
atom等で内容を確認することができます。自分の環境ではatmよりもメモ帳のほうが文字起こし部分を見つけやすかったです。
Transcription jobs
次は録音していたデータからの文字起こしを行ってみます。
Create transcription jobを選択してjobを作成していきます。
今回はtestという名前のjobを作成していきます。
Model typeはGeneral modelを選択し、Language settingsはSpecific languageを選択します。
Custom language modelは特定のユースケースに特化したモデルとなるため今回は選択しません。
Language settingsのAutomatic language identificationは文字起こしを行う言語がわからない際に選択します。
今回は日本語ということがわかっているためSpecific languageを選択しました。
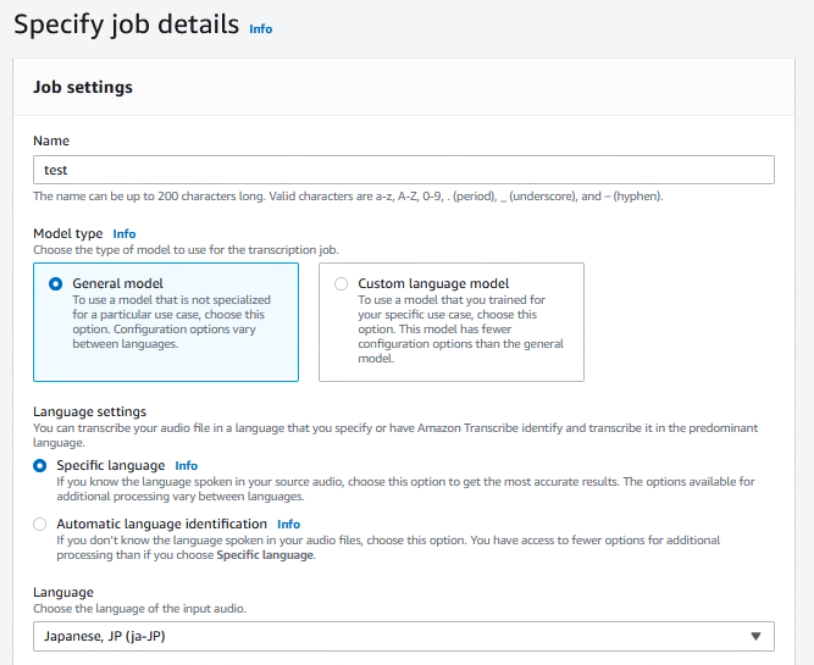
他のオプションは今回は選択せずにjobを実行します。
しばらく待つとjson形式で文字起こしされたデータをダウンロードできます。
以下が今回の文字起こしデータです。
文字起こしの際に使った文章はReal-time transcriptionの際と同じAWS公式のAmazon Transcribe紹介文を使っています。
アマゾン トランス クリーム を 使用 する と デベロッパー は 音声 を テキスト に 変換 する 機能 アプリケーション に 簡単 に。 追加 でき ます コンピューター で は 音声 データ は 検索 および 分析 する こと は 事実 上 不可能 です したがって 録音 さ れ た。 音声 は アプリケーション で 使用 する 前 に テキスト に 変換 する 必要 が、 あり ます
これ まで 顧客 は トランスクリプション を 提供 者 と 協力 し て 費用 の かかる 契約 に 署名 する 必要 が あり 自ら の テクノロジー スタック に 組み込ん で この タスク を、 行う こと は 困難 でし た。
これ ら の プロ プロバイダー の 多く は コール センター で 一般 的 な 音質 の 低い 通話 音声 など 様々 な し。 ない よう に うまく 適合 し、 ない 形式 の テクノロジー を 使用 し て いる ため 精度 が 低下 し、 ます
あのー その トランス 位 部 は 自動 音声 認識 え え そう よ オートマチック スピーチ で コンビネーション と 呼ば れる 深層 学習 プロセス を 使っ て 迅速 かつ 高 精度 に 音声 を テキスト に 変換 し、 ます
アマゾン トランス 位 部 は カスタマーサービス の 通話 の 文字 起こし 工藤 クローズド キャプション や 字幕 の 自動 作成 完全 に 検索 可能 な アーカイブ を 作成 する 際 に おけ る メディア さん の メタデータ の 生成 に 使用 でき ます
アマゾン と 卵 スクライブ メディカル を 使用 する と 医療 関連 の 音声 を テキスト に。 変換 する 機能 臨獣 ドキュメント は アプリケーション に 追加 でき ます
これだけでも役に立つのですがなかなかきちんと認識してくれない語句もあります。
その際に役に立つのがCustom vocabularyという機能です。
こちらの機能は認識しにくい語句を先に登録しておくことでその語句の認識性を高める事ができます。
今回は先程Transcription jobsを使用した際に認識しづらかった語句を登録してみましょう。
txtファイルに認識してほしい語句を一行ずつ入力し、好きな名前でファイルを保存します。
今回はアマゾントランスクライブやトランスクリプション提供者といった語句を登録させることにします。
次にコンソールからCustom vocabularyを選択し、Create vocabularyから登録することができます。
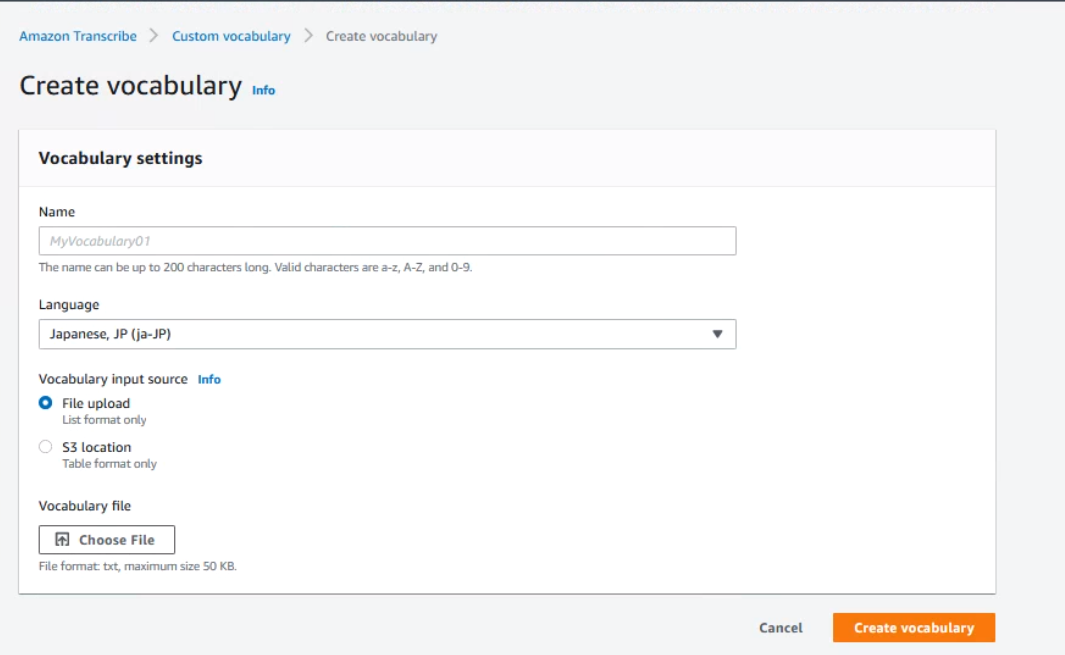
こちらで登録した後に再度Transcription jobsを再度作成します。
すると前回はなかったCustomizationという項目が増えていますのでここで先程作成したCustom vocabularyのjobを選択します。
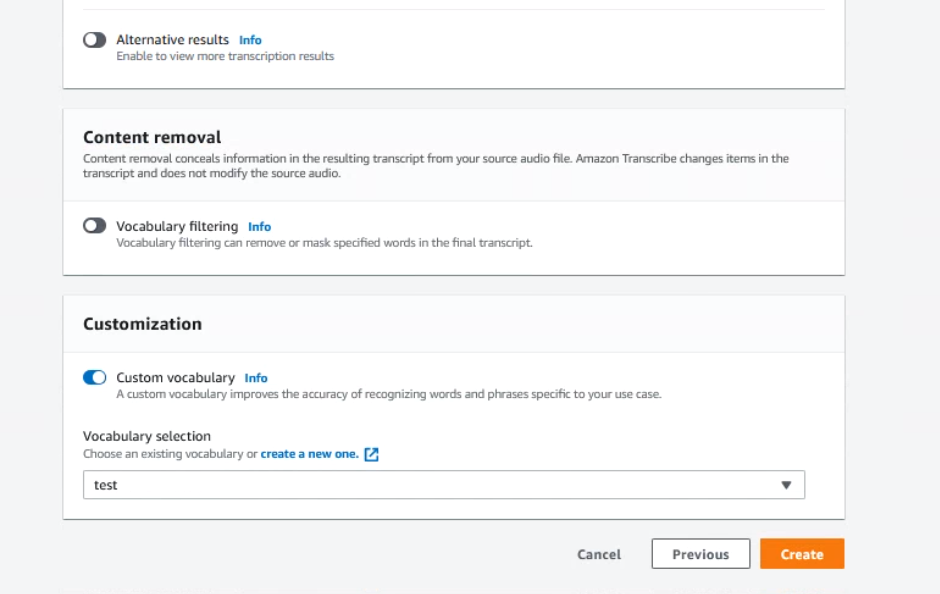
この状態で再度文字起こしされたデータを確認してみます。
以下が今回の文字起こしデータです。
アマゾントランスクライブ を 使用 する と デベロッパー は 音声 を テキスト に 変換 する 機能 アプリケーション に 簡単 に。 追加 でき ます
コンピューター で は 音声 データ は 検索 および 分析 する こと は 事実 上 不可能 です
したがって 録音 さ れ た。 音声 は アプリケーション で 使用 する 前 に テキスト に 変換 する 必要 が、 あり ます
これ まで 顧客 は トランスクリプション提供者 と 協力 し て 費用 の かかる 契約 に 署名 する 必要 が あり 自ら の テクノロジー スタック に 組み込ん で この タスク を、 行う こと は 困難 でし た
これ ら の プロ プロバイダー の 多く は コール センター で 一般 的 な 音質 の 低い 通話 音声 など 様々 な し。 ない よう に うまく 適合 し ない 形式 の テクノロジー を 使用 し て いる ため 精度 が 低下 し ます
アマゾントランスクライブ は 自動音声認識 え え そう よ オートマチック スピーチ で コンビネーション と 呼ば れる 深層 学習 プロセス を 使っ て 迅速 かつ 高 精度 に 音声 を テキスト に 変換 し、 ます
アマゾントランスクライブ は カスタマーサービス の 通話 の 文字 起こし 工藤 クローズド キャプション や 字幕 の 自動 作成 完全 に 検索 可能 な アーカイブ を 作成 する 際 に おけ る メディア さん の メタデータ の 生成 に 使用 でき ます
アマゾントランスクライブ メディカル を 使用 する と 医療 関連 の 音声 を テキスト に。 変換 する 機能 臨獣 ドキュメント は アプリケーション に 追加 でき ます
すると前回は認識してくれていなかったアマゾントランスクライブ、トランスクリプション提供者といった語句を認識してくれるようになっています。
他にも認識しづらかった語句を登録していくことで文字起こしの精度を上げることができます。
他の機能として不適切な語句を登録しておくことでその語句をマスクするVocabulary filteringという機能もあります。
Custom vocabularyとVocabulary filteringはReal-time transcriptionでも使用することができます。
まとめ
今回AmazonTranscribeを使ってみたのですがCustom vocabularyを使い精度を上げていくことでかなり使いやすくなると感じました。
時間がなく複数人の声が混じっている録音ファイル等を準備することができなかったため試せなかったのですが複数人が対象の際の精度次第ですが会議の議事録を取る際に予め録音しておき後ほど録音ファイルから文字起こしすることで議事録とすることも可能となるかもしれません。