作るもの
text = \
"""スープが美味しい。
麺は縮れ麺で、スープと相性がよい。
値段はやや高いものの、総じて満足感は高い。"""
get_noun_adj_pairs(text)
[['スープ', '美味しい'], ['相性', 'よい'], ['値段', '高い'], ['満足感', '高い']]
概要
冒頭の例のように、レビューテキストから名詞と形容詞のペアを抽出 してみます。
これを複数のレビューで集計することで、レビュー文を1つずつ読まずとも、傾向としてどんな部分がどういった評価を受けているのか が見えてきそうですよね。
(例えば、ラーメン店であれば、スープ、麺、値段それぞれがどんな評価が多いのか、とか)
基本的には、以下のような流れで実装しています。
- GiNZAで形態素解析+係り受け解析
- 名詞・形容詞のペアを抽出
- 特定の係り受け関係であれば採用
やや苦慮した部分は、以下の2点です。
- 複数の形態素からなる形容詞 の扱い(例:高価な=高価+な)
- GiNZAの係り受け解析結果(UD: Universal Dependency) の扱い
両者とも、私の知識が十分でなく、今回の扱いが適切でない可能性も多分にあります。その点はご了承ください(お気づきの点はコメントいただけるととても嬉しいです!)
ソースコード
コードの詳細は、こちらのNotebookをご参照ください。
実行環境は、Google Colaboratoryを想定しています。
Google Colaboratoryで開く場合はこちらから。
参考文献
- 河野ら, "不特定分野の商品レビューを対象とした評価情報の自動認識" (2017)
- M3 Tech Blog - GiNZAと患者表現辞書を使って患者テキストの表記ゆれを吸収した意味構造検索を試した
- 金山ら, "日本語 Universal Dependencies の試案" (2015)
- Universal Dependencies の日本語の情報ページ
1. GiNZAで形態素解析+係り受け解析
GiNZAは、日本語自然言語処理オープンソースライブラリです。
今回使いたい形態素解析や係り受け解析の他にも、単語のベクトル化や固有表現抽出なども可能で多機能です。ちなみに、高速・軽量なNLPフレームワークである spaCy と形態素解析器 SudachiPy を用いて実装されています。
まずは、GiNZAをインストールします。
! pip install -U ginza ja_ginza
1.1 基本的な使い方
GiNZAの使い方を簡単に記載しておきます。
spaCyを用いてGiNZAの日本語モデル('ja_ginza')を読み込み、それにテキストを入力するだけです。すると、文章が語単位に分割され、各語の原形や品詞情報を取得できるようになります。
# GiNZAの日本語モデルと読み込む
import spacy
nlp = spacy.load('ja_ginza')
# 解析パイプラインを適用
doc = nlp("温かい雰囲気が素敵。")
# 形態素解析の結果を確認
for token in doc:
print(token.text, token.lemma_, token.pos_) # 表層形, 原形, 品詞
# 表層形 原形 品詞
温かい 温かい ADJ
雰囲気 雰囲気 NOUN
が が ADP
素敵 素敵 ADJ
。 。 PUNCT
ここでの「品詞」は、次節に記載する Universal Dependenciesの定義での品詞 です。
中学校の現代文で学んだような、日本語における品詞(例:名詞、形容詞)の取得については後述します。
1.2 係り受け解析(Universal Dependencies)
続いて、係り受け解析です。
GiNZA(spaCy)は、Universal Dependenciesを用いた係り受け解析 を提供しています。
Universal Dependenciesは、多言語で一貫した構文構造とタグセットを定義するという取り組み とのことです。
当然ながら言語それぞれに構文が異なるため、従来は言語毎で異なる構文表現を用いていたが、それを統一的に扱っていこうという取り組み…と私は理解しています。
ということで、GiNZAの係り受け解析の結果を見てみましょう。
# 係り受け解析の結果を確認
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True, options={'distance': 90})
for token in doc:
for child_token in token.children:
print('{} --> {} : {}'.format(token.text, child_token.text, child_token.dep_))
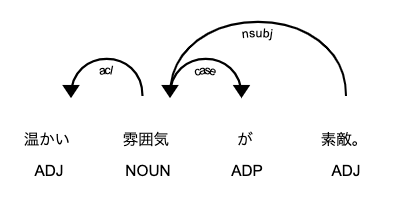
雰囲気 --> 温かい : acl
雰囲気 --> が : case
素敵 --> 雰囲気 : nsubj
素敵 --> 。 : punct
矢印の下に記載されているラベル(acl, nsubj, case)が係り受け解析の結果です。2つの語の関係性を表しています。
参考文献[3]よると、それぞれの意味は以下の通りです。
- acl:連体修飾節。
- nsubj:主格で述語に係る名詞句。
- case:助詞による格の表示。
ちなみに、GiNZAの出力結果は、文献[3]の例と一致しないものもありました。文献[3]がやや古いため、UDの日本語への適用方法がその後変更されたのかもしれません。
1.3 日本語品詞情報を取得する
前述したように、GiNZAのtoken.pos_にはUD定義の品詞(例:NOUN)が入っていました。
ここでは、日本語の品詞情報(例:名詞、形容詞)を取得したいと思います。
GiNZAは内部で形態素解析器SudachiPyを使用しており、その品詞特定の結果がtoken.tag_に格納されています。
ただ、"名詞-普通名詞-一般"のようにハイフン結合の文字列として格納されていてやや使いづらいため、Tokenクラスを少し拡張して、使いやすくしたいと思います。
# 品詞情報を取得するためTokenを拡張する
from spacy.tokens import Token
def get_jp_pos(token, idx):
"""日本語の品詞情報を取得する.
GiNZAでは、token.tag_に "名詞-普通名詞-一般" のように格納されている.
参考)UniDicの品詞体系
https://hayashibe.jp/tr/mecab/dictionary/unidic/pos
"""
pos_list = token.tag_.split('-')
if idx < len(pos_list):
return pos_list[idx]
return None
# token._ はユーザ拡張用の変数. Token.set_extension により、独自変数を追加可能
# cf. https://spacy.io/api/token
Token.set_extension("jp_pos_main", getter=lambda x: get_jp_pos(x, 0))
Token.set_extension("jp_pos_sub", getter=lambda x: get_jp_pos(x, 1))
doc = nlp("温かい雰囲気が素敵。")
for token in doc:
print(token.text, token._.jp_pos_main, token._.jp_pos_sub)
温かい 形容詞 一般
雰囲気 名詞 普通名詞
が 助詞 格助詞
素敵 形状詞 一般
。 補助記号 句点
これにより、日本語の品詞情報に、token._.jp_pos_main token._.jp_pos_subからアクセスできるようになりました。
2. 複数の形態素からなる形容詞を抜き出す
続いて、GiNZAの解析結果に基づいて、形容詞を抜き出します。
「品詞が特定されているんだから簡単じゃないの?」と感じると思いますが、それほど簡単ではありません。
例えば、「美しい」は一語で形容詞として抽出されるので、簡単に抜き出せます。一方で、「静かな」は形態素解析の結果「静か」「な」に分解されて しまいます。その上、「静か」は「形 状 詞」と判定されるため、形容詞として抜き出せません。
そこで、複数の形態素からなる形容詞を特定し、結合した上で抜き出す ことをしてみます。
今回の対象は2語の連結までとし、形容詞か否かはルールにより特定します。特定方法は、参考文献[1]を参考にしました。
def compound_adjective(token):
"""複合語の形容詞を返す. 該当しない場合はNone."""
# 次のtokenを取得
next_token = token.doc[token.i+1] if not token.is_sent_end else None
prev_token = token.doc[token.i-1] if not token.is_sent_start else None
if next_token is not None:
# 形容動詞 (形状詞 + な) ... 静かな
if (token._.jp_pos_main == '形状詞') and (next_token.text == 'な'):
return token.text + 'な'
# 名詞 + な ... 元気な
if (token._.jp_pos_main == '名詞') and (next_token.text == 'な'):
return token.text + 'な'
# 動詞 + 形容詞的 ... わかりやすい, 怒りっぽい
if (token._.jp_pos_main == '動詞') and (next_token._.jp_pos_sub == '形容詞的'):
return token.text + next_token.text
if prev_token is not None:
# 名詞 + ない ... 問題ない, 仕方ない
if (prev_token._.jp_pos_main == '名詞') and (token._.jp_pos_main == '形容詞') and (token._.jp_pos_sub == '非自立可能'):
return prev_token.text + token.text
# 該当しない場合は None
return None
texts = [
'この本はわかりやすい。',
'機能としては問題ない。',
'高価な腕時計をした男性。',
'穏やかな人。',
'先生は怒りっぽい。',
]
for text in texts:
print('=' * 30)
print(text)
doc = nlp(text)
for token in doc:
ret = compound_adjective(token)
if ret:
print('- {} --> {}'.format(token.text, ret))
==============================
この本はわかりやすい。
- わかり --> わかりやすい
==============================
機能としては問題ない
- ない --> 問題ない
==============================
高価な腕時計をした男性。
- 高価 --> 高価な
==============================
穏やかな人。
- 穏やか --> 穏やかな
==============================
先生は怒りっぽい。
- 怒り --> 怒りっぽい
複数の形態素からなる形容詞も抜き出せていることがわかります。
ただし、今回のこのルールでは、(1) 3語以上からなるもの(例:緊迫 し た)や、(2)ルールに該当しないもの(例:落ち着い た ← 動詞+助動詞)は抜き出すことができません。要改善点です。
3. 名詞・形容詞ペアを抽出する
無事、名詞と形容詞を抜き出せるようになりました。
(複合名詞は今回は対象外とします。複合名詞は専門用語などで多く、今回は不要と考えました。)
最後に、名詞と形容詞のペアから、係り受け解析結果を用いて、特定の関係性のペアのみを抽出 していきます。
具体的には、1.2の例で示した、以下の2つの関係性を抽出します。
- acl:連体修飾節(名詞 → 形容詞)
- nsubj:主格で述語に係る名詞句(形容詞 → 名詞)
token.childrenに、修飾先(矢印の先)の語が格納されているので、(1) 名詞と形容詞のペアとなっており、(2) 係り受けが上記に示したものである場合を取り出します。
def is_adjective(token):
"""形容詞か否かと、形容詞の場合はその文字列を返す."""
comp_adj = compound_adjective(token)
if comp_adj:
return True, comp_adj
elif token._.jp_pos_main == '形容詞':
return True, token.lemma_
return False, None
def get_noun_adj_pairs(text):
"""名詞と形容詞のペアを返す."""
noun_types = ('名詞') #('名詞', '代名詞')
pairs = []
doc = nlp(text)
for token in doc:
par_is_adj, par_adj_text = is_adjective(token)
for child_token in token.children:
if par_is_adj and (child_token._.jp_pos_main in noun_types) and (child_token.dep_ == 'nsubj'):
pairs.append([child_token.text, par_adj_text])
elif (token._.jp_pos_main in noun_types):
chi_is_adj, chi_adj_text = is_adjective(child_token)
if chi_is_adj and (child_token.dep_ == 'acl'):
pairs.append([token.text, chi_adj_text])
return pairs
text = 'スープが美味しい。麺は縮れ麺で、スープと相性がよい。値段はやや高いものの、総じて満足感は高い。'
get_noun_adj_pairs(text)
[['スープ', '美味しい'], ['相性', 'よい'], ['値段', '高い'], ['満足感', '高い']]
名詞・形容詞のペアを正しく抽出できていますね!
おまけ:食べログレビューに適用してみる
実際の食べログレビューのテキストに適用してみたいと思います。
横浜のフレンチレストラン「霧笛楼」のレビューから1件選びました → こちら
霧笛楼は、1981年に横浜元町に創業したフレンチレストランで、横浜開港当時を彷彿とさせるクラシックな洋館の建物が特徴的です。フランス菓子店でもあり?、「横濱煉瓦」というチョコレート菓子が横浜土産として有名です、多分。
ちなみに、私は行ったことはありません。横濱煉瓦は好きです。
それでは、作成した関数を適用してみます。
text = \
"""開港当時に人気だった港崎町遊郭の料亭『岩亀楼』をイメージした佇まいの
(中略)
接客は申し分なく対応も完璧でした。(*'▽'*)"""
noun_adj_pairs = get_noun_adj_pairs(text)
[['お菓子', '有名な'],
['世界観', '良し'],
['雰囲気', 'オリエンタルな'],
['建築', '好きな'],
['感じ', '切ない'],
['こと', '大切な'],
['こと', '大切な'],
['絵皿', 'きれいな'],
['雰囲気', 'エレガンスな'],
['和', '素晴らしい'],
['食材', '新鮮な'],
['美味しさ', 'ことない'],
['サービス', '申し分なく'],
['全て', '素晴らしい'],
['体験', '素晴らしい'],
['フレンチ', '伝統的な'],
['雰囲気', 'クラシカルな'],
['接客', '申し分なく']]
お店の評価としての、名詞と形容詞のペアが抜き出せていますね。
このペアのリストを見るだけで、どんなお店か想像できそうです。
今回はレビュー1件への適用でしたが、複数件のレビューに適用した上で、「味」「雰囲気」「サービス・接客」「価格・値段」などとペアとなる形容詞を集計することで、レビュー全体での評価の傾向が見えてきそうです。
まとめ
GiNZAを用いて、文章から名詞と形容詞のペアを抽出 してみました。
これをレビューテキストに適用することで、どんな部分がどのように評価されているか を抜き出す、レビュー分析が可能となります。(実際に、食べログレビューに適用して、お店に対する評価情報を抜き出せることを確認しました。)
一方で、残課題も多い結果となりました。
- 複合的な形容詞の抽出に漏れがある
- Universal Dependenciesの理解が不十分で、抽出漏れがありそう
これらについては引き続き知見を深めていきたいと思います。
最後までお読みいただき、ありがとうございました。
少しでも楽しんでいただけたり、参考になる部分があったりしましたら幸いです。
それでは!(*ˊᗜˋ)ノシ