概要
はじめに
- 某MedTech企業でエンジニア組織のマネジメントを担当しています。
- あくまで現時点(2024/1月頭)での情報からまとめていくので、数ヶ月もすれば陳腐化すると思います。
この記事のゴール
- 実践を意識したいので、以下のような要求/要件を過程して、これらを実現するための方針をまとめる資料とします。
- 中小企業規模でLLMを利用した日本国内向けサービス提供を考えている
- 画像系やマルチモーダルの生成AIは一旦考えないことにする
- Webアプリから機能を汎用的に使いたいため、LLMが提供する機能はRESTAPIなどのWebインタフェースで利用できるようにすること
- chatGPTのような入力に対する出力が得られれば機能として十分であると考える
- 場合によってはパラメータ数が低い軽量なモデルでも十分な可能性があるので、性能検証してどのモデルを採用するか決めるプロセスも含める
- モデル自体に開発コストをあまりかけられないので、ファインチューニングも考えない
- スモールスタートしたいので無料〜月数万円ぐらいの課金としたい
- 性能検証での初期投資はできずGPUは購入できない
- 長々と書きましたが、とりあえずほぼコストかけずに何か作ってスモールスタートでサービスインさせたいという要求です。
- 中小企業規模でLLMを利用した日本国内向けサービス提供を考えている
- WebアプリやWebAPIの開発方法を解説する記事ではないことをご了承願います。
検討順序
- まずはコストや開発効率性の観点で検討対象を絞り、その後に性能検証で絞り込む方針とします。
- 第一回目(本記事):モデルとAPIホスティング環境の検討
- まずはどのモデルをどうやってデプロイしてAPIサーバーとしてホスティングして利用するのがコスト的に許容できるのかを考えていきます。
- 第二回目(こちら):性能検証方法のまとめ
- 第一回目で絞った可能性として有り得そうなモデルの検証方法と結果をまとめていきます。
- 第三回目(未実施):お試しでWebアプリを作って実際に使えそうかどうか確認してみます。
(忙しい方のために)第一回目のまとめ
- 主要ベンダーのサービスでは、Gemini Proがコスト的にも開発効率的にもアドバンテージがあり有力な候補だと判断
- CPU環境でも動作する可能性のありそうなLlama-7b等を技術検証して、特定の用途で使えそうか確認していく、OSSモデルは自身で動作環境を用意するコストを考えると小規模での商用利用では検討対象外となるが、かなり軽量なモデルでも問題無いという用途もあり得るので、その検証はHuggingFaceかReplicate経由で実施していく
モデルとホスト方法の検討
主要ベンダー(OpenAI / Google / Microsoft)のサービスとモデル
- まずは主要なベンダーの生成AIサービスをそのまま使う方法を検討します。こちらに関しては当然ながらホスト方法を検討する必要がございません。
- まずは低コストだと考えられるOpenAIのchatGPT-3.5 Turboを見ていきます。
-

-
「gpt-3.5-turbo-1106」なら一問一答ぐらいを仮定して100文字(100tokenとする)入れて100文字結果を得た場合、
- ($0.001 x 100token + $0.002 x 100token) / 1000token x 150円(為替レート) = 0.045円なので、乱暴にいうと20回使って1円くらいなので、それなりに安く感じます。
- toCで月500円のサブスクなら原価で考えると、全体の中でここにかけられるのは数%でしょうか?仮に5%だと仮定すると25円なので500回/月ぐらいが限界でしょうか。
- toBで月10,000円のサブスクなら、10,000回/月ぐらいでしょうか。
- SDKもシンプルで、ホスティングのコストを考える必要がないので、ユースケースによってはありうるのではないでしょうか。
- ここにプラスで、ChatGPT Plusの$20/月もかかると思います。
-
usage limitやrate limitも気をつけるべきですが、引き上げ申請していけば問題はなさそうです。
-
- 次にGoogleを見ていきます。
- チャット形式のI/FとしてはBardが有名ですが、有料でAPIサービスを提供しているわけではなく、Bard-APIというのもありますがあくまでUnofficialで無償である限りrate limitにもかかりやすく、サービスとして組み込んだり商用利用には向いてないと推測してもよさそうです。
- 一方でGoogle DeepMindがGemini Proを2023/12/13に発表して、まだプレビュー版ですが、Gemini APIでアクセスでき、有償プランも用意されています。ただしまだGAにはなっていないようです。GAは2024年初頭予定とのこと。
-
参考:https://ai.google.dev/pricing
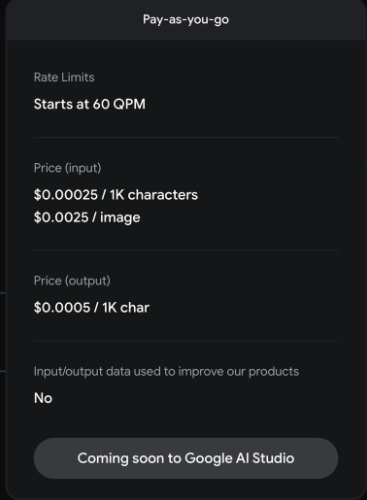
-
「gpt-3.5-turbo-1106」の1/4の価格です!!
-
- PaLM2は?
- 2023/5/10にgoogleが発表、GCPのVertexAI経由で利用することができます、今後GeminiもVertexAI経由で使うことになりそうですし、性能やコストを考慮するとGeminiが使えそうならこちらは一旦検討対象外としてもよさそうです。
- 参考:https://cloud.google.com/vertex-ai/pricing?hl=ja
- 「PaLM 2 Text Bison」が「gpt-3.5-turbo-1106」より少し安いです。
- Microsoftのcopilotは?
- Github Copilotを除いてAPIは提供していないようです、各法人単位でライセンス購入して使うサービスとのことでWebアプリから機能を使う用途に向いてなさそうです。
- Azure OpenAI Serviceというのもありますが、できることはOpenAIのサービスとあまり変わらないという印象です。
- AWSは?
- Amazon BedrockというAPI経由で基盤モデルを使えるフルマネージド型のサービスがあります、re:Invent2023ではいくつかのモデルが追加されています。
- 参考:
- Titan Text -LiteぐらいならGemini Proと同じぐらいの価格帯ですが、まだ日本語に対応していないようです。llama2もClaudeも若干高いです。
- Amazon BedrockというAPI経由で基盤モデルを使えるフルマネージド型のサービスがあります、re:Invent2023ではいくつかのモデルが追加されています。
OSSのモデル
- OSSのモデルを使う場合、自身でホスト環境を用意してAPI開発することになります。
- まずはホスティングのコストについて検討します。
- OSSモデルで有名なのはMeta社の2023/7に公開されたLlama2ですが、70億/130億/700億(7B/13B/70B)という3つのモデルがあって、70BはChatGPT3.5レベルに匹敵するぐらいだと言われていますので70Bを使えれば使えそうですが、7B/13Bも用途によっては使えないこともなさそうです、よって3モデルをホストするのにどれくらいのコストがかかるのか考えていきます。
-
参考
- https://ai-wonderland.com/entry/llama2
- https://zenn.dev/turing_motors/articles/f5f19f875bd8ba
- https://gigazine.net/news/20230313-llama-on-m1-mac/
- https://www.netone.co.jp/media/detail/20230922-02/
- https://blueqat.com/yuichiro_minato2/15576ed0-9062-4e78-a7f5-bfad72cc84f1
- https://zenn.dev/kun432/scraps/d532830c0f2260
- https://www.youtube.com/watch?v=jaM02mb6JFM
-
いくつかの先人が試してくれた結果を見る限り、ざっくりとした環境性能比較
モデル CPU/一般的なローカルマシン/入出力が数百tokenでの処理速度 7B 数十秒 13B 数分 70B 動かない -
70Bをホストするためには、VRAMが100GB以上必要そうでさらにそれを複数セッションでさばこうとすると、DGXステーション級が必要になります。よって数千万円の初期投資となり今回の用途には向きません。
-
7Bなら普通のCPU環境でもよさそう(ただし、llama.cppというパラメータを量子化して軽量化したモデルで動作させる必要がありそう)
-
13BならRTX4070とか個人向けのGPU環境レベルでよさそう
-
クラウドでGPU環境を用意するのは最低月数十万円かかるので、今回の検討対象外とします。13BはCPU環境でもメモリが多ければ使えそうですが、それなりのコストになりそうなので7Bのみ技術検証対象としてきます。
-
CPUマシンのホスト方法はVPSやAWS(EC2/Fargate)など様々ですが、月数万円でスモールスタートできると思います。
-
- その他のモデル
-
Elyza
- 東京大学松尾研究室発のAIスタートアップELYZA社が開発していて、Llama2をベースとして日本語能力を拡張するために追加事前学習を行ったモデルです。7bもあるので「ELYZA-japanese-Llama-2-7b」を検証対象としていきます。
-
PLaMo
- 「PLaMo-13B」はPFN社が2023/9/28公開した本語・英語の2つの言語のベンチマークタスクで高い性能を出しているLLMです。13bしかないようですので今回は検討対象外とします。
-
その他
- Swallow
- 東工大と産総研にチームが開発しているLLM、Llama2ベース、7bがあるのでこちらも余裕があれば検証していきます。
- Calm2-7b(CyberAgentLM2-7B)
- CyberAgentが2023/11/2に公開した日本語LLMです、こちらも余裕があれば検証していきたいです
- Swallow
-
- OSSモデルで有名なのはMeta社の2023/7に公開されたLlama2ですが、70億/130億/700億(7B/13B/70B)という3つのモデルがあって、70BはChatGPT3.5レベルに匹敵するぐらいだと言われていますので70Bを使えれば使えそうですが、7B/13Bも用途によっては使えないこともなさそうです、よって3モデルをホストするのにどれくらいのコストがかかるのか考えていきます。
- 技術検証方法について
- HuggingFaceやReplicateでホストされているモデルや公開APIについて
- あくまでお試し用途で、スモールスタートだとしてもWebアプリとの連携や商用利用には向かいないと思いますが性能検証用途には使えます。
- 今回は7Bならローカルでも動くかもしれないので、pythonのtransformers経由でサイトからローカルにロードしてから利用することになります。
- ReplicateはWebAPI公開している場合が多いようなので、コストの問題でクラウド上にGPU環境を用意する前のお試しにはよさそうです、一定数以上は課金されますが、クレジットカードも登録不要でlimit超えたとしてもその時点で止めてくれそうです。
- 現状で技術検証候補のモデルは下記
- https://huggingface.co/meta-llama/Llama-2-7b
- https://huggingface.co/meta-llama/Llama-2-7b-hf
- https://huggingface.co/meta-llama/Llama-2-7b-chat
- https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
- https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b
- https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-instruct
- https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct
- https://huggingface.co/tokyotech-llm/Swallow-7b-hf
- https://huggingface.co/tokyotech-llm/Swallow-7b-instruct-hf
- HuggingFaceやReplicateでホストされているモデルや公開APIについて
次回以降、
- 次回はまずは検証のためのデータを検討する
- 簡単な方法としてAPIでニュース情報を取得してきて下記のタスクを実行して結果を比較していく
- 予測
- 次の日に何が起きるのか、など
- リコメンド
- 今日はどういう行動をすべきか、など
- キーワード抽出
- 人名、地名、会社名の抽出、など
- 分類
- 国内/国外/エンタメ/経済/IT/科学、など
- 要約
- 各記事の要約、全記事の要約、など
- 予測
- 簡単な方法としてAPIでニュース情報を取得してきて下記のタスクを実行して結果を比較していく
- その次はどれか1つのモデルを使ってWebアプリとしてデプロイしていく