はじめに
Streamlitは、Webアプリケーションを開発するためのライブラリです。
Streamlitを使用すると、Pythonコードを簡単にWebページ上で実行することができます。
この記事では、Streamlitを使って機械学習アプリを作っていきます。
準備
1.「コマンドプロンプト」や「ターミナル」で、次のコマンドを実行します。
pip install streamlit
2.Streamlitが正常に動作することを確認します。
streamlit hello
ブラウザ画面が開けば成功です。
3.アプリケーションのエントリポイントとなるPythonファイルを作成します。例えば、app.pyという名前のファイルを作成します。
app.py
import streamlit as st
def main():
st.title('Hello Streamlit')
# ここに処理を書いていく
if __name__ == "__main__":
main()
4.「ターミナル」で作成したapp.pyがあるディレクトリに移動し、次を実行します。
streamlit run app.py
Local URL と Network URL が表示されます。
同時にブラウザ画面が開くと思います。
既に開いている場合は更新してみてください。
出力
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.11.3:8501
これで準備完了です。
アプリの機能
- ローカルから学習データ(CSV)をアップロードできる。
- カラムから特徴量・目的変数を選択できる。
- 検証データサイズを調整できる。
- 回帰分析・SVM・決定木の中からアルゴリズムを選択できる。
- 推論結果を可視化できる。
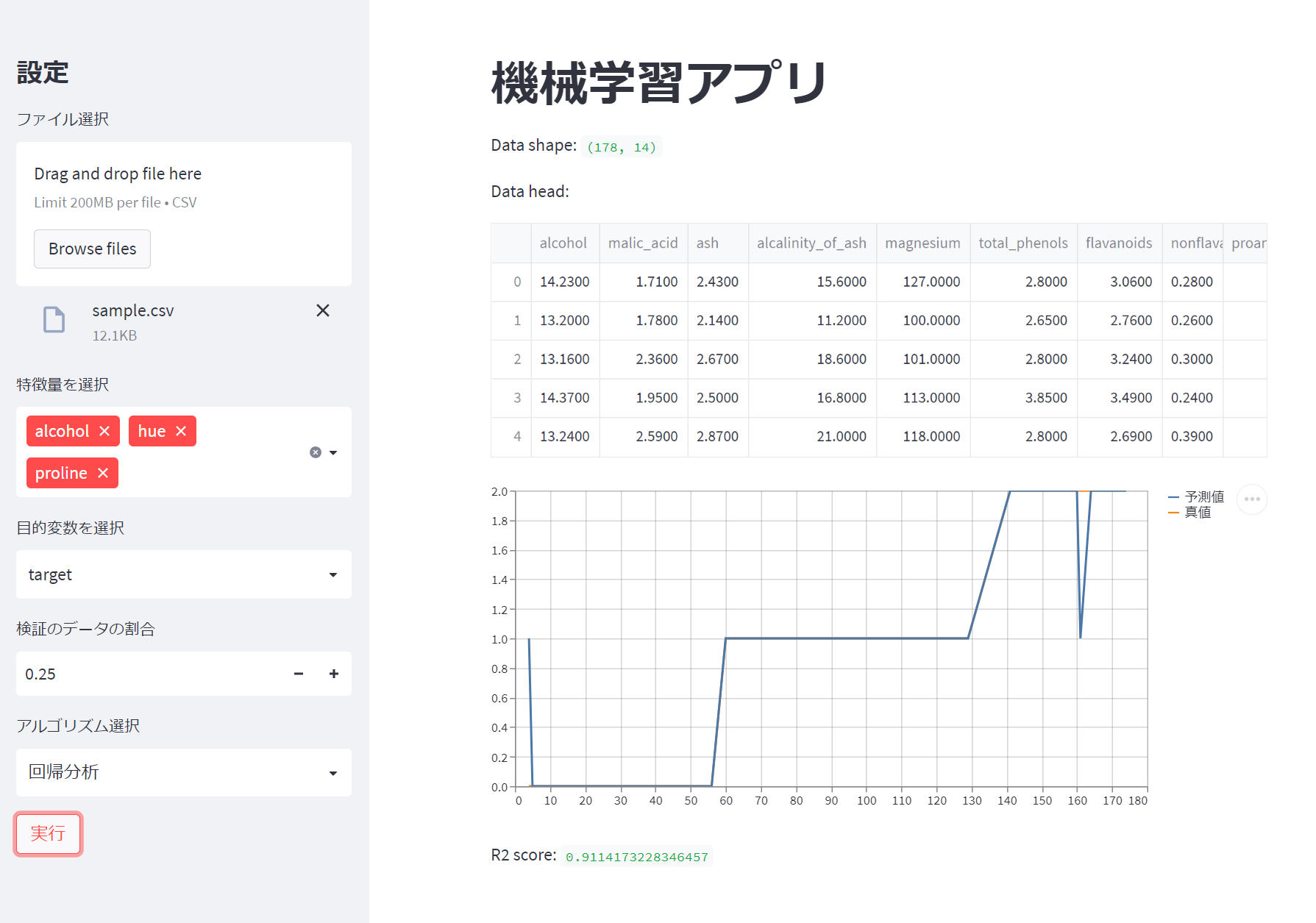
アプリ画面
最終的こういう画面に仕上がりました。
サンプルコード
app.py
import streamlit as st
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
def get_model(regression_type: str):
if regression_type == "Linear Regression":
model = LinearRegression()
elif regression_type == "SVM":
model = SVR()
else:
model = DecisionTreeRegressor()
return model
def main():
st.title("機械学習アプリ")
st.sidebar.title("設定")
# ファイルアップロード先を表示する。
uploaded_file = st.sidebar.file_uploader("ファイル選択", type="csv")
# データの読み込み・学習データ作成
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
available_columns = df.columns.tolist()
selected_columns = st.sidebar.multiselect("特徴量を選択", available_columns)
target_column = st.sidebar.selectbox(
"目的変数を選択", available_columns, index=len(available_columns)-1)
test_size = st.sidebar.number_input('検証のデータの割合', min_value=0.1)
st.write("Data shape:", df.shape)
st.write("Data head:", df.head())
if target_column is not None:
X = df[selected_columns]
y = df[target_column]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=0)
# アルゴリズム選択を表示する。
regression_type = st.sidebar.selectbox("アルゴリズム選択", ["回帰分析", "SVM", "決定木"])
model = get_model(regression_type)
# 推論処理実行
if st.sidebar.button("実行"):
try:
model.fit(X_train, y_train)
prediction = model.predict(X_test)
st.line_chart({'真値': y_test, '予測値': prediction})
st.write("R2 score: ", model.score(X_test, y_test))
except:
st.error('設定が正しくありません。')
if __name__ == '__main__':
main()
おわりに
Streamlitでは、レイアウトなど気にせず簡単にそれっぽい画面が作れて便利です。
あっさりした記事になりましたが、Streamlitの使い方の参考になれば幸いです。