この記事について
フィルタ系の画像処理をするコードを書くとき、大抵は多重ループになります。例えば、画像フィルタの場合、縦サイズ、横サイズ、対象ピクセルの縦近傍、対象ピクセルの横近傍で合計4重ループになります。
このような時に、演算やメモリアクセスをパイプライン化することで、処理を効率化できます。Vivado HLSではpipelineディレクティブを付けるだけでパイプライン化できますが、指定方法によってかなり効率が変わってくるので、それについて記します。
一番重要なこと
多重ループで外側のループにpipelineディレクティブを付けたとき、ネストされたループは全て展開(unroll)される。
これはどうしようもない。そういう仕様。
対策としては、内側のループだけパイプライン化する。または、dataflowを使うか、リソース制限をする。
パイプライン化における問題点
問題点 1
void top(uint8_t *ddrOut)
{
# pragma HLS INTERFACE m_axi depth=153600 port=ddrOut
uint8_t linebuf[640];
for (int y = 1; y < 480 - 1; y++) {
# pragma HLS pipeline
for (int x = 1; x < 640 - 1; x++) {
int data = 0;
for (int yy = y - 1; yy <= y + 1; yy++) {
for (int xx = x - 1; xx <= x + 1; xx++) {
data += yy * xx; // 特に意味はない
}
}
linebuf[x] = data;
}
memcpy(ddrOut, linebuf, 640);
ddrOut += 640;
}
}
↑は、一般的なフィルタと同様の構造をしたコードです。簡単のため、入力画像はなく、座標に応じて、適当な演算をして出力をする、というコードです (特に意味のあるロジックではありません)。高速化のために、一番外側のループでパイプライン化するように指定しています。
このコードを高位合成(C synthesis)すると、下記レポートのように、大量にリソースを使用してしまいます。これは、内側のループが展開されてしまうためです(パイプライン化というよりも、並列化になる)。この時、高位合成自体も非常に時間がかかります(数十分~数時間)。時間がかかっているときは、どうせリソース不足で使い物にならないので、途中で止めた方がいいです。

問題点 2
先ほどの例は多重ループでしたが、単に複数のモジュール(関数)をパイプライン化したい場合もあります。しかし、モジュール(関数)内にループがあると、同様の問題が発生します。
int funcA(const int a)
{
int temp = 0;
for (int i = 0; i < 100; i++) temp = (temp + a) * i; // 特に意味はない計算
return temp;
}
int funcB(const int a)
{
int temp = 0;
for (int i = 0; i < 100; i++) temp = (temp + a) * i * i; // 特に意味はない計算
return temp;
}
int funcC(const int a)
{
int temp = 0;
for (int i = 0; i < 100; i++) temp = (temp + a) * i * a; // 特に意味はない計算
return temp;
}
void top(uint8_t *ddrOut, const int a, const int b)
{
# pragma HLS INTERFACE m_axi depth=100000 port=ddrOut
uint8_t buf[100000];
for (int x = 0; x < 100000; x++) {
# pragma HLS pipeline
int temp = 0;
temp += funcA(x + a);
temp += funcB(x + a);
temp += funcC(x + a);
buf[x] = temp;
}
memcpy(ddrOut, buf, 100000);
}
上記のコードのように、funcA/B/Cをパイプラン実行したいとします(このコードも、ロジックには特に意味はありません。コード構造に注目してください)。パイプライン化したいのはあくまで、モジュール単位です。しかしこの場合も、funcA/B/C内のループまでunroll(展開)されてしまいます。結果として、下記のようにリソースを大量に使用してしまいます。

解決策
まず、パイプライン Directiveを付けたときに、ネストされたループ(関数内含む)を展開するというのは、Vivado HLSとして意図した動きです。
これを防ぐ手立てはありません。we dont have any directive like #pragma HLS UNROLL "NO".
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/How-can-I-prevent-pipelined-function-from-unroll/td-p/719898
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/How-to-pipeline-a-for-loop-including-functions/td-p/456030
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/how-to-keep-sub-loops-rolled/td-p/710062
そのため、対策としては以下の2つが考えられます。
- dataflow ディレクティブを使う
- 使用するリソースを制限する
解決策1: dataflow ディレクティブを使う
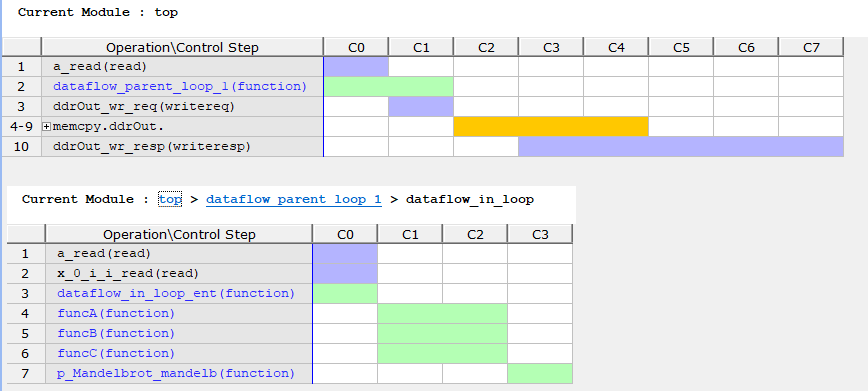
複数モジュールのパイプライン化 (問題点 2のコード)には、pipelineではなく、dataflowディレクティブを使うことで対応できます。
https://japan.xilinx.com/html_docs/xilinx2017_2/sdsoc_doc/topics/pragmas/ref-pragma_HLS_dataflow.html
void top(uint8_t *ddrOut, const int a, const int b)
{
# pragma HLS INTERFACE m_axi depth=100000 port=ddrOut
uint8_t buf[100000];
for (int x = 0; x < 100000; x++) {
# pragma HLS dataflow
int temp = 0;
temp += funcA(x + a);
temp += funcB(x + a);
temp += funcC(x + a);
buf[x] = temp;
}
memcpy(ddrOut, buf, 100000);
}
このコードのリソース使用量とタイミングチャートは下記になります。パイプラインdirectiveを指定した時よりもリソース使用量は大幅に抑えられています。

メモ
なお、dataflowディレクティブは適用できないケースがあります。一部の条件を満たさないループなどに対しては適用できません。そのような時は、ループ内の処理やループそのものを関数化して、その関数に対してdataflowディレクティブを適用することで対処できるかもしれません。
解決策2: 使用リソースを制限する
多重ループのパイプライン化 (問題点 1のコード)には、dataflowディレクティブは使用しづらいです。
パイプライン化や並列化はコンパイラに任せて、使用リソースが適量に収まるように指定するのが、お手軽な対処法だと思います。(ただし、この方法で最適解が導けるかは不明)
allocationディレクティブ
演算子の使用量を制限するには、#pragma HLS allocation instances=mul limit=1 operationといったディレクティブを追加します。この例では、乗算回路を1つだけ使用可能にします。他にも、addやsubも指定できます。
モジュール(関数)の使用量を制限するには、#pragma HLS allocation instances=func limit=2 functionといったディレクティブを追加します。この例では、func関数を同時に2つだけ呼べるようにします。
演算子の使用量を制限してみる
void top(uint8_t *ddrOut)
{
# pragma HLS INTERFACE m_axi depth=153600 port=ddrOut
# pragma HLS allocation instances=mul limit=1 operation
uint8_t linebuf[640];
for (int y = 1; y < 480 - 1; y++) {
# pragma HLS pipeline
for (int x = 1; x < 640 - 1; x++) {
int data = 0;
for (int yy = y - 1; yy <= y + 1; yy++) {
for (int xx = x - 1; xx <= x + 1; xx++) {
data += yy * xx;
}
}
linebuf[x] = data;
}
memcpy(ddrOut, linebuf, 640);
ddrOut += 640;
}
}
4重ループで、乗算回路を1つだけ使用できるようにします。
このコードのリソース使用量は以下の通りになります。乗算回路を1つだけに制限しているため、DSP48Eの使用量も抑えられています。

limit数を大きくすれば並列化されます。リソース量とパフォーマンスがトレードオフになるところです。
多重ループと関数呼び出しの組み合わせのとき
allocationディレクティブが有効になるのは、その関数内だけです。そのため、関数自体を複数並列に呼ばれたら、いくら関数内でリソースを制限しても、全体としては大量にリソースを使用してしまいます。
そのような時には、関数内、関数呼び出し、の両方にallocationディレクティブを指定することで制限できます。
uint8_t func(const int x, const int y)
{
# pragma HLS allocation instances=mul limit=1 operation
int data = 0;
for (double dy = - 1; dy <= 1; dy += 0.5) {
for (double dx = - 1; dx <= 1; dx += 0.5) {
data += (y + dy) * (x + dy);
}
}
return data;
}
void top(uint8_t *ddrOut)
{
# pragma HLS INTERFACE m_axi depth=153600 port=ddrOut
# pragma HLS allocation instances=func limit=1 function
for (int y = 1; y < 480 - 1; y++) {
# pragma HLS pipeline
uint8_t linebuf[640];
uint8_t temp;
for (int x = 1; x < 640 - 1; x++) {
temp = func(x, y);
linebuf[x] = temp;
}
memcpy(ddrOut, linebuf, 640);
ddrOut += 640;
}
}