この記事について
XilinxのSDSoC環境を使った開発の流れをステップバイステップで紹介していきます。
前回まで、standaloneとLinux用のSDSoCカスタムプラットフォームを作成しました。その後、動作確認用に、サンプルプログラム(行列積の計算)を使ってアプリケーションを作って動かしてみました。
今回は、作成したプラットフォーム上で、自分で一からプロジェクトを作ってみます。題材として、RGBからグレースケールに変換する画像処理IPを作ってみます。
環境
- 開発用PC: Windows 10 64-bit
- SDx IDE 2018.2
- プラットフォームはこの記事で作ったものを使用。基本的にはPSと複数のクロックソースがあるだけ。
- ターゲットボード: ZYBO (Z7-20)
- コードとプラットフォーム
https://github.com/take-iwiw/SDSOC_VARIOUS_IMPLEMENTATIONS
その他
本記事では、サンプル画像として以下のフリー素材を使わせていただきました。
https://www.pakutaso.com/20160738210post-8513.html
開発の流れ
通常のFPGA(あるいはASIC)開発も同じだと思うのですが、今回は以下の手順で開発していきます。
まずは通常のC言語で、CPU上で動くリファレンスコードを書きます。これによって、アルゴリズム検討を行います。また、後々ハードウェア化したコードが正しく動いているか確認するため、結果比較用に使います。
次に、いよいよハードウェア上で実装します。今回は、SDSoC環境なので、CPU用コードをそのままハードウェア化してみます。その後、最適化します。最適化の観点としては速度とリソース使用量が挙げられます。
リファレンスコードの実装
まずは、RGB画像をグレースケールに変換する処理を通常のC言語で実装します。環境はどこでもいいです(Visual Studio, MinGW, Cygwin, Linux, etc.)。Zynqなので、ZynqのCPU上でもOKです(ただし、開発効率は少しだけ落ちると思います)。
今回は、後々ハードウェアで動かしたときの結果との比較もZynq上で自動でやるため、リファレンスコードもZynq上で動かします。
(それでも、最初期のアルゴリズム確認用の実装/動作などはPCでやった方が良いと思います)
画像処理実装の準備
メインとなる画像処理実装の前に、画像の入出力処理が必要になります。実際にはカメラ画像だったり、メディアからのファイル読み込みになると思います。
今回は簡単のために、RAWファイルを読み込みます。ここでいうRAWは、RGBなら、1-pixelあたりRGBがそれぞれ8-bitのデータが左上から順に配置されたデータになります。グレースケールの場合はYのみ8-bitのデータになります。そのため、例えば640x480のグレースケール画像なら、ファイルサイズも640x480になります。ビットマップやJPEGと違い、ヘッダ情報もないので、ファイルサイズなどは使う人(実装者)が指定する必要がありますが、取り扱うのが非常に便利です。
(※ RAWというと、人によっては現像前のBayer画像などを思い浮かべるかもしれませんが、ここでは非圧縮、ヘッダ情報なしの画像データという意味です。)
RAW画像に変換する
適当な画像をRAW画像に変換します。ここではIrfanViewを使います。
まず、適当な画像(今回はJPEG)をIrfanViewで開きます。その後、Save asします。
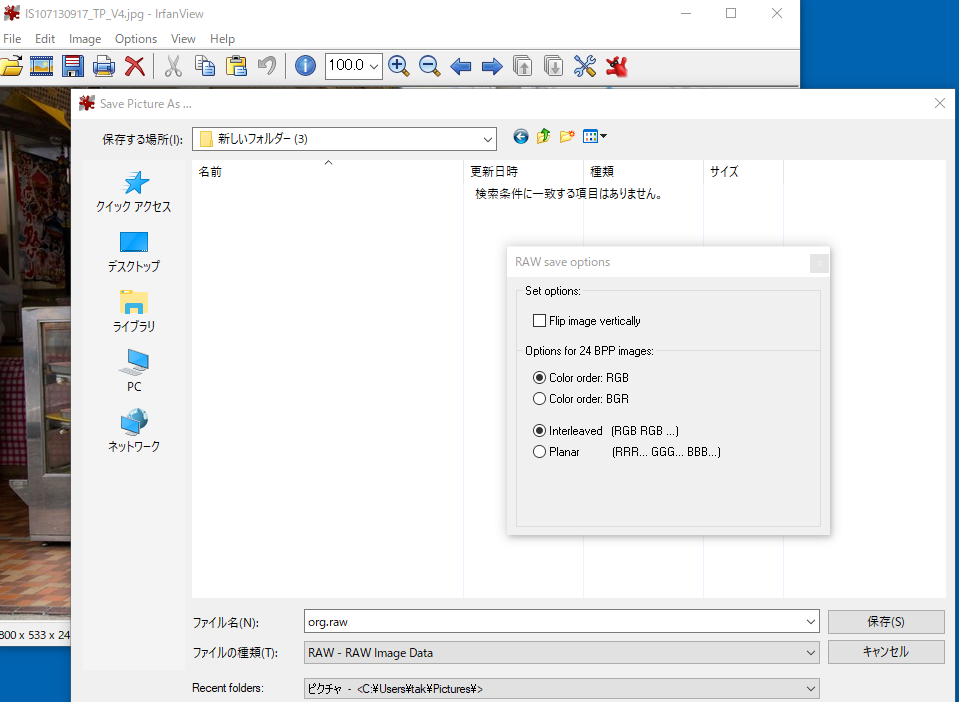
ファイルの種類として、「RAW - RAW Image Data」を選びます。
オプションはデフォルトの、Color order: RGB、Interleaved(RGB RGB...)を選びます。
ここでピクセルデータのフォーマットが決まるので、このようなデータを読むように実装をします。
なお、今回は保存前に画像のサイズを1920x1280にリサイズしました。
RAW画像を開く
先ほど作成したRAW画像を、IrfanViewで開きます。
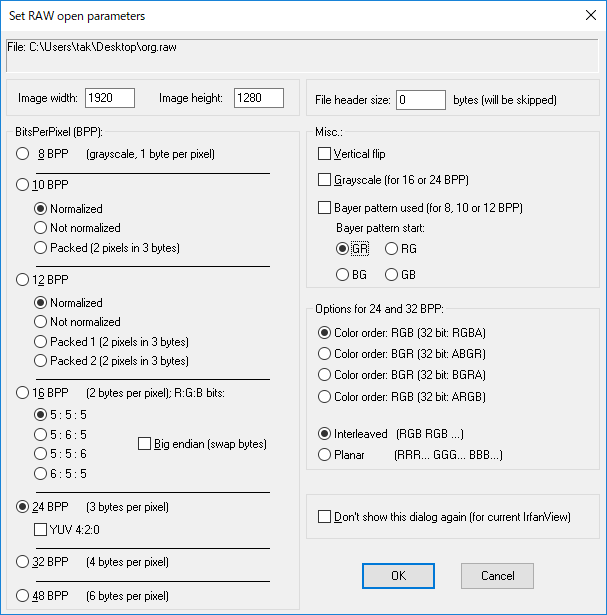
オプション指定をするウィンドウが開かれるので、そこに画像サイズ(1920x1280)と、BitsPerPixel、Color orderを指定します。
これらは、先ほど保存時に設定した通り、24BPP、Color order: RGBを指定します。
グレースケールの場合は、8BPPを指定します。
SDSoCアプリケーションプロジェクトの作成
基本的には、この手順と同じです。
New -> SDx Project、Project TypeとしてApplicationを選び、アプリケーション用プロジェクトを作成します。名前はrgb2yとしました。
プラットフォームとして、作成済みのdesign_1のLinux用を選びます。最後に、Templatesとして、Empty Applicationを選び完了です。(前回はArray Partitioningを選びました)。
実装準備
画像サイズなどの定数は、後で作るHW用コードからも参照できるように、別ファイルに分けておきます。(common.h)。
また、処理時間測定用のクラスを作っておきます。これは、SDSoCのサンプルコードからコピー/編集しました。(sds_utils.h)
ファイルの追加は、Project Explorer -> rgb2y -> src上で右クリック -> New -> File、で行います。拡張子も含めてファイル名を自分で打たないとダメなようです。
# ifndef COMMON_H_
# define COMMON_H_
# include <stdint.h>
# define WIDTH 1920 // [pixel]
# define HEIGHT 1280 // [pixel]
# define WIDTH_MAX WIDTH // [pixel]
# define HEIGHT_MAX HEIGHT // [pixel]
# define STRIDE_RGB (WIDTH * 3) // [byte]
# define STRIDE_Y (WIDTH * 1) // [byte]
# define TEST_NUM (10)
# endif // COMMON_H_
# ifndef SDS_UTILS_H_
# define SDS_UTILS_H_
# include <stdint.h>
# include "sds_lib.h"
namespace sds_utils {
class perf_counter
{
private:
uint64_t tot, cnt, calls;
public:
perf_counter() : tot(0), cnt(0), calls(0) {};
inline void reset() { tot = cnt = calls = 0; }
inline void start() { cnt = sds_clock_counter(); calls++; };
inline void stop() { tot += (sds_clock_counter() - cnt); };
inline uint64_t avg_cpu_cycles() {return (tot / calls); };
inline double avg_time() {return (avg_cpu_cycles() / (double)sds_clock_frequency()); };
};
}
# endif
CPU用リファレンスコードの実装
RAW画像をファイルからread、RGBからグレースケール(Y)に変換(convRGB2Y_CPU)、変換されたRAW画像(Yのみ)をファイルにwriteしています。
変換処理は10回callして、処理時間はその平均を求めます。
# include <stdint.h>
# include <stdio.h>
# include <stdlib.h>
# include <string.h>
# include "sds_utils.h"
# include "sds_lib.h"
# include "common.h"
static void readFile(const char* filename, uint8_t *data, uint32_t size)
{
FILE *fd = fopen(filename, "rb");
fread(data, 1, size, fd);
fclose(fd);
}
static void writeFile(const char* filename, uint8_t *data, uint32_t size)
{
FILE *fd = fopen(filename, "wb");
fwrite(data, 1, size, fd);
fclose(fd);
}
void convRGB2Y_CPU(uint8_t* dst, uint8_t* src, int width, int height, int dstStride, int srcStride)
{
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
uint8_t r = *(src + x * 3 + 0);
uint8_t g = *(src + x * 3 + 1);
uint8_t b = *(src + x * 3 + 2);
*(dst + x) = (uint8_t)(0.299f * r + 0.587f * g + 0.114f * b);
}
dst += dstStride;
src += srcStride;
}
}
int main()
{
sds_utils::perf_counter counter;
/*** CPU implementation ***/
uint8_t* imgSrc = (uint8_t*)malloc(WIDTH_MAX * HEIGHT_MAX * 3);
uint8_t* imgDst = (uint8_t*)malloc(WIDTH_MAX * HEIGHT_MAX);
readFile("org.raw", imgSrc, STRIDE_RGB * HEIGHT);
counter.reset();
for (int i = 0; i < TEST_NUM; i++) {
counter.start();
convRGB2Y_CPU(imgDst, imgSrc, WIDTH, HEIGHT, STRIDE_Y, STRIDE_RGB);
counter.stop();
}
printf("convRGB2Y_CPU: %.3f [msec]\n", counter.avg_time() * 1000);
writeFile("gray_cpu.raw", imgDst, STRIDE_Y * HEIGHT);
free(imgSrc);
free(imgDst);
}
ZYBO上で実行する
上記コードをビルドします。ハードウェア関数がない状態でも、最初だけは、ビットストリーム作成のために10分くらい時間がかかります。
出来上がったら、ZYBO上で実行します。今回はCPU用コードだけなので、elfファイルさえ実行出来ればいいのですが、今後ハードウェアも更新する必要があるのですが、結構忘れます。そのため、僕はいつも、生成されるsd_cardディレクトリの中身をコピーするようにしています。
そのためにscpコマンドを使っています。また、画像ファイルのやり取りにもscpコマンドを使っています。
実行の流れを、PC上のターミナル(MSYS)と、ZYBO上のターミナルのコマンドを合わせて記載します。基本的にはいつもこれらのコマンドをコピペしています。
scp /c/path-to-project/SDSOC_VARIOUS_IMPLEMENTATIONS/rgb2y/Release/sd_card/* root@192.168.1.87:/run/media/mmcblk0p1/ # MSYSターミナル: 必要なファイルをコピー
reboot # ZYBOターミナル: 再起動
scp /c/path-to-project/SDSOC_VARIOUS_IMPLEMENTATIONS/rgb2y/org.raw root@192.168.1.87:/home/root # MSYSターミナル: 入力RAW画像をコピー
/run/media/mmcblk0p1/rgb2y.elf # ZYBOターミナル: 実行
scp root@192.168.1.87:/home/root/*.raw /c/path-to-project/. # MSYSターミナル: 出力されたRAW画像をコピー
結果、以下のようにグレースケールに変換されたRAW画像が得られました。


ハードウェア化する
まずはそのままハードウェア化する
まずは、先ほどのCPU用リファレンスコードをそのままハードウェア化してみます。このハードウェア関数をconvRGB2Y_hw0とします。
ハードウェア関数を実装するファイルを作成します。(convRGB2Y.cpp/.h)
重要な点は、ヘッダファイルで、転送するデータサイズ量を指定するプラグマを付ける点です。これがないと、unsupported memory access on variable 'src' which is (or contains) an array with unknown size at compile time.といったエラーが出ます。
# ifndef CONV_RGB2Y_H_
# define CONV_RGB2Y_H_
# include <stdint.h>
# include "common.h"
# pragma SDS data zero_copy(dst[0:dstStride*height], src[0:srcStride*height])
void convRGB2Y_hw0(uint8_t* dst, uint8_t* src, int width, int height, int dstStride, int srcStride);
# endif // CONV_RGB2Y_H_
# include <string.h>
# include "convRGB2Y.h"
void convRGB2Y_hw0(uint8_t* dst, uint8_t* src, int width, int height, int dstStride, int srcStride)
{
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
uint8_t r = *(src + x * 3 + 0);
uint8_t g = *(src + x * 3 + 1);
uint8_t b = *(src + x * 3 + 2);
*(dst + x) = (uint8_t)(0.299f * r + 0.587f * g + 0.114f * b);
}
dst += dstStride;
src += srcStride;
}
}
ハードウェア化する
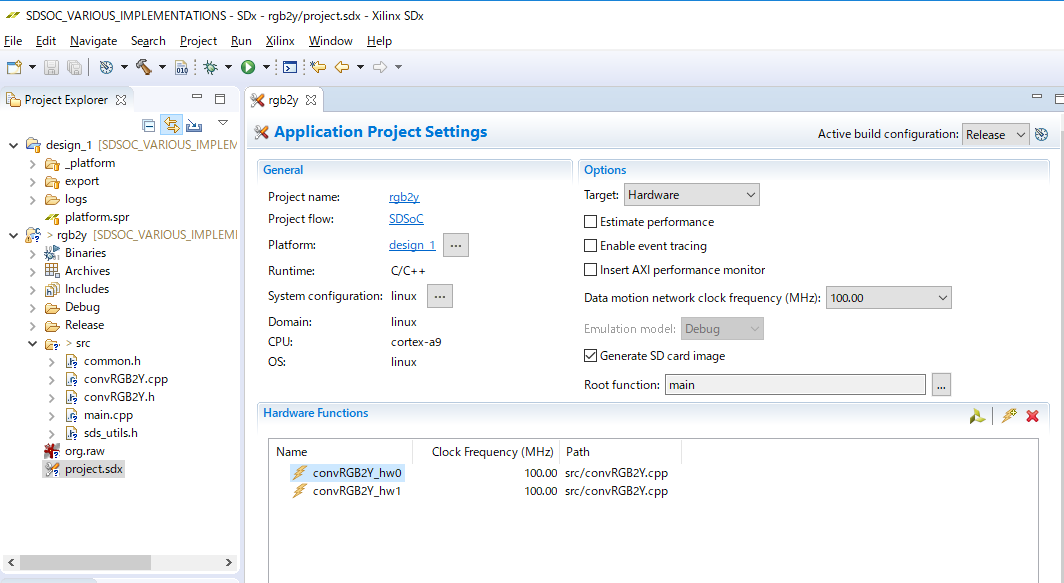
関数をハードウェア化するためには、登録する必要があります。project.sdxをダブルクリックして、Application Project SettingsのHardware Functionに登録します。
ハードウェア関数を呼ぶ
テストコード(main.cpp)から、ハードウェア化したconvRGB2Y_hw0関数を呼びます。特に特別なことはなく、通常の関数コールと同じです。
注意点として、データ領域確保には、mallocではなく、sds_allocまたはsds_alloc_non_cacheableを使う必要があります。これは、データ転送をハードウェアで行う際に、データが物理的に連続領域に確保されていることを保証するためです。
uint8_t* imgSrc8 = (uint8_t*)sds_alloc_non_cacheable(WIDTH_MAX * HEIGHT_MAX * 3);
uint8_t* imgDst8 = (uint8_t*)sds_alloc_non_cacheable(WIDTH_MAX * HEIGHT_MAX);
readFile("org.raw", imgSrc8, STRIDE_RGB * HEIGHT);
counter.reset();
for (int i = 0; i < TEST_NUM; i++) {
counter.start();
convRGB2Y_hw0(imgDst8, imgSrc8, WIDTH, HEIGHT, STRIDE_Y, STRIDE_RGB);
counter.stop();
}
printf("convRGB2Y_hw0: %.3f [msec]\n", counter.avg_time() * 1000);
writeFile("gray_hw0.raw", imgDst8, STRIDE_Y * HEIGHT);
実行する
先ほどのCPU実装と同じ手順で、必要ファイルをコピーして再起動後、実行します。今回はハードウェアが変更されているので、ビットストリームファイルの更新は必須になります。
結果は、次の最適化後の結果とまとめて記載します。
最適化する
今回は、データのビット幅を64-bitにする、ループにPIPELINEディレクティブを付ける、といった簡単な最適化を行います。
下記コードは追加部分のみを記載しています。
# pragma SDS data zero_copy(dst[0:dstStride*height/8], src[0:srcStride*height/8])
void convRGB2Y_hw1(uint64_t* dst, uint64_t* src, int width, int height, int dstStride, int srcStride);
enum {
RED = 0,
GREEN = 1,
BLUE = 2,
};
static uint8_t getPixel(uint64_t* lineBuf, int col, int rgb)
{
# pragma HLS INLINE
int index = col * 3 + rgb;
return (lineBuf[index / 8] >> (8 * (index % 8))) & 0xFF;
}
static uint8_t convPixelRGB2YgetPixel(uint8_t r, uint8_t g, uint8_t b)
{
# pragma HLS INLINE
return (uint8_t)(0.299f * r + 0.587f * g + 0.114f * b);
}
void convRGB2Y_hw1(uint64_t* dst, uint64_t* src, int width, int height, int dstStride, int srcStride)
{
uint64_t lineBuffSrc[WIDTH_MAX / 8 * 3];
uint64_t lineBuffDst[WIDTH_MAX / 8];
for (int y = 0; y < height; y++) {
# pragma HLS PIPELINE
memcpy(lineBuffSrc, src + y * srcStride / 8, width * 3);
for (int x = 0; x < width / 8; x++) {
/* 入出力は64-bitなので、8pixel単位で処理してまとめて出力する */
uint8_t y0 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 0, RED), getPixel(lineBuffSrc, x * 8 + 0, GREEN), getPixel(lineBuffSrc, x * 8 + 0, BLUE));
uint8_t y1 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 1, RED), getPixel(lineBuffSrc, x * 8 + 1, GREEN), getPixel(lineBuffSrc, x * 8 + 1, BLUE));
uint8_t y2 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 2, RED), getPixel(lineBuffSrc, x * 8 + 2, GREEN), getPixel(lineBuffSrc, x * 8 + 2, BLUE));
uint8_t y3 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 3, RED), getPixel(lineBuffSrc, x * 8 + 3, GREEN), getPixel(lineBuffSrc, x * 8 + 3, BLUE));
uint8_t y4 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 4, RED), getPixel(lineBuffSrc, x * 8 + 4, GREEN), getPixel(lineBuffSrc, x * 8 + 4, BLUE));
uint8_t y5 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 5, RED), getPixel(lineBuffSrc, x * 8 + 5, GREEN), getPixel(lineBuffSrc, x * 8 + 5, BLUE));
uint8_t y6 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 6, RED), getPixel(lineBuffSrc, x * 8 + 6, GREEN), getPixel(lineBuffSrc, x * 8 + 6, BLUE));
uint8_t y7 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 7, RED), getPixel(lineBuffSrc, x * 8 + 7, GREEN), getPixel(lineBuffSrc, x * 8 + 7, BLUE));
*(lineBuffDst + x) = ((uint64_t)y7 << (8 * 7)) | ((uint64_t)y6 << (8 * 6)) | ((uint64_t)y5 << (8 * 5)) | ((uint64_t)y4 << (8 * 4))
| ((uint64_t)y3 << (8 * 3)) | ((uint64_t)y2 << (8 * 2)) | ((uint64_t)y1 << (8 * 1)) | ((uint64_t)y0 << (8 * 0));
}
memcpy(dst + y * dstStride / 8, lineBuffDst, width);
}
}
結果
処理時間測定結果は以下の通りです。
root@design_1_linux:~# /run/media/mmcblk0p1/rgb2y.elf
convRGB2Y_CPU: 145.146 [msec]
convRGB2Y_hw0: 2002.840 [msec]
OK
convRGB2Y_hw1: 118.596 [msec]
OK
何も考えずにハードウェア化しただけのconvRGB2Y_hw0は、CPUと比べても非常に遅くなってしまいました。最適化したconvRGB2Y_hw1ではCPUに比べると少し早くなりましたが、劇的に変わったわけではありません。
理由として考えられるのは、今回はwidth、heightともに変数として扱いました。そのため、ハードウェア化する際に条件分岐が多く出てきて、あまり高速化されなかったのだと思います。
convRGB2Y_hw0のリソース使用量は以下の通りです。
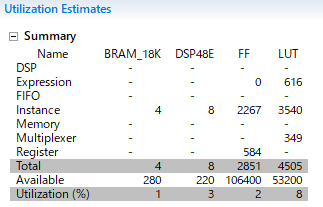
convRGB2Y_hw1のリソース使用量は以下の通りです。convRGB2Y_hw0に比べると増加していることが分かります。

もう少し最適化してみる
ちょっとずるいですが、横幅(width)を変数から定数(WIDTH)に変えて、外側ループをDATAFLOW、内側ループをPIPELINEにしてみます。
void convRGB2Y_hw2(uint64_t* dst, uint64_t* src, int width, int height, int dstStride, int srcStride)
{
uint64_t lineBuffSrc[WIDTH_MAX / 8 * 3];
uint64_t lineBuffDst[WIDTH_MAX / 8];
for (int y = 0; y < height; y++) {
# pragma HLS DATAFLOW
memcpy(lineBuffSrc, src + y * srcStride / 8, WIDTH * 3);
for (int x = 0; x < WIDTH / 8; x++) {
# pragma HLS PIPELINE
/* 入出力は64-bitなので、8pixel単位で処理してまとめて出力する */
uint8_t y0 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 0, RED), getPixel(lineBuffSrc, x * 8 + 0, GREEN), getPixel(lineBuffSrc, x * 8 + 0, BLUE));
uint8_t y1 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 1, RED), getPixel(lineBuffSrc, x * 8 + 1, GREEN), getPixel(lineBuffSrc, x * 8 + 1, BLUE));
uint8_t y2 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 2, RED), getPixel(lineBuffSrc, x * 8 + 2, GREEN), getPixel(lineBuffSrc, x * 8 + 2, BLUE));
uint8_t y3 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 3, RED), getPixel(lineBuffSrc, x * 8 + 3, GREEN), getPixel(lineBuffSrc, x * 8 + 3, BLUE));
uint8_t y4 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 4, RED), getPixel(lineBuffSrc, x * 8 + 4, GREEN), getPixel(lineBuffSrc, x * 8 + 4, BLUE));
uint8_t y5 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 5, RED), getPixel(lineBuffSrc, x * 8 + 5, GREEN), getPixel(lineBuffSrc, x * 8 + 5, BLUE));
uint8_t y6 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 6, RED), getPixel(lineBuffSrc, x * 8 + 6, GREEN), getPixel(lineBuffSrc, x * 8 + 6, BLUE));
uint8_t y7 = convPixelRGB2YgetPixel(getPixel(lineBuffSrc, x * 8 + 7, RED), getPixel(lineBuffSrc, x * 8 + 7, GREEN), getPixel(lineBuffSrc, x * 8 + 7, BLUE));
*(lineBuffDst + x) = ((uint64_t)y7 << (8 * 7)) | ((uint64_t)y6 << (8 * 6)) | ((uint64_t)y5 << (8 * 5)) | ((uint64_t)y4 << (8 * 4))
| ((uint64_t)y3 << (8 * 3)) | ((uint64_t)y2 << (8 * 2)) | ((uint64_t)y1 << (8 * 1)) | ((uint64_t)y0 << (8 * 0));
}
memcpy(dst + y * dstStride / 8, lineBuffDst, WIDTH);
}
}
この時の実行結果は以下の通りで、CPU実行の25%くらいまで処理時間が高速化されました。
root@design_1_linux:~# /run/media/mmcblk0p1/rgb2y.elf
convRGB2Y_CPU: 145.146 [msec]
convRGB2Y_hw0: 2002.840 [msec]
OK
convRGB2Y_hw1: 118.596 [msec]
OK
convRGB2Y_hw2: 37.231 [msec]
OK
処理時間見積もり
今回、処理時間測定のために、コンパイルして実機で動かして確認しました。
コンパイルはざっくり、ソフトウェア部分、ハードウェアIP部分、ハードウェア全体、に分けられます。
ここでいう「ハードウェアIP部分」は、各IPのビルドのことで、Vivado HLS等の高位合成と同じです。
最後にハードウェア全体のビットストリームを作成します。ログ上にはHardware accelerator integrationと出ます。これが長いです。
各IP(ハードウェア関数)に入力するデータのサイズなどが分かれば、処理時間はIPのビルドが完了した時点で分かります。
各ループに、#pragma HLS LOOP_TRIPCOUNT min=1280 max=1280といったプラグマを付けることで、各ループが何回実行されるかが分かるので、処理時間見積もりをしてくれます。
LOOP_TRIPCOUNTを付けて再度コンパイルしてみました。(今回は、Hardware accelerator integrationが出た時点でCancel)。
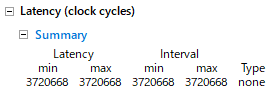
convRGB2Y_hw1のHLSレポートを見ると、以下のような見積もり値が出ます。
インターバルが3720668[サイクル]なので、3720668/ 100MHz = 0.03720668[秒]ということで、実際に近い値になっています。
ハードウェア関数を最適化するときには、ハードウェア全体を作る必要はなく、まずはIP単品の性能見積もりを使うことで効率的に開発出来そうです。