この記事について
XilinxのSDSoCを使用してハードウェア処理をCで高位合成する際に、どういうコードを書いたらどういう動きになるのか?、どういうコードが速いのか?、を色々と試しました。同じロジックを実現するために、50以上の異なる方法を試しました。Vivadoとの闘いの歴史です。
まず、ビット幅による性能の違いと、BRAM使用有無による違いを確認しました。その後、制御フローに関わる大きなディレクティブとして、PIPELINE、DATAFLOW、STREAM、UNROLLを試しました。また、付加的なディレクティブとして、ARRAY_PARTITIONと、データムーバの指定(AXI DMA)を試しました。
インターフェイス部分はSDSoC特有のものもありますが、ほとんどはVivao HLSでも同様だと思います。
環境
- 開発用PC: Windows 10 64-bit
- SDx IDE 2018.2
- プラットフォームはこの記事で作ったものを使用。基本的にはPSと複数のクロックソースがあるだけ。
- ターゲットボード: ZYBO (Z7-20)
- コードとプラットフォーム
対象とするロジック
uint8_t[1024 * blockNum]の配列に対して、各要素を2倍する。blockNumは変数として指定可能で、テストコード内に512を設定。
1024x512のグレースケール画像を想定しています。ピクセル単位で処理したいので、8-bit単位で計算することが求められます。
# define BLOCK_SIZE (1024)
void myIP(uint8_t* dst, uint8_t* src, int blockNum)
{
for (int i = 0; i < BLOCK_SIZE * blockNum; i++) {
uint8_t temp = *(src + i);
temp *= 2;
*(dst + i) = temp;
}
}
上記コードを元コード(リファレンスコード)とします。
これを、基本ロジックはそのままで、色々な方法で実装してみます。
測定用コード
測定用コード
# include <iostream>
# include <string.h>
# include <stdint.h>
# include <cstdio>
# include <stdlib.h>
# include <stdio.h>
# include "sds_utils.h"
# include "sds_lib.h"
# include "myIP_simple.h"
void verifyResult(uint8_t *dst, uint8_t *src, int blockNum)
{
for(int i = 0; i < BLOCK_SIZE * blockNum; i++) {
if ((uint8_t)(src[i] * 2) != dst[i]) {
printf(" error at index(%d). src = %d, dst = %d\n", i, src[i], dst[i]);
break;
}
}
}
void test_myIP_simple(int blockNum)
{
sds_utils::perf_counter counter;
uint8_t *src8 = (uint8_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
uint8_t *dst8 = (uint8_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
uint32_t *src32 = (uint32_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
uint32_t *dst32 = (uint32_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
uint64_t *src64 = (uint64_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
uint64_t *dst64 = (uint64_t*)sds_alloc_non_cacheable(BLOCK_SIZE * blockNum);
for(int i = 0; i < BLOCK_SIZE * blockNum; i++) {
src8[i] = i % 255;
((uint8_t*)src32)[i] = i % 256;
((uint8_t*)src64)[i] = i % 256;
}
memset(dst8, 0, BLOCK_SIZE * blockNum);
counter.reset();
for (int i = 0; i < TEST_NUM; i++) {
counter.start();
myIP_simple_8(dst8, src8, blockNum);
counter.stop();
}
std::cout << "myIP_simple_8" << ": " << counter.avg_time() * 1000 << " msec" << std::endl;
verifyResult((uint8_t*)dst8, (uint8_t*)src8, blockNum);
memset(dst32, 0, BLOCK_SIZE * blockNum);
counter.reset();
for (int i = 0; i < TEST_NUM; i++) {
counter.start();
myIP_simple_32(dst32, src32, blockNum);
counter.stop();
}
std::cout << "myIP_simple_32" << ": " << counter.avg_time() * 1000 << " msec" << std::endl;
verifyResult((uint8_t*)dst32, (uint8_t*)src32, blockNum);
memset(dst64, 0, BLOCK_SIZE * blockNum);
counter.reset();
for (int i = 0; i < TEST_NUM; i++) {
counter.start();
myIP_simple_64(dst64, src64, blockNum);
counter.stop();
}
std::cout << "myIP_simple_64" << ": " << counter.avg_time() * 1000 << " msec" << std::endl;
verifyResult((uint8_t*)dst64, (uint8_t*)src64, blockNum);
sds_free(src8);
sds_free(dst8);
sds_free(src32);
sds_free(dst32);
sds_free(src64);
sds_free(dst64);
}
上記のようなテストコードを用いて各ハードウェア関数をテストしました。
肝は、メモリ確保にsds_alloc_non_cacheableを使用する点です。ほとんどのサンプルコードだとメモリ確保にsds_allocを使用しています。どちらも、DMA転送できるように物理的に連続した領域を確保してくれます。sds_allocの方は、CPUからアクセスする際にキャッシュ経由でのアクセスになります。でも、それだとコヒーレンシが保たれないんじゃないの? と思ったのですが、ug1235によるとハードウェア関数を呼ぶ前後でキャッシュフラッシュしたり色々してくれるらしいです。つまり、CPUからもアクセスできるし、コヒーレンシも自動で保ってくれる良い所取りです。通常の開発ではこちらを使うことが多いと思います。
しかし、今回は処理時間を測定したいので、それだと困ります。ハードウェア関数の呼び出し前後で時間を測るのですが、余計な処理が入ると単純比較ができません。実際、このせいで1日くらいハマりました。ということで、今回はsds_alloc_non_cacheableを使います。ちなみに、ug1235には「CPUからアクセスされないメモリ用」、といったことが書いていましたが、アクセス自体は出来ました。ただ、非常に遅いので、実用には堪えません。
また、関数のハードウェア化は、一度に1つのみにします。つまり、Application Project SettingsのHardware Functionsには一度に1つだけ、テストしたい関数だけを登録します。これは、ハードウェア関数が1つしかない場合と、他にもある場合で処理時間が変わるケースがあったためです(本記事の最後の方で比較しています)。
また、FPGA開発においてはコンパイル時間も非常に重要な要素になってきます。今回は、IP作成時間として'\test_myip\Release_sds\vhls\myIP_simple_pipe_8_vivado_hls.log'の作成日時と更新日時の差分を、HW作成時間として'test_myip\Release_sds\p0\vivado\vivado.log'の作成日時と更新日時の差分を測定しました。コンパイル待ち中に動画を見たりネットを見たりしていたのですが、意外と誤差は少ないように思えます。
もう一つハマった点として、ハードウェア関数を呼び出す際には、Cのマクロ経由だとうまくいきませんでした(ハードウェア化されない)。テストコードを見ていただければわかると思うのですが、色々と共通な処理があるので、マクロかして簡潔に書こうとしたら、上手く動かずにハマりました。
処理時間は、IPを100MHzクロックで動作させたときの結果です。また、今回は複雑な計算はしていないため、DSP48Eの使用量は常に0でした。そのため、結果の表には載せていません。
0. CPU実装
まずは、処理をハードウェア化せずに、CPU(ARM Cortex-A9@666.66MHz x 2)で動かします。8-bit、32-bit、64-bit単位で処理をするコードを、Debugコンパイル、Releaseコンパイルで試しました。32-bitと64-bitでは、8-bit単位に分解して計算しました。単に、32-bit/64-bit単位で2倍したのではありません。これは、最終的には画像処理で1pixel単位の計算をすることを想定しているためです。結果は下記のとおりです。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | CPU実装 8-bit_Debug | 19.98 | - | - | - | - | - | - | - | CPU実装 8-bit。Debug |
| 2 | CPU実装 32-bit_Debug | 14.62 | - | - | - | - | - | - | - | CPU実装 32-bit。Debug |
| 3 | CPU実装 64-bit_Debug | 11.89 | - | - | - | - | - | - | - | CPU実装 64-bit。Debug |
| 4 | CPU実装 8-bit_Release | 3.60 | - | - | - | - | - | - | - | CPU実装 8-bit。Release |
| 5 | CPU実装 32-bit_Release | 3.68 | - | - | - | - | - | - | - | CPU実装 32-bit。Release |
| 6 | CPU実装 64-bit_Release | 3.26 | - | - | - | - | - | - | - | CPU実装 64-bit。Release |
これを見ると、Debugの時はビット数に応じて処理時間は高速化されていきます。Debugの時は、おそらく律義に指定のビット幅単位で計算するためだと思います。Releaseの時は、32-bitが一番遅いという不思議な結果になりました。ここら辺、逆アセンブラ結果を見ると色々分かると思うのですが、今回の趣旨とは外れるので深追いはしません。
1. 単純な実装
コード
https://github.com/take-iwiw/SDSOC_VARIOUS_IMPLEMENTATIONS/blob/master/test_myip/src/myIP_simple.cpp
1.1. 非パイプライン/パイプライン化
CPU実装したコードと同じものを、ハードウェア化します。それぞれ、myIP_simple_8、myIP_simple_32、myIP_simple_64とします。また、forループでパイプライン化したものをmyIP_simple_pipe_8
、myIP_simple_pipe_32、myIP_simple_pipe_64とします。パイプライン化には、ループ内で#pragma HLS PIPELINEを付けました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 7 | myIP_simple_8 | 10.49 | 7.30 | 4 | 0 | 1204 | 1598 | 0:18 | 8:51 | オリジナルコード 8-bit転送 |
| 8 | myIP_simple_32 | 2.63 | 7.30 | 4 | 0 | 1170 | 1356 | 0:18 | 9:04 | オリジナルコード 32-bit転送 |
| 9 | myIP_simple_64 | 1.32 | 7.30 | 8 | 0 | 1304 | 1727 | 0:20 | 9:47 | オリジナルコード 64-bit転送 |
| 10 | myIP_simple_pipe_8 | 5.25 | 7.30 | 4 | 0 | 1178 | 1626 | 0:18 | 8:55 | myIP_simple_8のループをパイプライン化 |
| 11 | myIP_simple_pipe_32 | 1.55 | 7.30 | 4 | 0 | 1146 | 1384 | 0:22 | 9:45 | myIP_simple_32のループをパイプライン化 |
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
結果、ビット幅に比例して高速化されています。64-bit単位で処理すると、8-bit単位に比べて8倍高速です。リソース使用量の観点で見ると、32-bit < 8-bit < 64-bitの順で多いのが面白いです。
パイプライン化することで、さらに2倍弱高速化されます。しかし、リソース使用量はあまり増加していません。LUT使用量は微増ですが、FF使用量は微減しています。パイプライン化するからFF使用量は増えると思ったのですが、不思議です。
1.2. (横道)実装方法の違いを確認
先ほどのmyIP_simple_pipe_64の実装で、細かな実装方法の違いによって結果に差が出るかどうかを試しました。具体的には、メモリアクセス方法を、ポインタとオフセットでアクセス(myIP_simple_pipe_64)、配列にしたもの(myIP_simple_pipe_64_a)、ポインタそのものをインクリメント(myIP_simple_pipe_64_b)、アクセス用のオート変数をポインタ化(myIP_simple_pipe_64_c)したもので比較しました。また、LOOP_TRIPCOUNTディレクティブを付けてみました(myIP_simple_pipe_64_tripcount)
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 13 | myIP_simple_pipe_64_a | 0.79 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:50 | myIP_simple_pipe_64の亜種。ポインタ計算方法を変更 |
| 14 | myIP_simple_pipe_64_b | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 8:32 | myIP_simple_pipe_64の亜種。ポインタ計算方法を変更 |
| 15 | myIP_simple_pipe_64_c | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:34 | myIP_simple_pipe_64の亜種。ポインタ計算方法を変更 |
| 16 | myIP_simple_pipe_64_tripcount | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:19 | 8:55 | myIP_simple_pipe_64の亜種。Tripcount設定 |
結論として、これくらいの実装の違いだったら結果に差はありませんでした。コンパイラが最適な形に最適化してくれているのだと思います。ハードウェア的にも同じものが作られていると思います。また、LOOP_TRIPCOUNTを付けても結果には影響はなく、HLSでレポートを見る際に、Timing等がちゃんと表示されるかどうかの違いがあるだけのようです。
ちなみに、LOOP_TRIPCOUNTに限った話ではないのですが、ディレクティブ(pragma)を付ける際には、以下の点に注意が必要そうです。
- スペースは使えない
- Cのマクロ定義値(define値)は使えない
1.3. PIPELINEディレクティブのオプション
PIPELINEディレクティブには、II(Initial Interval:ループの開始間隔)を指定するというオプションがあります。指定なしの場合はデフォルトの1が使われます。(なので最速になるはず?)。
この設定を変えることで、出来上がる回路も色々と変わってくると思うのですが、今回はこの指定はなしで話を進めていきます。
2. BRAMへデータ転送して計算する
2.1. BRAMを使う
今回のコードのように単純な計算をするだけで、各バイト(or ワード)に対して一度しかアクセスしない場合には、上記のコードで問題ありませんし、そっちの方が速いと思います。特に、今回の場合は実質的にバーストアクセスになるので速いと思います。
しかし、平滑化フィルタ処理のように、同じデータに何回もアクセスする場合には、通常は内蔵RAMにコピーします。これは、時間のかかるDDRへのアクセス回数を減らすためです。また、各バイト(or ワード)へのアクセス回数が1回だけでも、アクセス順序が連続でないと、メモリアクセス効率が悪くなる可能性があります。
ZynqにはBlock RAM(BRAM)と呼ばれる内蔵メモリがあるので、それを使います。しかしZYBOの場合、BRAMは240KByteしかないので、例えばFull HDの画像データ全部を一度にコピーすることは不可能です。そのため、通常、BRAMは画像処理ではラインバッファとして使われます。
BRAMは、ローカルの配列変数を宣言したら自動的に割り当てられます。
2.2 BRAMを使用したコード
先ほどの、myIP_simple_pipe_8とmyIP_simple_pipe_64と同様の実装を、BRAMを用いて行いました。それぞれ、myIP_buff1_pipe_8とmyIP_buff1_pipe_64です。DDRからBRAMへはmemcpyでデータコピーをしました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | myIP_simple_pipe_8 | 5.25 | 7.30 | 4 | 0 | 1178 | 1626 | 0:18 | 8:55 | myIP_simple_8のループをパイプライン化 |
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 17 | myIP_buff1_pipe_8 | 5.67 | 7.30 | 4 | 0 | 2272 | 6003 | 5:03 | 12:29 | BRAM(内蔵バッファ)に1ライン分コピーしてから計算。8-bit転送 |
| 18 | myIP_buff1_pipe_64 | 0.97 | 7.30 | 8 | 4 | 9223 | 4668 | 1:05 | 14:29 | BRAM(内蔵バッファ)に1ライン分コピーしてから計算。64-bit転送 |
結果として、処理時間は微増でしたが、リソース使用量はBRAM、FF、LUTいずれも大きく増加しました。今回の処理ではメリットは少ないですが、メモリアクセスが多くなると、BRAMを使った方が有利になるはずです。
その他気になった点としては、8-bitの方が64-bitよりもLUT使用量が多いです。これは、8-bitでアクセスするためのロジックなどが増えているためだと想像します。また、IP作成時間も5分を超えました(念のため2回やりましたが、結果は同じ)。論理演算の合成に時間がかかったのでしょうかね。
2.3. PIPELINEディレクティブの入れ方による影響
先ほどのmyIP_buff1_pipe_64の実装で、PIPELINEディレクティブの入れる位置によって結果に差が出るかどうかを試しました。具体的には、BRAMに配置される配列をfor文の中で宣言(myIP_buff1_pipe_64_a)、パイプラインディレクティブを2重ループの両方に挿入(myIP_buff1_pipe_64_b)、パイプラインディレクティブを内側のループだけに挿入(myIP_buff1_pipe_64_c)
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 18 | myIP_buff1_pipe_64 | 0.97 | 7.30 | 8 | 4 | 9223 | 4668 | 1:05 | 14:29 | BRAM(内蔵バッファ)に1ライン分コピーしてから計算。64-bit転送 |
| 19 | myIP_buff1_pipe_64_a | 0.97 | 7.30 | 8 | 4 | 9223 | 4668 | 1:03 | 13:59 | myIP_buff1_pipe_64亜種。BRAM宣言位置を変更 |
| 20 | myIP_buff1_pipe_64_b | 0.97 | 7.30 | 8 | 4 | 9223 | 4668 | 1:04 | 14:02 | myIP_buff1_pipe_64亜種。PIPELINEを外側と内側のループにつける |
| 21 | myIP_buff1_pipe_64_c | 2.02 | 7.30 | 8 | 4 | 1428 | 1983 | 0:19 | 9:06 | myIP_buff1_pipe_64亜種。PIPELINEを内側のループだけにつける |
結果、myIP_buff1_pipe_64、myIP_buff1_pipe_64_a、myIP_buff1_pipe_64_bの3つでは結果は同じになりました。配列の宣言位置は影響なし、また、パイプラインディレクティブは多重ループの外側のループに付ければ、内側にも効く、ようです。
内側のループにだけパイプラインディレクティブを付けたmyIP_buff1_pipe_64_cでは、処理時間は約倍になりましたが、リソース使用量は大幅に抑えられました。実際のところ、外側の大きなループにパイプラインを付けてうまくいくケースはあまりないと思います(先ほど書いたように、内側のすべての処理にも影響してしまうため、リソース使用量が激増する)。ですので、パイプライン化するのは小さいループだけにして、大きな処理は後述するDATAFLOW化するといったsolutionが、リソース使用量などを考慮するとバランスの取れた方法だと思います。
2.4. 入出力でバッファを分ける
myIP_buff1_pipe_64では、バッファ(配列)を1つだけ宣言しています。その後、DDR上の元データ(src)からmemcpyして、BRAMをread/modify/writeして、DDR上の結果格納先(dst)にmemcpyしています。しかし、多くの場合、入出力でバッファを分けた方がいいです。BRAM使用量的が増えてしまいますが、バッファが1つしかないと、フィルタ処理などで元データの参照が出来なくなってしまいます。(ちなみに、左上のピクセルにアクセス、等が必要な時にはラインバッファは3本必要になると思います。実際には入力3本 + 出力1本かな)
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 18 | myIP_buff1_pipe_64 | 0.97 | 7.30 | 8 | 4 | 9223 | 4668 | 1:05 | 14:29 | BRAM(内蔵バッファ)に1ライン分コピーしてから計算。64-bit転送 |
| 22 | myIP_buff2_pipe_64 | 0.97 | 7.30 | 8 | 8 | 6080 | 5219 | 1:08 | 12:32 | myIP_buff1_pipe_64をベースに、BRAMを入出力の2つにした |
先ほどのバッファ1つバージョン(myIP_buff_pipe_64)と、バッファを2つに分けたバージョン(myIP_buff2_pipe_64)を比較したのが上の表になります。処理時間に違いはありませんが、BRAMのメモリ使用量が増加しています。一方、FF使用量が低下しています。おそらく、read/modify/write中に結果を保持する必要がないためだと思われます。
2.5. データアクセスを簡単に
最初の比較実験の結果、64-bitが一番速かったので、ここまで64-bit単位で処理してきました。しかし、そのためデータアクセスが面倒になっています。これまでのコードではいつも、一度uint64_tの変数に代入して、そこへのポインタをuint8_t*にキャストして使っていました。これだけでも面倒なのですが、この方法だと、8-byteアラインを超えたデータにアクセスすることが出来ません(例えば、20個左のピクセル値の取得などができない)。
少なくとも同じBRAM上にあるデータは簡単に取れるようにしたいです。
2つの方法を考えました。1つは、所定の8-bitのデータをシフト、マスク演算によって取り出す関数をinline実装する(myIP_buff2_pipe_mask_64)。もう一つは、BRAMに配置される64-bitの配列を8-bitにキャストして使用する(myIP_buff2_pipe_cast_64)です。
なお、64-bitから8-bitにキャストできたのは入力用BRAMだけで、出力用BRAMはエラーが発生しました。色々と実装方法を変えて試したのですが、ダメでした。他にも、BRAMの配列宣言を8-bitにするなどしてみたのですが、それもダメ。ug473を見ると、独立した読み出しポートと書き込みポートの幅を選択といったことが書いてあるのでできると思うのですが、うまくいきませんでした。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 22 | myIP_buff2_pipe_64 | 0.97 | 7.30 | 8 | 8 | 6080 | 5219 | 1:08 | 12:32 | myIP_buff1_pipe_64をベースに、BRAMを入出力の2つにした |
| 23 | myIP_buff2_pipe_mask_64 | 0.97 | 7.30 | 8 | 8 | 6080 | 5219 | 1:02 | 12:57 | myIP_buff2_pipe_64亜種。BRAMアクセス方法を工夫(マスクして取り出し) |
| 24 | myIP_buff2_pipe_cast_64 | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:10 | 11:48 | myIP_buff2_pipe_64亜種。BRAMアクセス方法を工夫(キャストアクセス) |
| 25 | myIP_buff2_pipe_cast_64_a | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:15 | 10:56 | myIP_buff2_pipe_cast_64の亜種。PIPELINEを外側と内側のループにつける |
結果、myIP_buff2_pipe_mask_64ではmyIP_buff2_pipe_64と同じ結果になりました。明示的に実装しないでもコンパイラが同様のコードにしているのだと思います。ただ、実装を楽に分かりやすくするためにはmyIP_buff2_pipe_mask_64の方がいいと思います。myIP_buff2_pipe_cast_64だと処理時間は微増ですが、FF使用量は大幅に削減されました。
myIP_buff2_pipe_mask_64とmyIP_buff2_pipe_cast_64は、出力の単位(nearly=処理の単位)は64-bitのままですが、入力データへはバイト単位でアクセスできるようになったので、少しは使いやすくなりました。
ちなみに、BRAMに配置される配列の宣言位置を、for文の外にしたり、中で宣言したりしましたが、結果には影響しませんでした。
2.6. 関数化してみる
ここまで、1つの関数内で処理を記載していましたが、メインロジックは別の関数にまとめたくなります。myIP_buff2_pipe_cast_64をベースに色々と変えてみました。一つはfor文を含む処理をそのまま関数化し(myIP_buff2_pipe_cast_noinline_64)、もう一つは#pragma HLS INLINEを付けてインライン化しました(myIP_buff2_pipe_cast_inline_64)。また、DDRとBRAMコピーには今までmemcpyを使ってきましたが、自前のfor文ループでコピーする(myIP_buff2_pipe_cast_copyfunc_64)を作りました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 24 | myIP_buff2_pipe_cast_64 | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:10 | 11:48 | myIP_buff2_pipe_64亜種。BRAMアクセス方法を工夫(キャストアクセス) |
| 26 | myIP_buff2_pipe_cast_noinline_64 | 1.01 | 7.30 | 8 | 8 | 9871 | 6908 | 1:16 | 14:06 | myIP_buff2_pipe_cast_64亜種。メインロジックを関数化 |
| 27 | myIP_buff2_pipe_cast_inline_64 | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:35 | 11:21 | myIP_buff2_pipe_cast_64亜種。メインロジックをinline関数化 |
| 28 | myIP_buff2_pipe_cast_copyfunc_64 | error | 7.3 | 8 | 8 | 22300 | 29747 | 11:59 | 22:16 | myIP_buff2_pipe_cast_64亜種。メインロジックとmemcpyを自前関数化 |
結果、myIP_buff2_pipe_cast_inline_64はmyIP_buff2_pipe_cast_64と同じ結果になりました。一方、myIP_buff2_pipe_cast_noinline_64はFFとLUT使用量が増加してしまいました。つまり、あまり関数化はしない方がいいということでしょうか?
また、myIP_buff2_pipe_cast_copyfunc_64はリソース使用量も桁違いに増加し、ハードウェア作成時にエラーが発生しました(ERROR: [VPL-4] Design failed to meet timing.)。クロックを下げればいけるのかもしれませんが、今回はやりません。
3. DATAFLOWを使う
ここまで、高速化のために#pragma HLS PIPELINEを使ってきました。しかし、PIPELINEだと演算子単位でパイプライン化したり、ループを全部展開してしまったりと、強力すぎる場面も多々あります(コンパイルにめちゃくちゃ時間がかかった挙句、リソース不足で使えないということが結構あります)。
PIPELINEと似たものに#pragma HLS DATAFLOWがあります。こっちは関数呼び出しの粒度でパイプライン化してくれます。(こっちの方が一般にイメージするパイプラインに近いように思えます。)
3.1. 実装の注意点
-
DATAFLOW化できるのは、データ転送やシンプルな処理のみ
-
条件付き実行や、終了条件が複数あるループはだめ
-
同じ変数を、色々な場所で更新したり使用したりするのはよくない
- 下記のように、論理的には同じコードでも、src(ポインタ)の更新方法によってはエラーになる
DATAFLOW化できるケースと出来ないケースOK: for (int i = 0; i < blockNum; i++) { #pragma HLS DATAFLOW memcpy(buffSrc, src + i * BLOCK_SIZE / 8, BLOCK_SIZE); ... } ERROR: for (int i = 0; i < blockNum; i++) { #pragma HLS DATAFLOW memcpy(buffSrc, src, BLOCK_SIZE); src += BLOCK_SIZE / 8 ... } -
変数、バッファに対してread/modify/writeしない
- 先ほど出てきた、バッファを1つだけ使うコード(myIP_buff1_pipe)では、DATAFLOW化できない。
- 途中からバッファを入出力の2つに分けたが、これだとOK
ちなみに、バッファの宣言はループや#pragma HLS DATAFLOWの前でも後でも、結果には影響はなかったです。
3.2 パイプラインとの比較
今後は、バッファを2個使うケースだけを考えます。まずは先ほどの、パイプライン化してキャストしてアクセスするmyIP_buff2_pipe_cast_64と、同じコードで外側のループにパイプライン化ディレクティブの代わりに#pragma HLS DATAFLOWを付けてみました(myIP_buff2_df_cast_64)。また、さらに、内側のループにパイプライン化ディレクティブを付けてみました(myIP_buff2_df_cast_pipe_64)。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 24 | myIP_buff2_pipe_cast_64 | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:10 | 11:48 | myIP_buff2_pipe_64亜種。BRAMアクセス方法を工夫(キャストアクセス) |
| 29 | myIP_buff2_df_cast_64 | 1.33 | 7.30 | 14 | 0 | 1491 | 2218 | 0:23 | 9:29 | myIP_buff2_pipe_cast_64の外側ループをDATAFLOW。内側ループはディレクティブなし |
| 30 | myIP_buff2_df_cast_pipe_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:26 | 8:53 | myIP_buff2_pipe_cast_64の外側ループをDATAFLOW。内側ループはPIPELINE |
| 31 | myIP_buff2_df_cast_pipe_64_a | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 8:52 | myIP_buff2_df_cast_pipe_64亜種。BRAM宣言をループ外 |
結果、myIP_buff2_df_cast_64では、全体をパイプライン化したmyIP_buff2_pipe_cast_64よりかは少し遅くなっていますが、リソース使用量は大幅におされられています。また、内側ループをパイプライン化したmyIP_buff2_df_cast_pipe_64では、リソース使用量がおさえられつつ、処理時間も早いままです。(むしろ、パイプライン化の時より少し速い)
今回くらいの規模だと一番外側にPIPELINEディレクティブを付けることが出来ましたが、メインロジックが複雑になると、リソース不足になる可能性があります。その場合には、DATAFLOWを使った方がいいと思います。
3.3 色々な実装を試す
先ほどのパイプライン化と同じように、いくつかの実装パターンを試しました。
- myIP_buff2_df_mask_pipe_64: キャストの代わりに、マスクとシフト演算でアクセスします
- myIP_buff2_df_cast_noinline_64: メイン処理のループを関数化
- myIP_buff2_df_cast_inline_64: メイン処理のループをインライン関数化
- myIP_buff2_df_cast_copyfunc_64: memcpyを自前の関数化
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 29 | myIP_buff2_df_cast_64 | 1.33 | 7.30 | 14 | 0 | 1491 | 2218 | 0:23 | 9:29 | myIP_buff2_pipe_cast_64の外側ループをDATAFLOW。内側ループはディレクティブなし |
| 32 | myIP_buff2_df_mask_pipe_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 8:58 | myIP_buff2_df_cast_pipe_64で、BRAMアクセスにキャストではなくマスク使用 |
| 33 | myIP_buff2_df_cast_noinline_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 9:15 | myIP_buff2_df_cast_pipe_64亜種。メインロジックを関数化 |
| 34 | myIP_buff2_df_cast_inline_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 8:56 | myIP_buff2_df_cast_pipe_64亜種。メインロジックをinline関数化 |
| 35 | myIP_buff2_df_cast_copyfunc_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 9:57 | myIP_buff2_df_cast_pipe_64亜種。メインロジックとmemcpyを自前関数化 |
今回は、いずれのケースでも結果は同じになりました。なんでだろう。。
とりあえず、ここまでのまとめとしては、以下の2つが使い勝手がよさそうです。
- myIP_buff2_pipe_cast_inline_64: 速度重視
- myIP_buff2_df_cast_inline_64: バランス型
4. array_partitionを使う
DDRからBRAMにデータコピーしたからと言って、ディレイ無しでデータアクセスできるわけではありません。データアクセスが多発するような処理では、BRAMへのアクセス時間がボトルネックになることがあります。この時、BRAMに配置される配列を、小型の配列に分割して、読み書きポート数を増加させて、転送を早くすることが出来るらしいです。ARRAY_PARTITIONという機能だそうです。#pragma HLS ARRAY_PARTITION variable=buffSrc block factor=2といった記述で設定します。これは、buffSrcというBRAM配列を、block型で2つに分割するという意味です。array_partitionで分割しても、コード上のアクセスは通常通りで大丈夫らしいです。
タイプとしては、complete、cyclic、blockがあります。デフォルトのcompletetypeだと、メモリは使われずレジスタに分割されるっぽいです。せいぜい数十Byte程度の小さい容量に使うんだと思います。今回の用途では使わないです。cyclictypeだと、インターリーブ配置になるっぽいです。packed配置のYUVやRGBを格納するのに便利そうです。planarだと使わないと思います。blocktypeだと、単に1つの配列をN個のブロックに分割してくれる。
4.1. キャストしてBRAMアクセスしている場合は不可
これまで主に、64-bit幅のデータにバイト単位でアクセスするために、8-bit幅にキャストしてきました(myIP_buff2_pipe_cast_inline_64、myIP_buff2_df_cast_inline_64)。しかし、これらに対してarray_partitionを使おうとしたら、ERROR: [XFORM 203-103] unsupported array access (reinterpret, etc.).エラーが発生しました。uint64_tをuint8_tにキャストしてアクセスしているのが原因っぽいです。
4.2. 分割数ごとの比較
ということで、ここではmyIP_buff2_df_mask_pipe_64とmyIP_buff2_pipe_mask_64のメイン処理をinline関数化した、myIP_partition_0_pipe_mask_64とmyIP_partition_0_df_mask_64をベースに比較します。myIP_partition_0_pipe_mask_64とmyIP_partition_0_df_mask_64はどちらも、実質的には先ほどのmyIP_buff2_df_mask_pipe_64とmyIP_buff2_pipe_mask_64と同じです。
分割なし、2分割、4分割で比較します。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 36 | myIP_partition_2_pipe_cast_64 | error | error | error | error | error | error | error | error | myIP_buff2_pipe_cast_inline_64で、BRAMのARRAY_PARTITION(block, factor=2) |
| 37 | myIP_partition_2_df_cast_64 | error | error | error | error | error | error | error | error | myIP_buff2_df_cast_inline_64で、BRAMのARRAY_PARTITION(block, factor=2) |
| 38 | myIP_partition_0_pipe_mask_64 | 0.97 | 7.30 | 8 | 8 | 6080 | 5219 | 1:04 | 12:38 | myIP_buff2_pipe_mask_64で、メインロジックをinline関数化 |
| 39 | myIP_partition_2_pipe_mask_64 | 0.99 | 7.30 | 8 | 0 | 2396 | 3481 | 0:51 | 10:58 | myIP_partition_0_pipe_mask_64で、BRAMのARRAY_PARTITION(block, factor=2) |
| 40 | myIP_partition_4_pipe_mask_64 | 0.99 | 7.30 | 8 | 0 | 2396 | 3481 | 0:56 | 10:58 | myIP_partition_0_pipe_mask_64で、BRAMのARRAY_PARTITION(block, factor=4) |
| 41 | myIP_partition_0_df_mask_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:24 | 9:47 | myIP_buff2_df_mask_64で、メインロジックをinline関数化 |
| 42 | myIP_partition_2_df_mask_64 | 0.96 | 7.30 | 16 | 0 | 1562 | 2448 | 0:23 | 9:47 | myIP_partition_0_df_mask_64で、BRAMのARRAY_PARTITION(block, factor=2) |
| 43 | myIP_partition_4_df_mask_64 | 0.96 | 7.30 | 24 | 0 | 1591 | 2404 | 0:24 | 9:41 | myIP_partition_0_df_mask_64で、BRAMのARRAY_PARTITION(block, factor=4) |
結果、処理時間はほとんど変わりませんでした。これは、今回の処理ではBRAMへのアクセスが少ないため、ここを改善しても効果がなかったためだと思います。データアクセスが多発する処理だと効果が出てくると思います。
リソース使用量の観点で見ると、データフローを使用した方は何となくイメージ通りです。分割数が増えるにしたがってBRAM(のinstance)使用量が増加しています。しかし、パイプラインを使用した方は、分割無しのケースがBRAM使用量もFF/LUT使用量も多いという不思議な結果になりました。謎です。
5. streamを使う
コード
https://github.com/take-iwiw/SDSOC_VARIOUS_IMPLEMENTATIONS/blob/master/test_myip/src/myIP_stream.cpp
ここまで、パフォーマンス改善の手段として、大きくPIPELINEとDATAFLOWを使ってきました。他にもstreamというものがあります。概念的にはDATAFLOWと似ているのですが、単位が違います。DATAFLOWは関数単位でパイプライン化します。一方streamはデータ(今回の場合はuint64_tの変数)の流れでパイプライン化します。このデータ(変数)が逐次流れ(stream)ていきます。
なお、この流れは川の流れのように一方通行で、逆流はできません。そのため逐次処理に向いていると思います。逆に、フィルタ処理のように、左のピクセルのデータや上のピクセルのデータをreadするといったことが出来ません。(やろうと思えばできるのかもしれませんが、大変だと思います。)
streamを使うには、hls::stream<uint64_t>でデータが流れるときに通るfifoを定義してあげるだけです。後は>>と<<でデータを送ったり、受け取ったりします。データ型として今回はuint64_tを使っていますが、構造体でも大丈夫なようです。
そして、すべての処理をDATAFLOWディレクティブで囲ってあげます。
void myIP_stream_df_all_64(uint64_t* dst, uint64_t* src, int blockNum)
{
hls::stream<uint64_t> fifoSrc;
hls::stream<uint64_t> fifoDst;
# pragma HLS DATAFLOW
read_all_64(fifoSrc, src, blockNum);
process_all_64(fifoSrc, fifoDst, blockNum);
write_all_64(fifoDst, dst, blockNum);
}
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 44 | myIP_stream_df_64 | error at index(1024). src = 4, dst = 0 | 7.30 | 8 | 0 | 1434 | 2299 | 0:24 | 9:37 | myIP_simple_pipe_64の処理をstream化 (行単位) |
| 45 | myIP_stream_df_all_64 | 0.78 | 7.30 | 8 | 0 | 1526 | 2405 | 0:23 | 9:39 | myIP_simple_pipe_64の処理をstream化 |
結果、myIP_simple_pipe_64同等の性能になりました。これは、BRAMを使用していないため、ほぼ同じような結果になったのだと思います。
5.1. 一部分だけをstream化
先ほどは、すべての処理をDATAFLOWディレクティブで囲いましたが、これを行単位でやってみました。
ハードウェア化は問題なくできたのですが、2行目以降の実行結果が間違えていました。
void myIP_stream_df_64(uint64_t* dst, uint64_t* src, int blockNum)
{
hls::stream<uint64_t> fifoSrc;
hls::stream<uint64_t> fifoDst;
for (int i = 0; i < blockNum; i++) {
# pragma HLS DATAFLOW
read_64(fifoSrc, src);
process_64(fifoSrc, fifoDst);
write_64(fifoDst, dst);
}
}
6. AXI DMAを使用
コード
https://github.com/take-iwiw/SDSOC_VARIOUS_IMPLEMENTATIONS/blob/master/test_myip/src/myIP_dma.cpp
特に説明はしていなかったのですが、ここまで、DDRとハードウェア関数のインターフェイスにはzero_copyというプラグマをヘッダファイル内の関数宣言の直前に付けていました。これによって、自動的にAXI-Masterインターフェイスが生成されます(おそらくIP内部に)。
# pragma SDS data zero_copy(dst[0:BLOCK_SIZE*blockNum/8], src[0:BLOCK_SIZE*blockNum/8])
void myIP_simple_pipe_64(uint64_t* dst, uint64_t* src, int blockNum);
DDR-IP間でデータをコピーするもの(データムーバ-: data mover)として、明示的に色々なものを指定できます。今回は、AXI_DMA_SIMPLEを使うよう指示してみます。
//#pragma SDS data zero_copy(dst[0:BLOCK_SIZE*blockNum/8], src[0:BLOCK_SIZE*blockNum/8])
# pragma SDS data copy(dst[0:BLOCK_SIZE*blockNum/8], src[0:BLOCK_SIZE*blockNum/8])
# pragma SDS data access_pattern(dst:SEQUENTIAL, src:SEQUENTIAL)
# pragma SDS data data_mover(dst:AXIDMA_SIMPLE, src:AXIDMA_SIMPLE)
void myIP_dma_simple_pipe_64(uint64_t* dst, uint64_t* src, int blockNum);
6.1. memcpyがあるとデータムーバとしてAXI DMAは使えない
タイトルの通りです。これまで、DDRからBRAMへのデータコピーにはほとんどの場合memcpyを使っていました。しかし、それだとERROR: [SYNCHK 200-22] test_myip/src/myIP_dma.cpp:79: memory copy is not supported unless used on bus interface possible cause(s): non-static/non-constant local array with initialization).といったエラーが出ました。
ということで、BRAMを使う実装の場合には、memcpyではなく自前のcopy関数を使ったコードと比較します。
6.2 比較
myIP_simple_pipe_64とmyIP_buff2_df_cast_copyfunc_64と、それぞれを使うようにした、myIP_dma_simple_pipe_64とmyIP_dma_df_copyfunc_64を比較します。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 35 | myIP_buff2_df_cast_copyfunc_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 9:57 | myIP_buff2_df_cast_pipe_64亜種。メインロジックとmemcpyを自前関数化 |
| 46 | myIP_dma_simple_pipe_64 | 0.66 | 7.27 | 0 | 0 | 56 | 124 | 0:19 | 9:36 | myIP_simple_pipe_64で、pragmaをDMA化 |
| 47 | myIP_dma_pipe_cast_64 | error | error | error | error | error | error | error | error | myIP_buff2_pipe_cast_64で、pragmaをDMA化 |
| 48 | myIP_dma_df_cast_64 | error | error | error | error | error | error | error | error | myIP_buff2_df_cast_inline_64で、pragmaをDMA化 |
| 49 | myIP_dma_pipe_copyfunc_64 | error | 6.89 | 8 | 0 | 4729 | 6153 | 1:10 | 12:56 | myIP_buff2_pipe_cast_copyfunc_64で、pragmaをDMA化 |
| 50 | myIP_dma_df_copyfunc_64 | 0.69 | 6.89 | 6 | 0 | 132 | 458 | 0:25 | 10:21 | myIP_buff2_df_cast_copyfunc_64で、pragmaをDMA化 |
結果、どちらも、処理時間もリソース使用量ともに大幅に削減されました。
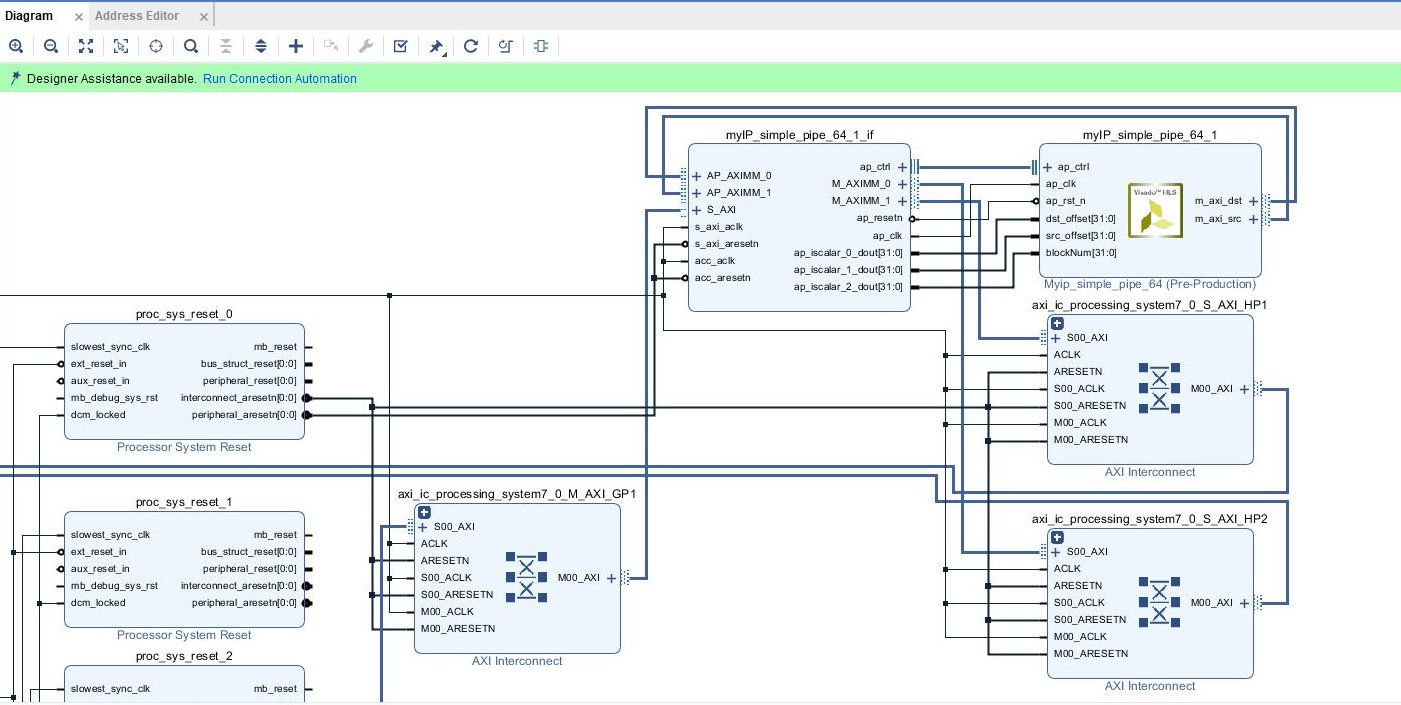
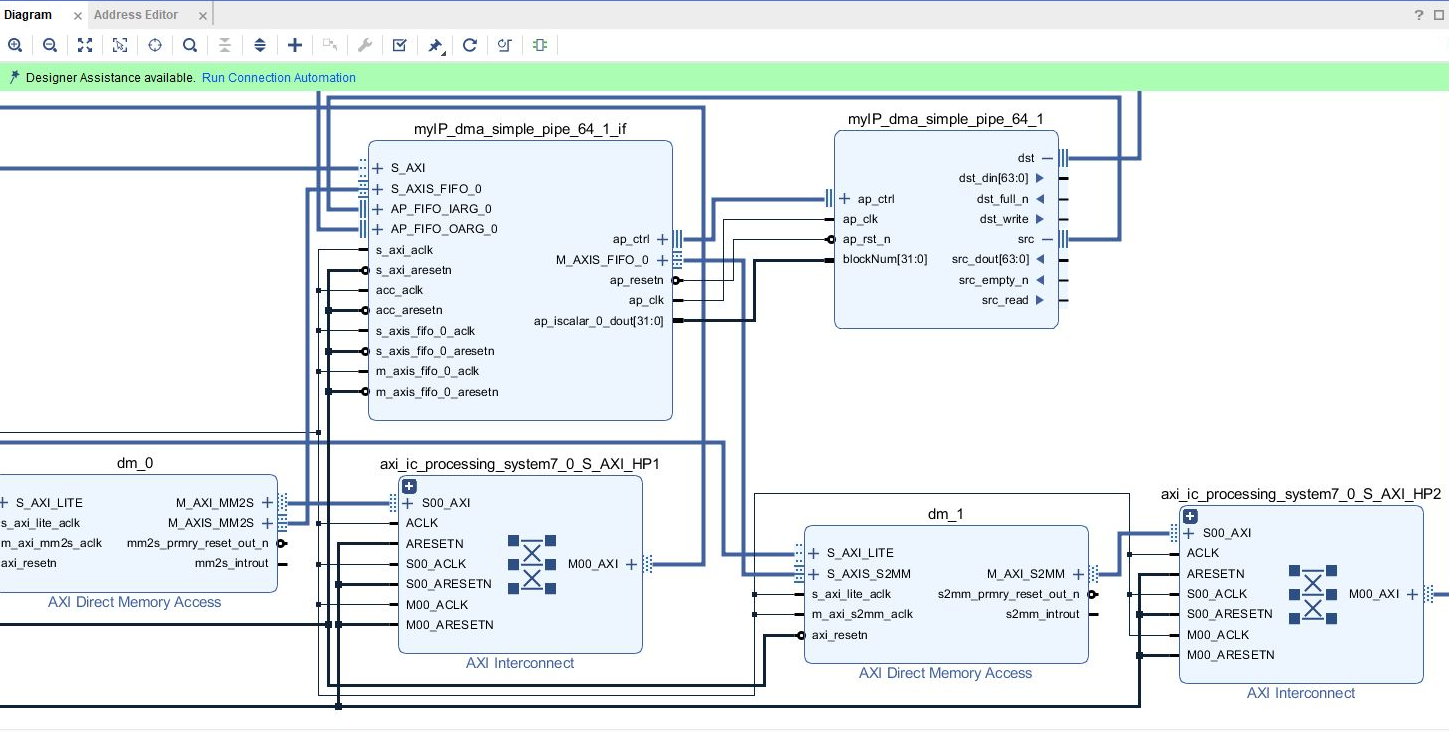
しかし、リソース使用量に関しては、DMAを使う方はIPの外にDMAが作られただけです。生成されたVIVADOプロジェクトで全体のデザインを比較すると、myIP_dma_simple_pipe_64の方ではDMAが作られているのが分かります。
↓ zero_copy使用
↓ AXI DMA使用
7. その他色々
7.1 ループの終了条件を変数化
コード
https://github.com/take-iwiw/SDSOC_VARIOUS_IMPLEMENTATIONS/blob/master/test_myip/src/myIP_var.cpp
今回の実装はいずれも、uint8_t[1024 * blockNum]という配列を処理することを目的としています。これは、2次元の画像を想定しており、横サイズは1024固定。縦サイズが変数(blockNum)という想定です。そのため、行単位の処理は全て固定値でしたが、それを変数化してみます。以下、2つの実装を考えます。元々は、BLOCK_SIZEという固定の定義値を使っていたのを、同じ値の変数を設定するようにしました。
- myIP_buff2_pipe_cast_inline_var_64: myIP_buff2_pipe_cast_inline_64で、BLOCK_SIZEを変数化
- myIP_buff2_df_cast_inline_var_64: myIP_buff2_df_cast_inline_64で、BLOCK_SIZEを変数化
結果として、myIP_buff2_df_cast_inline_var_64の方は、ERROR: [XFORM 203-722] In dataflow (test_myip/src/myIP_var.cpp:38) of function myIP_buff2_df_cast_inline_var_64, conditional execution on is not supported.というエラーが出てしましました。これは、終了条件が可変なループであるためです。
myIP_buff2_pipe_cast_inline_var_64を元の実装と比較すると以下の通りでした。
処理時間は2倍以上になってしまいましたが、リソース使用量は少なくなりました。これは、内側ループのパイプライン化(並列化)がそんなにできなくなったためだと思われます。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 27 | myIP_buff2_pipe_cast_inline_64 | 1.00 | 7.30 | 8 | 8 | 4220 | 5367 | 1:35 | 11:21 | myIP_buff2_pipe_cast_64亜種。メインロジックをinline関数化 |
| 34 | myIP_buff2_df_cast_inline_64 | 0.96 | 7.30 | 14 | 0 | 1486 | 2237 | 0:22 | 8:56 | myIP_buff2_df_cast_pipe_64亜種。メインロジックをinline関数化 |
| 51 | myIP_buff2_pipe_cast_inline_var_64 | 2.51 | 7.30 | 8 | 6 | 2037 | 2694 | 0:21 | 9:59 | myIP_buff2_pipe_cast_inline_64で、BLOCK_SIZEを変数化 |
| 52 | myIP_buff2_df_cast_inline_var_64 | error | error | error | error | error | error | error | error | myIP_buff2_df_cast_inline_64で、BLOCK_SIZEを変数化 |
7.2. Debug/Releaseによる違い
プロジェクトをビルドする際に、Debug/Releaseで違いがあるかを確認しました。
結果、ハードウェア的な観点でいうと全く同じものが出来上がりました。また、実行したところ処理時間も同じでした。
SDSoCではビルド時に、ハードウェア関数、及び呼び出しコードのスタブが作られます(Release\_sds\swstubs\)。ここで、冒頭で記したように、キャッシュのクリアなどの処理が付加されます。
これが何のためのコード化分からないのですが、DebugとReleaseでportinfo.cファイル内に違いがありました。Releaseの時にはaccel_open()、accel_close()呼び出しがありました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | myIP_simple_pipe_64_Release | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 53 | myIP_simple_pipe_64_Debug | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:18 | 7:41 | myIP_simple_64のループをパイプライン化 |
7.3. 他のハードウェア関数による影響
今回の実験では、ハードウェア化する関数は常に1度に1つだけにしました。実は、これは実験初期にはまったのですが、一緒にハードウェア化される関数によって結果に影響が出てしまいます。
myIP_simple_pipe_64を単独でハードウェア化した場合と、他の関数(myIP_simple.cpp、myIP_buff2_pipe_64、myIP_buff2_pipe_mask_64、myIP_buff2_pipe_cast_64、myIP_buff2_pipe_cast_64_a)をまとめてハードウェア化した場合で結果を比べてみました。
myIP_buff2_pipe_64も同様に、単独でハードウェア化した場合と、他の関数とまとめてハードウェアかした場合で結果を比べました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | myIP_simple_pipe_64 | 0.78 | 7.30 | 8 | 0 | 1281 | 1755 | 0:20 | 9:36 | myIP_simple_64のループをパイプライン化 |
| 22 | myIP_buff2_pipe_64 | 0.97 | 7.30 | 8 | 8 | 6080 | 5219 | 1:08 | 12:32 | myIP_buff1_pipe_64をベースに、BRAMを入出力の2つにした |
| 54 | myIP_simple_pipe_64_混合 | 0.68 | 7.30 | 8 | 0 | 1281 | 1755 | - | - | myIP_simple.cpp、myIP_buff2_pipe_64、myIP_buff_pipe.cpp、myIP_buff_pipe.cpp、myIP_buff_pipe.cppをまとめてハードウェア化 |
| 55 | myIP_buff2_pipe_64_混合 | 1.23 | 7.30 | 8 | 8 | 6080 | 5218 | - | - | myIP_simple.cpp、myIP_buff2_pipe_64、myIP_buff_pipe.cpp、myIP_buff_pipe.cpp、myIP_buff_pipe.cppをまとめてハードウェア化 |
結果として、HLSが出力するIP単品としては同じものが出来上がりました。自動生成されるスタブ関数も特に違いはありませんでした。しかし、処理時間が異なりました。
myIP_simple_pipe_64の方は高速化され、myIP_buff2_pipe_64の方は遅くなっていました。
何が要因か、よくわかっていないのですがバス構成じゃないかと思っています。
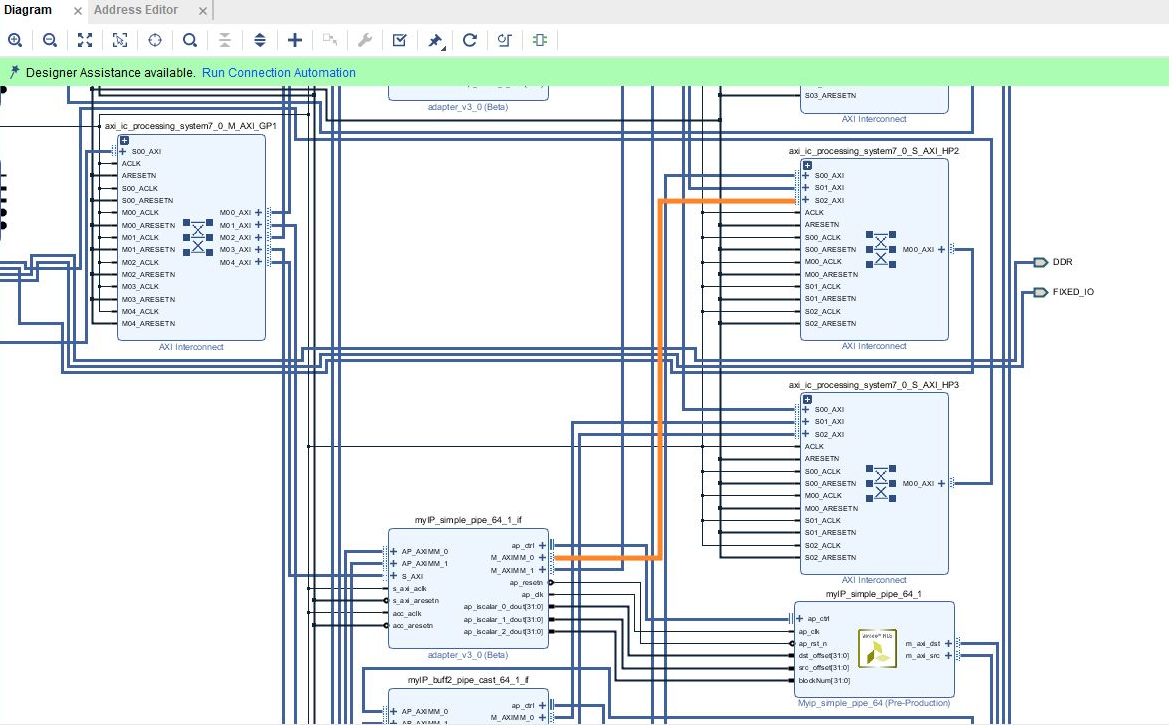
出来上がったハードウェア全体のプロジェクトをVivadoで確認してみました。(ちなみに、Vivadoプロジェクトはtest_myip\Release\_sds\p0\vivado\prj\prj.xprに作られます)。
対象とするIP周辺で見ると特に違いはないのですが、DDR(HP)アクセス用のAXI Interconnectに接続されるIPの数が増加しています。これが原因なんじゃないかなと思っています。バス衝突が起きてるとか?
(あー、でも、テストコードの動き的に同時アクセスは起こりえないか。それに、遅くなるだけなら分かるのだけど、速くなるのが解せない)
↓ 単独でハードウェア化したとき
↓ 複数の関数をハードウェア化したとき
7.4. ノンブロッキング呼び出し
これまで、当然のようにハードウェア関数を呼ぶ前後で処理時間を測ってきました。しかし、処理自体はハードウェア側で実行されるので、その間CPUは自由に動けるはずです。が、実際には処理完了を待たされています。これは、sds\swstubs\内に自動生成されるコードで、処理の完了を待つように実装されるためです。
これをノンブロッキングコール(非同期)にするためには、ハードウェア関数の呼び出し直前に#pragma SDS async(<ID>)を入れます。完了を待つには#pragma SDS wait(ID)を入れます。IDは関数ごとではなく、グローバルで一意な値じゃないとダメっぽいです。
7.5 その他
- SDxのエラーログに表示される行番号は、元のソースコードの行番号ではなくて、
sds\swstubs\内に自動生成されるコード内の行番号 - ハードウェア関数のヘッダファイル内でpragmaを変えたら、Application Project Settingで再度ハードウェア関数の登録が必要。じゃないと反映されない
8. (追記) UNROLLを使う
PIPELINE、DATAFLOWと並んで、処理の高速化のためのディレクティブとして、UNROLLというものがあります。ループ文にUNROLLを付けるとそのループを展開してくれます。「ループ本体の複数コピーを作成して、ループの繰り返しカウンターをそれに合わせて調整します。」だそうです。(https://japan.xilinx.com/support/documentation/sw_manuals_j/xilinx2015_2_1/sdsoc_doc/topics/calling-coding-guidelines/concept_pipelining_loop_unrolling.html )。そのため、PIPELINE化よりUNROLLの方が高速化への期待度は大きいですが、使用リソースが増加したり、逆に同一リソース(特にメモリ)へのアクセスが集中してパフォーマンスが出ない可能性もありそうです。
ただ、よく分かっていないのですが、Xilinxフォーラムのいくつかの投稿を見ると、「PIPELINEディレクティブを付けた内側のループは展開される」ようです。ということは、PIPELINEディレクティブはUNROLLを含む? となるのですが、どうなんでしょう。PIPELINEディレクティブを付けた一番外のループは除いて、ネストされたループだけが展開される、ということでしょうか。よくわかりません。
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/How-can-I-prevent-pipelined-function-from-unroll/td-p/719898
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/How-to-pipeline-a-for-loop-including-functions/td-p/456030
https://forums.xilinx.com/t5/Vivado-High-Level-Synthesis-HLS/how-to-keep-sub-loops-rolled/td-p/710062
myIP_buff2_pipe_cast_64をベースに、外側のループにUNROLLを付けたもの(myIP_buff2_unroll_cast_64)、外側と内側の両方のループにUNROLLを付けたもの(myIP_buff2_unroll_unroll_cast_64)、内側のループにUNROLLを付けたもの(myIP_buff2_inner_unroll_cast_64)を試しました。
また、factorによって、ループを何個コピーするかを指定できます。それぞれ、指定なし、8、16、で試してみました。
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 56 | myIP_buff2_unroll_cast_64 | 2.67 | 7.30 | 8 | 6 | 1434 | 1964 | 0:20 | 9:43 | myIP_buff2_pipe_cast_64の外側ループをUNROLL。内側ループはディレクティブなし |
| 57 | myIP_buff2_unroll8_cast_64 | 3.16 | 7.30 | 8 | 6 | 3236 | 5370 | 0:26 | 9:57 | myIP_buff2_unroll_cast_64にfactor=8を付けた |
| 58 | myIP_buff2_unroll16_cast_64 | 3.16 | 7.30 | 8 | 6 | 5087 | 8926 | 0:34 | 10:09 | myIP_buff2_unroll_cast_64にfactor=16を付けた |
| 59 | myIP_buff2_unroll_unroll_cast_64 | 1.68 | 7.30 | 8 | 8 | 1472 | 3927 | 0:45 | 9:13 | myIP_buff2_pipe_cast_64の外側ループをUNROLL。内側ループもUNROLL |
| 60 | myIP_buff2_unroll8_unroll8_cast_64 | 2.33 | 7.30 | 8 | 8 | 3620 | 6638 | 0:27 | 10:17 | myIP_buff2_unroll_unroll_cast_64にfactor=8をつけた |
| 61 | myIP_buff2_unroll16_unroll16_cast_64 | 2.25 | 7.30 | 8 | 8 | 6495 | 14302 | 2:40 | 12:01 | myIP_buff2_unroll_unroll_cast_64にfactor=16をつけた |
| 62 | myIP_buff2_inner_unroll_cast_64 | 1.68 | 7.30 | 8 | 8 | 1472 | 3927 | 0:57 | 9:20 | myIP_buff2_pipe_cast_64の内側ループをUNROLL |
| 63 | myIP_buff2_inner_unroll8_cast_64 | 2.09 | 7.30 | 8 | 6 | 1485 | 2193 | 0:23 | 9:33 | myIP_buff2_inner_unroll_cast_64にfactor=8をつけた |
| 64 | myIP_buff2_inner_unroll16_cast_64 | 2.05 | 7.30 | 8 | 6 | 1529 | 2447 | 0:22 | 9:31 | myIP_buff2_inner_unroll_cast_64にfactor=16をつけた |
結果分かったこととしては、
- UNROLLディレクティブを外側ループにつけても、内側ループには適用はされない
- 展開数(factor)が多いからと言って、処理が高速化されるわけではない。むしろ遅くなるケースもある(リソース取り合いになるため?)
- factorを増やすことで、リソース使用量が増加しているため、並列化自体はされているのだと思います
- factor指定なしだと「ループは全展開(fully unrolled)」になる。とHLSのドキュメントには書かれている。が、実際にはfactorを指定した方が並列度は高いように見える
UNROLLとARRAY_PARTITIONを組み合わせてみる
UNROLLを使ってもあまり高速化さなかったです(むしろ、PIPELINEやDATAFLOWより遅い)。理由としてはBRAMアクセスが同時に発生することで、待たされてしまうのかな? と想像しました。
ということで、ARRAY_PARTITIONと組み合わせることで改善しないかを試してみました。
まずはfactor指定なしで外側と内側ループ両方をUNROLL化した関数を試しました。ARRAY_PARTITIONの分割数は0(ディレクティブなし)、2、4としました。(myIP_partition_0_unroll_mask_64,
myIP_partition_2_unroll_mask_64、myIP_partition_4_unroll_mask_64)。
また、factorに16を指定して、分割数を4にしたものも試しました。(myIP_partition_4_unroll16_mask_64)
| No. | IP名 | 処理時間 [msec] | Timing [nsec] | BRAM (instance) | BRAM (memory) | FF | LUT | IP作成時間 [sec] | HW作成時間 [sec] | 内容 |
|---|---|---|---|---|---|---|---|---|---|---|
| 65 | myIP_partition_0_unroll_mask_64 | 1.68 | 7.30 | 8 | 8 | 1472 | 3927 | 0:42 | 9:49 | myIP_buff2_unroll_unroll_cast_inline_64で、BRAMのARRAY_PARTITION(block, factor=0) |
| 66 | myIP_partition_2_unroll_mask_64 | 1.52 | 7.30 | 8 | 16 | 1437 | 3890 | 0:39 | 9:31 | myIP_buff2_unroll_unroll_cast_inline_64で、BRAMのARRAY_PARTITION(block, factor=2) |
| 67 | myIP_partition_4_unroll_mask_64 | 1.43 | 7.30 | 8 | 32 | 1425 | 4035 | 0:49 | 9:30 | myIP_buff2_unroll_unroll_cast_inline_64で、BRAMのARRAY_PARTITION(block, factor=4) |
| 69 | myIP_partition_4_unroll16_mask_64 | 1.98 | 7.30 | 8 | 32 | 5889 | 21519 | 29:44 | 15:28 | myIP_partition_4_unroll_mask_64で、UNROLLのfactor=16 |
結果、UNROLLのfactor指定なしのケースでは、僅かですが処理時間が短くなりました。
また、factor=16としたケースでは、コンパイル時間、リソース使用量ともに爆増しました。コンパイル時間に至っては、IPの高位合成だけで30分近くかかりました。しかし、処理時間はfactor指定なしに比べて遅いという残念な結果になりました。
おわりに
色々と試したことをつらつらと書いていきました。
処理内容やリソース使用量との兼ね合いがあるので、「この方法が一番良い」というのはありませんが、PIPELINEなど有名どころの方法で実装したときにどうなるのか、の勘所を掴めた気がします。