この記事はアイスタイル Advent Calendar 2024 20日目の記事です。
みなさんおはようございます、こんにちは、こんばんはアイスタイルの@iwasakikです。
現在、DBREグループに所属しており、RDBMSのクラウド化全般とDBの運用を担当しています。
今回SQL ServerからTiDB Cloudを移行するプロジェクトにおけるパフォーマンス試験において、TiDB Cloudで大量のINSERTするときに工夫が必要だったのでその時のことを書きます。
これまでにもDB(主にMySQL)に関する記事をいくつか書いているので、よかったら見てください!
TiDB Cloudの導入検証している背景について
アイスタイルでは開発基盤Rebornというオンプレミスからクラウドへの移行PJTが進行中です。
弊社はメインDBの一つとしてオンプレミスのSQL Serverを利用していますが、こちらもクラウド移行の対象となっています。
オンプレミスのSQL Serverの脱却を図っているのは、コストや運用負荷の高さ・構成の複雑さなど多々理由があります。
オンプレミスのSQL Serverからの移行先として様々な候補が挙げられましたが、その中でもTiDB Cloudは主な移行先候補となっているため今回パフォーマンス検証を実施しました。
TiDB Cloudについて
TiDB Cloudはオープンソースの分散型SQLデータベース「TiDB」のフルマネージドサービスです。
多くの方が紹介してくださっているので詳細な説明は割愛しますが、以下の特徴があります。
- MySQL互換
- リアルタイムのHTAP(ハイブリッドトランザクショナルおよび分析処理)をサポート
- スケーラブルで高性能
- 高可用性と信頼性
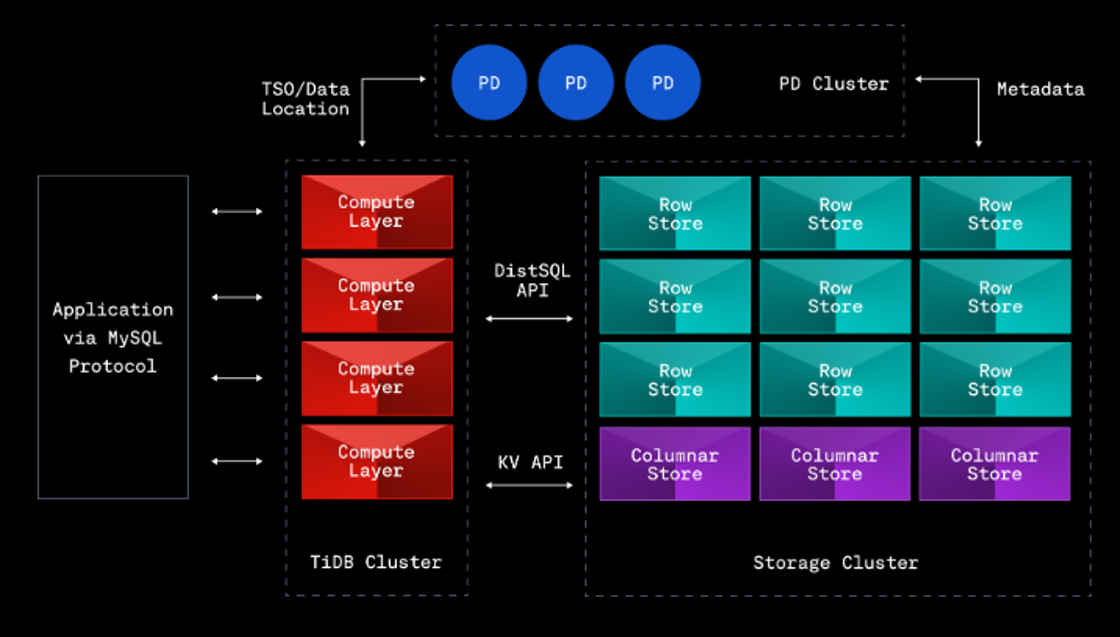
また、TiDBの主要コンポーネントは以下の通りです。
- TiDB
→ SQL解析レイヤー、ステートレス - TiKV
→ キーバリュー構造のデータストアレイヤー - PD
→ クラスター全体の管理を行う - TiFlash
→ 列指向ストレージエンジンでHTAPを実現(プラガブル)
TiDB Cloudのパフォーマンス検証について
TiDB Cloudが弊社のSQL Serverの移行先として適しているかを検証するためパフォーマンス試験を実施しました。
SQL ServerとTiDBで異なるタイプのデータベースかつ私自身がパフォーマンス検証に不慣れだったこともあり、準備や計画に苦戦しましたが他のメンバーの協力もあり以下の方法でパフォーマンス検証を実施することができました。
パフォーマンス検証方法の概要
- JDBC Runner on EC2を負荷試験ツールとして利用
- 本番運用しているSQL Serverから通常時と夜間バッチ実行時に流れているクエリを抽出
- 上記クエリがTiDBで実行できるようMySQL互換の構文へ変換
- それぞれの時間帯のQPS(Queries Per Second)を算出し、上記のクエリを利用して同じQPSを達成できるか、達成するためにはどの程度のスペックが必要になるかを測定
- SQL ServerとTiDB Cloudそれぞれでクエリの実行時間を測定し、パフォーマンスの違いを測定(今回の記事では触れません)
※本番環境のSQL Serverから100%すべてのSQLを抽出することは難しかったので代表的なクエリのみを利用しています。
検証実施時のTiDBクラスターのスペックは以下の通りです。
検証実施時のTiDBクラスターのスペック
| 項目 | 内容 |
|---|---|
| TiDB Version | v7.5.0 |
| TiDB Cluster Size | 8 vCPU, 16 GiB : 11 Nodes |
| TiKV Cluster Size | 16 vCPU, 64 GiB : 200GiB Storage × 12 Nodes |
| TiFlash Cluster Size | 32 vCPU, 128 GiB : 200GiB Storage × 1 Nodes |
パフォーマンス試験時に発生した課題について
背景
現行SQL Serverで単一テーブルに大量データのINSERTを行うバッチ処理があります。
試験項目の一つとしてそのINSERT処理が可能かを検証しました。
INSERT対象のテーブル・クエリは以下の通りです(実際のテーブル名・カラム名などは異なります)。
INSERTクエリはJDBC Runnerで実行するためjsに変換し、データはe_type,e_id,s_type,r_idに実際のデータを参考にしたランダムな値が入るようにしております。
CREATE TABLE `keywords` (
`e_type` smallint(6) NOT NULL,
`e_id` int(11) NOT NULL,
`s_type` smallint(6) NOT NULL,
`r_id` int(11) NOT NULL,
`d_order` int(11) NOT NULL,
`p_count` smallint(6) NOT NULL,
`p_display_order` int(11) DEFAULT NULL,
PRIMARY KEY (`e_type`,`e_id`,`s_type`,`r_id`) ,
KEY `idx_keywords_by_display_order` (`e_type`,`e_id`,`s_type`,`d_order`,`r_id`),
KEY `idx_keywords_reviews_by_photo_display_order` (`e_type`,`e_id`,`s_type`,`p_display_order`,`r_id`,`p_count`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
function run() {
var e_type = random(1, 8);
var e_id = random(1, 2100000000);
var s_type = random(1,3);
var r_id = random(1, 2100000000);
execute("INSERT INTO poc.keywords (e_type, e_id, s_type, r_id, d_order, p_count, p_display_order) VALUES( $int, $int, $int, $int, 1, 1, 1)", e_type, e_id, s_type, r_id)
}
発生した課題
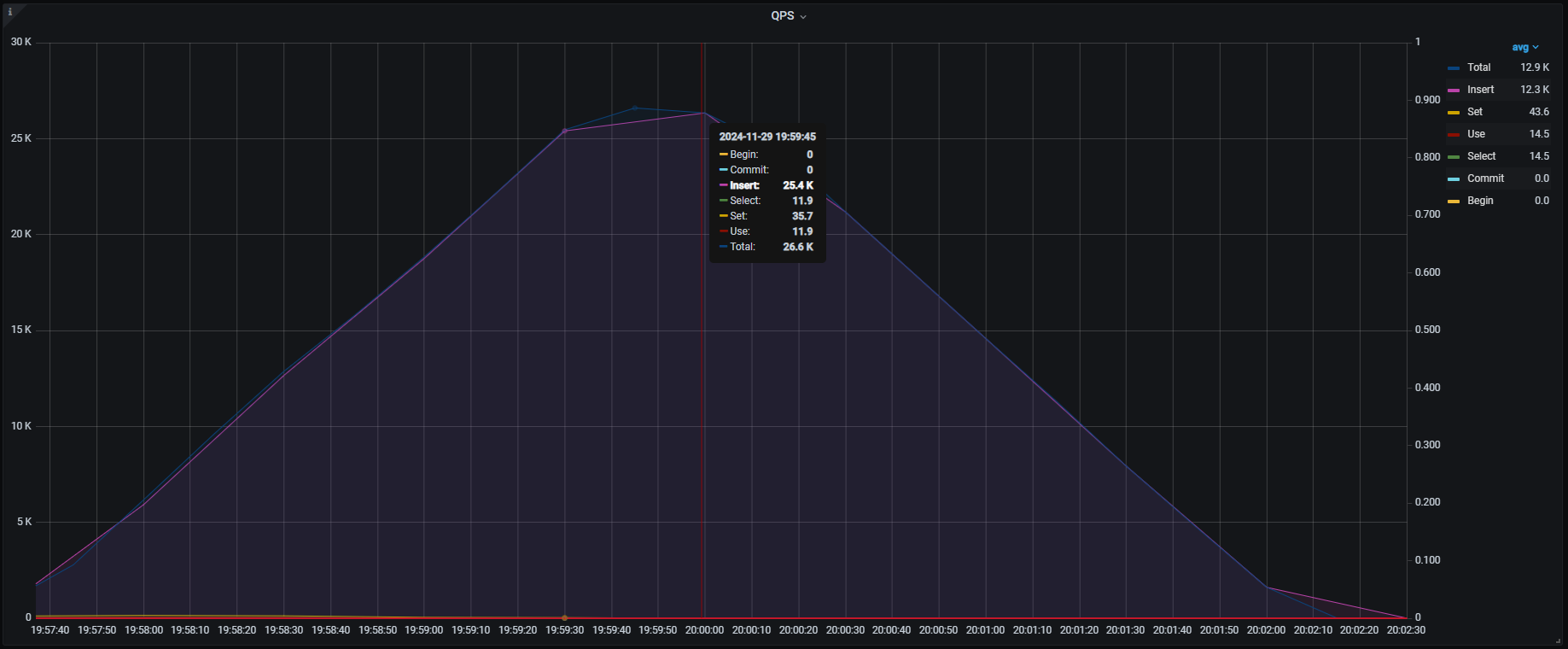
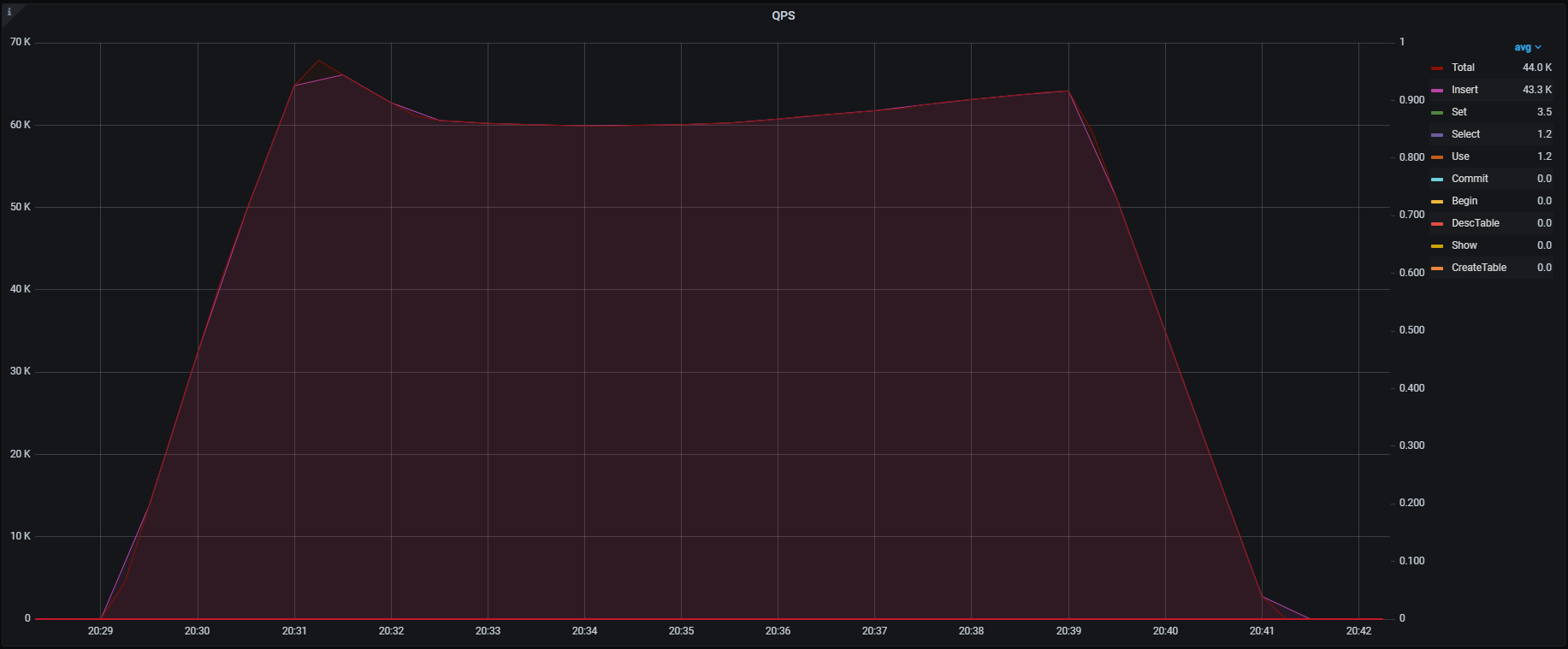
上記INSERT処理の目標QPSは50,000QPSでしたが、検証を実施したところ1テーブルに対するINSERT処理でどんなにJDBC Runner側のTPS(Transactions Per Second)設定をあげても25,000QPS程度で頭打ちになり、50,000QPSを達成することができませんでした。
※JDBC Runnerを実行しているEC2の負荷は問題ありませんでした。
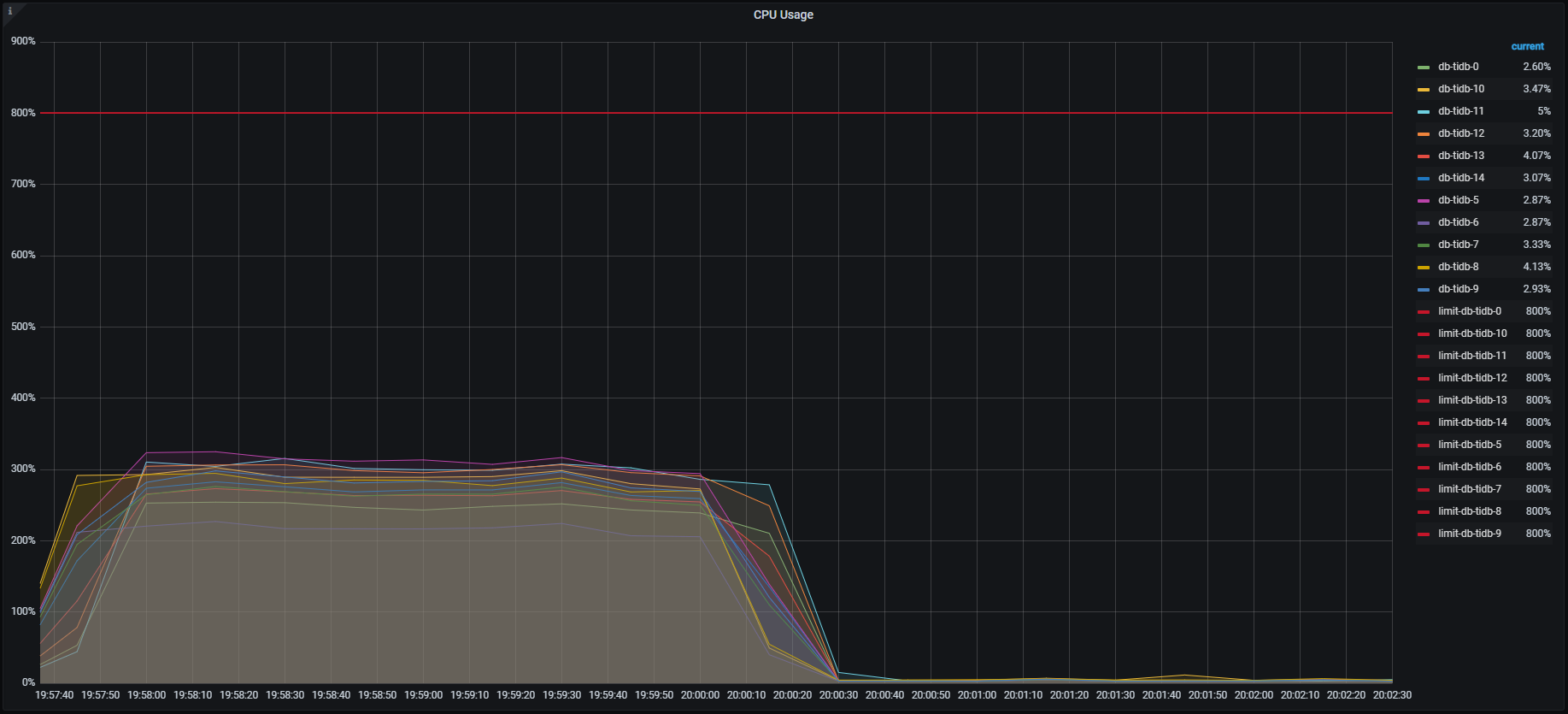
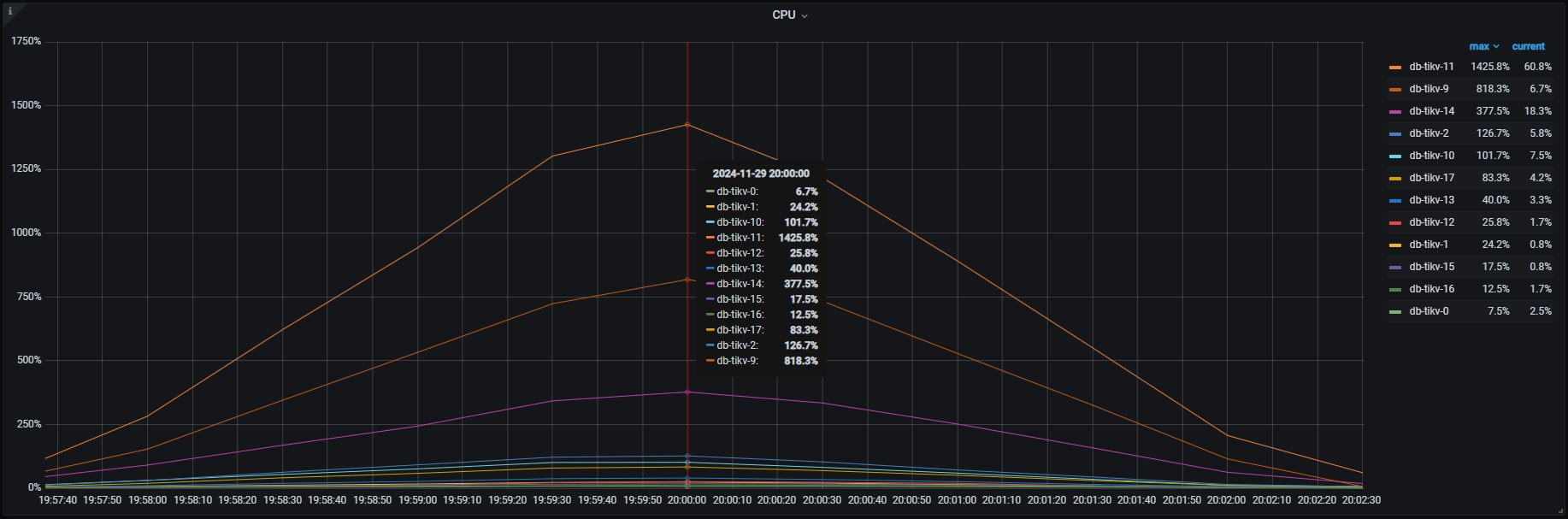
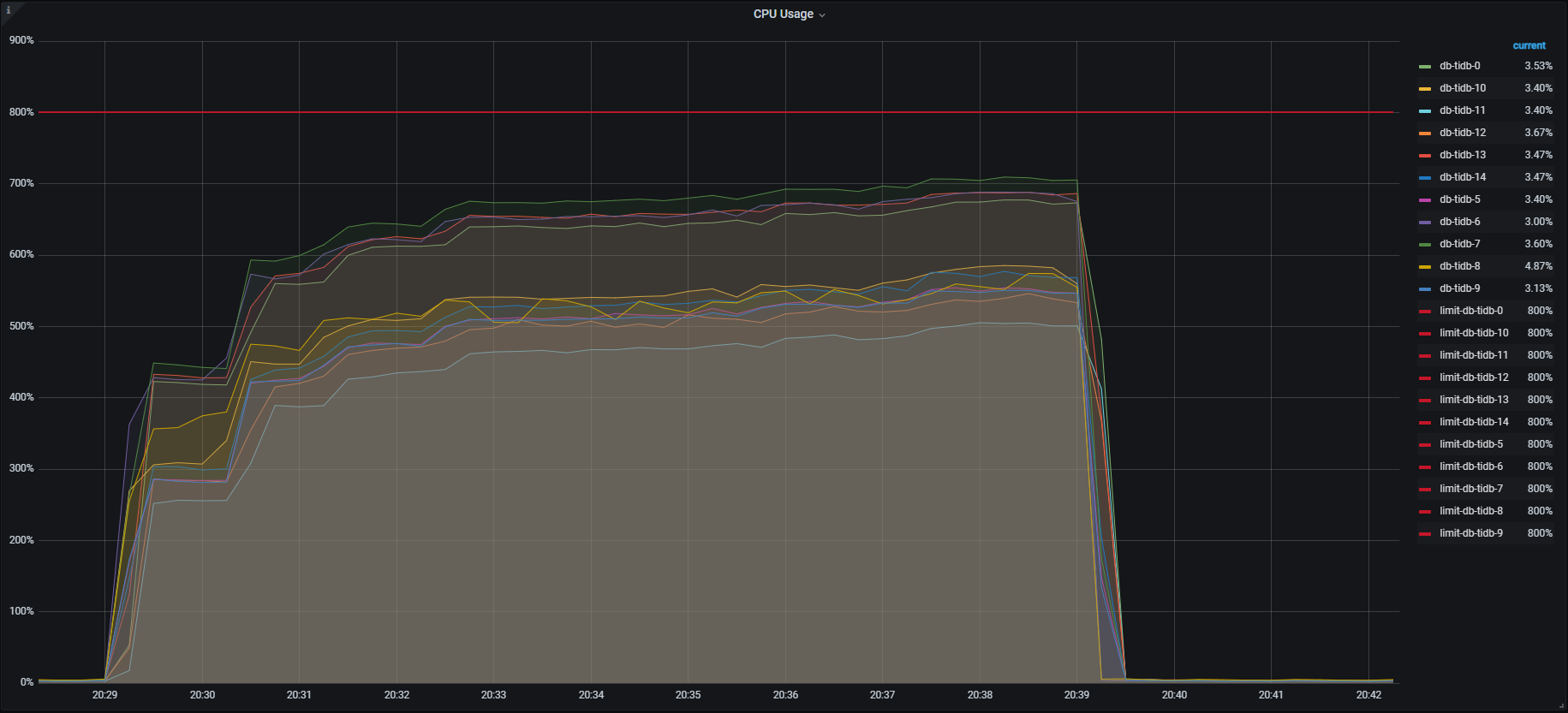
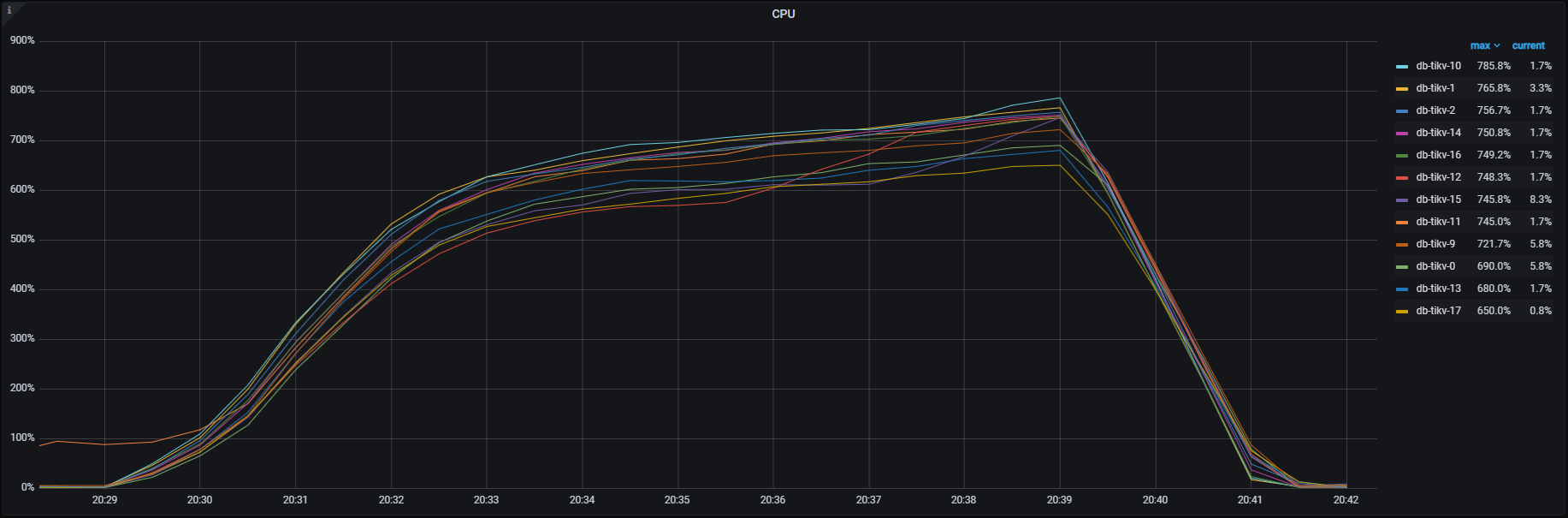
各種メトリクスを見るとTiKV , TiDBそれぞれこのようになっており、特にTiKVでは一部のノード(db-tikv-11)に負荷の偏りが見られました。
QPS
TiDB CPU負荷
TiKV CPU負荷
解決方法
PingCAP社のサポートの力もお借りして、以下の方法でQPSが出ない問題を解決しました。
解決方法1:パーティショニング
パーティショニングとは、1つのテーブルのデータの格納方法をユーザーが決めた単位で分割する処理の事です。
TiDBの場合、強制的に指定のパーティションに分割することによってテーブルに対するI/Oを分散し、TiKVのリソースを効率よく活用することを目指しました。
TiDBでは行の保管の単位としてリージョンを利用しているので、パーティションが分かれるということがリージョンが分かれることにつながります。
パーティションとリージョンは1:1でなく1:Nで対応しており、パーティションがリージョンの最大サイズより大きければ、複数のリージョンにまたがって保管されることもあります。
今回のINSERT先のテーブルは、PKが複合キーなのでKEYパーティションを利用しました。
具体的には以下のようにパーティショニングを行ったテーブルを用意し、INSERT処理を実行しました。
今回の検証では、TiKVのノード数に合わせてパーティションの数を12に設定しました。
CREATE TABLE `keywords_partition` (
`e_type` smallint(6) NOT NULL,
`e_id` int(11) NOT NULL,
`s_type` smallint(6) NOT NULL,
`r_id` int(11) NOT NULL,
`d_order` int(11) NOT NULL,
`p_count` smallint(6) NOT NULL,
`p_display_order` int(11) DEFAULT NULL,
PRIMARY KEY (`e_type`,`e_id`,`s_type`,`r_id`) ,
KEY `idx_keywords_p_by_display_order` (`e_type`,`e_id`,`s_type`,`d_order`,`r_id`),
KEY `idx_keywords_p_by_photo_display_order` (`e_type`,`e_id`,`s_type`,`p_display_order`,`r_id`,`p_count`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COLLATE=utf8mb4_bin
PARTITION BY KEY (`e_type`,`e_id`,`s_type`,`r_id`) PARTITIONS 12;
解決方法2:プレスプリットリージョン(PRE_SPLIT_REGIONS)の設定により、事前にリージョンを分割する
TiDBでは、新しいテーブルが作成されると、デフォルトで1つのリージョンが割り当てられます。このリージョンのサイズが制限を超えると、リージョンは自動的に分割されます。しかし、初期状態で1つのリージョンにすべての書き込みリクエストが集中すると、ホットスポットが発生する可能性があります。これを防ぐために、プレスプリット機能が導入されています。
プレスプリットを使用することで、テーブル作成時にリージョンを事前に分割し、各TiKVノードに分散させることができます。これにより、書き込みリクエストが均等に分散され、パフォーマンスを向上させることでTiKVのリソースを効率よく活用することを目指しました。
具体的には以下のようにプレスプリットリージョンの設定を行ったテーブルを用意し、INSERT処理を実行しました。
今回の検証では、SHARD_ROW_ID_BITS, PRE_SPLIT_REGIONをそれぞれ4に設定しました。SHARD_ROW_ID_BITS, PRE_SPLIT_REGIONは2の乗数で、4だと16リージョン(2^4) に分割されます。さらにインデックスデータ用に1つのリージョンが追加されます。
set @@global.tidb_scatter_region = on; -- 分割されるまでCREATE TABLEを待つ
CREATE TABLE `keywords_pre_split_regions` (
`e_type` smallint(6) NOT NULL,
`e_id` int(11) NOT NULL,
`s_type` smallint(6) NOT NULL,
`r_id` int(11) NOT NULL,
`d_order` int(11) NOT NULL,
`p_count` smallint(6) NOT NULL,
`p_display_order` int(11) DEFAULT NULL,
PRIMARY KEY (`e_type`,`e_id`,`s_type`,`r_id`) NONCLUSTERED,
KEY `idx_keywords_psr_by_display_order` (`e_type`,`e_id`,`s_type`,`d_order`,`r_id`),
KEY `idx_keywords_psr_by_photo_display_order` (`e_type`,`e_id`,`s_type`,`p_display_order`,`r_id`,`p_count`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4;
ALTER TABLE keywords_pre_split_regions ATTRIBUTES 'merge_option=deny'; -- REGIONマージを禁止する
結果と考察
パーティショニングとプレスプリットリージョンそれぞれ実施したテーブルにおいて、INSERT処理を実施したところ以下の結果となりました。
今回の検証は、パーティショニングとプレスプリットリージョンのそれぞれ一方だけの設定で計測しており、2つの設定を組合せての計測は実施しておりません。
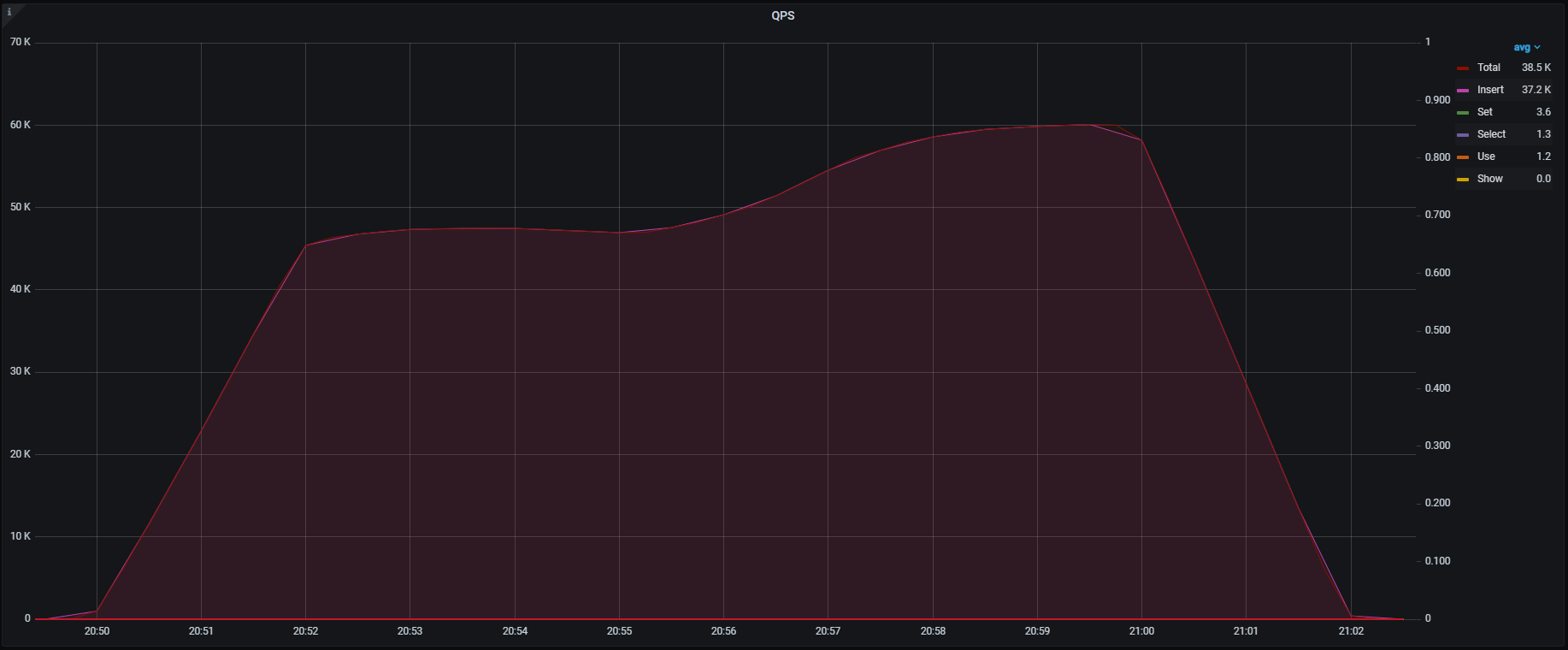
パーティショニングテーブルに対するINSERT結果
QPS
TiDB CPU負荷
TiKV CPU負荷
上記結果について
- QPSが60,000QPS以上になり目標としていた50,000QPSは達成
- TiKVの負荷がもともとは1ノードに集中していたものが複数ノードに分散され、理想的なリソースの使われ方をしている
- クエリ処理数の増加に伴い、TiDBのCPU負荷も全体的に上がっている
プレスプリットリージョン(PRE_SPLIT_REGIONS)テーブルに対するINSERT結果
QPS
TiDB CPU負荷
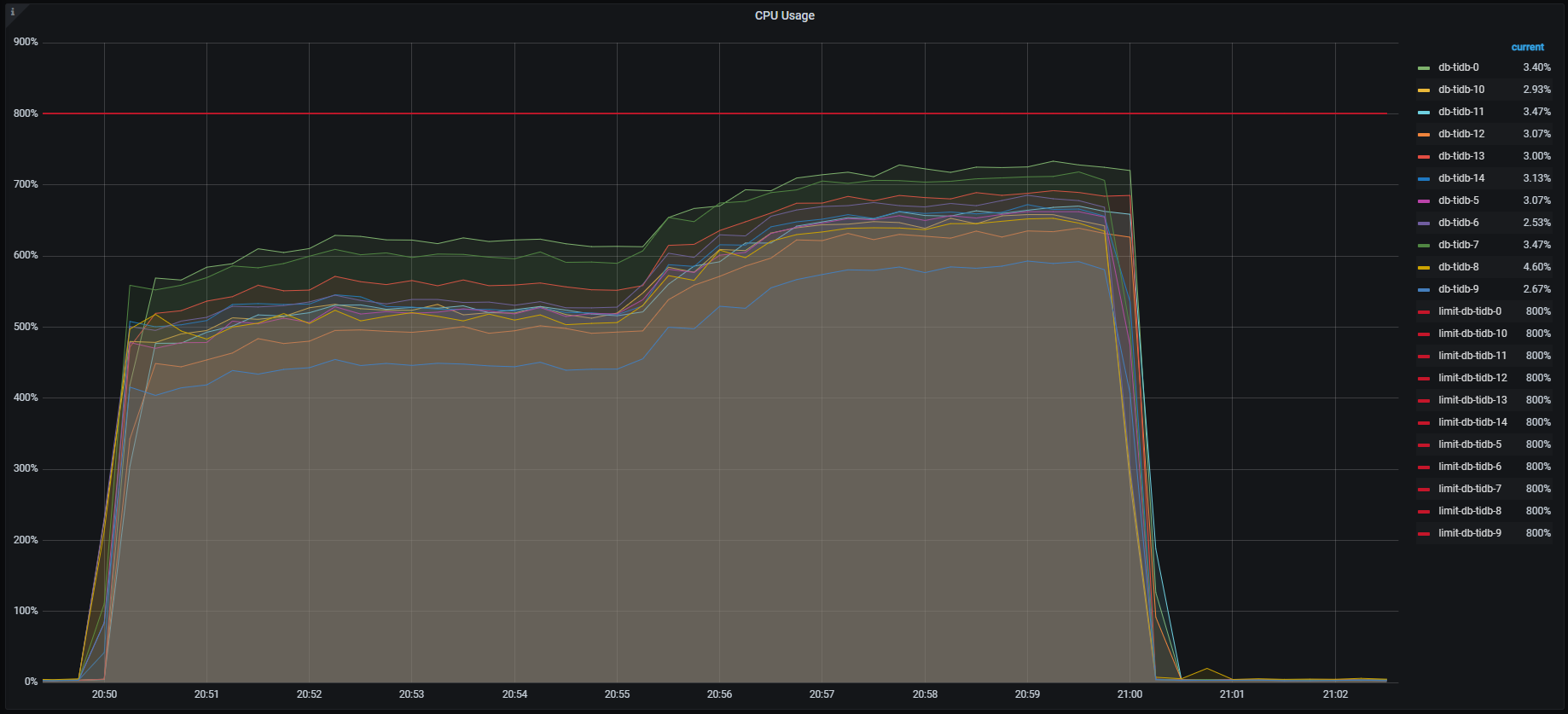
TiKV CPU負荷
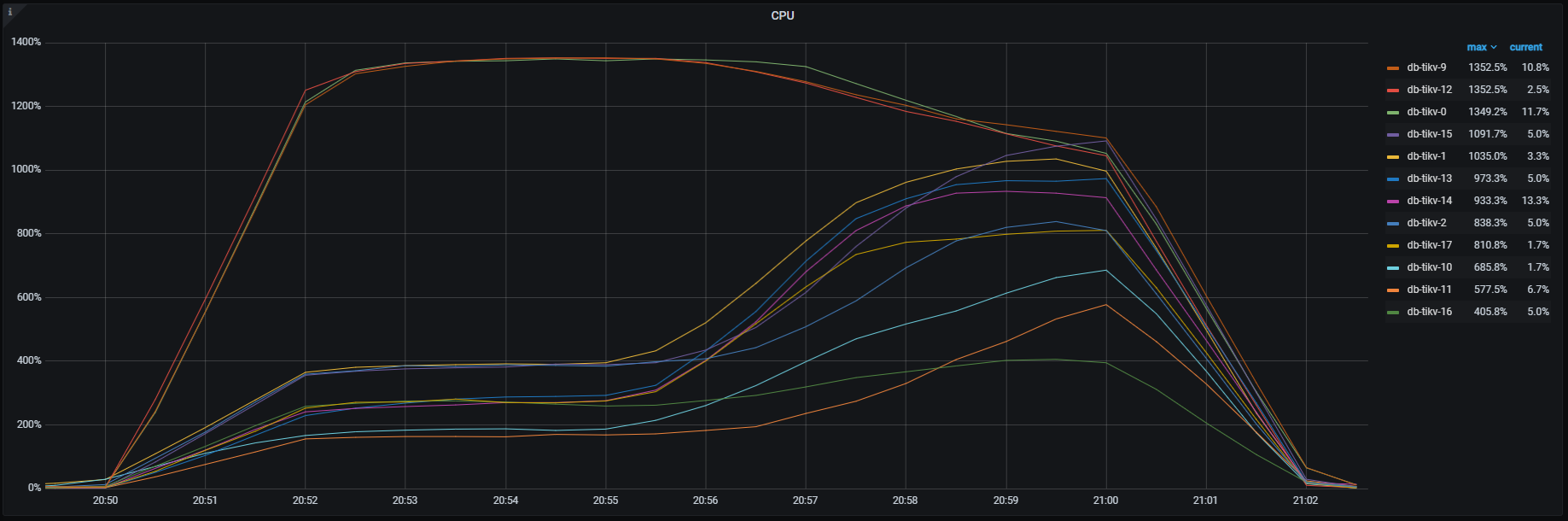
上記結果について
- 最終的なQPSが約60,000QPSになり目標としていた50,000QPSは達成
- TiKVの負荷が最初は数ノードに集中していたが、最終的に複数ノードに分散され、理想的なリソースの使われ方をしている
プレスプリットリージョン(PRE_SPLIT_REGIONS)の設定でもこのような偏りが発生するのはバージョン依存のもののようで、v8.4では改善が図られているとのことでした。
※後でPingCAPさんから教えてもらいました
- クエリ処理数の増加に伴い、TiDBのCPU負荷も全体的に上がっている
結果に対する考察
上記の結果より、TiDB CloudにおけるINSERTのパフォーマンス向上においては、パーティショニングとプレスプリットリージョン(PRE_SPLIT_REGIONS)の設定が効果的であると分かりました。
パーティショニングとプレスプリットリージョン(PRE_SPLIT_REGIONS)はいずれもリージョンを分散させる効果がある設定ですが、目的や機能には違いがあるため用途に合わせて適した方を選ぶ必要はあります。
特に対象のテーブルに対するクエリや処理の性質によってどのような物理設計をすべきか検討する必要があります。
例えば、リージョンが分割されていなければ一回のアクセスで済む処理が、リージョンが分割されていた場合複数に分割してアクセスしなければならず性能が劣る可能性はあります。
ただ、単一のクエリであればTiDBはマルチスレッドなのでTiKVへのリクエストを並行に投げることは可能です。
しかし、上記のクエリが複数同時実行された場合などを考慮すると実際に検証してみないと判断できません。
また、パーティションを行った行がWHEREに含まれる場合には、該当パーティションしか読まなくてよいとオプティマイザが判断できるため、パーティションの方が早くなることもあります。
今回は移行前の検証として、INSERTのパフォーマンスを上げるためだけを考えて物理設計を行いましたが、実際に移行を進める際には関係するアプリケーションエンジニアと密接に協力しながらアプリケーションの仕様を把握したうえでどういった設計が適しているか判別していく必要があると考えています。
さいごに
今回のパフォーマンス検証では、このINSERTの件以外にもいくつか検討しなければならない事項がありましたが、一緒に検証に取り組んだメンバーに恵まれて困難を乗り越えることができました。
また、PingCAPさんの手厚いサポートもあり、疑問点はすぐに解消することができました。
RDBMS(SQL Server)からNewSQLであるTiDBに移行を検討する際は、それぞれの特性の違いを理解し、TiDBのアーキテクチャを把握したうえで必要に応じて最適なチューニングを行う必要があることが分かりました。
同じように移行を検討している方にとって少しでも参考になれば幸いです。