PDF を HTML に正確に変換できる BuildVu と、クラウド検索サービスである Azure Search を組み合わせることで、大量の PDF からドキュメントデータベースを構築し、高速な検索と閲覧を可能にするドキュメント検索システムを構築する事ができます。
PDF を HTML へ変換できる BuildVu についての詳細はこちらをご覧ください。
本稿では BuildVu で PDF から HTML へ変換されたドキュメントを Azure Search で検索できるようにする際に、必要となるであろう情報を提供します。
Azure Search に限らず、Elasticsearch や他の全文検索エンジンにも、有用な情報が含まれているので参考にしてください。
前提条件
- Azure ポータル上で Azure Search サービスを作成済みである。
- Azure Search をコントロールするためのアプリケーション・サーバーを構築済みである。
- BuildVu によって生成された HTML はウェブに公開されている状態である。
BuildVu より出力されたファイルから、必要な情報を取得する
出力されたファイルから、インデックスを作成する際に利用できる情報が取得できます。
例えば、2 ページの PDF を BuildVu で HTML へ変換すると以下のようなファイル構成で出力されます。
([ ]はフォルダです)
- [出力フォルダ]
- [1]
- [2]
- [assets]
- [fonts]
- [thumbnails]
- 1.svg
- 2.svg
- annotations.json
- config.js
- index.html
- search.json
これらのファイルから、以下のような情報を取得できます。
- thumbnails フォルダからはサムネイルの画像
- annotations.json からは注釈に関する情報
- config.js からはドキュメントタイトルや総ページ数などの情報
- search.json からはドキュメント内のテキストデータ
以下で、それぞれを詳しく解説します。
thumbnails フォルダ
このフォルダの中に、サムネイル画像が
[ ページ番号 ].jpg
という具合に配置されています。
検索結果にサムネイル画像を掲載したい場合に、利用することができます。
annotations.json
PDF に注釈が含まれている場合は、その情報が annotations.json に記述されています。
注釈の内容も検索対象としたい場合は、この JSON ファイルを解析して、Azure Search のドキュメントに含めます。
annotations.json は、以下のようなフォーマットで記述されています。
(読みやすくするため整形しています)
{"pages":[
{"page":1,"annotations":[
{"type":"Text","bounds":[423,365,37,37],"objref":"39","contents":"これは注釈です。","title":"TM-MBP1","appearance":"1/annots/39.png"},
{"type":"Highlight","bounds":[219,536,588,57],"objref":"41","title":"TM-MBP1","appearance":"1/annots/41.png"}
]}
]}
例えば、1 ページ目の 1 つ目の注釈の文字列を取得するには、以下のようになります。
// annotations.json の内容が annots に読み込まれているものとします。
var text = annots.pages[0].annotations[0].contents;
なお、注釈以外に、ハイライトの情報も含まれている点に注意してください。
contents へアクセスする前に、type を確認すると良いでしょう。
config.js
config.js には PDF ドキュメントに関する多くの情報が含まれています。
ただし、このファイルは IDRViewer が利用することを想定しているため、js ファイルである点に注意してください。
以下のようなフォーマットで記述されています。
IDRViewer.config = {"pagecount":5,"title":"ドキュメントタイトル","author":"作者","fileName":"ファイル名.pdf","bounds":[[909,1286]],"bookmarks":[{"title":"しおり1","page":1,"zoom":"Fit"},{"title":"しおり2","page":2,"zoom":"Fit","children":[{"title":"しおり2-1","page":3,"zoom":"Fit"},{"title":"しおり2-2","page":4,"zoom":"Fit"},]}],"thumbnailType":"jpg","pageType":"html","pageLabels":[]};
アプリケーションで利用する際には、内容を取得後に
IDRViewer.config =
を削除して、JSON として処理することも可能です。
JSON として処理した後、PDF ドキュメントのタイトルを取得する例。
// config.js の内容が JSON として config に読み込まれているものとします。
var docTtl = config.title;
PDF のしおりの情報を取得することもできます。
2 つ目のしおりのタイトルとページ番号を取得する例。
// config.js の内容が JSON として config に読み込まれているものとします。
var bms = config.bookmarks;
var ttl = bms[1].title;
var pg = bms[1].page;
Azure Search のドキュメントに、これらの情報を利用することで、検索結果をより分かりやすいものにすることができます。
search.json
PDF ドキュメント内のテキストデータが以下のようなフォーマットで含まれています。
["これは1 ページ目のテキストデータです","2 ページ目のテキストデータ","3ページ目"]
2 ページ目のテキストデータを取得するには以下のようにアクセスします。
// search.json の内容が search に読み込まれているものとします。
var text = search[1];
Azure Search に作成するインデックスの例
Azure ポータルで Azure Search インデックスを作成する手順と、BuildVu から得た情報を格納するフィールドの設定例をご紹介します。
ここでは、変換された PDF をページ単位で、Azure Search にドキュメントとして登録することを想定して作成します。
まず、作成した Azure Search サービスを選択し、「インデックスの追加」ボタンを押します。
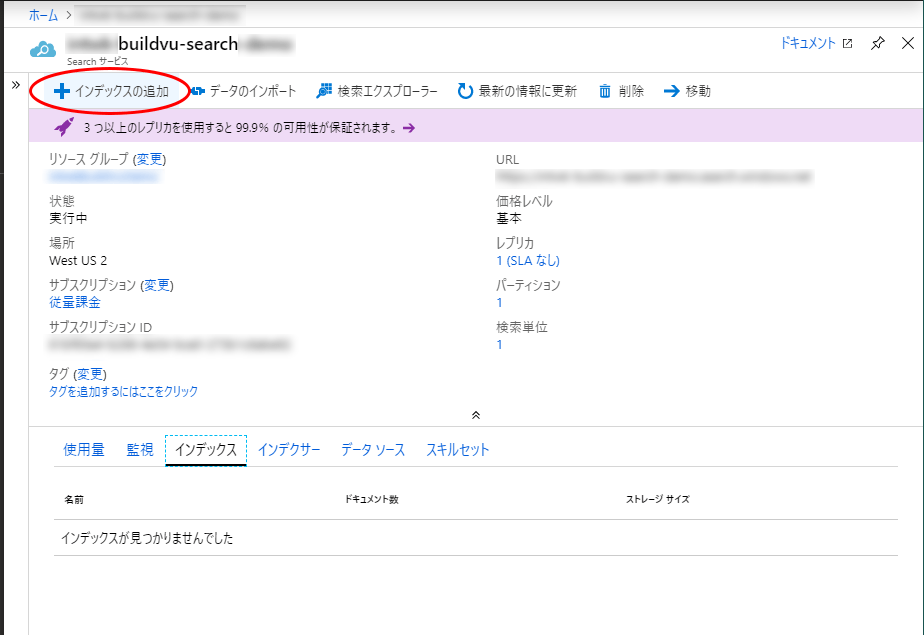
「インデックスの追加」画面では、インデックス名やキーとなるフィールドの設定、値を格納するフィールドの追加を行います。
ここではインデックス名を「buildvu-search」としています。
キーでは、各ドキュメントの一意の値を格納するフィールドを指定します。
予め、id というフィールドが用意されており、既にそれが選択された状態になっています。
新たにフィールドを追加した後で、キーとなるフィールドを変更することもできます。
ただし、キーとなるフィールドの型は String 、取得可能は ON である必要があります。
インデックス名とキーの設定は、作成後に変更できない点に留意してください。

続いて、「フィールドの追加」ボタンを押して、フィールドを追加していきます。
それぞれ、フィールド名と型を指定し、取得可能などの属性をチェックボックスで設定することができます。
各属性を ON にした場合の効果は以下のとおりです。
- 取得可能 ⇒ 検索結果に値が含まれるようになります。
- フィルター可能 ⇒ 完全一致の
$filterクエリでフィールドを参照できるようになります。 - ソート可能 ⇒ この値でソートできるようになります。
- ファセット可能 ⇒ あるカテゴリの値を格納することで、そのカテゴリに属するドキュメントの数が得られるようになります。
- 検索可能 ⇒ 全文検索の対象とします。
- アナライザー ⇒ 検索可能な場合、どのアルゴリズムを利用して形態素解析を行うかを指定します。
ここでは以下のようにフィールドを追加しました。
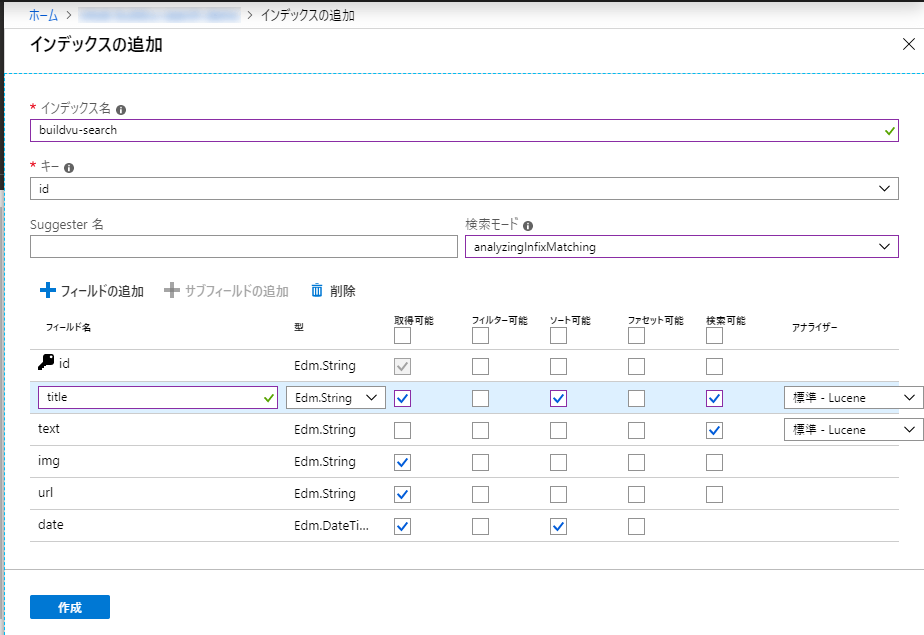
id フィールド
Key となる一意の値を格納するためのフィールドです。
title フィールド
ドキュメントタイトルを格納するフィールドです。
ページ単位なので、実際にはタイトルに加え、何ページ目なのかも含むと、検索結果がより分かりやすくなります。
ここで利用できる情報は config.js に含まれています。
アナライザーは「標準-Lucene」としていますが、用途に応じて「日本語-Lucene」や「日本語-Microsoft」などを選択しても良いでしょう。
text フィールド
ページのテキストデータを格納するフィールドです。
多くの場合、データ量が大きいため取得可能にはしません。
(取得可能でなくても、ヒットしたテキストは別途取得できます)
ここで利用できる情報は search.json に含まれています。
アナライザーは「標準-Lucene」としていますが、用途に応じて「日本語-Lucene」や「日本語-Microsoft」などを選択しても良いでしょう。
img フィールド
thumbnails フォルダに格納されている、サムネイルへのパスを格納します。
検索結果にサムネイルを掲載することで、視覚的に探しやすくなります。
url フィールド
実際のドキュメントへの URL を格納します。
IDRViewer で表示したい場合は、予め以下のように編集しておくと良いでしょう。
https://sample.com/document01/1.html
↓
https://sample.com/document01/?page=1
date フィールド
ドキュメントが作成された日時を格納するためのフィールドです。
毎年同名で追加されるドキュメントなどがある場合に有用です。
型は DateTimeOffset を指定しています。
以上のようなインデックスを作成し、REST API などでドキュメントの追加、検索などを行えるアプリケーションを、構築していくことになります。