はじめに
ソフトウェアの品質問題は悩みの種です。
脆弱性の検知にCPEを利用するのが一般的ですが問題点も多々あります。
- 製品ごとに表記揺れが激しい
- 必ずしもすべての製品にCPEが発行されるわけではない
- 一つの製品に対して複数のCPEが発行されていることがある
- CPEが変更されてしまうことがある
などなど。
特にパッケージエコシステムも利用されていないようなレガシーなシステムなどでは正確なCPEを求めることが難しいため、脆弱性とのマッチング精度に絶望します。
各種脆弱性検出ツールでは様々な対策が行われていますが、今回はLLMを使ってCPEを求めてみようと思います。
作成物
目標
- 入力例:
Visual Studio Code 0.2.9 - 出力例:
cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
戦略
LLMのチューニングにはいくつかの手法があるので検討していきます。
- LoRA
- メモリ効率が良く事前学習済みモデルを維持しながら特定のタスクに適応できる
- 新しい知識の学習には向かない
- RAG
- 外部データを自由に追加可能
- 外部データの管理が不適切だと逆に誤情報が増える
脆弱性情報は日々更新されるのでLoRAではダメそうです。
でも今回は学習もかねて LoRA+RAG の両方で行ってみようと思います。
学習データの用意
学習データは go-cpe-dictionary を使って用意します。
$ go-cpe-dictionary fetch nvd
$ go-cpe-dictionary fetch jvn
取得できた cpe.sqlite3 の categorized_cpes テーブルを覗いて中身を確認してみます。
| id | fetch_type | title | cpe_uri | cpe_fs | part | vendor | product | version | update | edition | language | software_edition | target_software | target_hardware | other | deprecated |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 191056 | nvd | Microsoft Visual Studio Code 0.2.9 | cpe:/a:microsoft:visual_studio_code:0.2.9 | cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:* | a | microsoft | visual_studio_code | 0\.2\.9 | ANY | ANY | ANY | ANY | ANY | ANY | ANY | 0 |
| $\hspace{140em}$ | ||||||||||||||||
どうやら title が一般的な製品の名称のようです。
title から cpe_fs を求められれば良さそうです。
今回は必要最小限の title, part, vendor, product, version を学習データとします。
試しにアプリケーションのみに絞ってランダムに15万件をCSVで抽出してみます。
$ python create_dataset.py
LoRAによるファインチューニング
モデルは多言語対応している Qwen/Qwen2.5-1.5B-Instruct を使ってみます。渡される製品名に日本語が含まれる可能性は普通にありそうです。
次にチャットテンプレートを考えます。
レスポンスを構造体にパース出来たほうが後で扱いやすそうです。
勉強もかねて langchain.output_parsers.StructuredOutputParser の利用を前提にプロンプトを組んでみます。
DEFAULT_SYSTEM_PROMPT = """
Generate a JSON from the given text.
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"part": string // May have 1 of 3 values. a for Applications. h for Hardware. o for Operating Systems.
"vendor": string // Values for this attribute SHOULD describe or identify the person or organization that manufactured or created the product.
"product": string // The name of the system/package/component. product and vendor are sometimes identical.
"version": string // The version of the system/package/component.
}
```"""
content = f"""```json
{{
"part": "{part}",
"vendor": "{vendor}",
"product": "{product}",
"version": "{version}"
}}
```"""
chat_template = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": title},
{"role": "assistant", "content": content},
]
さっそく学習していきます。
$ python train.py
学習の確認
15万件学習したところ1時間30分ほどかかりました。
バッチサイズが 6*18 で総ステップ数は 1388 です。
tensorboad でログを確認してみます。
$ tensorboard --logdir=logs
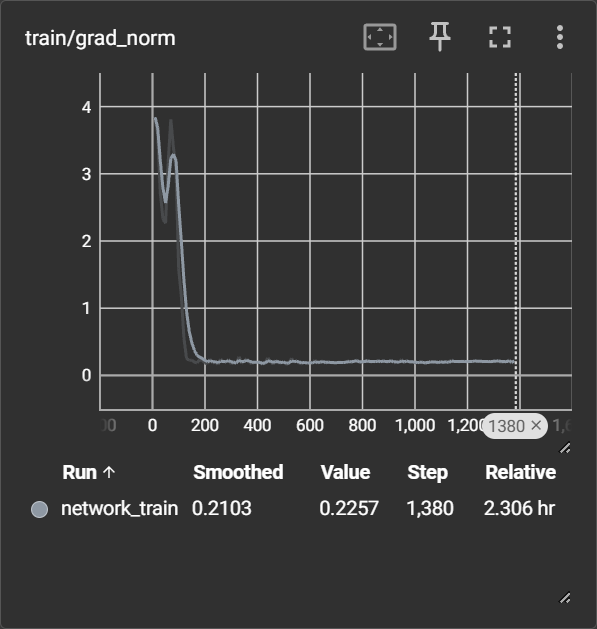
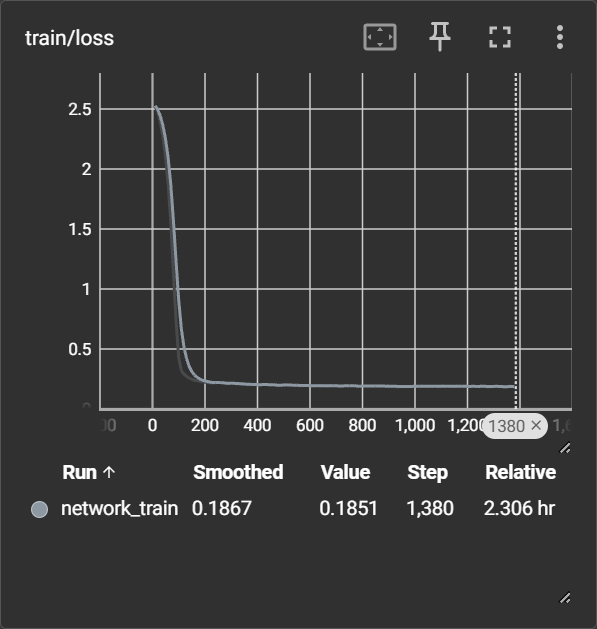
どうやらlossはステップ 1000 あたりで落ち切っているようです。
以降 0.18 ~ 0.19 あたりをうろうろしています。
LoRAを使用してCPEを生成してみる
LLMと先ほど学習したLoRAを読み込みます。
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-1.5B-Instruct",
device_map=device,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
peft_model = PeftModel.from_pretrained(model, get_last_checkpoint(lora_path)).to(device)
出力を構造体にパースしたいので langchain.output_parsers.StructuredOutputParser を使用します。
OutputParser を使ってテンプレートに出力フォーマットの指定を埋め込みます。
output_parser = StructuredOutputParser.from_response_schemas([
ResponseSchema(name="part", description="May have 1 of 3 values. a for Applications. h for Hardware. o for Operating Systems."),
ResponseSchema(name="vendor", description="Values for this attribute SHOULD describe or identify the person or organization that manufactured or created the product."),
ResponseSchema(name="product", description="The name of the system/package/component. product and vendor are sometimes identical."),
ResponseSchema(name="version", description="The version of the system/package/component."),
])
format_instructions = output_parser.get_format_instructions()
prompt_template = PromptTemplate(
template=(
"Generate a JSON from the given text.\n"
"{format_instructions}\n\n"
),
input_variables=[],
partial_variables={"format_instructions": format_instructions}
)
chat_template = tokenizer.apply_chat_template(
[
{"role": "system", "content": prompt_template.format()},
{"role": "user", "content": query}
],
tokenize=False,
add_generation_prompt=True
)
アウトプットを整形してCPE2.3を出力してみます。
学習データに含まれていないCPEの update 以降の情報は * で固定してしまいます。
model_inputs = tokenizer([chat_template], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128,
num_return_sequences= 10,
do_sample=True,
temperature=1.3,
)
generated_ids = [
output_ids[len(model_inputs.input_ids[0]):] for output_ids in generated_ids
]
responses = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f"Input: {query}")
print("Output:")
for idx, response in enumerate(responses):
try:
result = output_parser.parse(response)
part = result["part"]
vendor = result["vendor"]
product = result["product"]
version = result["version"]
print(f"#{idx}: cpe:2.3:{part}:{vendor}:{product}:{'*' if version=='' or version=='ANY' else version}:*:*:*:*:*:*:*")
except Exception as e:
print(f"#{idx}: {response}")
print(e)
Visual Studio Code 0.2.9 を渡して生成してみます。
$ generate.py
Input: Visual Studio Code 0.2.9
Output:
#0: cpe:2.3:a:ms-vim:vscode:0.2.9:*:*:*:*:*:*:*
#1: cpe:2.3:a:ms:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#2: cpe:2.3:a:ms:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#3: cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#4: cpe:2.3:a:ms-visualstudio-code:code:0.2.9:*:*:*:*:*:*:*
#5: cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#6: cpe:2.3:a:ms:visualstudio_code:0.2.9:*:*:*:*:*:*:*
#7: cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#8: cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
#9: cpe:2.3:a:microsoft:visual_studio_code:0.2.9:*:*:*:*:*:*:*
Process finished with exit code 0
間違ったCPEもありますが正しいもの求められています。
Visual Studio から microsoft がちゃんと推論出来ていますね。
ただこれだとあまり精度が高いとも言えず誤検出も怖いです。
まとめ
LoRAによるファインチューニングだけでもそれらしいCPEを得ることができました。
しかし、脆弱性情報は日々更新されるものです。
やはりRAGを用いて外部データを参照できたほうが良さそうです。
次は今回作成したコードをRAGを用いた形に修正してみようと思います。