概要
最近よく「決定木よりLightGBMの方が性能が良い」と聞きますが、
実際どれくらい性能に差があるのか、自分で確かめてみることにしました。
サンプルデータ
sample_car_data.csv (N=400)

| ID | 説明 | 種別 |
|---|---|---|
customer_id |
ユニークID | - |
family |
同居家族 | 説明変数 |
age |
年齢(18~70歳) | 説明変数 |
gender |
性別(男性=0, 女性=1) | 説明変数 |
income |
世帯収入(万円単位) | 説明変数 |
marital_status |
配偶者の有無(0=未婚, 1=既婚) | 説明変数 |
children |
子供の人数 | 説明変数 |
region |
居住地(都市=0, 郊外=1, 地方=2) | 説明変数 |
employment_type |
雇用形態(正社員=0, 自営業=1, パート=2) | 説明変数 |
hobby |
趣味(0=アウトドア, 1=読書, 2=旅行, 3=スポーツ, 4=映画) | 説明変数 |
car_preference |
欲しい車のボディタイプ(0=SUV, 1=セダン, 2=ミニバン, 3=ハッチバック) | 説明変数 |
previous_car_owner |
過去に車を保有していたか(0=なし, 1=あり) | 説明変数 |
previous_manufacturer |
過去の車メーカー(0=トヨタ, 1=ホンダ, 2=日産, 3=スズキ, 4=ダイハツ, 5=マツダ, 6=その他, 99=保有なし) | 説明変数 |
manufacturer |
現在保有している車のメーカー(0=トヨタ, 1=ホンダ, 2=日産, 3=スズキ, 4=ダイハツ, 5=マツダ, 6=その他) | 目的変数 |
補足
previous_manufacturer = 99(保有なし)について :
LightGBMの場合はNaNのままでもモデルが自動的に処理できますが、決定木はNaNを扱えないため、previous_car_owner = 0 の場合は previous_manufacturer = 99(保有なし) に置き換えています。
今回はモデルを比較するため、同じデータを使用しています。
環境
python3.x
jupyter lab
モデル構築と評価指標
・DecisionTreeとLightGBMで分類
・評価指標はAccuracyとF1スコアを使用
Accuracy(正解率)
全体のデータの中で、モデルが正しく予測できた割合のことです。
例えば、100件中72件正しく予測できればAccuracyは0.72(72%)となります。
F1スコア
モデルが予測した結果の中で、どれだけ正しく当てられたか(正解率)と、実際の正解をどれだけ漏らさず見つけられたか(再現率)を両方バランスよく評価する指標です。
特に、正解データの数に偏りがある場合(例えば「はい」と「いいえ」の数が大きく違う場合)に、Accuracyだけだと誤解が生まれやすいので、F1スコアでバランスを見ます。
コード
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, ConfusionMatrixDisplay, f1_score
from sklearn.tree import DecisionTreeClassifier, plot_tree
import lightgbm as lgb
📚サンプルデータを読み込む
#=============================================
# データ読み込む
#=============================================
CSVファイル(sample_car_data.csv)をShift-JISエンコードで読み込みます。
df_moto = pd.read_csv("sample_car_data.csv", encoding='shift-JIS')
# データの先頭3行を表示して、読み込み結果を確認します
df_moto.head(3)

日本語データを扱う際はエンコーディングに注意しましょう。
📚型の変換
#=============================================
# カテゴリ列のデータをカテゴリ型に変換する
#=============================================
# 数値として扱いたい列(連続値など)
numeric_cols = ["family", "age","children", "income"]
# IDや目的変数は変換対象から除外
exclude_cols = ["customer_id", "manufacturer"]
# 変換対象のカテゴリ列を抽出
categorical_cols = [
col for col in df_moto.columns
if col not in exclude_cols + numeric_cols
]
# カテゴリ型にする
df_moto[categorical_cols] = df_moto[categorical_cols].astype("category")
・astype("category") → カテゴリ型(category)に変換
メモリ使用量が減り、LightGBMなどの一部のモデルでは処理速度や精度の向上に繋がります。
数値として扱うべき列を誤ってカテゴリ型に変換しないために、あらかじめ数値として扱いたい列(numeric_cols)や、ID・目的変数(exclude_cols)を除外し、それ以外の列をカテゴリ型に変換しています。
📚説明変数、目的変数を設定
#=============================================
# 説明変数(特徴量)を設定
#=============================================
# 顧客IDと目的変数の「manufacturer」は除外
X_df = df_moto.drop(['customer_id', 'manufacturer'], axis=1)
#=============================================
# 目的変数を設定
#=============================================
y_df = df_moto['manufacturer']
# クラス数(カテゴリーの種類)を確認
classes = np.unique(y_df)
print("クラス:", classes)
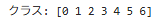
・説明変数(特徴量) → モデルに入力するデータ。ここではcustomer_idやmanufacturer(目的変数)は除外しています。
・目的変数 → 予測したい値で、この例ではmanufacturerがそれにあたります。
・np.unique() → 目的変数のユニークなクラス(カテゴリ)を取得し、分類問題のクラス数を確認しています。
📚訓練データとテストデータに分割
#=============================================
# データ分割
#=============================================
# 説明変数(X_df)と目的変数(y_df)を訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X_df, y_df, random_state=0)
print("訓練データ数:", len(X_train))
print("テストデータ数:", len(X_test))

・train_test_split → モデルの学習に使うデータ(訓練データ)と評価に使うデータ(テストデータ)を分けるための関数。
・random_state → 固定することで、実行するたびに同じ分割結果を得られます。
・len(X_train)/len(X_test) → 分割後のデータ数を表示して、きちんと分割されているかを確認。
📚scikit-learnで決定木モデルを作成
#=============================================
# 決定木モデルの作成・学習
#=============================================
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# テストデータに対する予測
y_pred_dt = dt_model.predict(X_test)
・DecisionTreeClassifier
→ データから分類ルールを学習し、分類用の決定木を構築するための「箱」。
・max_depth=5
→ 決定木の深さ(分割の最大階層数)を5に制限。深すぎると過学習になることがあるので調整が重要。
・random_state
→ 乱数のシード値を指定し、結果の再現性を担保す。プログラミング界隈で「42」はよく使われる定番のシード値で、特に意味なし。
・predict → 学習済みモデルを使って、テストデータのクラス(カテゴリ)を予測。
📚scikit-learnで決定木可視化
#=============================================
# 決定木の可視化 (scikit-learn)
#=============================================
plt.figure(figsize=(20, 10))
plot_tree(dt_model, filled=True, feature_names=X_df.columns)
plt.title("scikit-learn Decision Tree")
plt.savefig("比較用_Tree.png", dpi=300)
plt.show()
・dt_model → scikit-learnで学習した決定木モデルを指定。
・filled=True → ノードをクラスごとに色分けして見やすく。
・feature_names → 特徴量名を渡すと、分割条件に実際の列名表示。指定しないとX[0]やX[1]のように数字で表示される。
・plt.figure(figsize=(20, 10)) → 描画する図のサイズを横20インチ×縦10インチに指定。
・plot_tree → 学習済みの決定木を可視化する関数。filled=Trueを指定すると、ノードがクラスごとに色分けされ、特徴量名も表示される。

plot_treeはscikit-learnの機能なので基本的に追加インストール不要ですが、
上の図はGraphvizを使っているため、必要に応じてインストールしてください。
📚 LightGBMによる決定木の学習・予測
#=============================================
# LightGBM:目的に応じて設定
#=============================================
if len(classes) == 2:
objective = 'binary'
metric = 'binary_error'
else:
objective = 'multiclass'
metric = 'multi_error'
params = {
'objective': objective,
'metric': metric,
'verbose': -1,
}
if objective == 'multiclass':
params['num_class'] = len(classes)
・if len(classes) == 2 → クラス数が2なら二値分類(バイナリ分類)として扱う。
・objective = 'binary'
→ LightGBMの目的関数(損失関数)を「binary」(2クラス分類用)に指定。
→ これにより、モデルは2クラス分類用のロジスティック回帰的な処理を行う。
・metric = 'binary_error'
→ 訓練時や検証時の評価指標として「誤分類率(二値分類)」を使う。
→ 精度を測る評価方法の一つ。
else:(つまり、クラスが3つ以上なら)
・objective = 'multiclass'
→ LightGBMの目的を「多クラス分類」に指定。内部的には softmax を使った分類。
・metric = 'multi_error' → 多クラス分類の誤差率を計算する評価指標。
・params['num_class']
→ 多クラス分類の場合はクラス数を明示的に指定しないとエラーになる。
#=============================================
# LightGBM用データセットを作成(特徴量名を指定)
#=============================================
lgb_train = lgb.Dataset(
X_train.values,
label=y_train.values,
feature_name=X_df.columns.tolist()
)
# モデル学習(50回のブースティング)
lgb_model = lgb.train(params, lgb_train, num_boost_round=50)
#=============================================
# テストデータで予測
#=============================================
y_pred_lgb_prob = lgb_model.predict(X_test.values)
# クラス予測(確率→ラベル)
if objective == 'binary':
y_pred_lgb = (y_pred_lgb_prob > 0.5).astype(int)
else:
y_pred_lgb = np.argmax(y_pred_lgb_prob, axis=1)
・lgb.Dataset(...) → LightGBM 専用のデータ構造に変換
・X_train.values → NumPy配列に変換した訓練データの特徴量。
・label=y_train.values → 目的変数(正解ラベル)。
・feature_name
→ 特徴量名を明示的に渡すことで、可視化や特徴量重要度の出力時に列名がそのまま使われる。
→ 渡さないと「feature_0, feature_1,…」のように自動生成されるので注意
・X_df.columns.tolist() → 元の特徴量名をリストで渡す。
・predict()
→ 出力はクラスごとの確率なので、2値分類と多クラス分類で後処理を分ける必要がある。
2値分類(binary classification):
出力が分岐して「Yes / No」のように2つのクラスに分かれる分類問題のこと。
多クラス分類(multi-class classification)とは、:
出力が3つ以上のカテゴリに分類される問題です。たとえば「トヨタ / ホンダ / 日産」のようなパターン。
📚 LightGBMによる決定木可視化
#=============================================
# LightGBMの木の構造 (特徴量名表示)
#=============================================
ax = lgb.plot_tree(
lgb_model,
tree_index=0, # 表示する木の番号(0番目の木)
figsize=(20, 10), # 図のサイズ指定
show_info=['split_gain', 'internal_value', 'leaf_count']
)
plt.title("LightGBM Tree #0")
plt.savefig("LightGBM_Tree.png", dpi=300)
plt.show()
・lgb_model → 学習済みのLightGBMモデルオブジェクトを指定。
・tree_index=0 → 決定木の中で何番目の木を表示するか指定。0は最初の木。
・figsize=(20, 10) → 描画される図のサイズ(幅×高さ、単位はインチ)を指定。
・show_info →
- split_gain :分割による利得(重要度)
- internal_value :ノードの値(例:予測値の平均など)
- leaf_count :そのノードに属するデータ数
・plot_tree → 指定した木(tree_index=0)の構造を可視化する関数。

決定木とLightGBMの木の解説
決定木とLightGBMの木の構造は見た目も性質もかなり違いますね。
それは、それぞれのモデルが木の作り方や使い方に違いがあるためです。
決定木は1本の木だけで分類を行いますが、LightGBMはたくさんの小さな決定木を順番に学習して、少しずつ予測を改善していきます。
この仕組みを「勾配ブースティング(Gradient Boosting)」と呼び、一般的に高い精度が期待できます。
モデルごとの特徴:
決定木
→ 1本の大きな木で分類する
→ レベル・ワイズ(depth-wise):全体を均等に枝分かれさせる
LightGBM
→ 何百本もの木を使い少しずつ改善
→ リーフ・ワイズ(leaf-wise):効果の大きい葉(リーフ)を優先して深掘りする
LightGBMの木は単独で予測するものではなく、複数の木を合わせて予測します。
そのため、1本の木だけを見て性能を判断するのは正しくありません。
今回は決定木との違いを理解するための可視化として、「こんな感じなんだ〜」くらいの気持ちで見てね。
📚 モデルの評価
#=============================================
# 精度評価
#=============================================
print("【DecisionTree】 Accuracy:", accuracy_score(y_test, y_pred_dt))
print("【DecisionTree】 F1 Score:", f1_score(y_test, y_pred_dt, average='weighted'))
print("【LightGBM】 Accuracy:", accuracy_score(y_test, y_pred_lgb))
print("【LightGBM】 F1 Score:", f1_score(y_test, y_pred_lgb, average='weighted'))
#=============================================
# 混同行列の表示
#=============================================
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
# 決定木の混同行列
ConfusionMatrixDisplay.from_predictions(y_test, y_pred_dt, ax=ax[0])
ax[0].set_title("Decision Tree Confusion Matrix")
# LightGBMの混同行列
ConfusionMatrixDisplay.from_predictions(y_test, y_pred_lgb, ax=ax[1])
ax[1].set_title("LightGBM Confusion Matrix")
plt.tight_layout()
plt.show()
・Accuracy(正解率) → 全体の予測のうち、正しく予測できた割合を示す。
・F1 Score → 精度(Precision)と再現率(Recall)の調和平均で、特にクラス不均衡がある場合に役立つ指標。
・混同行列 → 予測結果の詳細を表で示し、各クラスごとの正解・誤分類の傾向を把握できる。

🔍評価結果
【DecisionTree】 Accuracy: 0.72
【DecisionTree】 F1 Score: 0.719
【LightGBM】 Accuracy: 0.69
【LightGBM】 F1 Score: 0.69
えっ💦LightGBMのほうが精度が低い!!
改善に向けて試すべきこと
・ハイパーパラメータの調整
max_depth、learning_rate、num_leavesなどをチューニングしてみる。
・カテゴリ変数の扱いを工夫する
LightGBMはカテゴリ変数を直接扱えますが、One-Hotやターゲットエンコーディングなどを試すと結果が変わることも。
・データの分割方法・クロスバリデーションの導入
複数分割での評価で過学習やモデルの安定性をチェック。
・特徴量エンジニアリング
新たな特徴量の作成や不要な特徴量の削除を検討。
・欠損値(NaN)の扱いに注意
LightGBMは欠損値を内部処理可能なので、特定値で埋めるよりNaNのまま扱うか適切な補完を推奨。
(※欠損値対応の結果も最後に掲載)
混同行列の解説

X軸:モデルが予測したクラス(0〜6)
Y軸:実際の正しいクラス(0〜6)
X軸はモデルの予測したクラス、Y軸は実際のクラス(正解)を表しています。
対角線上の数字は、モデルが正しく分類した件数です。
例)
X軸=0, Y軸=0 の値=1:クラス0を正しく1件分類
X軸=6, Y軸=6 の値=12:クラス6を正しく12件分類
X軸=5, Y軸=6 の値=15:実際はクラス6なのに、モデルはクラス5と予測し、15件誤分類
🔍参考:欠損値対応の結果
サンプルデータのprevious_manufacturer = 99(保有なし)を
欠損値(NaN)で扱った場合のLightGBMの結果

残念ながら、今回のケースでは 決定木の方が精度で勝ちました。
まとめ
決定木とLightGBMを比べてみたけど、今回は決定木の方がちょっと良かったです。
LightGBMは設定やデータ次第で伸びしろありそうなので、また調整してみます。
モデルは使ってみてナンボ!いろいろ試してみるのが大事ですね。
みんなが「精度が高い!」って言ってても、うのみにしちゃダメだよって結果でした。
🔍LightGBMだけを深掘りした投稿はこちらでやってます!