概要
購買デモグラフィック(購買層の属性)をRで決定木 作ってたんですが、Pythonでも同じように結果が出るのか気になって比較してみました。
反省
技術的な説明は他の方が十分にされてるので アルゴリズムのせい にして済ませていたところ、某転職サイトのAIによる解析結果で
「アルゴリズムのせい」と繰り返すだけではだめです
と指摘されたので、心から反省するとともに技術的な解説を追加します。
(25年7月某日)
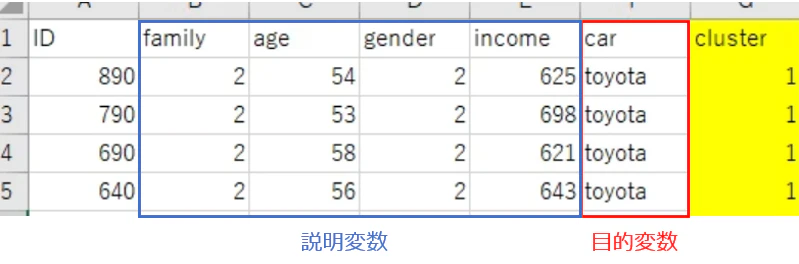
サンプルデータ
クラスタリングで分類したcluster(グループ)1のデータを使います。
Python処理時のフォルダ構成等でこちらに説明してます。
説明変数
・family : 同居家族の人数
・age : 年齢
・gender : 性別
・income : 世帯収入
※ここで リーケージ注意報!
サンプルデータには時系列や購入車名が無いため問題ありませんが、実際のデータを扱う場合には注意が必要です。
もし未来の情報(予測対象が先に分かってしまうもの)が含まれていると、AIが「ズル(カンニング)」をして、本来の性能以上に高精度に見せかけることがあります。
それを防ぐために、与えるデータが本当に予測に必要な情報だけで構成されているかを必ず確認してくださいな。
目的変数
・car : 購入したい車のメーカ名
環境
Python
python3.x
jupyter lab
R
RGui
Python コード
import pandas as pd
import numpy as np
import os
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import pydotplus
from IPython.display import Image
import matplotlib.pyplot as plt
#=============================================
# Inputファイル情報
#=============================================
INPUT_folder = '2_data'
INPUT_DNAME = '11.csv'
#=============================================
# Outputファイル情報
#=============================================
OUTPUT_folder = '3_output'
#=============================================
# カレントパス
#=============================================
current_dpath = os.getcwd()
#print('INFO:current_path:' + current_dpath)
#=============================================
# パレントパス
#=============================================
parent_dpath =os.path.sep.join(current_dpath.split(os.path.sep)[:-1])
#print('INFO:parent_path:' + parent_dpath)
#=============================================
# Inputデータファイル Path
#=============================================
input_dpath =os.path.sep.join([parent_dpath + '\\' + INPUT_folder,INPUT_DNAME])
#print('INFO:input_path:' + input_dpath)
#=============================================
# Outputデータファイル Path
#=============================================
output_dpath =parent_dpath + '\\' + OUTPUT_folder
#print('INFO:output_path:' + output_dpath)
#=============================================
# サンプルデータ読み込む
#=============================================
df = pd.read_csv(input_dpath,encoding='shift-JIS')
df = pd.DataFrame(df)
読み込んだデータを 説明変数 と 目的変数 指定
・ 説明変数 → 予測に使う入力データ
・ 目的変数 → 予測したい結果
#=============================================
# 説明変数・目的変数の準備
#=============================================
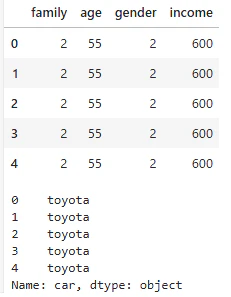
X_df = df.drop(['ID','car', 'cluster'], axis=1)
y_df = df['car']
#正しく分割できたかを確かめる
display(X_df.head())
print(y_df.head())
正しく分割できたことを確認します。
モデル
#=============================================
# 精度計算
#=============================================
X_train, X_test, y_train, y_test = train_test_split(X_df, y_df, random_state=0)
モデルがどのくらい「当てられるか(予測できるか)」を確認するために、「訓練用(train)」と「テスト用(test)」にデータを分割
● 学習用データ(X_train, y_train)
→ モデル(例えば回帰や分類器)を作るために使う。モデルが「学習」する材料。
● 訓練用データ(X_test, y_test)
→ 学習には使わずに「ちゃんと予測できるかどうか」を検証するために使う。
現実の未知データに近い立場。
print(len(X_train))
print(len(X_test))

全N数 → 220
・テストデータ数 → 220 × 0.25 = 55
・訓練データ数 → 220 − 55 = 165
※ 評価の際はデータを訓練用・テスト用に分割しましたが、モデル評価後、最終的な決定木の作成には全データを用いて再度学習を行います。
クラスを初期化
#=============================================
# 決定木モデルを構築するクラスを初期化
#=============================================
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=0)
Python(scikit-learn)でモデルを作るときは、
「モデルの設計図(クラス)」をまず用意して、その後「学習させる」。
これから作る決定木は、こういうルールで分割してね!と指示してます。
・criterion='gini' → 不純度の計算方法(ジニ係数)
・max_depth=3 → 木の深さの上限
・random_state=0 → 乱数の種(再現性確保)
※gini: 決定木の分岐の純度を測る指標で、クラスがどれだけ混ざっているかを表します。
値が0に近いほど1つのクラスに偏っていて、1に近いほど混ざり合っています。
木の中の分岐ルールを作って、訓練データを分類する仕組みを学習させる
#=============================================
# 決定木モデルを生成
#=============================================
model = clf.fit(X_train, y_train)
・clf = DecisionTreeClassifier(...)
→ 決定木の設定(深さや分割基準など)を決めた「空のモデル」を準備
・clf.fit(X_train, y_train)
→ この訓練データをもとに、
「どの特徴量をどの順番で分割すれば目的変数をうまく分類できるか」を学習=木の構造がこの時点で決まる
・model = ...
→ fit()は訓練済みのモデル(self)を返すので、modelには学習済みの決定木が入る
訓練データとテストデータの正解率を算出
#=============================================
# 訓練・テストそれぞれの正解率を算出
#=============================================
print('正解率(train):{:.3f}'.format(model.score(X_train, y_train)))
print('正解率(test):{:.3f}'.format(model.score(X_test, y_test)))
正解率(train):0.564
正解率(test):0.564
う!!ってなりそうですが、
今回は簡易的なサンプルデータを使用しているため、目的変数(car)と説明変数
(年齢・性別など)の間に、そもそも明確なパターンがない予測が難しいデータだったので
仕方ないです。
本番環境での分析では、より精度の高いモデル構築が可能になります👍
凡例作成
#=============================================
# 凡例
#=============================================
def add_class_legend(legend_text, x=0.1, y=0.8):
plt.gcf().text(
x, y,
legend_text,
fontsize=13,
va="top",
ha="left",
bbox=dict(
boxstyle="round,pad=0.5",
fc="lightyellow",
ec="gray",
lw=1
)
)
テキストで凡例(目的変数)を追加します。
学習
モデルにデータを学習させ、決定木のルールを作ります
#=============================================
# 学習
#=============================================
model.fit(X_df, y_df)
インデックス作成
#=============================================
# クラスのインデックス対応表を作成
#=============================================
legend_text = "Class index mapping:\n"
for idx, class_label in enumerate(model.classes_):
legend_text += f"{idx}: {class_label}\n"
model.classes_ は、目的変数(ラベル)のユニークなクラス名の配列です。
例えばクラス(目的変数)が ["A", "B", "C"] の場合、インデックスは 0, 1, 2 となります。
enumerate() でクラス名とインデックスを順に取り出し、
legend_text に「0: A」「1: B」「2: C」といった対応を書き加えています。

決定木を描画する
プロットの全体サイズを指定
#=============================================
# プロットの全体サイズを指定
#=============================================
plt.figure(figsize=(20,10))
木を大きく見やすく描画するために指定します(幅20インチ×高さ10インチ)。
描画
#=============================================
# 決定木を描画
#=============================================
# 比率あり
tree.plot_tree(
model,
feature_names=X_df.columns,
class_names=model.classes_.astype(str),
filled=True,
max_depth=6
)
決定木を視覚化し、各ノードにサンプルの比率を表示します。凡例としてクラスの対応表をグラフ内に追加しています
・ model → 学習済みの決定木
・ feature_names=X_df.columns → 特徴量の列名をノードに表示
・ class_names=model.classes_.astype(str)
→ 目的変数のラベルをノードに表示(数字ではなく文字列で分かるようにする)
・ filled=True → ノードに色を付けて分かりやすく
・ max_depth=6 → ツリーの深さを指定。最大6に制限(深すぎると見にくい)
・ proportion=True → 各ノードに表示するサンプル数を割合で示す場合に使用
add_class_legend(legend_text)
先ほど定義した関数で、凡例(クラスのインデックスとラベルの対応表)を
テキストでグラフ上に追加しています。
plt.savefig("P_decision_tree.png_N", dpi=300)
plt.show()
描画した決定木をPNGファイルとして保存し、同時に画面にも表示します。
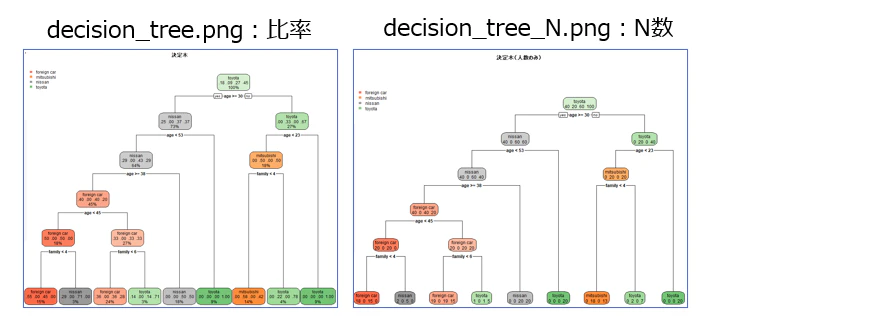
<参考用>ノードに表示するサンプル数を割合にした場合
#=============================================
# 決定木のプロット 比率 &PNG保存
#=============================================
# プロットの全体サイズを指定(幅20インチ×高さ10インチ)
plt.figure(figsize=(20,10))
tree.plot_tree(
model,
feature_names=X_df.columns,
class_names=model.classes_.astype(str),
filled=True,
max_depth=6,
proportion=True ♯ ←これを追加する
)
add_class_legend(legend_text) # ←ここで関数を呼ぶ
plt.savefig("P_decision_tree.png", dpi=300)
plt.show()
max_depth=6を指定しているのに、ツリーが4階層しか描画されないのは、木が実際に
学習した深さが4だからです。
**max_depthの指定は「最大6まで表示してもいいよ」という上限を決めているだけ。
木の実際の深さが6未満なら、それ以上の階層は存在しない→ だから表示も4階層で止まる。

読み取り方
・age<= 30 → 30歳以下かどうかで分岐(条件が真なら左、偽なら右へ進む)
・gini=0.678 → 不純度を示す指標。0に近いほど純粋(1つのクラスに偏っている)
・value=[40,20,60,100] → → 各クラス[foreign car(外車),mitsubishi,nissan,toyota]のN数
・sample =220人 → このノードに属するデータ数(全体で220件)

R コード
# ライブラリ
library(rpart)
library(rpart.plot)
#----------------------------------------------
# <必要に応じて> 作業フォルダに移動
#----------------------------------------------
#現在の作業フォルダ表示
getwd()
#setwd("C:/Users/user/【移動先のフォルダパス】/")
#----------------------------------------------
# データ読み込み
#----------------------------------------------
df <- read.csv("11.csv", fileEncoding = "shift-jis")
#----------------------------------------------
# 説明変数・目的変数の準備
#----------------------------------------------
# 説明変数(特徴量)を抽出
# ID, car, cluster 列を除いたデータを使う
x_df <- subset(df, select = -c(ID,car, cluster))
# 目的変数(ターゲットラベル)を抽出
# car列が目的変数
y_df <- df$car
# rpart()では formula(y ~ .) の形で学習するため
# 説明変数と目的変数を1つのデータフレームに結合
# データを結合(rpartはformulaで指定するので)
data_all <- data.frame(y_df, x_df)
・subset() → 指定した列を除外して説明変数を選択
・ y_df <- df$car
→ 車のカテゴリ(外車、三菱、日産、トヨタなど)を目的変数として取得。
・data.frame()で結合 → Rのrpart()は「formula形式」で
r
y ~ .
と書く必要があるため、説明変数と目的変数をまとめて1つのデータフレームを作成。
#----------------------------------------------
# 訓練・テスト分割
#----------------------------------------------
# 乱数の種を固定(再現性のため)
set.seed(0)
# データフレームの行番号(1:nrow)から75%をランダム抽出
train_idx <- sample(seq_len(nrow(data_all)), size = 0.75 * nrow(data_all))
# 訓練データ(インデックスに含まれる行)
train_data <- data_all[train_idx, ]
# テストデータ(インデックスに含まれない行)
test_data <- data_all[-train_idx, ]
・ set.seed(0)
→ 乱数のシードを固定し、毎回同じ分割になるようにしています(再現性の確保)。
・ sample()
→ データ行番号をランダムに抽出。size=0.75 * nrow()で全体の75%を訓練用に選びます。
・ train_data, test_data
→ 訓練データとテストデータを分離。テストデータは評価にのみ使います。
rpart()はformula形式(目的変数 ~ 説明変数)でモデルを作成するため、説明変数と目的変数を同じデータフレームにまとめています。
ここではsubset()を使って不要な列(IDやクラスタ情報)を除外し、純粋に予測に使う変数のみを選んでいます。
#----------------------------------------------
# モデル訓練
#----------------------------------------------
model <- rpart(y_df ~ .,
data = train_data,
method = "class",
parms = list(split = "gini"),
control = rpart.control(maxdepth = 3))
・ rpart() → 決定木モデルを学習する関数。
・ y_df ~ . → 目的変数をy_df(先ほど作ったdata_allの列)、説明変数は残り全てを利用。
・data = train_data → 学習データは訓練データ。
・method = "class"→ 分類問題を指定。
・parms = list(split = "gini")→ ジニ係数で分割基準を決定。
・control = rpart.control(maxdepth = 3) → 木の深さを最大3に制限(過学習防止)。
訓練データとテストデータを75%/25%に分割し、決定木(ジニ係数・最大深さ3)を学習しています。
set.seed()で分割を固定し、再現性を確保しています。
#----------------------------------------------
# 訓練データに対して予測
#----------------------------------------------
train_pred <- predict(model, train_data, type = "class")
train_acc <- mean(train_pred == train_data$y_df)
#----------------------------------------------
# # テストデータに対して予測
#----------------------------------------------
test_pred <- predict(model, test_data, type = "class")
#----------------------------------------------
# テストデータの正解率
#----------------------------------------------
test_acc <- mean(test_pred == test_data$y_df)
#----------------------------------------------
# 結果を出力
#----------------------------------------------
cat(sprintf("正解率(train): %.3f\n", train_acc))
cat(sprintf("正解率(test): %.3f\n", test_acc))
正解率(train): 0.606
正解率(test): 0.455
Pythonの結果と違いますが、理由として
1. 実装が別物
Python: scikit-learn の DecisionTreeClassifier
R: rpart パッケージ
これらは**理論的には同じ「決定木(CARTアルゴリズム)」**を使っていますが、
デフォルトの実装・パラメータ・細かい計算の扱いが異なります。
2. デフォルトの分割基準
scikit-learn→ デフォルト criterion = "gini"
rpart→ デフォルトも一応ジニ係数ですが、枝刈りの仕方や扱いが異なる
parms = list(split = "gini")
で明示しているのでここは合わせていますが、
それ以外の内部計算や分割候補の扱いが異なります。
3. 木の枝刈り
Python→ 基本的に「木を全部伸ばしてからmax_depthなどで制限」
R (rpart)→ 「枝刈り(pruning)」を自動で行うため、ツリーのサイズや分割が違う
rpartは「複雑度パラメータ(cp)」の設定で木の枝刈り度合いが変わります。
4. 乱数と分割
set.seed()やrandom_stateを同じにしても、両方の実装で乱数の使い方が微妙に異なり、
データの分割や分岐候補が変わります。
#----------------------------------------------
# 決定木の設定
#----------------------------------------------
model <- rpart(
y_df ~ .,
data = x_df,
method = "class",
parms = list(split = "gini"),
control = rpart.control(maxdepth = 6)
)
・rpart() → 決定木(CART: Classification And Regression Tree)を学習する関数
・ y_df ~ . → y_df(目的変数)を予測するために「その他の全ての変数(ピリオド.)」を
説明変数として使う (例 : y_df ~ x1 + x2 + x3)
・data = data_all → モデルが学習するためのデータフレーム
※data_allには必ずy_dfが列として含まれている必要がある。
・ method = "class" → 分類問題で学習する
・ parms = list(split = "gini") → ノードを分割するときの不純度指標をジニ係数にする
・ control = rpart.control(maxdepth = 6) → 木の最大深さの制限を指定
#----------------------------------------------
# 決定木のプロット N数 &PNG保存
#----------------------------------------------
rpart.plot(model,
type = 2,
extra = 1,
fallen.leaves = TRUE,
main = "決定木(人数のみ)")
・rpart.plot() → 決定木をきれいに描画する
・type = 2→ 分割条件を枝の上に表示する形式
・extra = 1→ ノード内にサンプル数(N数)を表示する
(extraを変えると確率や分類も出せます)
・fallen.leaves = TRUE→ 木の葉を下にそろえる(見た目がきれい)
・main = "決定木(人数のみ)"→ プロットのタイトル
# PNGに保存
png("decision_tree_N.png", width = 1000, height = 800)
rpart.plot(model,
type = 2,
extra = 1,
fallen.leaves = TRUE,
main = "決定木(人数のみ)")
dev.off()
・ png() → 描画を画像ファイルに出力
・ model → どの決定木モデルを描画するかを指定
・ type = 2 → 分割条件(ルール)を枝の上に表示する形式
・extra = 1 → ノードに表示する「追加情報」を指定。
extra=0: 表示なし
extra=1: 各ノードにサンプル数(N数)だけ表示
extra=2: 分類されたクラスを表示
extra=5: クラスと確率を表示
extra=101: クラス、確率、N数を全部表示(情報量多い)
extra=104: 確率とサンプル数を表示
・ fallen.leaves = TRUE → 葉(末端のノード)を一番下に揃える
・ main = "決定木(人数のみ)" → 描画するプロットのタイトル
<参考用>ノードに表示するサンプル数を割合にした場合
#----------------------------------------------
# 決定木のプロット 比率 &PNG保存
#----------------------------------------------
rpart.plot(model,
type = 2,
extra = 104,
fallen.leaves = TRUE,
main = "決定木")
# PNGに保存
png("decision_tree.png", width = 1000, height = 800)
rpart.plot(model,
type = 2,
extra = 104,
fallen.leaves = TRUE,
main = "決定木")
dev.off()
比較
全体
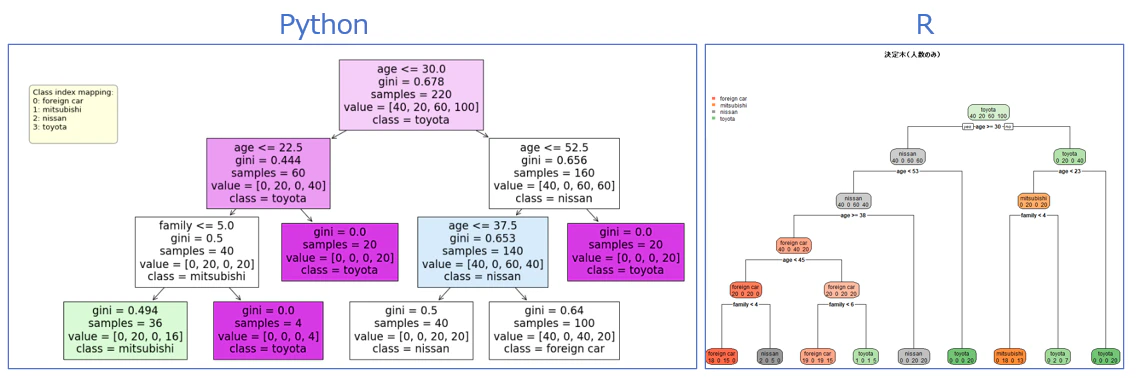
問題①:枝、PyhonとR、なんか逆(アルゴリズムのせい)。

問題②:年齢、Pyhon何でそんなことしちゃうの(アルゴリズムのせい)。
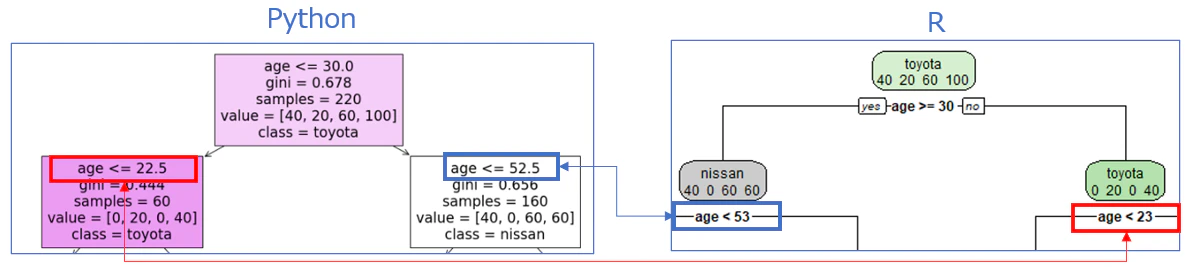
決定木で age <= 22.5 のような条件が表示されて「え? 22.5歳って何?」となりますね。
Pythonの決定木(例:sklearn.tree.DecisionTreeClassifier)では、「この数字には大きい・小さいの意味があるんだな」と思って、年齢のように数字の間に境界を引いて分けちゃいます。
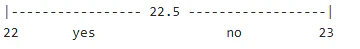
age <= 22.5 の解釈:
→ Yes(True):年齢が 22歳以下
→ No(False):年齢が 23歳以上
になります。
※ 性別など本来は順番のないものも数字で渡すと、同じように大きさで分けてしまいます。Rは性別をカテゴリとして扱ってくれるので、この点が少し違います。
問題③:同じ階層(4階層)で確認すると、赤〇の個所が異なってます(アルゴリズムのせい)。
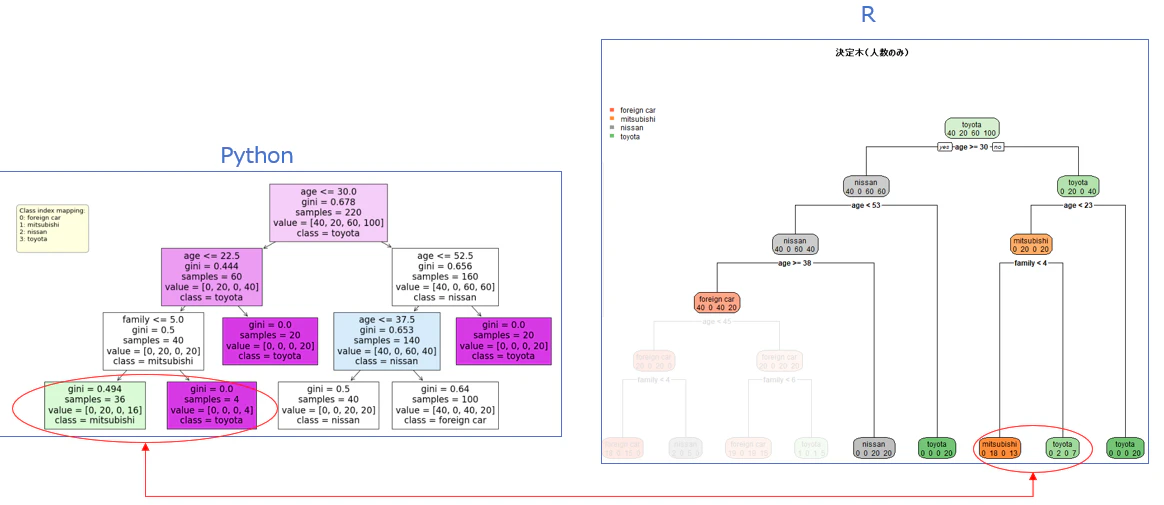
まとめ
Rの決定木(rpart)をPython(scikit-learn)に寄せることも技術的には可能ですが、
実務や多くのケースでは完全に一致させる必要はなく、
それぞれの特徴を理解した上で使い分けるのが現実的です。
全部アルゴリズムのせいで片付けていましたが、まじめに解説してみました。
以上です