深層学習 day1
0. プロローグ
ニューラルネットワーク(NN)概要
・ニューラルネットワークの全体像
「入力層」「中間層」「出力層」の3つに分かれる。
・ディープラーニングとは
何層もの中間層を持つニューラルネットワークを用いて、入力値から目的とする出力値に変換する数学モデルを構築すること。
ニューラルネットワーク(NN)でできること
・回帰
結果予想 (売上予想、株価予想)
ランキング(競馬順位予想、人気順位予想)
・分類
猫写真の判別
手書き文字認識
花の種類分類
深層学習の実用例
自動売買(トレード)
チャットボット
翻訳
音声解釈
囲碁・将棋AI
確認テスト
●確認テスト
・ディープラーニングは、結局何をやろうとしているか2行以内で述べよ。
何層もの中間層を持つニューラルネットワークを用いて、入力値から目的とする出力値に変換する数学モデルを構築すること。
・次の中のどの値の最適化が最終目的か
重み[W], バイアス[b]
●確認テスト
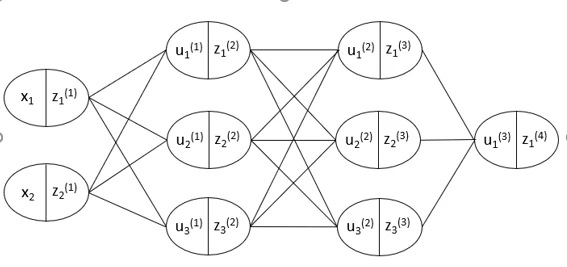
・以下のニューラルネットワークを紙に書け。
入力層:2ノード1層
中間層:3ノード2層
出力層:1ノード1層
1. 入力層~中間層
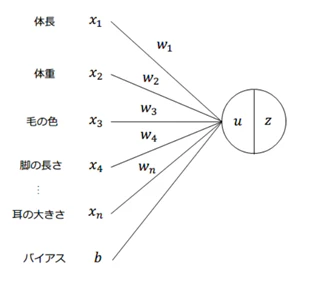
・入力層($x$)とは、ニューラルネットワークにおいてデータが入力される層
・中間層($u$)とは、前の層からの入力値を変換し、次の層へ出力する層
・重み($w$)は、前の層からの入力値を変換する係数であり、その重要度を表現することができる。
・バイアス($b$)は、重み(係数)だけでは表現できないずれ(切片)を表現する。
u=w_1x_1+w_2x_2+w_3x_3+w_4x_4......+b=Wx+b
確認テスト
●確認テスト
・この図式に動物分類の実例を入れてみよう。
●確認テスト
・数式$u=w_1x_1+w_2x_2+w_3x_3+w_4x_4+b=Wx+b$をPythonで書け。
import numpy as np
u = np.dot(x, W) + b
●確認テスト
・1-1のファイルから中間層の出力を定義しているソースを抜き出せ。
z = functions.sigmoid(u)
print_vec("中間層出力", z)
2. 活性化関数
ニューラルネットワークにおいて、次の層への出力の大きさを決める非線形の関数。
入力値の値によって、次の層への信号のON/OFFや強弱を定める働きをもつ。
中間層用の活性化関数
・ReLU関数
・シグモイド(ロジスティック)関数
・ステップ関数
出力層用の活性化関数
・ソフトマックス関数
・恒等写像
・シグモイド(ロジスティック)関数
ステップ関数
しきい値を超えたら発火する関数であり、出力は常に1か0。
パーセプトロン(ニューラルネットワークの前身)で利用された関数。
しかし、0~1間の間を表現できず、線形分離可能なものしか学習できなかった。
f(x) = \left\{ \begin{array}{ll}1 & (x \geq 0) \\0 & (x \lt 0) \end{array} \right.
シグモイド関数
0~1の間を緩やかに変化する関数で、ステップ関数ではON/OFFしかない状態に対し、信号の強弱を伝えられるようになり、予想ニューラルネットワーク普及のきっかけとなった。
しかし、大きな値では出力の変化が微小なため、勾配消失問題を引き起こす事があった。
{f(x)=\frac{1}{1+e^{-x}}}
ReLU関数
今最も使われている活性化関数
勾配消失問題の回避とスパース化に貢献することで良い成果をもたらしている。
f(x) = \left\{ \begin{array}{ll}x & (x \geq 0) \\0 & (x \lt 0) \end{array} \right.
確認テスト
●確認テスト
・線形と非線形の違いを簡潔に説明せよ。
線形は直線(1次元)で表される関数
非線形は曲線(2次元以上)で表される関数
●確認テスト
・配布されたソースコードより該当する箇所を抜き出せ。
z1 = functions.relu(u1)
z2 = functions.relu(u2)
3. 出力層
入力したデータがどのクラスに属するか、の確率を各クラスごとに出力する。
誤差関数
・誤差関数は、出力層の結果(計算値)と正解値との比較から、どのくらい間違えているかを表現する。
ズレているほどそn値は大きくなる。
・2値分類ならクロスエントロピー、他クラス分類ならカテゴリカルクロスエントロピー、
回帰なら平均二乗誤差や平均絶対誤差等が用いられる。
・平均二乗誤差(MSE:Mean Squared Error)
回帰問題の誤差関数
${\frac{1}{2}\sum_{n=1}^N(y_n-t_n)^2}$
def mean_squared_error(y, d):
return np.mean(np.square(y-d)) / 2
・クロスエントロピー(交差エントロピー)
分類問題の誤差関数
${-\sum_{n=1}^Nt_n\mathbb{log}y_n}$
非常によく使う関数
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
#
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7) / batch_size
出力層の活性化関数
・回帰 → 恒等写像
・ニ値分類 → シグモイド関数
・多クラス分類 → ソフトマックス関数

確認テスト
●確認テスト
・なぜ、下式で引き算でなく二乗するか述べよ
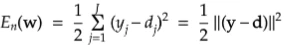
引き算を行うだけでは、各ラベルでの誤差で正負両方の値が発生する可能性がある。その際、誤差を足し合わせると正負の数で打ち消しあってしまう。そのため誤差の合計を正しくあらわすことができない。
それを防ぐため、2乗してそれぞれのラベルでの誤差を正の値になるようにする。
・上式の1/2はどういう意味を持つか述べよ
誤差逆伝播の計算で誤差関数の微分を用いるが、この1/2があることで計算が簡略化できるため。本質的な意味はない。
●確認テスト
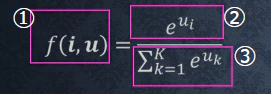
・①~③の数式に該当するソースコードを示し、一行づつ処理の説明をせよ。
① softmax(x)
② np.exp(x)
③ np.sum(np.exp(x))
# ソフトマックス関数
def softmax(x):
if x.ndim == 2: ### このif文の中の処理はミニバッチでのみ使われる
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x)) ### ミニバッチ以外での処理はこの部分だけ ②/③
●確認テスト

・①~②の数式に該当するソースコードを示し、一行づつ処理の説明をせよ。
① cross_entropy_error(d, y)
② -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7))
# クロスエントロピー
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
###本質的な処理は最後の1行
### 1e-7は対数関数で0の時-∞になるのを防ぐため加算
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
4. 勾配降下法
誤差関数が最小値をとるようなパラメータを見つけたい
しかし誤差関数は複雑であるので最小値を見つけることはむずかしい。
そこで誤差関数の勾配を利用して最小値に近づけるように探すことが勾配降下法である。
①勾配降下法
②確率的勾配降下法
③ミニバッチ勾配降下法
①勾配降下法
数式:
$w^{t+1} = w^{(t)} - \epsilon \Delta E$
ΔE 誤差勾配
ϵ 学習率
②確率的勾配降下法
メリット
・データが冗長な場合は計算コストを軽減
・毎回毎回違いデータを使って学習するため、望まない局所最適解に収束するリスクを軽減
・オンライン学習できる
数式:
$w^{t+1} = w^{(t)} - \epsilon \Delta E_n$
③ミニバッチ勾配降下法
メリット
確率的勾配降下法のメリットを損なわず、計算機の計算資源を有効利用できる
→CPUを利用したスレッド並列化やGPUを利用したSIMD並列化
数式:
$w^{t+1} = w^{(t)} - \epsilon \Delta E_t$
$E_t = \frac{1}{N_t} \sum_{n \in D_t} E_n$
$N_t = |D_t|$
学習率
学習率が大きいと、最適解を飛び越えて値が大きくなり、学習がうまく進まない。このことを「発散」という。
逆に、学習率が小さいと発散する確率が減るが、学習が終わるまでの時間がかかる。
また、学習率が小さいと、局所最適解(極小値)を求めてしまう可能性がある。
勾配降下法の学習率を決定する手法は以下のような方法がある。
・Momentum
・AdaGrad
・Adadelta
・Adam
確認テスト
●確認テスト
・該当するソースコードを探してみよう。
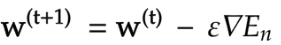
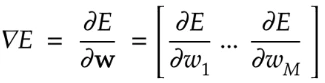
network[key] -= learning_rate * grad[key]
grad = backward(x, d, z1, y)
●確認テスト
・オンライン学習とはなにか2行でまとめよ。
学習データが入ってくる都度パラメータを更新し、学習を進めていく。
最初に全部データを準備する必要がない。
●確認テスト
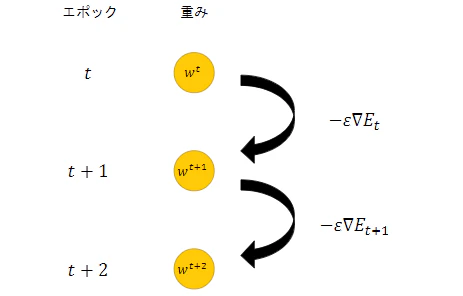
・この数式の意味を図に書いて説明せよ。
$w^{t+1} = w^{(t)} - \epsilon \Delta E_t$
5. 誤差逆伝播法
算出された誤差を、出力層側から順に微分し、前の層前の層へと伝播。最小限の計算で各パラメータでの微分値を解析的に計算する手法。
確認テスト
●確認テスト
誤差逆伝播法では不要な再帰的処理を避ける事が出来る。既に行った計算結果を保持しているソースコードを抽出せよ。
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
#delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
## 試してみよう
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
delta1 = delta1[np.newaxis, :]
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
x = x[np.newaxis, :]
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
# print_vec("偏微分_重み1", grad["W1"])
# print_vec("偏微分_重み2", grad["W2"])
# print_vec("偏微分_バイアス1", grad["b1"])
# print_vec("偏微分_バイアス2", grad["b2"])
return grad
●確認テスト
・2つの空欄に該当するソースコードを探せ。
delta2 = functions.d_mean_squared_error(d, y)
grad['W2'] = np.dot(z1.T, delta2)
深層学習 day2
1. 勾配消失問題
誤差逆伝播法が下位層に進んでいくに連れて、勾配がどんどん緩やかになっていく。
そのため、勾配降下法による、更新では下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる。
勾配消失の解決方法
・活性化関数の選択
→ReLU関数を選択する。なぜなら、
・今最も使われている活性化関数
・勾配消失問題の回避とスパース化に貢献することで良い成果をもたらしている。
・重みの初期値設定
→Xavierの初期値、Heの初期値
・バッチ正規化
→ミニバッチ単位で入力値のデータの偏りを抑制する手法
確認テスト
●確認テスト
・シグモイド関数を微分した時、入力値が0の時に最大値をとる。その値として正しいものを選択肢から選べ。
0.25
●確認テスト
・重みの初期値に0を設定すると、どのような問題が発生するか。簡潔に説明せよ。
すべての重みの値が同じ値で出力層まで伝わるため、重みをもつ意味がなくなり、正しいチューニングが行えなくなる。
●確認テスト
・一般的に考えられるバッチ正規化の効果を2点挙げよ。
計算が高速
勾配消失が起こりづらい。
演習
「2_2_2_vanishing_gradient_modified.ipynb」を使用して演習
・ガウス分布に基づいて重みを初期化
・活性化関数はシグモイド関数を使用
→勾配消失を防ぐための対策がとられていない。
<結果>
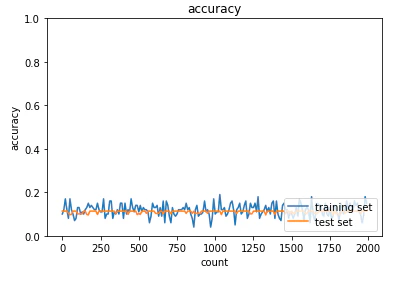
学習が行われていない。
・ガウス分布に基づいて重みを初期化
活性化関数はRelu関数を使用
<結果>
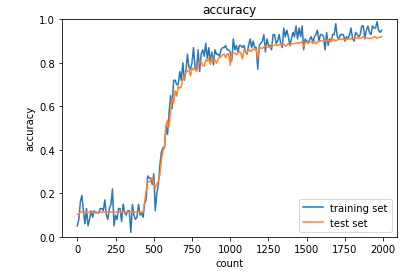
途中までは学習が進まないがその後急に進む。
・Xavier初期化
活性化関数はシグモイド関数を使用
<結果>
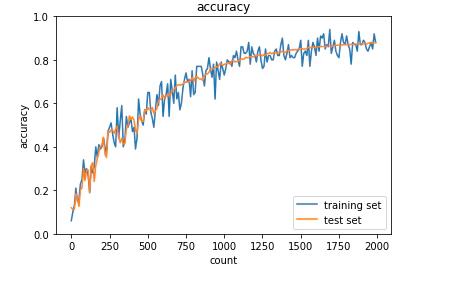
はじめから順調に学習が進んでいる。
・He初期化
活性化関数はRelu関数を使用
<結果>
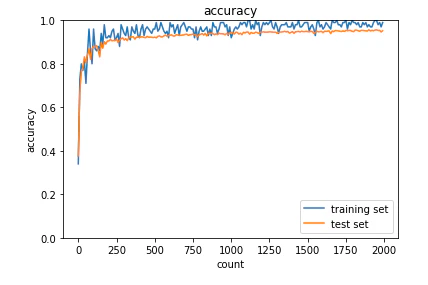
高速に学習が進んでいる。
・バッチ正則化
「2_3_batch_normalization.ipynb」を使用して演習
<結果>
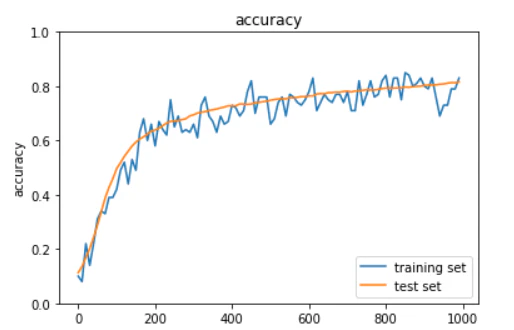
学習がうまく進んでいる。
2. 学習率最適化手法
初期の学習率設定方法の指針
・初期の学習率を大きく設定し、徐々に学習率を小さくしていく
・パラメータ毎に学習率を可変させる
→学習率最適化手法を利用して、学習率を最適化
学習率最適化手法
・モメンタム
・AdaGrad
・RMSprop
・Adam
モメンタム
誤差をパラメータで微分したものと学習率の積を減算した後、現在の重みに前回の重みを減算した値と慣性の積を加算する
$V_{t} = \mu V_{t-1} - \epsilon \nabla E$
$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)} + V_{t}$
モメンタムのメリット
・局所的最適解にはならず、比較的大域的最適解になりやすい。
・谷間についてから最も低い位置(最適値)にいくまでの時間が早い
AdaGrad
誤差をパラメータで微分したものと再定義した学習率の積を減算する
$h_0 = \theta$
$h_t = h_{t-1}+(\nabla E)^2$
$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)} - \epsilon \frac{1}{\sqrt{h_t}+\theta}\nabla E$
勾配の緩やかな斜面に対して、最適値に近づける。
しかし、学習率が徐々に小さくなるので、鞍点問題を引き起こす事があった。
RMSProp
誤差をパラメータで微分したものと再定義した学習率の積を減算する
$h_t = \alpha h_{t-1}+(1-\alpha)(\nabla E)^2$
$\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)} - \epsilon \frac{1}{\sqrt{h_t}+\theta}\nabla E$
局所的最適解にはならず、大域的最適解となる。
ハイパーパラメータの調整が必要な場合が少ない。
Adam
・モメンタムの、過去の勾配の指数関数的減衰平均
・RMSPropの、過去の勾配の2乗の指数関数的減衰平均
上記をそれぞれ孕んだ最適化アルゴリズムである。
確認テスト
●確認テスト
・モメンタム、AdaGrad、RMSpropの特徴をそれぞれ簡潔に説明せよ。
モメンタム:大域的最適解になりやすい。
AdaGrad:勾配が緩やな場合でも最適値に近づける。
RMSprop:AdaGradの改良版。ハイパーパラメータの調整が必要な場合が少ない
演習
「2_4_optimizer_after.ipynb」を使用して演習
・SGD(確率的勾配降下法)
(ソースコード省略)
<結果>
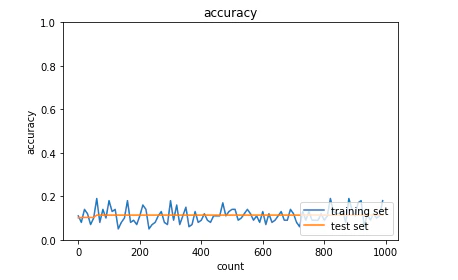
学習がうまくいかなかった。
・Momentum
コードの確認
# 慣性
momentum = 0.9
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
v = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
v[key] = np.zeros_like(network.params[key])
### モメンタムの更新量の計算 ###################
v[key] = momentum * v[key] - learning_rate * grad[key]
network.params[key] += v[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
<結果>
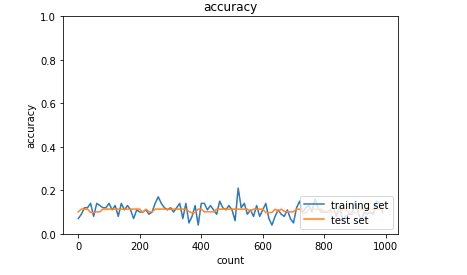
学習がうまくいかなかった。
・AdaGrad
コードの確認
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
# 変更しよう
# ===========================================
if i == 0:
h[key] = np.zeros_like(network.params[key])
### AdaGradの更新量の計算 ###########################
h[key] = momentum * h[key] - learning_rate * grad[key]
network.params[key] += h[key]
# ===========================================
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
<結果>
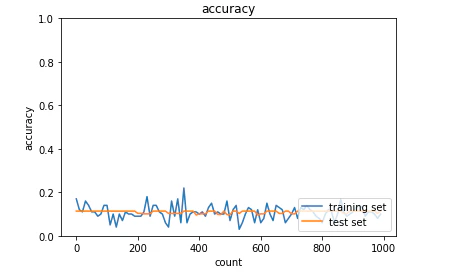
学習がうまくいかなかった。
・RSMprop
コードの確認
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
decay_rate = 0.99 ### ハイパーパラメータ##########
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
h[key] = np.zeros_like(network.params[key])
### 更新量の計算 ###########################
h[key] *= decay_rate
h[key] += (1 - decay_rate) * np.square(grad[key])
network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
<結果>
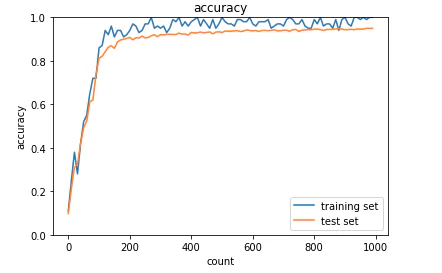
学習がうまくいった。
・Adam
コードの確認
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
m = {}
v = {}
learning_rate_t = learning_rate * np.sqrt(1.0 - beta2 ** (i + 1)) / (1.0 - beta1 ** (i + 1))
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
m[key] = np.zeros_like(network.params[key])
v[key] = np.zeros_like(network.params[key])
### 更新量の計算 ###########################
m[key] += (1 - beta1) * (grad[key] - m[key])
v[key] += (1 - beta2) * (grad[key] ** 2 - v[key])
network.params[key] -= learning_rate_t * m[key] / (np.sqrt(v[key]) + 1e-7)
<結果>
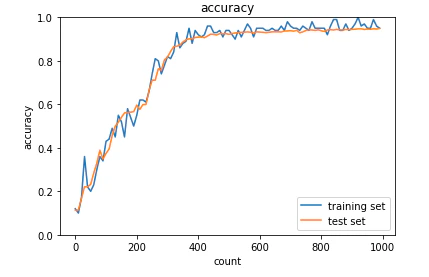
学習がうまくいった。
3. 過学習
過学習の原因
重みが大きい値をとることで、過学習が発生することがある。
・学習させていくと、重みにばらつきが発生する。
・重みが大きい値は、学習において重要な値であり、重みが大きいと過学習が起こる。
過学習の解決策
誤差に対して、正則化項を加算することで、重みを抑制する。
過学習がおこりそうな重みの大きさ以下で重みをコントロールし、かつ重みの大きさにばらつきを出す必要がある。
正則化の手法
<L1正則化、L2正則化>
{E_n(\boldsymbol{w}) + \frac{1}{p}\lambda \|\boldsymbol{x}\|_p\\
\|\boldsymbol{x}\|_p = (|x_1|^p+|x_2|^p+\cdots+|x_n|^p)^{\frac{1}{p}}\\
}
\\
p=1のとき、L1正則化\\
p=2のとき、L2正則化
<ドロップアウト>
過学習の課題
→ノードの数が多い
ドロップアウトとは︖
→ランダムにノードを削除して学習させること
メリットとして、データ量を変化させずに、異なるモデルを学習させていると解釈できる。
確認テスト
●確認テスト
・機械学習で使われる線形モデル(線形回帰、主成分分析…etc)の正則化は、モデルの重みを制限することで可能となる。
前述の線形モデルの正則化手法の中にリッジ回帰という手法があり、その特徴として正しいものを選択しなさい
(a)ハイパーパラメータを大きな値に設定すると、すべての重みが限りなく0に近づく
(b)ハイパーパラメータを0に設定すると、非線形回帰となる
(c)バイアス項についても、正則化される
(d)リッジ回帰の場合、隠れ層に対して正則化項を加える
解答:(a)
●確認テスト
・下図について、L1正則化を表しているグラフはどちらか答えよ。
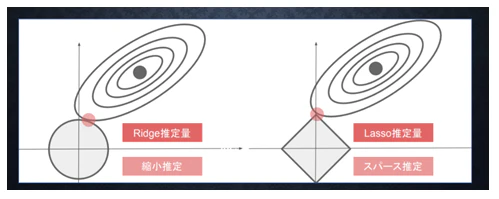
解答:右の図(Lasso)
演習
「2_5_overfiting.ipynb」を使用して演習
import numpy as np
from collections import OrderedDict
from common import layers
from data.mnist import load_mnist
import matplotlib.pyplot as plt
from multi_layer_net import MultiLayerNet
from common import optimizer
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True)
print("データ読み込み完了")
# 過学習を再現するために、学習データを削減
x_train = x_train[:300]
d_train = d_train[:300]
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10)
optimizer = optimizer.SGD(learning_rate=0.01)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
grad = network.gradient(x_batch, d_batch)
optimizer.update(network.params, grad)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i+1) % plot_interval == 0:
accr_train = network.accuracy(x_train, d_train)
accr_test = network.accuracy(x_test, d_test)
accuracies_train.append(accr_train)
accuracies_test.append(accr_test)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
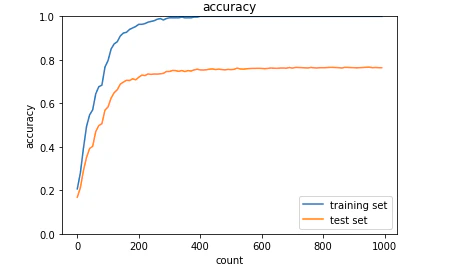
訓練データに対する正解率とテストデータに対する正解率に大きな乖離があり過学習が起きている。
これに対処するために、様々な正則化を行った。
・L2正則化
<結果>
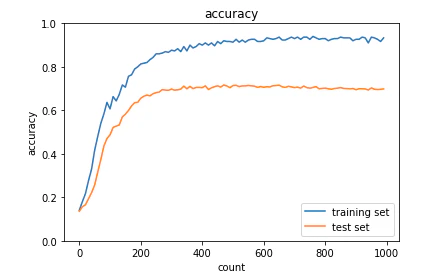
正則化を行っていない時に比べて、訓練データの正解率とテストデータの正解率の乖離が小さくなっている。
・L1正則化
<結果>
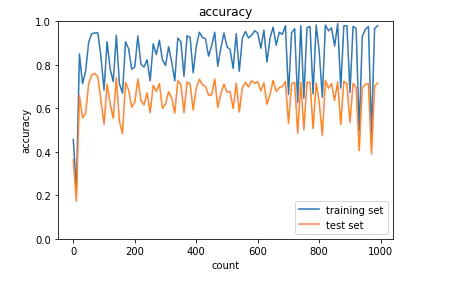
一部の重みが0となるため、正答率が安定しない。
・ドロップアウト
<結果>
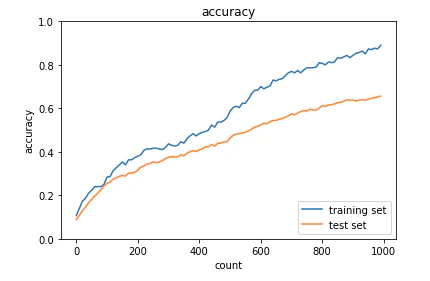
過学習を抑制しながら、順調に学習が進んでいる。
4. 畳み込みニューラルネットワークの概念
(畳み込み層の全体像)
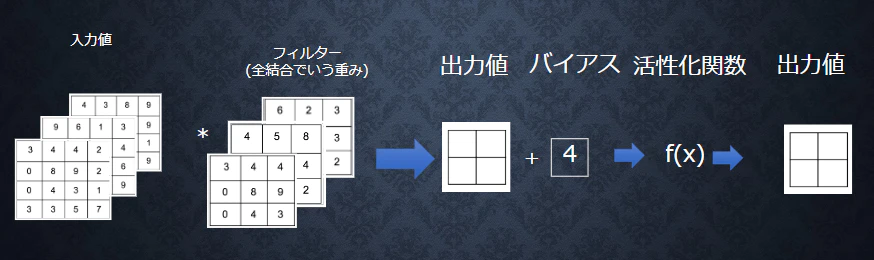
畳み込み層
画像の場合、縦、横、チャンネルの3次元のデータをそのまま学習し、次に伝えることができる。
3次元の空間情報も学習できるような層が畳み込み層である。
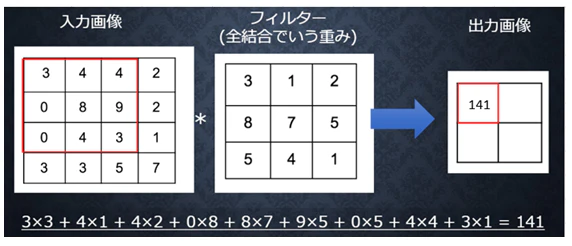
・バイアス
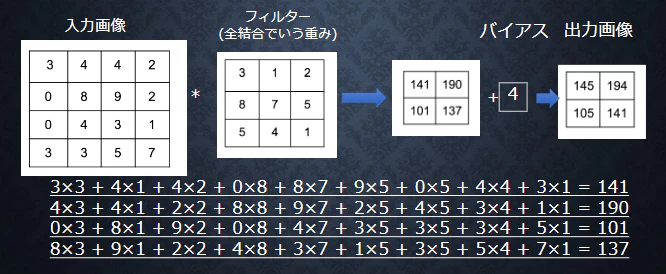
フィルター適用後のデータに加算される値
上記の図ではバイアスは4
・パディング
画像の周囲に固定値(例えば0)を埋め込んで、サイズを大きくすること。
これをすることで、畳み込みをしても画像のサイズを維持することが出来る。
また、パディングなしの場合、画像の端の方は他の部分と比べて畳み込みに使われる回数が少なくなり、特徴が抽出されにくい。しかしパディングをすることによってより端の方も特徴が抽出されるようになる。
・ストライド
畳み込みの際にフィルタをずらす間隔
・チャンネル
空間的な奥行き。例えばカラー画像の場合はRGBの3チャンネルに分けて畳み込みを行う。
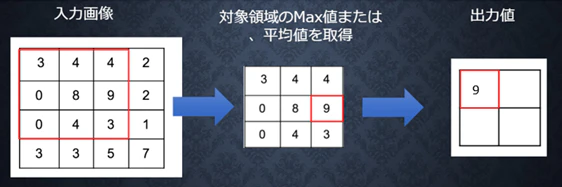
プーリング層
対象領域の中から1つの値(最大値、平均値など)を取得する層。
情報を減らすことによって、画像サイズを小さくできる。
情報は減るものの、畳み込んだ後に行うことでそれらしい特徴をとらえた値のみを抽出できる。
確認テスト
●確認テスト
・サイズ6×6の入力画像を、サイズ2×2のフィルタで畳み込んだ時の出力画像のサイズを答えよ。なおストライドとパディングは1とする
答え:7x7
演習
コードの確認
「2_6_simple_convolution_network.ipynb」を使用して演習
・高速で演算するために、入力の行列を並び替える。
input_data = np.random.rand(2, 1, 4, 4)*100//1 # number, channel, height, widthを表す
print('========== input_data ===========\n', input_data)
print('==============================')
filter_h = 3
filter_w = 3
stride = 1
pad = 0
col = im2col(input_data, filter_h=filter_h, filter_w=filter_w, stride=stride, pad=pad)
print('============= col ==============\n', col)
print('==============================')

・畳み込み処理
学習データとして、MNISTというデータセットを利用する。
from common import optimizer
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(flatten=False)
print("データ読み込み完了")
# 処理に時間のかかる場合はデータを削減
x_train, d_train = x_train[:5000], d_train[:5000]
x_test, d_test = x_test[:1000], d_test[:1000]
network = SimpleConvNet(input_dim=(1,28,28), conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
optimizer = optimizer.Adam()
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
grad = network.gradient(x_batch, d_batch)
optimizer.update(network.params, grad)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i+1) % plot_interval == 0:
accr_train = network.accuracy(x_train, d_train)
accr_test = network.accuracy(x_test, d_test)
accuracies_train.append(accr_train)
accuracies_test.append(accr_test)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
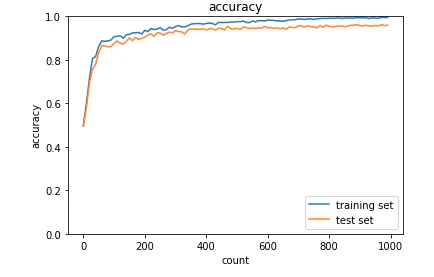
学習を繰り返すごとに、正答率は上がってゆく。
実行にとても時間がかかった。
5. 最新のCNN
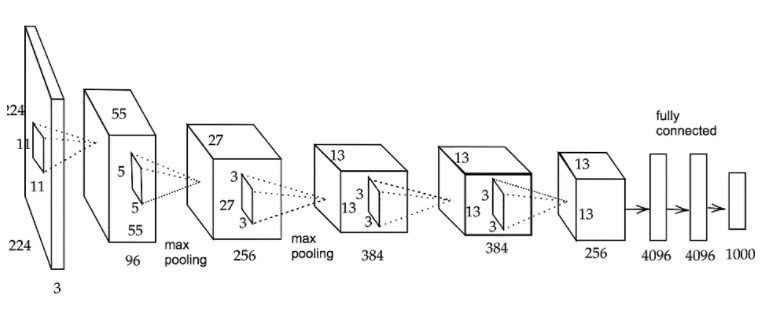
AlexNet
・高い精度で物体認識を行うことを目指して開発されたモデル
・2012年にILSVRC(ImageNet Large Scale Visual Recognition Challenge)で優勝したモデル。
・5層の畳み込み層およびプーリング層、それに続いて③層の全結合層という構造。
・過学習を防ぐ施策としてサイズ4096の全結合層の出力にドロップアウトを使用している