深層学習 day3
1. 再起型ニューラルネットワークの概念
RNNとは?
時系列データに対応可能な、ニューラルネットワークである。
時系列データとは?
RNNの数学的記述
u^t = W_{(in)}x^t + Wz^{(t-1)}x^t + b
z^t = f( W_{(in)}x^t + Wz^{(t-1)}x^t + b)
v^t = W_{(out)}z^t + c
y^t = g(W_{(out)}z^t + c)
BPTTとは?
確認テスト
●確認テスト
・RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
前回の中間層から今回の中間層を定義する際にかけられる重み
●確認テスト
・$z=t^2$
$t=x+y$ のとき、連鎖律の原理を使い、dz/dxを求めよ。
微分の連鎖率は $\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}$
$\frac{dz}{dt}=2t$
$\frac{dt}{dx}=1$
より、 $\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}=2t\times 1=2(x+y)$
●確認テスト
・下図のy1をx1,s0,s1,win,w,woutを用いて数式で表わせ。
また、中間層の出力にシグモイド関数を作用させよ。

$z_1=sigmoid \left( s_0 W+x_1W_{in}+b \right)$
$y_1=sigmoid \left( z_1 W_{out}+c \right)$
演習
「3_1_simple_RNN.ipynb」を使用して演習
・weight_init_stdやlearning_rate, hidden_layer_sizeを変更してみる
・重みの初期化方法を変更してみる Xavier, He
・中間層の活性化関数を変更してみる
実行結果
■初期設定時
weight_init_std = 1、learning_rate = 0.1、hidden_layer_size = 16の場合
Loss:0.0008183348639234245

学習初期はまったく計算できていないが中盤以降正しく計算されている。
学習初期
iters:0
Loss:1.1975681144149255
Pred:[0 0 0 0 0 0 0 0]
True:[1 0 1 0 1 0 0 0]
74 + 94 = 0
----------
iters:100
Loss:1.2389801912116842
Pred:[0 0 0 0 0 0 1 0]
True:[0 0 1 1 1 1 1 0]
5 + 57 = 2
----------
iters:200
Loss:1.1297270239377117
Pred:[1 1 1 1 1 1 1 1]
True:[1 0 0 1 1 0 0 0]
126 + 26 = 255
----------
学習中盤
iters:2900
Loss:0.31628167916708866
Pred:[0 1 1 1 1 1 1 1]
True:[0 1 1 1 1 1 1 1]
4 + 123 = 127
----------
iters:3000
Loss:0.1747678585251631
Pred:[1 0 1 1 0 1 1 0]
True:[1 0 1 1 0 1 1 0]
67 + 115 = 182
----------
iters:3100
Loss:0.17302211592386807
Pred:[1 1 0 1 1 0 0 1]
True:[1 1 0 1 1 0 0 1]
108 + 109 = 217
----------
学習終盤
iters:9800
Loss:0.0018430173212841529
Pred:[1 0 0 1 0 1 0 1]
True:[1 0 0 1 0 1 0 1]
50 + 99 = 149
----------
iters:9900
Loss:0.0008183348639234245
Pred:[0 1 0 0 0 1 0 0]
True:[0 1 0 0 0 1 0 0]
47 + 21 = 68
----------
■ weight_init_std = 1、learning_rate = 0.6、hidden_layer_size = 16の場合
Loss:8.66837291755142e-06

■ weight_init_std = 6、learning_rate = 0.1、hidden_layer_size = 16の場合
Loss:0.09452716719245466

■ weight_init_std = 1、learning_rate = 0.1、hidden_layer_size = 64の場合
Loss:0.0010448489630578296


■ 重みの初期化方法をXavierに変更
# Xavier
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size))
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size))
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size))
Loss:0.005330465874498452

■ 重みの初期化方法をHeに変更
# He
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size)) * np.sqrt(2)
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
Loss:0.002617721908055697

■ 中間層の活性化関数をReLUに変更してみる
以下の4か所を変更した。
z[:,t+1] = functions.relu(u[:,t+1])
y[:,t] = functions.relu(np.dot(z[:,t+1].reshape(1, -1), W_out))
delta_out[:,t] = functions.d_mean_squared_error(dd, y[:,t]) * functions.d_relu(y[:,t])
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_relu(u[:,t+1])
Loss:1.0

予測値がすべて0であり、学習が全く進んでいない。
2. LSTM
RNNの課題として、時系列を遡れば遡るほど勾配が消失してゆくというものがあり、そのため長い時系列の学習が困難なことがある。
その解決策として、以前学習した勾配消失の解決方法とは別に、構造自体を変えて解決したLSTMというものがある。
LSTMは、CEC(Constant Error Carousel)と入力ゲート・出力ゲート・忘却ゲートの3つのゲートで構成されている。
<LSTMの全体図>

・CEC
(2)0.25
●確認テスト
・以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測においてなくなっても影響を及ぼさないと考えられる。このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもお腹が空いたから何か____。」
忘却ゲート
3. GRU
従来のLSTMでは、パラメータが多数存在していたため、計算負荷が大きいという課題があった。
GRUは、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった構造である。
メリットとしては、計算負荷が低いことがあげられる。
確認テスト
●確認テスト
・LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
LSTM:パラメータ数が多く、計算負荷が大きい
CEC:記憶はできるが、学習特性がない
●確認テスト
・LSTMとGRUの違いを簡潔に述べよ。
LSTM:パラメータが多数存在しているため、計算負荷が大きい。
GRU:パラメータが大幅に削減され計算負荷が低いものの、精度は同等またはそれ以上が望める。
演習
「predict_word.ipynb」を使用して演習を行う。
・自然言語処理で何かの単語が来た際に次に来る単語を予測する
・今回予測するのは"some of them looks like"の次に来る単語
実行結果
次に来る単語として、最も可能性が高かったのは"some of them looks like et"

4. 双方向RNN
時間軸に対して未来方向と過去の方向のRNNを組み合わせたものを双方向RNNと呼ぶ。
過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデルである。
実用例としては、文章の推敲や、機械翻訳等がある。
演習チャレンジ

(4)
5. Seq2Seq
seq2seqはEncoder-Decoderモデルの一種である。
具体的な用途:機械対話、機械翻訳など
Encoder RNN
ユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造。
Taking:文章を単語等のトークンごとに分割し、さらにトークンごとのIDに分割する。
Embedding:IDからそのトークンを表す分散表現ベクトルに変換する。
Encoder RNN:ベクトルを順にRNNに入力していく。
<Encoder RNN処理手順>
・vec1をRNNに入力し、hidden stateを出力。
このhidden stateと次の入力vec2をまたRNNに入力してきたhidden stateを出力という流れを繰り返す。
・最後のvecを入れたときのhidden stateをfinal stateとしてとっておく。
このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
Decoder RNN
システムがアウトプットデータを、単語等のトークンごとに生成する構造。
<Decoder RNNの処理>
1.Decoder RNN: Encoder RNNのfinal state (thought vector)から、各token の生成確率を出力。
final stateをDecoder RNNのinitial stateととして設定し、Embeddingを入力。
2.Sampling:生成確率にもとづいてtokenをランダムに選びます。
3.Embedding:選ばれたtokenをEmbeddingしてDecoder RNNへの次の入力とします。
4.Detokenize:以上を繰り返し、得られたtokenを文字列に直します。
HRED
HREDは過去n-1個の発話から次の発話を生成する。
Seq2seqでは、会話の文脈無視で、応答がなされたが、HREDでは、前の単語の流れに即して応答されるため、より人間らしい文章が生成される。
HREDはseq2seqとcontext RNNが組み合わさった構造を持つ。この構造により、過去の発話の履歴を加味した返答ができる。
HREDの課題
・確率的な多様性が字面にしかなく、会話の「流れ」のような多様性が無い。
→同じコンテキスト(発話リスト)を与えられても、答えの内容が毎回会話の流れとしては同じものしか出せない。
・短く情報量に乏しい答えをしがちである。
→短いよくある答えを学ぶ傾向がある。
VHRED
VHREDとは、HREDにVAEの潜在変数の概念を追加したもの。
→HREDの課題を解決した構造
オートエンコーダ
教師なし学習の一つ。そのため学習時の入力データは訓練データのみで教師データは利用しない。
オートエンコーダ具体例:
MNISTの場合、28x28の数字の画像を入れて、同じ画像を出力するニューラルネットワーク
オートエンコーダの構造:
入力データ(画像)から潜在変数zに変換するニューラルネットワークをEncoder
逆に潜在変数zをインプットとして元画像を復元するニューラルネットワークをDecoder。
メリット:次元削減が行えること(zの次元が入力データより小さい場合、次元削減とみなすことができる。)

VAE
通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているものの、その構造がどのような状態かわからない。
VAEはこの潜在変数zに確率分布z~N(0,1)を仮定したもの。

確認テスト
●確認テスト
・下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
(2)
●確認テスト
・Seq2SeqとHRED、HREDとVHREDの違いを簡潔に述べよ。
Seq2SeqとHREDの違い:Seq2Seqはは文脈のない一問一答しかできないが、HREDは過去n−1個の発話から文脈に応じた回答ができる。
HREDとVHREDの違い:HREDは当たり障りのない回答をしがちだが、VHREDはそれらの課題を解決し、多様性ある回答ができる。
●確認テスト
・VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
確率分布
6. word2vec
RNNでは、単語のような可変長の文字列をNNに与えることはできない。そのため固定長形式で単語を表す必要がある。
word2vecは単語をベクトルとして表現する手法であり、分散表現の獲得が可能になる。
1.学習データから辞書を作成
例:学習データ:"I want to eat apples. I like apples."
辞書:{apples, eat, I, like, to, want}
2.辞書の単語数分のone-hotベクトルを作成
例:apples(1,0,0,0,0,0)
eat(0,1,0,0,0,0)
I(0,0,1,0,0,0)
like(0,0,0,1,0,0)
to(0,0,0,0,1,0)
want(0,0,0,0,0,1)
大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能となった。
7. Attention Mechanism
・seq2seq の問題は長い文章への対応が難しいことである。
↑ なぜなら2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならないため。
・解決策として文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要となる。
・その仕組みがAttention Mechanismであり、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みである。
確認テスト
●確認テスト
・RNNとword2vec、seq2seqとAttention Mechanismの違いを簡潔に述べよ。
RNNとWord2vecの違い:RNNは時系列データを処理するのに適したNNであり、Word2vecは単語の分散表現ベクトルを得る手法。
seq2seqとAttentionの違い:Seq2Seqは一つの時系列データから別の時系列データを得るネットワークであり、Attentionは時系列の中身に対して、関連性に重みをつける手法。
深層学習 day4
1. 強化学習
長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく

<強化学習の応用例>
マーケティングの場合
環境: 会社の販売促進部
エージェント: プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。
行動: 顧客ごとに送信、非送信のふたつの行動を選ぶことになる。
報酬: キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける。
価値関数
価値を表す関数としては「状態価値関数」と「行動価値関数」の2種類がある。
ある状態の価値に注目する場合は、状態価値関数
状態と価値を組み合わせた価値に注目する場合は、行動価値関数
方策関数
方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数
2. AlphaGo
・囲碁のプログラム
・AlphaGo (Lee)とAlphaGo Zeroの2種類がある
・方策関数
19×19、48チャンネルの盤面の予測確立を出力し、最良の手を予測する
畳み込みニューラルネットワークが利用されている
出力層にはSoftMax関数が利用される

・価値関数
19×19、49チャンネルの盤面の勝率を-1~1で予測する
畳み込みニューラルネットワークが利用されている
出力層にはTanHを利用する

Alpha Goの学習
以下の学習ステップで行われる。
1. 教師あり学習によるRollOutPolicyとPolicyNetの学習
2. 強化学習によるPolicyNetの学習
3. 強化学習によるValueNetの学習
1. PolicyNetの教師あり学習
・強化学習前に教師あり学習を行うことである程度正確な学習ができるようにしている
・KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った
・具体的には、教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
・この学習で作成したPolicyNetは57%ほどの精度である。
2. PolicyNetの強化学習
・現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行った。
・PolicyPoolとは、PolicyNetの強化学習の過程を500 Iteraionごとに記録し保存しておいたものである。
・現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ぐためである。
・この学習をminibatch size 128で1万回行った。
3. ValueNetの学習
・PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。
・教師データ作成の手順は
- まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
- 次にN+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
- 最後にS(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
・S(N+1)とRを教師データ対、損失関数を平均二乗誤差として回帰問題として学習した。
・この学習をminibatch size 32で5000万回行った。
・N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている。
AlphaGo(Lee) とAlphaGoZeroの違い
1. 教師あり学習を一切行わず、強化学習のみで作成
2. 特徴入力からヒューリスティックな要素(役に立ちそうな要素)を排除し、石の配置のみにした
3. PolicyNetとValueNetを1つのネットワークに統合した
4. Residual Net(後述)を導入した
5. モンテカルロ木探索からRollOutシミュレーションをなくした

Residual Network
・ネットワークにショートカット構造を追加して深いネットワークを回避して勾配爆発、消失を抑える効果を狙ったもの
・Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった
・基本構造はConvolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLUのBlockを1単位にして積み重ねる形となる
・Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある

Residual Networkの派生形
・Residual Blockの工夫
- Bottleneck
1×1KernelのConvolutionを利用し、1層目で次元削減を行って3層目で次元を復元する3層構造にし、2層のものと比べて計算量はほぼ同じだが1層増やせるメリットがある、としたもの
- PreActivation
ResidualBlockの並びをBatchNorm→ReLU→Convolution→BatchNorm→ReLU→Convolution→Addとすることにより性能が上昇したとするもの
・Network構造の工夫
- WideResNet
ConvolutionのFilter数をk倍にしたResNet。
1倍→k倍xブロック→2*k倍yブロックと段階的に幅を増やしていくのが一般的。
Filter数を増やすことにより、浅い層数でも深い層数のものと同等以上の精度となり、またGPUをより効率的に使用できるため学習も早い
- PyramidNet
WideResNetで幅が広がった直後の層に過度の負担がかかり精度を落とす原因となっているとし、段階的にではなく、各層でFilter数を増やしていくResNet。
3. 軽量化・高速化技術
データ並列化
親モデルを各ワーカーに子モデルとしてコピー
データを分割し、各ワーカーごとに計算させることをデータ並列化と呼ぶ。
・データ並列化:同期型

・データ並列化:非同期型
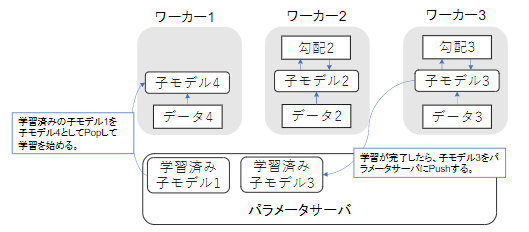
処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
しかし、非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
現在は同期型の方が精度が良いことが多いので、主流となっている
モデル並列化
親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。

GPUによる高速化
・GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
・CPU
高性能なコアが少数
複雑で連続的な処理が得意
・GPU
比較的低性能なコアが多数
簡単な並列処理が得意
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
モデルの軽量化
モデルの精度を維持しつつパラメータや演算回数を低減する手法の総称
計算の高速化と省メモリ化を行うため、モバイル,IoT 機器と相性が良い手法
1.量子化
4. 応用技術
MobileNet
Depthwise Separable Convolution (Depthwise ConvolutionとPointwise Convolution)という仕組みを用いて画像認識において軽量化・高速化・高精度化したモデル。



MobileNetは、Depthwise Separable Convolutionという手法を用いて計算量を削減している。
通常の畳込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行う。

DenseNet
Dense Convolutional Network(以下、DenseNet)は、畳込みニューラルネットワーク(以下、CNN)アーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、Residual Network(以下、ResNet)などのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseBlockと呼ばれるモジュールを用いた、DenseNetもそのようなアーキテクチャの一つである。

●DenseNetとResNetの違い
・DenseBlockでは前方の各層からの出力全てが後方の層への入力として用いられる
・RessidualBlockでは前1層の入力のみ後方の層へ入力
●DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは成⻑率(Growth Rate)と呼ばれるハイパーパラメータが存在する。
●DenseBlock内の各ブロック毎にk個ずつ特徴マップのチャネル数が増加していく時、kを成⻑率と呼ぶ
正規化

・Batch Norm
ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化

・Layer Norm
それぞれのsampleの全てのpixelsが同一分布に従うよう正規化

・Instance Norm
さらにchannelも同一分布に従うよう正規化

WaveNet
生の音声波形を生成する深層学習モデル
Pixel CNNを音声に応用したもの

確認テスト
●確認テスト
・深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNet の大きな貢献の1 つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。
(あ)Dilated causal convolution
●確認テスト
(あ)を用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
(い)パラメータ数に対する受容野が広い
5. Transformer
<Encoder-Decoderモデル(ニューラル機械翻訳)の問題点>
長さに弱い
文長が長くなると翻訳精度が落ちる

<Attention の利点>
文長が長くなっても翻訳精度が落ちないこと

<Transfomer>
TransfomerはEncoder-DecoderとAttention機構を組み合わせ、最後に全結合層を経て翻訳結果を返すモデルである。
・2017年6月に登場 - RNNを使わない
・ 必要なのはAttentionだけ
・ 当時のSOTAをはるかに少ない計算量で実現
・ 英仏 (3600万文) の学習を8GPUで3.5日で完了

演習
「lecture_chap1_exercise_public.ipynb」「lecture_chap2_exercise_public.ipynb」を使用して演習を行う。
・Seq2SeqモデルとTransformerモデルのそれぞれで、英語から日本語への翻訳を行う。
・2つの結果を比較する。
実行結果
<Seq2Seqモデル>
翻訳結果

BLEUスコア

<Transformerモデル>
翻訳結果

BLEUスコア

考察
・Seq2Seqモデルの翻訳結果よりもTransformerモデルの翻訳結果の方が自然な日本語だと感じた。
・BLEUスコアも18.2から25.6へと向上した。
6. 物体検知・セグメンテーション
広義の物体認識タスク

代表的データセット
データ選択学習のために重要

Box/画像が少ない → 認識された風船の数が少ない
評価指標
Confusion Matrixを利用する

$$ Precision = \frac{TP}{TP + FP} $$
$$ Recall = \frac{TP}{TP + FN} $$
IoU:Intersection over Union
・物体検出においてはクラスラベルだけでなく物体位置の予測精度も評価したい
・Confusion Matrixの要素を用いて表現される
$$ IoU = \frac{TP}{TP + FP + FN} 別名Jaccard係数とも呼ばれる $$
-